架构入门 - 高性能篇数据库高性能
Posted 林中轩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构入门 - 高性能篇数据库高性能相关的知识,希望对你有一定的参考价值。
单机高性能与集群高性能都是针对负责计算的服务器而言的,负责存储的数据库服务器因为处理的是数据而不是计算,架构和使用方式又有所不同
SQL - 读写分离
基本原理是将数据库读写操作分散到不同节点上,从而分散读写压力到不同的节点上
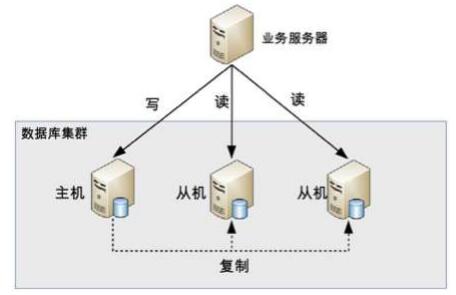
一主一从或一主多从都可以;主机负责读写操作,从机负责读操作,每个机器都需要同时工作;主机通过复制将数据同步到从机,每个节点都存储了所有的数据
复制延迟
mysql的主从复制延迟可能达到1秒,如果有大量数据,1分钟也可能,那么这样很容易造成用户注册了但是无法登陆
一般的解决方法是将关键业务全部指向主机,非关键业务进行读写分离,比如注册登陆都指向主机,修改个人信息就读写分离,即使查询出来的是旧的数据,业务上的影响也不会太大
分配机制
如何将读写操作分开,访问不同的数据库呢?
【1】 程序代码封装
在程序中抽象出一个数据访问层,实现读写操作分离和数据库服务连接的管理,比如

实现简单,但无法通用,每个语言都需要写一个,主从数据库发生切换则需要修改所有系统并重启
【2】 中间件封装
独立出一套系统来,实现读写操作分离和数据库服务连接的管理,中间件对业务服务器提供SQL兼容的协议。业务服务器访问中间件与数据库无差异,如图
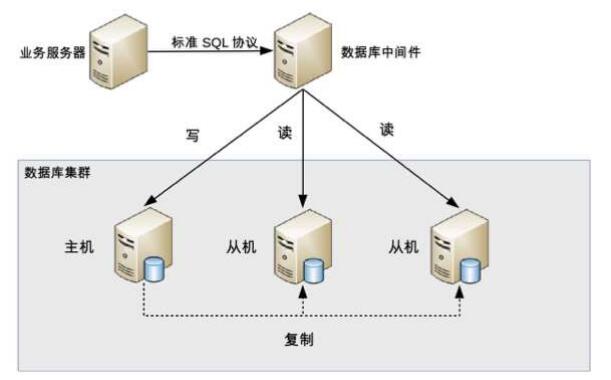
能够支持多种语言,且能够探测服务器主从状态,比如向某个测试表里写个数据,成功就是主机,失败就是从机。但是对应的实现极其复杂,容易出BUG,所有数据库请求都走中间件的话性能是个大问题。一般使用成熟的中间件方案,如MySQL Proxy,Atlas
SQL - 分库分表分区
为什么需要分这么多东西,主要是因为如果在单库或者单表上:
- 数据量太大,即使加了索引,索引也非常大,读写性能太差
- 数据量太大,备份和恢复耗时太长
- 数据库文件太大,导致物理上受影响的可能更大(机房火灾烧了一块,恰好是这个数据库)
分库
为了解决数据量太大,且读写操作太多的问题,分库是按不同的业务模块将数据分散到不同的数据库服务器,比如:

但会存在以下问题:
- 事务问题。在执行分库之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担
- 跨库跨表的join问题。在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成
- 额外的数据管理负担和数据运算压力。额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算
- 成本问题。本来是1台服务器,现在是3台,所以一开始是不需要考虑分库的,除非一开始就是业务特别多,用户量特别大,否则一定要避免初期在开发上的无端开销,以后业务起来之后再分库也不迟
分表
【1】 垂直分表
为了解决表的宽度问题,同时还能分别优化每张单表的处理能力。所以将表结构根据数据的活跃度拆分成多个表,把不常用的字段单独放到一个表、把大字段单独放到一个表、把经常使用的字段放到一个表
复杂度的增加在于操作表的数量会增加,比如以前一条SQL需要查一个表,现在需要查两次,分别查两个表
【2】 水平分表
为了解决单表数据量过大(数据量达到千万级别)问题。所以需要将数据按一定的规则划分到不同表中,需要在读写的时候通过规则路由到具体的数据上
从而引起的复杂度有:
- 路由
范围路由:根据有序的数据列,如时间戳/ID作为路由条件,不同的分段分散到不同的表中。比如按ID分段
复杂度在于分段大小,太小则导致表太多影响以后维护难度,太大导致单表性能问题,一般在100万到2000万之间
范围路由的优点在于可以跟随数据的增长而平滑地去扩充新的表,而不影响原有表的数据,但缺点在于数据分布不均匀,可能0-100万的用户表已经填满了,但100-200万的用户还没几个,并且还需要维护表的增加逻辑
Hash路由:通过选取某个列的值进行Hash运算,然后根据Hash结果分散到不同的表中。比如ID字段用ID%n(n代表分表的数量)计算,从而路由到对应表中
复杂度一是在于表的数量选取,二是在于路由字段的选取,因为还需要考虑到日后的增删改查,如果数据分散到100张表里,那么不得不查100张表才能拿到所有数据,所以还需要在一定程度上将数据聚合,比如根据用户组的ID进行分表,那么就不会影响到用户组的查询效率,当然到底通过哪个字段分,是根据业务需要来取舍的
Hash路由的优点在于实现简单,不需要维护扩表逻辑,一般也不需要扩表,缺点在于一旦要扩展表的时候,所以数据都需要重新计算分配,导致大量数据的变动
配置路由:用一张独立的路由表来记录路由信息。比如以用户ID为路由字段,创建一张维护用户ID-表ID信息的表,做到根据用户ID,查到这个用户信息所在的表
配置路由的优点在于实现简单,扩充表的时候只需要指定迁移的数据,修改路由表就行了,缺点在于必须多查询一次路由表,而且路由表数据量太大的话又会成为一个瓶颈
- 查询操作
在水平分表之后,一旦涉及到查询全部表数据的SQL(比如多表查询join/查询总数count/全数据order by),都需要进行多次查询然后将结果汇集到一起,无法避免地需要在原来的基础上重写大量业务读写逻辑的代码
分区
为了解决单表数据量过大的另外的一种方式,不是把一张表在逻辑上拆分,而是把一张表的数据在物理上分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的,通过将不同数据按一定规则放到不同的区块中提升表的查询效率
比如在MySQL中,在创建表时可以指定分区表的类型以及按哪个字段进行分区,完成后对业务是透明的,原来的SQL也能基本照常使用(可能需要针对分区表做优化,条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区),在MySQL内部会负责路由到具体哪个分区
但分区的缺点在于:分区表中无法使用外键、分区键必须是主键或唯一索引、分区数量有限制
NOSQL
关系型数据库存在以下缺点:
- 只能存储行,无法存储数据结构。比如查一个用户列表必须在数据库里拆成多行,查询出来再拼装,不能直接存储一个列表
- 表结构无法扩展。不存在的列无法进行操作,修改时也会长时间锁表
- 全文检索功能弱。只能用like进行全表扫描,性能很低
K-V存储
全称Key-Value存储,典型代表:Redis。是一个高性能K-V缓存系统,Value是具体的数据结构,包括string、hash、set、sort set、list、bitmap、hyperloglog
所以,在Redis里就可以存储数据结构了,并且修改操作也很容易,比如LPOP操作时移除并返回key对应的list的第一个元素,如果用关系型数据库来存储,则需要:
- 每条数据必须有编号ID和位置编号
- 查询出第一条数据
- 删除第一条数据
- 更新从第二条开始的所有数据的位置编号
可以看出来需要多次SQL操作,性能很低。
Redis的缺点主要是不支持ACID事务,Redis的事务只能支持IC(隔离性、一致性)无法保证AD(原子性、持久性),但仍然是高性能缓存的首选
文档数据库
为了解决表结构无法扩展而生,大部分存储的格式是JSON,所以好处是:
- 新增字段简单。业务上新增字段,不需要再修改表结构,直接读写就行
- 历史数据不会出错。对于历史数据,不需要新增字段也不会出错,只会返回空值
所以根据这个特点,特别适合电商和游戏这类的业务场景,因为不同商品的属性差异非常大,即时是同类商品也有不同的属性
但缺点是不支持事务、无法实现关系数据库的join操作,只能用多次查询代替关系数据库的多表联合查询
列式数据库
列式数据库就是按列存储的数据库,对应的关系数据库就被称为行数据库,有以下的优势:
- 同时读取多个列的时候效率高,因为这些列式是按行存储在一起的,一次磁盘操作就能把一行数据的各个列都读取到内存
- 能够一次性完成对一个行中多个列的写操作,保证写操作的原子性和一致性
列式数据库的优势:
- 特定场景下节省IO。比如计算某个城市体重超重的人员数据,列数据库只需要读取每个人的体重这一列就行,但行数据库必须把所有数据都读取出来。所以列式数据库应用在离线的大数据分析和统计场景中,因为主要是对部分单列进行操作,且数据写入后不需要更新删除
- 更高的存储压缩比。行数据库压缩率在3:1到5:1,而列数据库在8:1到30:1,因为单个列的数据相似度比行来说更高
劣势:更新多个列性能差,因为列式存储是将不同的列存储到磁盘上不连续的空间,导致更新多个列的时候磁盘是随机写操作
全文搜索引擎
针对的是第三个关系型数据库的缺点,解决全文快速查询,关系型数据库不可能对每个字段建立索引,模糊匹配也是全表扫描,性能很差
基本原理是倒排索引,建立单词到文档的索引。比如有两篇文章1和2
文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
| 关键词 | 文章号 | 出现频率 | 出现位置 |
|---|---|---|---|
| guangzhou | 1 | 2 | 3,6 |
| live | 1 | 2 | 2,5 |
| live | 2 | 1 | 2 |
| shanghai | 2 | 1 | 3 |
| tom | 1 | 1 | 1 |
在Lucene中,将上面三列中的所有字段作为基础数据,然后分析出以上的数据结构,最后作为词典文件、频率文件、位置文件保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息
比如我想查shanghai,那么先查到文章号2,然后找到文章具体位置,随后展示给我了
以上是关于架构入门 - 高性能篇数据库高性能的主要内容,如果未能解决你的问题,请参考以下文章
云原生 | 混沌工程工具 ChaosBlade Operator 入门篇