机器学习40讲学习笔记-18 从全局到局部:核技巧
Posted bohu83
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习40讲学习笔记-18 从全局到局部:核技巧相关的知识,希望对你有一定的参考价值。
一 序
本文属于极客时间机器学习40讲学习笔记系列。
18 从全局到局部:核技巧
对偶性主要应用在最优决策边界的求解中。这部分的推导过程在https://blog.csdn.net/bohu83/article/details/114198931
我首先要吐槽下,对于小白很难掌握这块,因为数学公式推导要求较高。对比了机器学习40讲,我再看下之前贪心学院的NLP 训练营课程。我会发现文哲老师会站在小白能方便理解的角度去讲,从最简单的SVM从线性分类器导出,根据最大化分类间隔的目标,我们可以得到线性可分问题的SVM训练时求解的问题。但现实应用中很多数据是线性不可分的,通过加入松弛变量和惩罚因子,可以将SVM推广到线性不可分的情况,具体做法是对违反约束条件的训练样本进行惩罚,得到线性不可分的SVM训练时优化的问题。这个优化问题是一个凸优化问题,并且满足Slater条件,因此强对偶成立,通过拉格朗日对偶可以将其转化成对偶问题求解。最后再讲核函数,就跟下面的讲公式,缺乏必要背景知识铺垫,也缺乏图的几何意义辅助理解。机器学习40讲真的对小白太不友好了。
这部分内容我就是整理下,我在看的时候觉得如果数学不好,那就不理解推导过程。推荐看下这篇:https://zhuanlan.zhihu.com/p/82732640
真的有必要结合几何意义去理解。
********************************************************************
当支持向量机用于线性可分的数据时,不同类别的支持向量到最优决策边界的距离之和为
,其中的w 是超平面的线性系数,让间隔
最大化就是让
最小化,所以线性可分的支持向量机对应的最优化问题就是
其中
为数据点
对应的类别,其取值为
这个问题本身是个凸二次规划(convex quadratic programming)问题,借助拉格朗日乘子,这个原问题(primal problem)就可以改写成所谓的广义拉格朗日函数(generalized Lagrange function)
其中每个
都是
的分量。和原来的优化问题相比,除了和决策边界有关的变量 w 和b之外,广义拉格朗日函数还引入了一组不小于 0 的参数
广义拉格朗日函数的最优化可以分成两步:先把
看成
就是只和w,b 有关的函数了。接下来如何确定最优的决策边界参数呢?当参数w,b不满足原问题的约束时大值其实就是不存在,只有符合原问题的要求时,
的最大值才有意义。
那么这个最大值等于多少呢?由于
的符号相反,因此两者之积必然是小于 0 的,所以最大值
原始的最小化问题就被等效为
也就是广义拉格朗日函数的极小极大问题。
让广义拉格朗日函数对决策边界的两个参数w,b 的偏导数为 0,就可以得到
将解出的约束关系先代入到
原函数求出来的是
数学上可证明,上面的过程满足Karush-Kuhn-Tucker 条件(简称 KKT 条件)时,原问题和对偶问题才能殊途同归。支持向量机对原问题和对偶问题之间等价关系的利用就是它的对偶性(duality)。
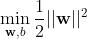
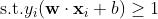
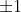
![L({\\bf w}, b, {\\boldsymbol \\alpha}) = \\dfrac{1}{2} || {\\bf w} || ^ 2 + \\sum\\limits_{i = 1}^m \\alpha_i[1 - y_i ({\\bf w} \\cdot {\\bf x}_i + b)]](https://image.cha138.com/20210523/cea9c7e176f24eb6b7252b62d305a8d0.jpg)
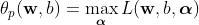

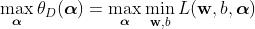
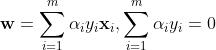
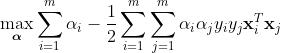
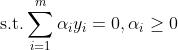
核技巧相关
虽然加入了松弛变量和惩罚因子,但支持向量机还是一个线性模型,只是允许错分样本的存在,这从它的决策函数也可以看出来。接下来要介绍的核映射使得支持向量机成为非线性模型,决策边界不再是线性的超平面,而可以是形状非常复杂的曲面。
核函数
下面补充一个背景知识
从异或问题出发。假设待分类的四个点
分别为
,那么只需要添加一个多项式形式的新属性
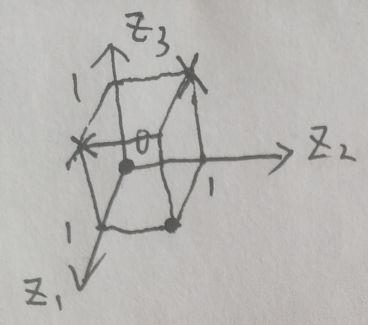
就可以将原来的四个点分别映射为三维空间上的 (0, 0, 0), (0, 1, 1), (1, 0, 1) 和 (1, 1, 0)。这时,在三维空间中只需要将原来的数据平面稍微向上抬一点,就能完美地区分两个类别了。
忍不住再插一句,如果你跟我一样缺乏空间思维,那么看完上面这段话没啥感觉。有个图就不一样了
图1对于对角线的同类数据,没法阿勇一条直线来区分,图2 显然任意一个在底平面和顶平面之间的平面可以解决异或问题的分类。
以下图片来自:https://blog.csdn.net/qq_40061206/article/details/113270412 作者:流动的风与雪
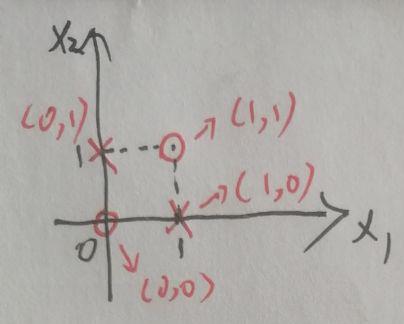
对高维空间上新生成的特征向量进行内积运算,得到的才是真正的核函数(kernel function)。核函数的数学表达式具有如下的形式
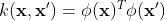
从思想上讲,核方法(kernel method)表示的是将低维空间中的线性不可分问题通常可以转化为高维空间中的线性可分问题的思路;从运算上讲,核技巧(kernel trick)表示的是通过间接定义特征映射来直接计算内积的运算方法。
常用的核函数有以下几种:
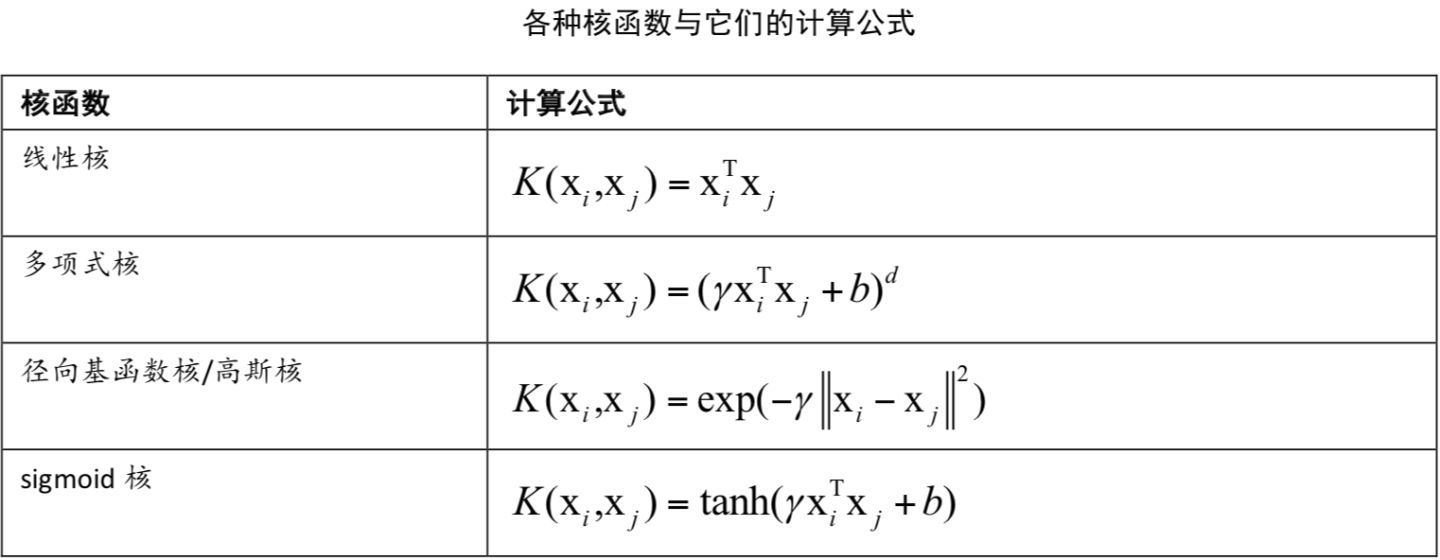
在 Scikit-learn 中设置核函数参数有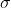 决定了高斯函数的宽度,另一个需要需要设置的是正则化参数C。
决定了高斯函数的宽度,另一个需要需要设置的是正则化参数C。
除了简化内积运算之外,核函数更本质的意义在于对相似性度量(similarity measure)的表示。在直观的认识中,两个数据点相距越近,它们归属于同一类别的可能性就越高。如果将径向基的结果看成数据点相似度的话,那么  和
和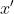 离得越近,两者之间的相似度就越高(接近于 1);反过来离得越远,相似度就越低(接近于 0),将这种逻辑引申一步就可以得到,核函数是实现局部化(localization)的工具.
离得越近,两者之间的相似度就越高(接近于 1);反过来离得越远,相似度就越低(接近于 0),将这种逻辑引申一步就可以得到,核函数是实现局部化(localization)的工具.

以上是关于机器学习40讲学习笔记-18 从全局到局部:核技巧的主要内容,如果未能解决你的问题,请参考以下文章