ElasticSearches 使用function_score及soft_score定制搜索结果的分数
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearches 使用function_score及soft_score定制搜索结果的分数相关的知识,希望对你有一定的参考价值。

1.概述
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
概述转载并且补充:使用function_score及soft_score定制搜索结果的分数
太难了,没认真看
https://blog.csdn.net/lijingjingchn/article/details/106405577
https://www.yuque.com/luxiaojun/sau1l2/ly8sxo
我们将介绍使用function_score的基础知识,并介绍一些function core技术非常有用和有效的用例。
介绍
评分的概念是任何搜索引擎(包括Elasticsearch)的核心。评分可以粗略地定义为:找到符合一组标准的数据并按相关性顺序将其返回。相关性通常是通过类似TF-IDF的算法来实现的,该算法试图找出文本上与提交的查询最相似的文档。尽管TF-IDF及其表亲(例如BM25)非常棒,但有时必须通过其他算法或通过其他评分启发式方法来解决相关性问题。在这里,Elasticsearch的script_score和function_score功能变得非常有用。本文将介绍这些工具的用法。
文本相似性不是最重要因素的一个域示例是地理搜索。如果正在寻找在给定点附近的好咖啡店,则按与查询在文本上的相似程度对咖啡店进行排名对用户而言不是很有用,但按地理位置在附近的排名对他们。
另一个示例可能是视频共享站点上的视频,其中搜索结果可能应该考虑视频的相对受欢迎程度。如果某个流行歌星上传了具有给定标题的视频,从而获得了数百万的观看次数,那么该视频可能应该比具有相似文字相关性的不受欢迎的视频更胜一筹。
在使用Elasticsearch进行全文搜索的时候,默认是使用BM25计算的_score字段进行降序排序的。当我们需要用其他字段进行降序或者升序排序的时候,可以使用sort字段,传入我们想要的排序字段和方式。 当简单的使用几个字段升降序排列组合无法满足我们的需求的时候,我们就需要自定义排序的特性,Elasticsearch提供了function_score的DSL来自定义打分,这样就可以根据自定义的_score来进行排序。
在实际的使用中,我们必须注意的是:soft_score和function_score是耗资源的。您只需要计算一组经过过滤的文档的分数。
下面我们来用一个例子来具体说明如何来通过script_core和function_core来定制我们的分数。
准备数据
我们首先来下载我们的测试数据:
git clone https://github.com/liu-xiao-guo/best_games_json_data
然后我们通过Kibana把这个数据来导入到我们的Elasticsearch中:
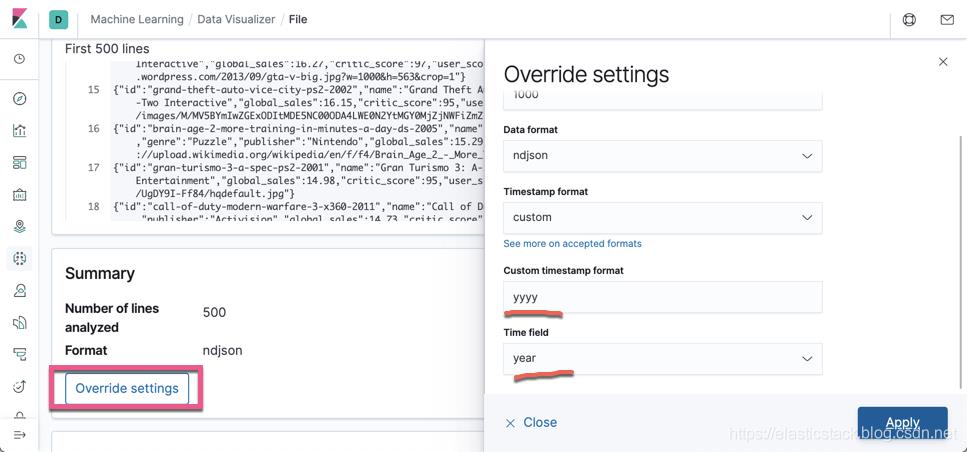
在导入的过程中,我们选择Time field为year,并且指定相应的日期格式:
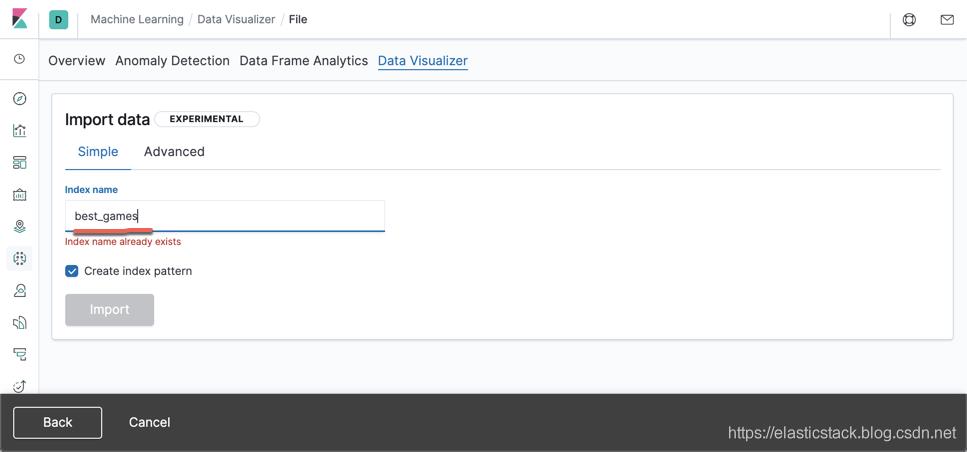
我们指定我们的索引名字为best_games:
我们可以查看一下一个样本的文档就像是下面的格式一样:
"_source" : {
"global_sales" : 82.53,
"year" : 2006,
"image_url" : "https://upload.wikimedia.org/wikipedia/en/thumb/e/e0/Wii_Sports_Europe.jpg/220px-Wii_Sports_Europe.jpg",
"platform" : "Wii",
"@timestamp" : "2006-01-01T00:00:00.000+08:00",
"user_score" : 8,
"critic_score" : 76,
"name" : "Wii Sports",
"genre" : "Sports",
"publisher" : "Nintendo",
"developer" : "Nintendo",
"id" : "wii-sports-wii-2006"
}
在上面我们可以看出来这个文档里有两个很重要的字段:critic_score及user_score。一个是表示这个游戏的难度,另外一个表示游戏的受欢迎的程度。
正常查询
首先我们来看看如果不使用任何的分数定制,那么情况是怎么样的。
GET best_games/_search
{
"_source": [
"name",
"critic_score",
"user_score"
],
"query": {
"match": {
"name": "Final Fantasy"
}
}
}
在上面的查询中,为了说明问题的方便,在返回的结果中,我们只返回name, critic_score和user_score字段。我们在name字段里含有“Final Fantasy”的所有游戏,那么显示显示的结果是:
"hits" : [
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "2qccJ28BCSSrjaXdSOnC",
"_score" : 8.138414,
"_source" : {
"user_score" : 9,
"critic_score" : 92,
"name" : "Final Fantasy VII"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6KccJ28BCSSrjaXdSOnC",
"_score" : 8.138414,
"_source" : {
"user_score" : 8,
"critic_score" : 92,
"name" : "Final Fantasy X"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6qccJ28BCSSrjaXdSOnC",
"_score" : 8.138414,
"_source" : {
"user_score" : 8,
"critic_score" : 90,
"name" : "Final Fantasy VIII"
}
},
...
从上面的结果中,我们可以看出来Final Fantasy VII是最匹配的结果。它的分数是最高的。
Soft_score 查询
加入我们我们是游戏的运营商,那么我们也许我们自己想要的排名的方法。比如,虽然所有的结果都很匹配,但是我们也许不只单单是匹配Final Fantasy,而且我们想把user_score和critic_score加进来(虽然你可以使用其中的一个)。我们想这样来算我们的分数。
最终
score = score*(user_score*10 + critic_score)/2/100
也就是我们把user_score乘以10,从而变成100分制。它和critic_score加起来,然后除以2,并除以100,这样就得出来最后的分数的加权系数。这个加权系数再乘以先前在上一步得出来的分数才是最终的分数值。经过这样的改造后,我们发现我们的分数其实不光是全文搜索的相关性,同时它也紧紧地关联了我们的用户体验和游戏的难道系数。
那么我们如何使用这个呢?
参照Elastics的官方文档soft_score,我们现在做如下的搜索:
GET best_games/_search
{
"_source": [
"name",
"critic_score",
"user_score"
],
"query": {
"script_score": {
"query": {
"match": {
"name": "Final Fantasy"
}
},
"script": {
"source": "_score * (doc['user_score'].value*10+doc['critic_score'].value)/2/100"
}
}
}
}
在上面的查询中,我们可以看到我们使用了新的公式:
"script": {
"source": "_score * (doc['user_score'].value*10+doc['critic_score'].value)/2/100"
}
那么我查询后的结果为:
"hits" : [
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "2qccJ28BCSSrjaXdSOnC",
"_score" : 7.405957,
"_source" : {
"user_score" : 9,
"critic_score" : 92,
"name" : "Final Fantasy VII"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "K6ccJ28BCSSrjaXdSOrC",
"_score" : 7.0804205,
"_source" : {
"user_score" : 8,
"critic_score" : 94,
"name" : "Final Fantasy IX"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6KccJ28BCSSrjaXdSOnC",
"_score" : 6.9990363,
"_source" : {
"user_score" : 8,
"critic_score" : 92,
"name" : "Final Fantasy X"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6qccJ28BCSSrjaXdSOnC",
"_score" : 6.917652,
"_source" : {
"user_score" : 8,
"critic_score" : 90,
"name" : "Final Fantasy VIII"
}
},
...
我们从上面可以看出来最终的分数_score是完全不一样的值。我们同时也看出来尽管第一名的Final Fantasy VII没有发生变化,但是第二名的位置由Final Fantasy X变为Final Fantasy IX了。
针对script的运算,有一些预定义好的函数可以供我们调用,它们可以帮我们加速我们的计算。
Saturation
Sigmoid
Random score function
Decay functions for numeric fields
Decay functions for geo fields
Decay functions for date fields
Functions for vector fields
我们可以参考Elastic的官方文档来帮我们更深入地了解。
Function score 查询
function_score允许您修改查询检索的文档分数。 例如,如果分数函数在计算上很昂贵,并且足以在过滤后的文档集上计算分数,则此功能很有用。
要使用function_score,用户必须定义一个查询和一个或多个函数,这些函数为查询返回的每个文档计算一个新分数。
function_score可以只与一个函数一起使用,比如:
GET /_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"boost": "5",
"random_score": {},
"boost_mode": "multiply"
}
}
}
这里它把所有的文档的分数由5和一个由random_score (返回0到1之间的值)相乘而得到。那么这个分数就是一个从0到5之间的一个数值:
"hits" : [
{
"_index" : "chicago_employees",
"_type" : "_doc",
"_id" : "Hrz0_W4BDM8YqwyDD06A",
"_score" : 4.9999876,
"_source" : {
"Name" : "ADKINS, WILLIAM J",
"Job Titles" : "SUPERVISING FIRE COMMUNICATIONS OPERATOR",
"Department" : "OEMC",
"Full or Part-Time" : "F",
"Salary or Hourly" : "Salary",
"Annual Salary" : 121472.04
}
},
{
"_index" : "kibana_sample_data_logs",
"_type" : "_doc",
"_id" : "eXNIHm8BjrINWI3xYF0J",
"_score" : 4.9999495,
"_source" : {
"agent" : "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (Khtml, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes" : 6630,
"clientip" : "77.5.51.49",
"extension" : "",
"geo" : {
"srcdest" : "CN:ID",
...
尽管这个分数没有多大实际的意思,但是它可以让我们每次进入一个网页看到不同的文档,而不是严格按照固定的匹配而得到的固定的结果。
我们也可以配合soft_score一起来使用function_score:
GET best_games/_search
{
"_source": [
"name",
"critic_score",
"user_score"
],
"query": {
"function_score": {
"query": {
"match": {
"name": "Final Fantasy"
}
},
"script_score": {
"script": "_score * (doc['user_score'].value*10+doc['critic_score'].value)/2/100"
}
}
}
}
那么显示的结果是:
"hits" : [
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "2qccJ28BCSSrjaXdSOnC",
"_score" : 60.272747,
"_source" : {
"user_score" : 9,
"critic_score" : 92,
"name" : "Final Fantasy VII"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "K6ccJ28BCSSrjaXdSOrC",
"_score" : 57.623398,
"_source" : {
"user_score" : 8,
"critic_score" : 94,
"name" : "Final Fantasy IX"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6KccJ28BCSSrjaXdSOnC",
"_score" : 56.96106,
"_source" : {
"user_score" : 8,
"critic_score" : 92,
"name" : "Final Fantasy X"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6qccJ28BCSSrjaXdSOnC",
"_score" : 56.29872,
"_source" : {
"user_score" : 8,
"critic_score" : 90,
"name" : "Final Fantasy VIII"
}
},
...
细心的读者可能看出来了。我们的分数和之前的那个soft_score结果是不一样的,但是我们搜索的结果的排序是一样的。
在上面的script的写法中,我们使用了硬编码,也就是把10硬写入到script中了。假如有一种情况,我将来想修改这个值为20或其它的值,重新看看查询的结果。由于script的改变,需要重新进行编译,这样的效率并不高。一种较好的办法是如下的写法:
GET best_games/_search
{
"_source": [
"name",
"critic_score",
"user_score"
],
"query": {
"script_score": {
"query": {
"match": {
"name": "Final Fantasy"
}
},
"script": {
"params":{
"multiplier": 10
},
"source": "_score * (doc['user_score'].value*params.multiplier+doc['critic_score'].value)/2/100"
}
}
}
}
脚本编译被缓存以加快执行速度。 如果脚本具有需要考虑的参数,则最好重用相同的脚本并为其提供参数。
boost_mode
boost_mode是用来定义最新计算出来的分数如何和查询的分数来相结合的。
mulitply 查询分数和功能分数相乘(默认)
replace 仅使用功能分数,查询分数将被忽略
sum 查询分数和功能分数相加
avg 平均值
max 查询分数和功能分数的最大值
min 查询分数和功能分数的最小值
field_value_factor
field_value_factor函数使您可以使用文档中的字段来影响得分。 与使用script_score函数类似,但是它避免了脚本编写的开销。 如果用于多值字段,则在计算中仅使用该字段的第一个值。
例如,假设您有一个用数字likes字段索引的文档,并希望通过该字段影响文档的得分,那么这样做的示例如下所示:
GET /_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "likes",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
}
}
}
上面的function_score将根据field_value_factore按照如下的方式来计算分数:
sqrt(1.2 * doc['likes'].value)
field_value_factor函数有许多选项:
- field 要从文档中提取的字段。
- factor 字段值乘以的可选因子,默认为1。
- modifier 应用于字段值的修饰符可以是以下之一:
none,log,log1p,log2p,ln,ln1p,ln2p,平方,sqrt或reciprocal。 默认为无。 - missing 如果文档没有该字段,则使用该值。 就像从文档中读取一样,修饰符和因数仍然适用于它。
针对我们的例子,我们也可以使用如下的方法来重新计算分数:
GET best_games/_search
{
"_source": [
"name",
"critic_score",
"user_score"
],
"query": {
"function_score": {
"query": {
"match": {
"name": "Final Fantasy"
}
},
"field_value_factor": {
"field": "user_score",
"factor": 1.2,
"modifier": "none",
"missing": 1
}
}
}
}
在上面的例子里,我们使用user_score字段,并把这个字段的factor设置为1.2。这样加大这个字段的重要性。重新进行搜索:
"hits" : [
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "2qccJ28BCSSrjaXdSOnC",
"_score" : 87.89488,
"_source" : {
"user_score" : 9,
"critic_score" : 92,
"name" : "Final Fantasy VII"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6KccJ28BCSSrjaXdSOnC",
"_score" : 78.128784,
"_source" : {
"user_score" : 8,
"critic_score" : 92,
"name" : "Final Fantasy X"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "6qccJ28BCSSrjaXdSOnC",
"_score" : 78.128784,
"_source" : {
"user_score" : 8,
"critic_score" : 90,
"name" : "Final Fantasy VIII"
}
},
{
"_index" : "best_games",
"_type" : "_doc",
"_id" : "K6ccJ28BCSSrjaXdSOrC",
"_score" : 78.128784,
"_source" : {
"user_score" : 8,
"critic_score" : 94,
"name" : "Final Fantasy IX"
}
},
...
我们可以看出来我们的分数又有些变化。而且排序也有变化。
functions
上面的例子中,每一个doc都会乘以相同的系数,有时候我们需要对不同的doc采用不同的权重。这时,使用functions是一种不错的选择。几个function可以组合。 在这种情况下,可以选择仅在文档与给定的过滤查询匹配时才应用该function:
GET /_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"boost": "5",
"functions": [
{
"filter": {
"match": {
"test": "bar"
}
},
"random_score": {},
"weight": 23
},
{
"filter": {
"match": {
"test": "cat"
}
},
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 42
}
}
}
上面的boost为5,也即所有的文档的加权都是5。我们同时也看到几个定义的functions。它们是针对相应的匹配的文档分别进行加权的。如果匹配了,就可以乘以相应的加权。
针对我们的例子,我们也可以做如下的实验。
GET best_games/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "Final Fantasy"
}
},
"boost": "1",
"functions": [
{
"filter": {
"match": {
"name": " XIII"
}
}