Scrapy爬虫框架总结
Posted amcomputer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy爬虫框架总结相关的知识,希望对你有一定的参考价值。
python的Scrapy爬虫框架有5个大部件,细分的话有7个小部件。框架隔一段时间不用就会忘记很多知识点,学了好几遍了,老是忘记一些常用的数据扭转逻辑,因此写下该博文,以期帮助后续爬虫学习和开发。同时,时间长了容易忘记这些部件,因此尝试对scrapy爬虫框架进行总结。
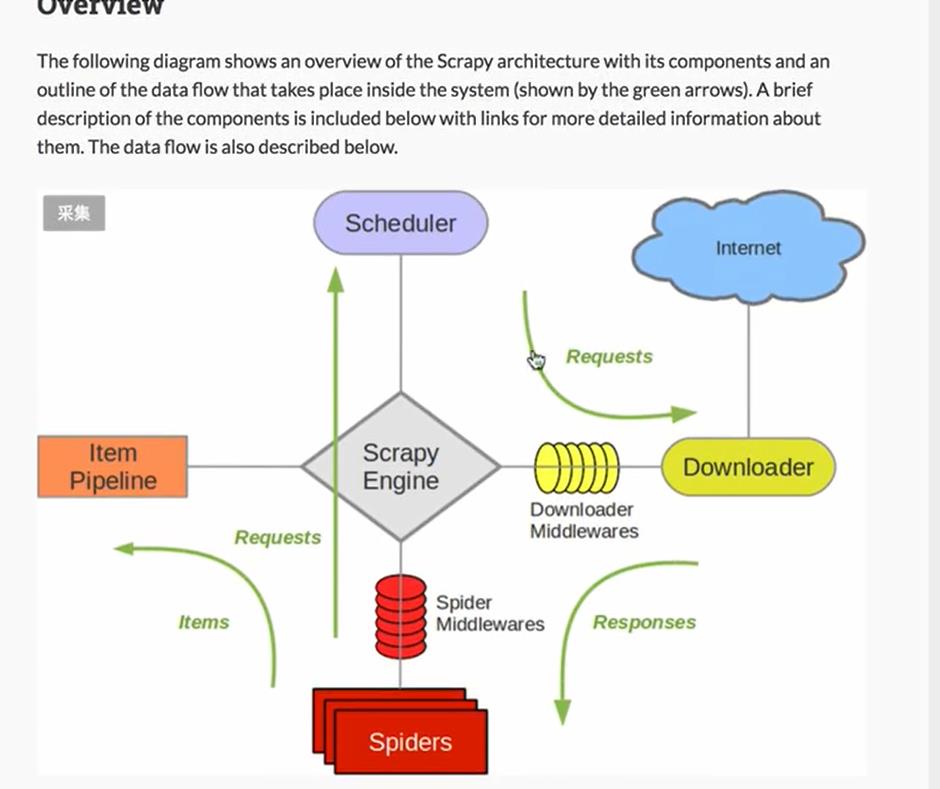
一 理解数据流图
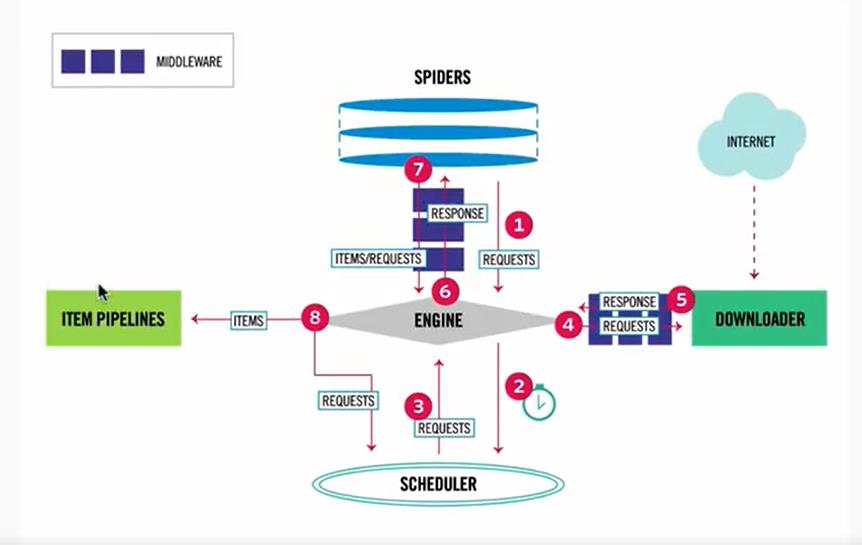
理解数据流图后,可以对Scrapy框架进行总体上的把稳和理解,方便后续对组件的理解。

二 理解部件功能
按照数据流图扭转步骤介绍:
Spiders:功能:1发送请求url,2解析response 里面要写具体的解析过程,用parse(response)方法实现,常用Xpath或者CSS进行解析
Scrapy Engine:负责协同各部件,类似于大S脑。数据传递都需要经过他。
Scheduler: 调度器,负责request请求调度
Donloader Middlewares: 下载中间件。负责真正请求前的预处理工作,比如添加User-agent,cookie或者代理,超时异常处理等等,里面的类主要有3个方法。
process_request(request,spider) 处DOWNLOADER_MIDDLEWARES理请求
process_response(request,response,spider)处理响应
process_exception(request,exceptionspider)处理异常。对于里面的 Middlewares类需要注意它们的执行优先级(DOWNLOADER_MIDDLEWARES)和顺序(Egine在左,Downloader在右边)
Spider Middlewares: 蜘蛛中间间。
Iteam pipeline: 主要有2个功能,第一个是定义爬取数据结构(需要继承scrapy.Item),
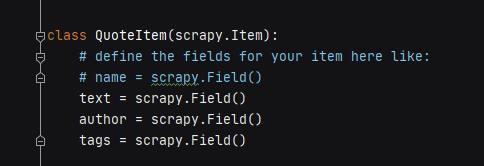
第二个是保存数据入数据库或者数据清洗。里面的pIpeline类主要实现3个方法,类执行顺序也有优先级(参考Donloader Middlewares)
process_spider(spider), 必须实现的方法。
open_spider(spider), process_spider执行前执行该函数,用来初始化操作
close_spider(spider), process_spider执行后执行该函数,用来完成操作,如关闭数据库等等
from_crawler(cls, crawler), 获取全局参数,帮助open_spider(spider),完成初始化
以上是关于Scrapy爬虫框架总结的主要内容,如果未能解决你的问题,请参考以下文章
python scrapy爬虫框架概念介绍(个人理解总结为一张图)