机器学习——“决策树&随机森林”学习笔记
Posted super尚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——“决策树&随机森林”学习笔记相关的知识,希望对你有一定的参考价值。
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。
决策树算法的核心是要解决两个问题:
1)如何从数据表中找出最佳节点和最佳分枝?
2)如何让决策树停止生长,防止过拟合?
决策树的步骤:
1.实例化
2.训练模型
3.导入测试集进行测试
clf = DecisionTreeClassifier()
clf = clf.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
- 将数据转化成一棵树,要找到最佳节点和分支的衡量标准是“不纯度”。不纯度越低,决策树拟合效果越好。
- 每个子节点都有一个不纯度,子节点不纯度一定低于父节点,所以叶节点不纯度最低。
不纯度计算指标:
entropy-信息熵
gini-基尼系数
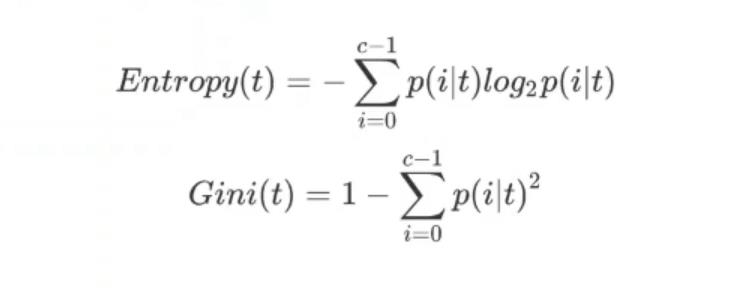
- t表示给定的节点,i代表标签的任意分类。p(i|t)代表标签分类i再节点t上所占的比例
- 相对于基尼系数信息熵对不纯度更加敏感,信息熵计算稍慢,有对数
- 对于高维数据或者噪声很多的数据,信息熵很容易过拟合
训练的数据顺序要放对:x_train,x_test,y_train,y_test
#30%测试,剩下的训练
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
关于随机森林的一些参数可以参考我的另一篇文章:
sklearn——随机森林RandomForestClassifier的参数含义
准确率(precision)
召回率(recall)
准确率是指预测结果属于某一类的个体,实际属于该类的比例。召回率是被正确预测为某类的个体,与数据集中该类个体总数的比例。
n_estimators
这是森林中树木的数量,即基基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators
越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林
的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来
越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
(调参必看)随机森林中模型参数对模型的影响程度。

以上是关于机器学习——“决策树&随机森林”学习笔记的主要内容,如果未能解决你的问题,请参考以下文章