python自动化web自动化:5.测试框架实战一通用方法封装配置文件basepage基类封装
Posted new nm个对象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python自动化web自动化:5.测试框架实战一通用方法封装配置文件basepage基类封装相关的知识,希望对你有一定的参考价值。
我们以百度搜索功能为例来实战讲解测试框架的搭建。
一.创建框架目录
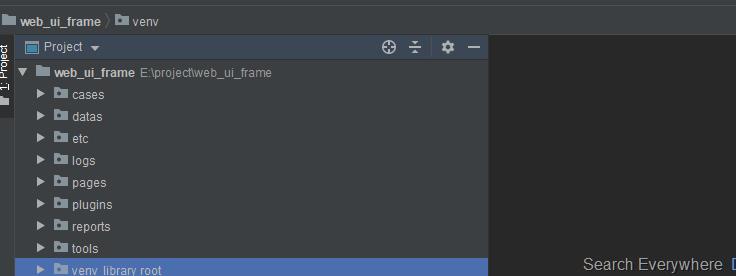
- cases:用例文件管理目录
- datas:用例数据文件管理目录
- etc:配置文件管理目录
- logs:日志目录
- pages:pageobject文件管理目录
- plugins:第三方插件管理目录,例如存放chromedriver.exe文件
- reports:测试报告目录
- tools:通用方法代码文件管理目录
二.完成通用方法的封装
在编写测试用例代码前,我们可以先完成日志打印,文件读取等公共方法的封装。供后续用例编写时使用。
(1)日志方法封装
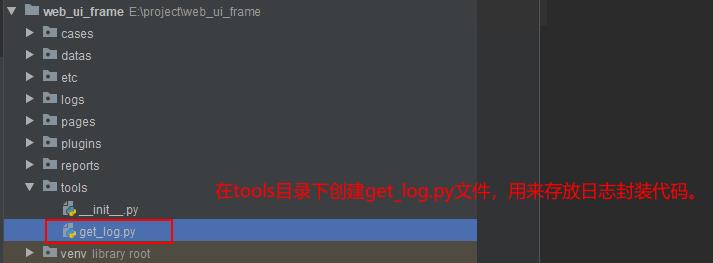
# filename:get_log.py
#! /usr/bin/python
# -*- coding: utf-8 -*-
import logging
class GetLog:
"""
自定义logging类
方法:1.get_logger:获取一个Logger对象。
"""
def get_logger(self, name, level, fromt, path):
"""
获取Logger对象。
:param name: Logger名字。
:param level: Logger级别。
:param fromt: Logger日志输出级别。
:param path: 日志文件路径。
:return: Logger对象
"""
self.logger = logging.getLogger(name=name)
self.logger.setLevel(logging.DEBUG)
if not self.logger.hasHandlers():
# 给Logger添加一个FileHandler
file_handler = logging.FileHandler(filename=path,encoding='utf-8')
file_handler.setLevel(level=level)
file_handler.setFormatter(fmt=fromt)
self.logger.addHandler(file_handler)
# 给Logger添加一个FileHandler
stream_handler = logging.StreamHandler()
stream_handler.setLevel(level=level)
stream_handler.setFormatter(fmt=fromt)
self.logger.addHandler(stream_handler)
return self.logger
以后我们需要使用日志时,只需要调用GetLog().get_logger()方法即可。
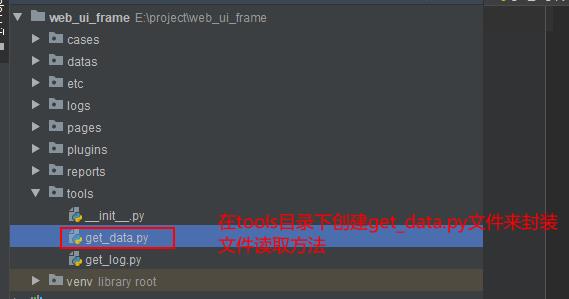
(2)文件读取方法封装
自动化测试中,我们常常将用例数据等单独存放在数据文件中以便维护,所以文件读取在自动化测试中运用十分频繁。我们可以将文件读取方法单独封装出来,供我们使用。
#! /usr/bin/python
# -*- coding: utf-8 -*-
from configparser import ConfigParser
import yaml
def get_data_from_ini(path,node,key):
"""
封装:获取element.ini文件方法
:param path: ini文件路径。
:param node: 需要查找内容所在的node。
:param key: 需要查找内容所在的key。
:return:
"""
target = ConfigParser()
target.read(path,encoding='utf-8')
result = target.get(node,key)
result = result.split('|') # 使用"|"完成字符串分割,返回一个列表。
return result
def get_data_from_yaml(path):
"""
获取指定yaml文件的内容
:param path: yaml文件路径。
:return:
"""
with open(path,'r',encoding='utf-8') as f:
result = yaml.safe_load(f)
return result
这里我们只封装了ini,yaml文件的读取方法,后续如果需要读取其他文件,可以继续封装对应方法即可。
(3)获取项目根路径方法封装
在项目中我们需要使用项目根目录来拼接文件路径。但是如果我们的项目文件放在不同的目录,项目根路径也会不同,所以我们可以将获取根路径的方法单独封装出来。

#! /usr/bin/python
# -*- coding: utf-8 -*-
import os
def get_base_dir(dir_name):
"""
获取项目根路径
:param dir_name: 项目根目录名字。
:return:
"""
now_dir = os.getcwd() # 获取当前文件的路径,相当于pwd
while True:
now_dir_list = os.path.split(now_dir)
now_dir = now_dir_list[0]
if now_dir_list[1] == dir_name:
now_dir = os.path.join(now_dir_list[0], now_dir_list[1])
break
return now_dir
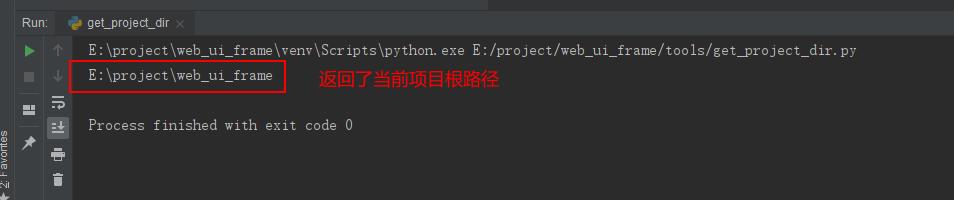
if __name__ == "__main__":
print(get_base_dir('web_ui_frame'))
运行结果如下:
(4)获取时间戳
我们在生成日志文件和测试报告时,往往需要添加时间戳。所以我们可以将生成时间戳的方法也单独出来。
#! /usr/bin/python
# -*- coding: utf-8 -*-
from datetime import datetime
def get_now_time():
"""
获取当前时间字符串
:return:
"""
now = datetime.now().strftime('%Y-%m-%d-%H%M%S')
return now
if __name__ == "__main__":
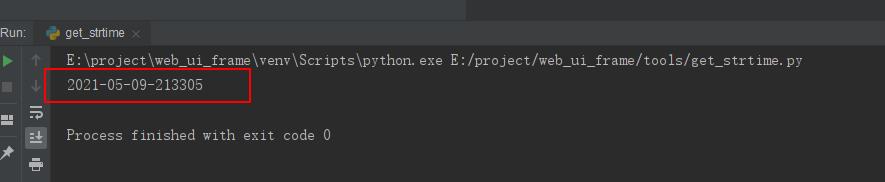
print(get_now_time())
运行结果如下:
三.config文件设置
在自动化开发过程中,我们可以将一些全局变量写在配置文件中方便我们以下更改维护。例如:日志级别,日志文件路径,数据文件路径等。
#! /usr/bin/python
# -*- coding: utf-8 -*-
# 项目根路径
import logging
from tools.get_project_dir import get_base_dir
BASEDIR = get_base_dir(dir_name='web_ui_frame')
# 日志设置
import os
from tools.get_log import GetLog
from tools.get_strtime import get_now_time
LOG_NAME = 'ROOT'
LOG_PATH = os.path.join(BASEDIR,f'logs/{get_now_time()}.log')
LOG_LEVEL = logging.INFO
LOG_FORMAT = logging.Formatter('%(asctime)s-%(levelname)s-%(message)s-%(filename)s-%(lineno)d-%(funcName)s')
# 实例化以后Logger对象
LOGGER = GetLog().get_logger(name=LOG_NAME, level=LOG_LEVEL, fromt=LOG_FORMAT, path=LOG_PATH)
后续如果我们有新的全局变量需要添加,可以直接写在config.py文件中即可。
四.basepage类封装
我们在前面讲解过浏览器的公共方法可以封装到basepage类中,供业务的页面page类继承使用,而不是在页面page类中直接使用selenium的接口。这样可以大大增加我们代码的可维护性,可移植性。
#! /usr/bin/python
# -*- coding: utf-8 -*-
import os
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
from etc.config import BASEDIR, LOGGER
class BasePage:
"""
#! /usr/bin/python
# -*- coding: utf-8 -*-
import os
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
from etc.config import BASEDIR, LOGGER
class BasePage:
"""
公共page类,封装浏览器的相关操作方法。
方法:1._get_url: 访问网址
2._find_element: 二次封装,定位页面单个元素方法
3._find_elements: 二次封装,定位页面多个元素方法
4._click_element: 二次封装,点击页面元素的方法
5._send_keys_element: 二次封装,输入内容到页面元素的方法
6._wait_element_to_click: 二次封装,显示等待元素可点击
7._get_title: 二次封装,获取页面title
8._quit_driver: 二次封装,关闭浏览器
9._get_screenshot_as_file: 二次封装:获取页面截图并保存
"""
def __init__(self, driver:WebDriver=None):
"""
构造方法
:param driver:
"""
# 生成一个driver对象
if not driver:
driver_path = os.path.join(BASEDIR,'./plugins/chromedriver.exe')
self._driver = webdriver.Chrome(executable_path=driver_path)
self._driver.maximize_window()
self._driver.implicitly_wait(5)
else:
self._driver = driver
def _get_url(self, url):
"""
二次封装:访问网址方法
:param url: url地址
:return:
"""
try:
self._driver.get(url)
LOGGER.info(f'visit url {url} success')
except Exception as e:
LOGGER.error(f'visit url {url} failed, the reason is {e}')
raise Exception(f'visit url {url} failed')
def _find_element(self, method, message):
"""
二次封装,定位页面单个元素方法
:param method: 定位元素的方法。例如:By.ID
:param message: 元素信息。例如:"kw"
:return:
"""
try:
if method == "id":
ele = self._driver.find_element(By.ID,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == "name":
ele = self._driver.find_element(By.NAME,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == "xpath":
ele = self._driver.find_element(By.XPATH,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == "css":
ele = self._driver.find_element(By.CSS_SELECTOR,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == 'class':
ele = self._driver.find_element(By.CLASS_NAME,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == 'link_text':
ele = self._driver.find_element(By.LINK_TEXT,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == 'partial_link_text':
ele = self._driver.find_element(By.PARTIAL_LINK_TEXT,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
elif method == 'tag_name':
ele = self._driver.find_element(By.TAG_NAME,message)
LOGGER.info(f'find element (method:{method},message:{message}) success')
return ele
except Exception as e:
LOGGER.error(f'find element (method:{method},message:{message}) failed, the reason is {e}')
raise Exception(f'not find element:method={method},message={message}')
def _find_elements(self, method, message):
"""
二次封装,定位页面多个元素方法
:param method: 定位元素的方法。例如:By.ID
:param message: 元素信息。例如:"kw"
:return:
"""
try:
if method == "id":
eles = self._driver.find_elements(By.ID,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == "name":
eles = self._driver.find_elements(By.NAME,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == "xpath":
eles = self._driver.find_elements(By.XPATH,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == "css":
eles = self._driver.find_elements(By.CSS_SELECTOR,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == 'class':
eles = self._driver.find_elements(By.CLASS_NAME,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == 'link_text':
eles = self._driver.find_elements(By.LINK_TEXT,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == 'partial_link_text':
eles = self._driver.find_elements(By.PARTIAL_LINK_TEXT,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
elif method == 'tag_name':
eles = self._driver.find_elements(By.TAG_NAME,message)
LOGGER.info(f'find elements (method:{method},message:{message}) success')
return eles
except Exception as e:
LOGGER.error(f'find elements (method:{method},message:{message}) failed, the reason is {e}')
raise Exception(f'not find elements:method={method},message={message}')
def _click_element(self, ele:WebElement):
"""
二次封装,点击页面元素的方法
:param ele: 待点击的页面元素。
:return:
"""
try:
ele.click()
LOGGER.info(f'click element {ele}')
except Exception as e:
LOGGER.error(f'click element {ele} failed, the reason is {e}')
raise Exception(f'click element {ele} failed')
def _send_keys_element(self, ele:WebElement, text):
"""
二次封装,输入内容到页面元素的方法
:param ele: 页面元素。
:param text: 内容
:return:
"""
try:
ele.send_keys(text)
LOGGER.info(f'send text to element {ele} success')
except Exception as e:
LOGGER.error(f'send text to element {ele} failed, the reason is {e}')
raise Exception(f'send text to element {ele} failed')
def _wait_element_to_click(self, method, message, timeout=20):
"""
二次封装,显示等待元素可点击
:param method: 定位元素的方法。例如:By.ID
:param message: 元素信息。例如:"kw"
:param message: 超时时间,默认为20s
:return:
"""
try:
if method == "id":
ele = WebDriverWait(self._driver,timeout).until(expected_conditions.element_to_be_clickable((By.ID,message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == "name":
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.NAME, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == "xpath":
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.XPATH, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == "css":
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == 'class':
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.CLASS_NAME, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == 'link_text':
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.LINK_TEXT, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == 'partial_link_text':
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.PARTIAL_LINK_TEXT, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
elif method == 'tag_name':
ele = WebDriverWait(self._driver, timeout).until(expected_conditions.element_to_be_clickable((By.TAG_NAME, message)))
LOGGER.info(f'wait element (method:{method} message:{message}) to clickable success')
return ele
except Exception as e:
LOGGER.error(f'wait element (method:{method} message:{message}) to clickable failed, the reason is {e}')
raise Exception(f'wait element (method:{method} message:{message}) to clickable failed')
def _get_title(self):
"""
获取页面title
:return:
"""
try:
title = self._driver.title
LOGGER.info(f'get page title success, title is {title}')
except Exception as e:
LOGGER.error(f'get page title failed, the reason is {e}')
raise Exception(f'get page title failed')
def _quit_driver(self):
"""
关闭浏览器
:return:
"""
try:
self._driver.quit()
LOGGER.info('close broswer success')
except Exception as e:
LOGGER.error(f'close broswer failed, the reason is {e}')
raise Exception('close broswe failed')
def _get_screenshot_as_file(self, path):
"""
截取当前页面
:param path: 保存为图片的路径
:return:
"""
try:
self._driver.get_screenshot_as_file(path)
LOGGER.info(f'get screenshot as file {path} success')
except Exception as e:
LOGGER.error(f'get screenshot as file {path} failed, the reason is {e}')
raise Exception(f'get screenshot as file {path} failed')
我们这里只封装了selenium的部分常用API,如果后续需要使用新的API可以继续在basepage中封装。我们的原理是selenium的原生接口方法是与业务无关的,我们尽量不要使用原生的,而是在basepage中封装一次再使用,这样可以大大增加代码的可维护性和可移植性。
以上是关于python自动化web自动化:5.测试框架实战一通用方法封装配置文件basepage基类封装的主要内容,如果未能解决你的问题,请参考以下文章