Redis:Redis基础知识 01
Posted Xiao Miao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis:Redis基础知识 01相关的知识,希望对你有一定的参考价值。
Redis基础知识 01
一、NoSQL与RDBMS
1.RDBMS
- RDBMS:关系型数据库管理系统
- 工具:mysql、Oracle、SQL Server…
- 应用:业务型数据存储系统:事务和稳定性
- 特点:体现数据之间的关系,保证业务完整性和稳定性,小数据量的性能也比较好
- 需求:能实现高并发的数据库,接受高并发需求
2.NoSQL
- NoSQL:非关系型数据库
- 工具:Redis、HBASE、MongoDB…
- 应用:一般用于高并发性能场景下的数据缓存或者数据库存储
- 特点:读写速度特别快、相对而言不如RDBMS稳定,对事物的支持不太友好
- 开发:每中NoSQL都有自己的命令语法
- 解决:RDBMS的问题:实现读写分离
- 读需求:读请求不读MySQL、读取Redis
- 写需求:直接写入MySQL
二、Redis的功能与应用场景
- 定义:基于内存的分布式的NoSQL数据库
- 功能:提高高性能并发的数据存储
- 特点
- 基于C语言开发的系统,与硬件交互性能更好
- 基于内存实现数据读写,读写性能更快
- 分布式的、扩展性和稳定性更好
- 支持事务、拥有各种各样丰富的数据结构
- 应用场景
- 缓存:用于实现高并发的数据缓存
- 数据库:用于实现高性能的数据读写
- 场景
- 数据库:永久性存储
- 缓存:临时存储
- 消息中间件:消息队列MQ
三、Redis的安装、部署
- Redis版本
- 3.x:支持分片集群功能
- 5.x:分片集群的功能更加稳定
1.Windows上的部署
GitHub:下载地址
版本:Redis-x64-3.2.100.zip
 解压完毕就可以使用
解压完毕就可以使用
- 测试
- 打开客户端和服务端
有的系统存在兼容性问题,服务端不能直接打开,需要编写一个脚本文件打开服务端,脚本文件内容如下
redis-server.exe redis.windows.conf
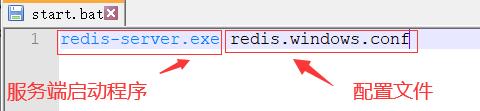
- 服务端
- 客户端
 - 测试命令
- 测试命令

2.Redis的桌面管理工具的部署
百度网盘:下载地址
提取码:zfin
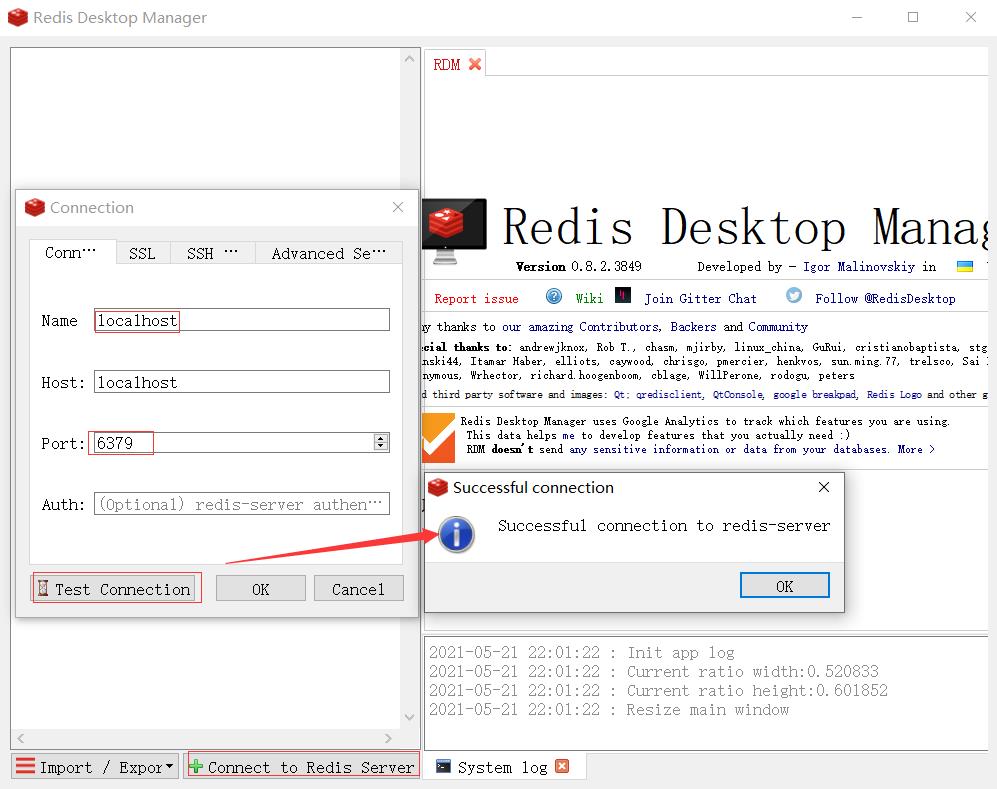
- 解压安装即可
- 启动连接
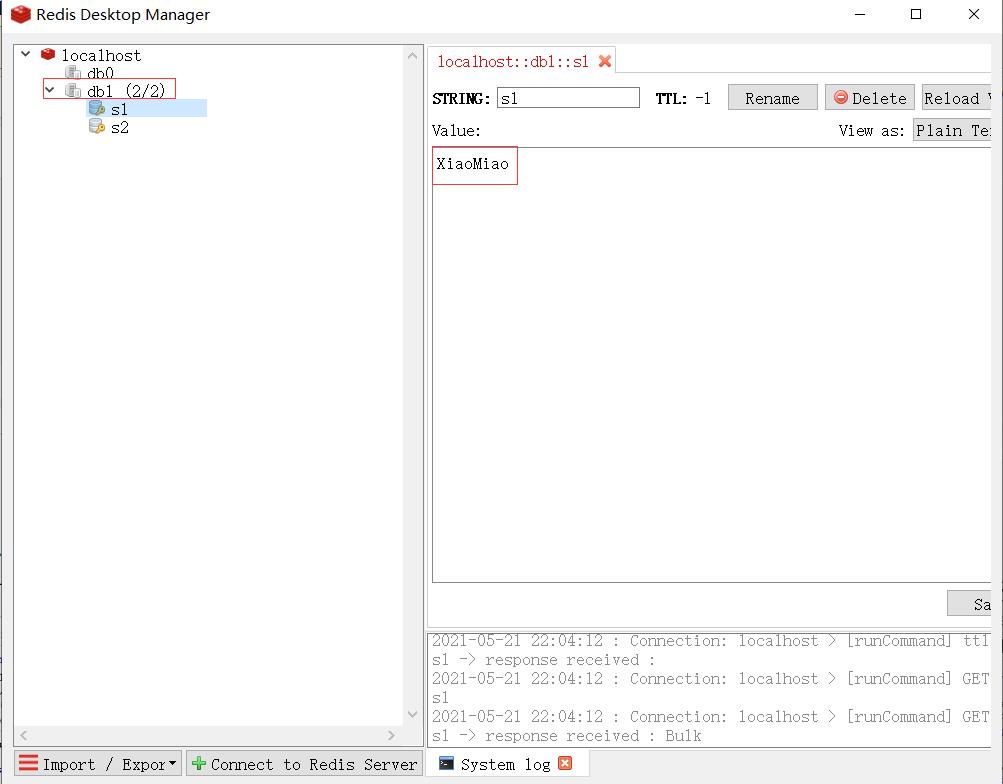
3.Linux上的部署
百度网盘:下载地址
提取码:tfp9
版本:redis-3.2.8.tar.gz
- 将下载的redis安装包上传安装包到Linux上
#1.切换到指定目录
cd /export/software/
#2.上传
rz

解压
tar -zxvf redis-3.2.8.tar.gz -C /export/server/
安装依赖
yum -y install gcc-c++ tcl
编译安装
#1.进入源码目录
cd /export/server/redis-3.2.8/
#2.编译
make
#3.安装,并指定安装目录
make PREFIX=/export/server/redis-3.2.8-bin install
修改配置
1.复制配置文件
cp /export/server/redis-3.2.8/redis.conf /export/server/redis-3.2.8-bin/
2.创建目录
#1.创建redis日志目录
mkdir -p /export/server/redis-3.2.8-bin/logs
#2.创建redis数据目录
mkdir -p /export/server/redis-3.2.8-bin/datas
3.修改配置
#1.切换到redis-3.2.8-bin目录
cd /export/server/redis-3.2.8-bin/
#2.编辑配置文件
vim redis.conf
- 修改内容如下:
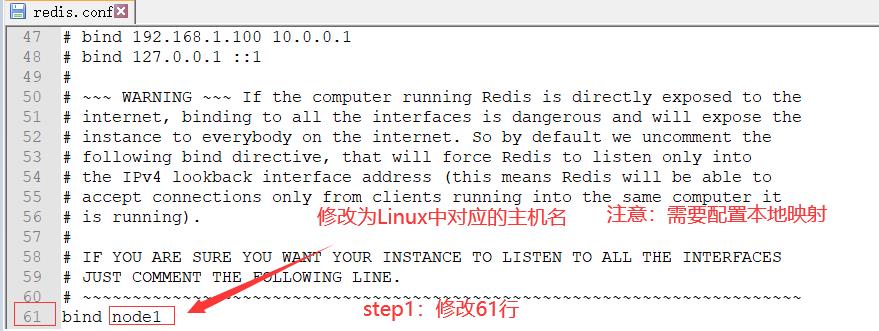

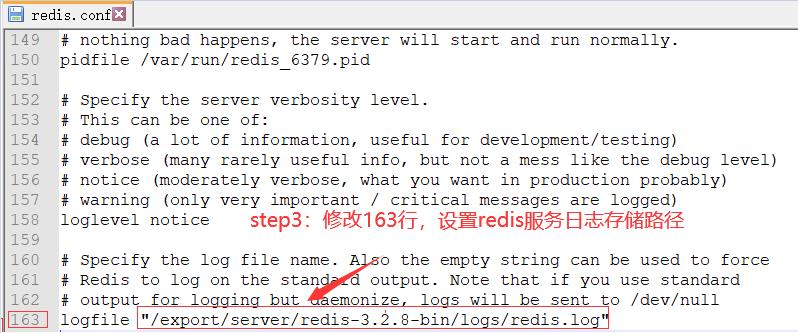
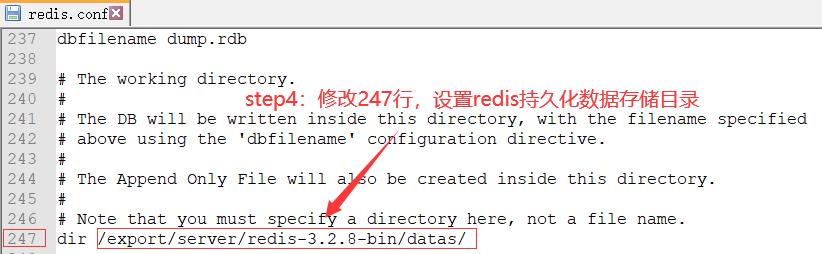
4.创建软连接
#1.切换到server目录
cd /export/server
#2.创建软连接
ln -s redis-3.2.8-bin redis

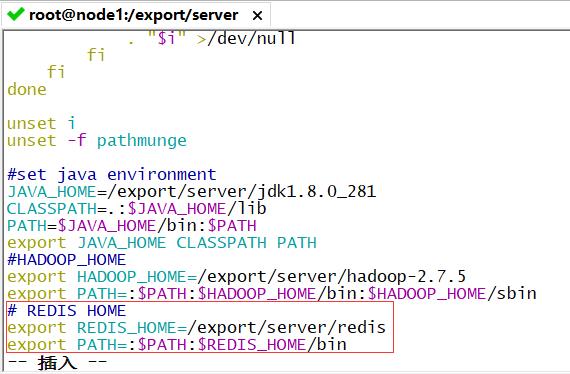
5.配置环境变量
#1.编辑profile文件
vim /etc/profile
#2.添加以下内容
# REDIS HOME
export REDIS_HOME=/export/server/redis
export PATH=:$PATH:$REDIS_HOME/bin
#3.刷新环境变量
source /etc/profile
启动
1.启动服务端
命令
/export/server/redis/bin/redis-server /export/server/redis/redis.conf
查看是否启动
ps -ef | grep redis
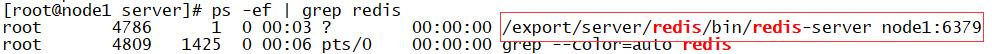 2.编辑服务端启动脚本
2.编辑服务端启动脚本
vim /export/server/redis/bin/redis-start.sh
添加脚本内容如下:
#!/bin/bash
REDIS_HOME=/export/server/redis
${REDIS_HOME}/bin/redis-server ${REDIS_HOME}/redis.conf

修改权限
chmod u+x /export/server/redis/bin/redis-start.sh
3.启动客户端
/export/server/redis/bin/redis-cli -h node1 -p 6379
4.关闭客户端和服务端
关闭客户端
exit
关闭服务端
- 客户端中
shutdown
- Linux命令行下
kill -9 pid
- 通过客户端命令
bin/redis-cli -h node1 -p 6379 shutdown
测试
四、Redis数据结构和类型
Redis数据结构
- 整个Reids中所有数据以KV结构形式存在
- K:作为唯一标识符,唯一标识一条数据,固定为String类型
- V:真正存储的数据,可以有多种类型
- String、Hash、List、Set、Zset、BitMap、HypeLogLog
Redis:类似于Java中的一个Map集合
Map<String,T> = Redis存储
- 写:指定K和V
- 读:指定K
Redis数据类型
| Key:String | Value类型 | Value值 | 应用场景 |
|---|---|---|---|
| s1 | String | 10000 | 一般用于存储单个数据指标的结果 |
| hs1 | Hash | name:zhangsan age : 18 sex : male | 用于存储整个对象所有属性值 |
| ls1 | List | {100,200,300} | 有序允许重复的集合,每天获取最后一个值 |
| ss1 | Set | {userid1,userid2,userid3…} | 无序且不重复的集合,直接通过长度得到UV |
| zs1 | ZSet | {1-衣服,2-文具,3-电脑…} | 有序不可重复的集合,统计TopN |
| bs1 | BitMap | {0101010101010000000011010} | 将一个字符串构建位,通过0和1来标记每一位 |
| ps1 | HypeLogLog | {id1,id2,id3…} | 类似于Set集合,底层实现原理不一样,数据量大的情况下,性能会更好 |
- String类型
- KV:【String,String】,类似于Java中Map集合的一条KV
- Hash类型
- KV:【String,Map集合】:Map集合的嵌套,Map集合中的元素是无序的
- List类型
- KV:【String,List】:有序且可重复
- Set类型
- KV:【String,Set】:无序且不重复
- Zset类型
- KV:【String,TreeMap集合】:Value也类似于Map集合,有序的Map集合
- 类似于List和Set集合特点的合并:有序且不可重复
五、Redis命令
1.通用命令
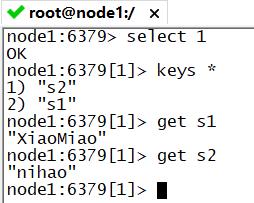
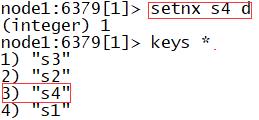
- keys:列举当前数据库中所有Key
#1.列举所有key
keys *
#2.列举s开头的所有key
keys s*
#3.列举1结尾的所有key
keys *1

- del key:删除某个KV
#删除key值为s1的kv
del s1

- exists key :判断某个Key是否存在 ,存在为1,不存在为0
#判断k值为s2的是否存在
exists s2
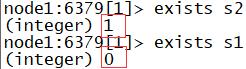
- type key:判断这个K对应的V的类型的
#判断s2的v的类型
type s2
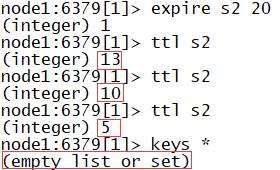
 - expire K 过期时间:设置某个K的过期时间,一旦到达过期时间,这个K会被自动删除
- expire K 过期时间:设置某个K的过期时间,一旦到达过期时间,这个K会被自动删除
#为k值为s2的设置过期时间20秒
expire s2 20
- ttl K:查看某个K剩余的存活时间
#查看k值为s2的剩余存活时间
ttl s2
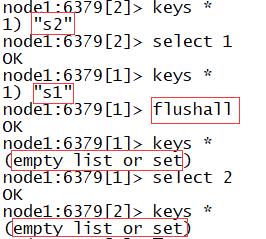
- select N:切换数据库
- 默认Redis有16个数据库,DB0 ~ DB15
- 默认自动进入0数据库
#切换到数据库2
select 2
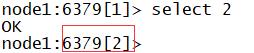
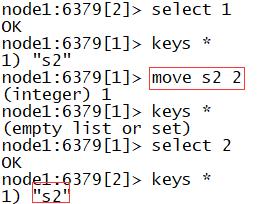
- move key N:将某个Key移动到某个数据库中
#将s2移动到数据库2
move s2 2
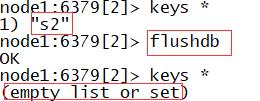
- flushdb:清空当前数据库的所有Key
#清楚当前数据库所有k
flushdb
- flushall:清空所有数据库的所有Key
#清空所有数据库的所有k
flushall
2.String类型的常用命令
-
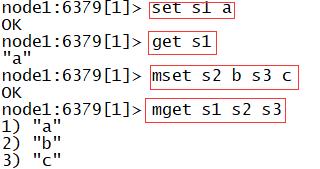
set:给String类型的Value的进行赋值或者更新
- 语法:set K V
-
get:读取String类型的Value的值
- 语法:get K
-
mset:用于批量写多个String类型的KV
- 语法:mset K1 V1 K2 V2 ……
-
mget:用于批量读取String类型的Value
- 语法:mget K1 K2 K3 ……
-
setnx:只能用于新增数据,当K不存在时可以进行新增
- 语法:setnx K V
- 应用:构建抢占锁,搭配expire来使用
-
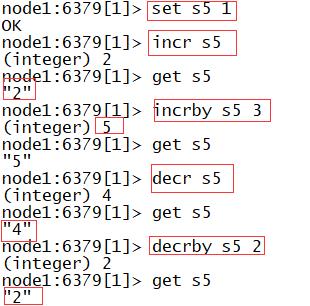
incr:用于对数值类型的字符串进行递增,递增1
- 语法:incr K
-
incrby:指定对数值类型的字符串增长固定的步长
- 语法:incrby K N
-
decr:对数值类型的数据进行递减,递减1
- 语法:decr K
-
decrby:按照指定步长进行递减
- 语法:decrby K N
-
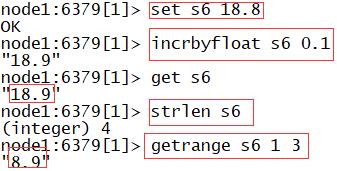
incrbyfloat:基于浮点数递增
- 语法:incrbyfloat K N
-
strlen:统计字符串的长度
- 语法:strlen K
-
getrange:用于截取字符串
- 语法:getrange s2 start end
3.Hash类型的常用命令
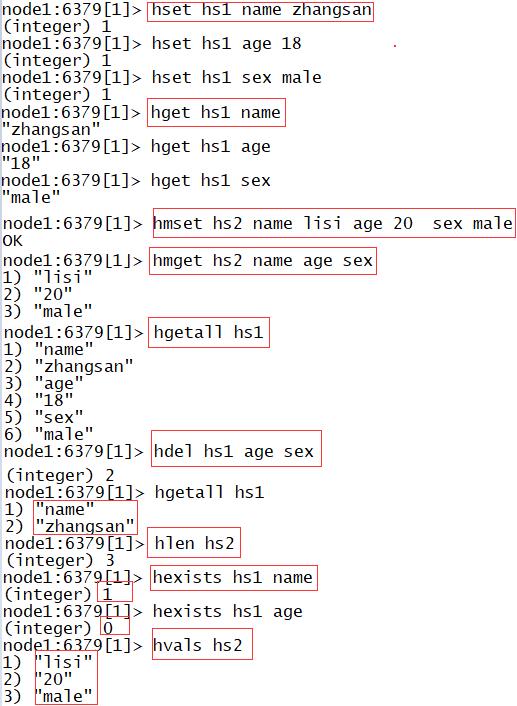
-
hset:用于为某个K添加一个属性
- 语法:hset K k v
-
hget:用于获取某个K的某个属性的值
- 语法:hget K k
-
hmset:批量的为某个K赋予新的属性
- 语法:hmset K k1 v1 k2 v2 ……
-
hmget:批量的获取某个K的多个属性的值
- 语法:hmget K k1 k2 k3……
-
hgetall:获取所有属性的值
- 语法:hgetall K
-
hdel:删除某个属性
- 语法:hdel K k1 k2 ……
-
hlen:统计K对应的Value总的属性的个数
- 语法:hlen K
-
hexist*:判断这个K的V中是否包含这个属性
- 语法:hexists K k
-
hvals:获取所有属性的value的
- 语法:hvals K
4.List类型的常用命令
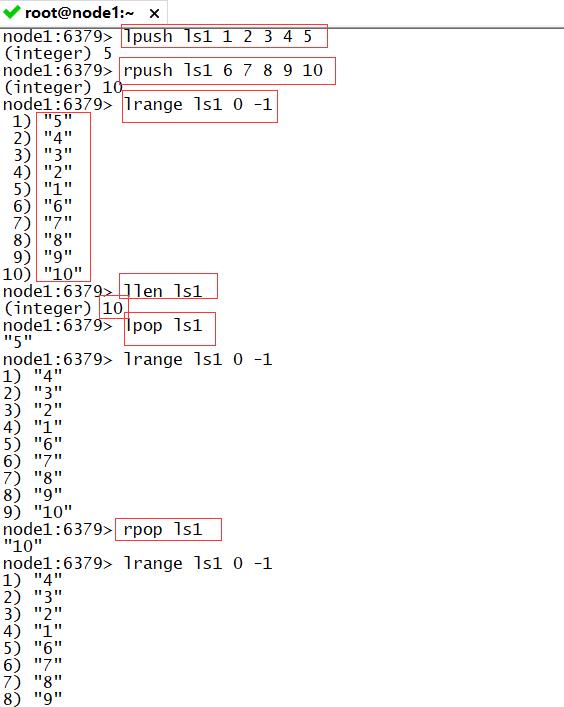
-
lpush:将每个元素放到集合的左边,左序放入
- 语法:lpush K e1 e2 e3…
-
rpush:将每个元素放到集合的右边,右序放入
- 语法:rpush K e1 e2 e3…
-
lrange:通过下标的范围来获取元素的数据
- 语法:lrange K start end
- 注意:从左往右的下标从0开始,从右往左的下标从-1开始,一定是从小的到大的下标
- lrange K 0 -1:所有元素
-
llen:统计集合的长度
- 语法:llen K
-
lpop:删除左边的一个元素
- 语法:lpop K
-
rpop:删除右边的一个元素
- 语法:rpop K
5.Set类型的常用命令
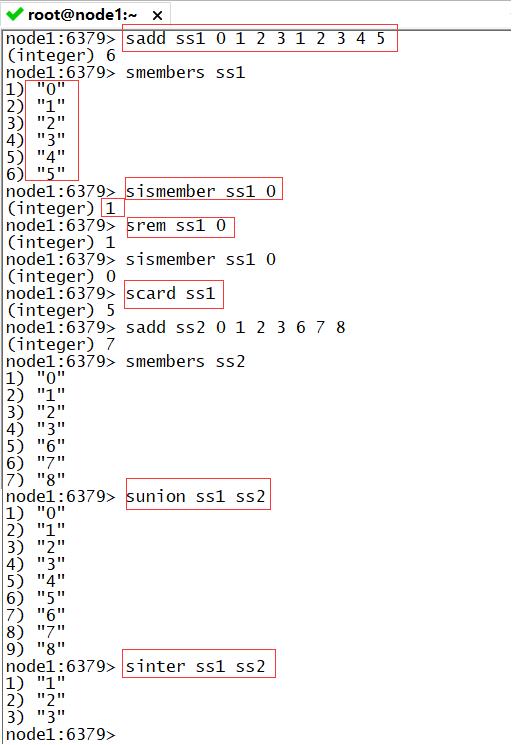
-
sadd:用于添加元素到Set集合中
- 语法:sadd K e1 e2 e3 e4 e5…
-
smembers:用于查看Set集合的所有成员
- 语法:smembers K
-
sismember:判断是否包含这个成员
- 语法:sismember K e1
-
srem:删除其中某个元素
- 语法:srem K e
-
scard:统计集合长度
- 语法:scard K
-
sunion:取两个集合的并集
- 语法:sunion K1 K2
-
sinter:取两个集合的交集
- 语法:sinter K1 K2
6.Zset类型的常用命令
-
zadd:用于添加元素到Zset集合中
- 语法:zadd K score1 k1 score2 k2 …
-
zrange:范围查询
- 语法:zrange K start end [withscores]
-
zrevrange:倒序查询
- 语法:zrevrange K start end [withscores]
-
zrem:移除一个元素
- 语法:zrem K k1
-
zcard:统计集合长度
- 语法:zcard K
-
zscore:获取评分
- 语法:zscore K k
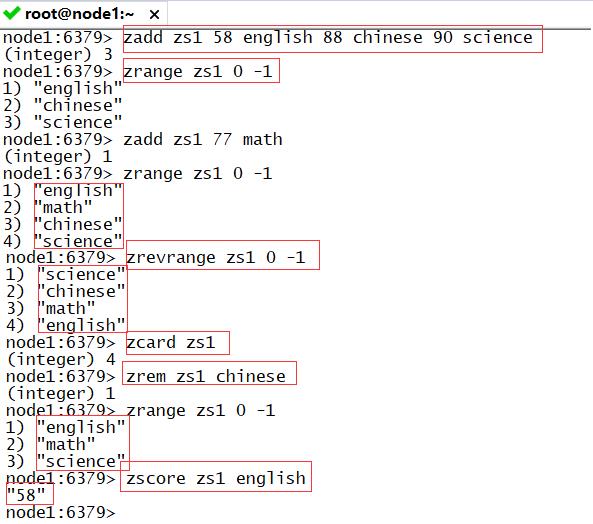
7.BitMap类型的常用命令
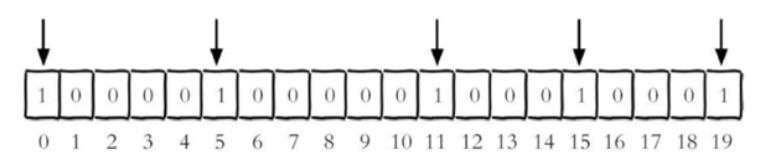
功能:通过一个String对象的存储空间,来构建位图,用每一位0和1来表示状态

-
Redis中一个String最大支持512M = 2^32次方,1字节 = 8位
-
使用时,可以指定每一位对应的值,要么为0,要么为1,默认全部为0
-
用下标来标记每一位,第一个位的下标为0
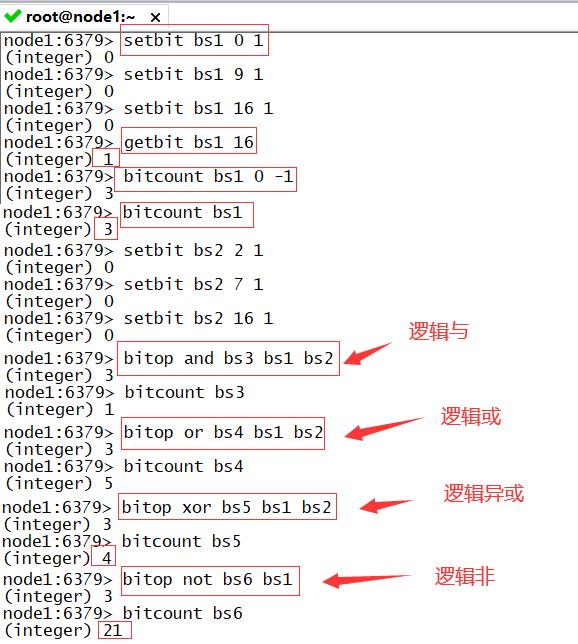
setbit:修改某一位的值
- 语法:setbit bit1 位置 0/1
getbit:查看某一位的值
- 语法:getbit K 位置
bitcount:用于统计位图中所有1的个数
- 语法:bitcount K [start end]
- 注:start end代表的是字节,0代表前8位,1代表9到16位
bitop:用于位图的运算:and/or/not/xor
- 语法:bitop and/or/xor/not bitrs bit1 bit2
- 注:除了 not 操作之外,其他操作都可以接受一个或多个 key 作为输入
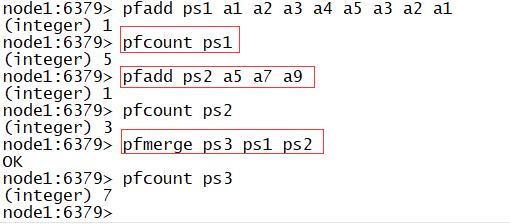
8.HyperLogLog类型的常用命令
功能:类似于Set集合,用于实现数据数据的去重
- 区别:底层实现原理不一样
- 应用:适合于数据量比较庞大的情况下的使用,存在一定的误差率
pfadd:用于添加元素
- 语法:pfadd K e1 e2 e3…
pfcount:用于统计个数
- 语法:pfcount K
pfmerge:用于实现集合合并
- 语法:pfmerge pfrs pf1 pf2…
六、Jedis
1.Jedis依赖
<properties>
<jedis.version>3.2.0</jedis.version>
</properties>
<dependencies>
<!-- Jedis 依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${jedis.version}</version>
</dependency>
<!-- JUnit 4 依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
2.构建连接
import org.junit.After;
import org.junit.Before;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisClientTest {
//构建连接
Jedis jedis = null;
@Before
public void getConnection(){
//方式一:直接构建一个连接对象
//实例化一个客户端连接对象,指定服务端地址
// jedis = new Jedis("node1",6379);
//方式二:通过连接池来构建连接
//构建连接池,并且配置连接池属性
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);//最大连接数
jedisPoolConfig.setMaxIdle(10);//最大空闲连接
jedisPoolConfig.setMaxWaitMillis(1500);//最大等待时间
//构建连接池:连接池配置对象,主机名,端口
JedisPool jedisPool = new JedisPool(jedisPoolConfig,"node1",6379);
//从连接池中获取连接对象
jedis = jedisPool.getResource();
}
//释放连接
@After
public void close(){
jedis.close();
}
}
3.Jedis:String操作
@Test
public void stringTest() {
jedis.set("s1", "hadoop");
String s1 = jedis.get("s1");
System.out.println(s1);
jedis.set("s2", "2");
jedis.incr("s2");
String s2 = jedis.get("s2");
System.out.println(s2);
jedis.expire("s2", 20);
// while(true){
// System.out.println(jedis.ttl("s2"));
// }
System.out.println(jedis.exists("s1"));
System.out.println(jedis.exists("s2"));
jedis.setex("s2", 10, "hive");
}
4.Jedis:Hash操作
@Test
public void hashTest(){
jedis.hset("hs1","name","zhangsan");
String name = jedis.hget("hs1", "name");
System.out.println(name);
System.out.println("-------------------------------------");
Map<String,String> maps = new HashMap<>();
maps.put("age","20");
maps.put("sex","male");
jedis.hmset("hs1",maps);
List<String> hmget = jedis.hmget("hs1", "name", "age", "sex");
System.out.println(hmget);
Map<String, String> map = jedis.hgetAll("hs1");
System.out.println(map);
for(Map.Entry map1 : map.entrySet()){
System.out.println(map1.getKey()+"\\t"+map1.getValue());
}
jedis.hdel("hs1","name");
Long l1 = jedis.hlen("hs1");
System.out.println(l1);
System.out.println(jedis.hexists("hs1","name"));
System.out.println(jedis.hexists("hs1","age"));
}
5.Jedis:List操作
@Test
public void listTest(){
jedis.lpush("ls1","1","2","3","4");
jedis.rpush("ls1","5","6","7","8");
List<String> ls1 = jedis.lrange("ls1", 0, -1);
System.out.println(ls1);
System.out.println(jedis.llen("ls1"));
jedis.lpop("ls1");
jedis.rpop("ls1");
System.out.println(jedis.lrange("ls1",0,-1));
}
6.Jedis:Set操作
@Test
public void setTest(){
jedis.sadd("ss1","1","4","5","4");
jedis.sadd("ss1","1","1","6","6");
Set<String> ss1 = jedis.smembers("ss1");
System.out.println(ss1);
System.out.println(jedis.sismember("ss1","2"));
System.out.println(jedis.sismember("ss1","1"));
System.out.println(jedis.scard("ss1"));
jedis.srem("ss1","1");
System.out.println(jedis.sismember("ss1","1"));
}
7.Jedis:Zset操作
@Test
public void zsetTest(){
jedis.zadd("zs1",20,"chinese");
jedis.zadd("zs1",99,"english");
jedis.zadd("zs1",30,"science");
Set<String> zs1 = jedis.zrange("zs1", 0, -1);
Set<Tuple> zset2 = jedis.zrevrangeWithScores("zs1", 0, -1);
System.out.println(zs1);
System.out.println(jedis.zcard("zs1"));
jedis.zrem("zs1","english");
System.out.println(jedis.zrevrangeWithScores("zs1", 0, -1));
}
以上是关于Redis:Redis基础知识 01的主要内容,如果未能解决你的问题,请参考以下文章