神经网络模型量化综述(上)
Posted Adlik 深度学习推理工具链
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络模型量化综述(上)相关的知识,希望对你有一定的参考价值。
神经网络是资源密集型算法,其不仅需要大量的计算成本,而且还要消耗大量的内存。尽管计算资源在日益增多,但优化深层神经网络的训练和推理对于模型的落地仍然是非常重要的。特别是,越来越多的模型将从服务器端移到边缘侧等资源有限的设备上,如智能手机和嵌入式设备上,如何将复杂的模型部署在资源有限的设备上是当前深度学习技术必须要解决的问题。作为通用神经网络模型优化方法之一,模型量化可以减小深度神经网络模型的尺寸大小和模型推理时间,其适用于绝大多数模型和不同的硬件设备。
1. 模型量化基础
1.1 什么是量化?
量化是指将信号的连续取值近似为有限多个离散值的过程。可理解成一种信息压缩的方法。在计算机系统上考虑这个概念,一般用“低比特”来表示。也有人称量化为“定点化”,但是严格来讲所表示的范围是缩小的。定点化特指 scale 为 2 的幂次的线性量化,是一种更加实用的量化方法。为了保证较高的精度,计算机中大部分的科学运算都是采用浮点型进行计算,常见的是 float32 和 float64。神经网络的模型量化即将网络模型的权值,激活值等从高精度转化成低精度的操作过程,例如将 float32 转化成 int8,同时我们期望转换后的模型准确率与转化前相近。由于模型量化是一种近似算法方法,精度损失是一个严峻的问题,大部分的研究都在关注这一问题。
1.2 模型量化的优势
模型量化可以带来如下几个方面的优势:
-
更少的存储开销和带宽需求。即使用更少的比特数存储数据,有效减少应用对存储资源的依赖。
-
更低的功耗。移动 8bit 数据与移动 32bit 浮点型数据相比,前者比后者高 4 倍的效率,而在一定程度上内存的使用量与功耗是成正比的。
-
更快的计算速度。相对于浮点数,大多数处理器都支持 8bit 数据的更快处理,如果是二值量化,则更有优势。
1.3 模型量化原理
模型量化为定点与浮点等数据之间建立一种数据映射关系,使得以较小的精度损失代价获得了较好的收益。详细如下:
R 表示真实的浮点值,Q 表示量化后的定点值,Z 表示 0 浮点值对应的量化定点值,S 则为定点量化后可表示的最小刻度。由浮点到定点的量化公式如下:
由定点到浮点反量化公式如下:
其中,S 和 Z 的求值公式如下:
分别表示最大和最小的浮点数,最大和最小的定点数。量化后的 Q 还是反推求得的浮点值 R,若它们超出各自可表示的最大范围,则需进行截断处理。
2. 模型量化算法
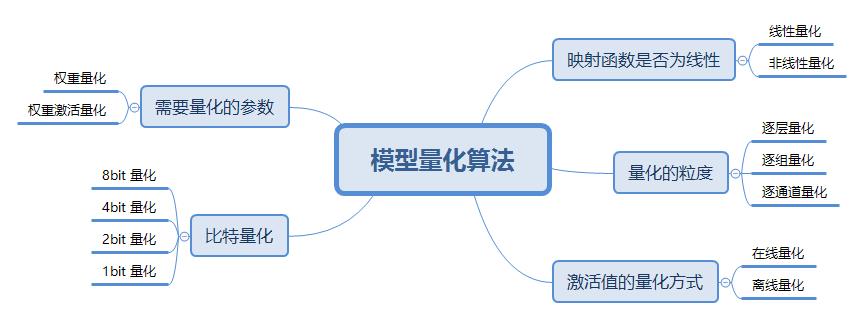
2.1 线性量化
根据映射函数是否是线性可以分为两类,即线性量化和非线性量化,本文主要讨论线性量化技术。
根据参数 Z 是否为零可以将线性量化分为两类:对称量化和非对称量化。
对称量化
如上图所示,所谓的对称量化,即使用一个映射公式将输入数据映射到 [-128,127] 的范围内,图中 表示的是输入数据的最小值, 表示输入数据的最大值。对称量化的一个核心即零点的处理,映射公式需要保证原始的输入数据中的零点通过映射公式后仍然对应 [-128,127] 区间的零点。总而言之,对称量化通过映射关系将输入数据映射在 [-128,127] 的范围内,对于映射关系而言,我们需要求解的参数即 Z 和 S。
非对称量化
如上图所示,所谓的非对称量化,即使用一个映射公式将输入数据映射到 [0,255] 的范围内,图中 表示的是输入数据的最小值, 表示输入数据的最大值。总而言之,对称量化通过映射关系将输入数据映射在 [0,255] 的范围内,对于映射关系而言,我们需要求解的参数即 Z 和 S。
2.2 逐层量化、逐组量化和逐通道量化
根据量化的粒度(共享量化参数的范围)可以分为逐层量化、逐组量化和逐通道量化。
-
逐层量化以一个层为单位,整个 layer 的权重共用一组缩放因子 S 和偏移量 Z; -
逐组量化以组为单位,每个 group 使用一组 S 和 Z; -
逐通道量化则以通道为单位,每个 channel 单独使用一组 S 和 Z。
当 group=1 时,逐组量化与逐层量化等价;当 group=num_filters (即 dw 卷积)时,逐组量化逐通道量化等价。
2.3 在线量化和离线量化
根据激活值的量化方式,可以分为在线(online)量化和离线(offline)量化。
-
在线量化:指激活值的 S 和 Z 在实际推断过程中根据实际的激活值动态计算; -
离线量化,即指提前确定好激活值的 S 和 Z。
由于不需要动态计算量化参数,通常离线量化的推断速度更快些。
2.4 比特量化
根据存储一个权重元素所需的位数,可以将其分为 8bit 量化、4bit 量化、2bit 量化和 1bit 量化等。
-
二进制神经网络。即在运行时具有二进制权重和激活的神经网络,以及在训练时计算参数的梯度。 -
三元权重网络。即权重约束为+1, 0 和 -1 的神经网络。 -
XNOR 网络。即过滤器和卷积层的输入是二进制的。XNOR 网络主要使用二进制运算来近似卷积。
2.5 权重量化和权重激活量化
根据需要量化的参数可以分类两类:权重量化和权重激活量化。
-
权重量化。即仅仅需要对网络中的权重执行量化操作。由于网络的权重一般都保存下来了,因而我们可以提前根据权重获得相应的量化参数 S 和 Z。由于仅仅对权重执行了量化,这种量化方法的压缩力度不是很大。 -
权重激活量化。即不仅对网络中的权重进行量化,还对激活值进行量化。由于激活层的范围通常不容易提前获得,因而需要在网络推理的过程中进行计算或者根据模型进行大致的预测。
3. 模型量化实现的介绍
3.1 模型量化实现的一般步骤
对于模型量化任务而言,具体的执行步骤如下所示:
-
步骤1-在输入数据(通常是权重或者激活值)中统计出相应的 min_value 和 max_value; -
步骤2-选择合适的量化类型,对称量化(int8)还是非对称量化(uint8); -
步骤3-根据量化类型、min_value 和 max_value 来计算获得量化的参数 Z/Zero point 和 S/Scale; -
步骤4-根据标定数据对模型执行量化操作,即将其由 FP32 转换为 INT8; -
步骤5-验证量化后的模型性能,如果效果不好,尝试着使用不同的方式计算 S 和 Z,重新执行上面的操作。
3.2 Pytorch 模型量化介绍
具体的细节请参考该链接:QUANTIZATION(https://pytorch.org/docs/master/quantization.html)。
与典型的 FP32 类型相比,PyTorch 支持 INT8 量化,从而可将模型尺寸减少 4 倍,并将内存带宽要求减少 4 倍。与 FP32 计算相比,对 INT8 计算的硬件支持通常快 2 到 4 倍。量化主要是一种加速推理的技术,并且量化算子仅支持前向传递。
PyTorch 支持多种量化深度学习模型的方法。在大多数情况下,该模型在 FP32 中训练,然后将模型转换为 INT8。此外,PyTorch 还支持训练时量化,该训练使用伪量化模块对前向和后向传递中的量化误差进行建模。注意,整个计算是在浮点数中进行的。在量化意识训练结束时,PyTorch 提供转换功能,将训练后的模型转换为较低的精度。
PyTorch 支持每个张量和每个通道非对称线性量化。每个张量意味着张量内的所有值都以相同的方式缩放。每通道意味着对于每个尺寸(通常是张量的通道尺寸),张量中的值都按比例缩放并偏移一个不同的值(实际上,比例和偏移成为矢量)。这样可以在将张量转换为量化值时减少误差。为了在 PyTorch 中进行量化,我们需要能够以张量表示量化数据。量化张量允许存储量化数据(表示为 int8 / uint8 / int32)以及诸如 scale 和zero_point 之类的量化参数。量化张量除了允许以量化格式序列化数据外,还允许许多有用的操作使量化算术变得容易。
PyTorch 提供了三种量化模型的方法,具体包括训练后动态量化、训练后静态量化和训练时量化。
训练后动态量化: 这是最简单的量化形式,其中权重被提前量化,而激活在推理过程中被动态量化。这种方法用于模型执行时间由从内存加载权重而不是计算矩阵乘法所支配的情况,这适用于批量较小的 LSTM 和 Transformer 类型。对整个模型应用动态量化只需要调用一次torch.quantization.quantize_dynamic() 函数即可完成具体的细节请参考该量化教程。
训练后静态量化: 这是最常用的量化形式,其中权重是提前量化的,并且基于在校准过程中观察模型的行为来预先计算激活张量的比例因子和偏差。CNN 是一个典型的用例,训练后量化通常是在内存带宽和计算节省都很重要的情况下进行的。进行训练后量化的一般过程如下所示:
-
步骤1-准备模型:通过添加 QuantStub 和 DeQuantStub 模块,指定在何处显式量化和反量化激活值;确保不重复使用模块;将需要重新量化的任何操作转换为模块的模式; -
步骤2-将诸如 conv + relu 或 conv + batchnorm + relu 之类的组合操作融合在一起,以提高模型的准确性和性能; -
步骤3-指定量化方法的配置,例如选择对称或非对称量化以及 MinMax 或 L2Norm 校准技术; -
步骤4- 插入 torch.quantization.prepare() 模块来在校准期间观察激活张量; -
步骤5-使用校准数据集对模型执行校准操作; -
步骤6-使用 torch.quantization.convert() 模块来转化模型,具体包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现等。
训练时量化: 在极少数情况下,训练后量化不能提供足够的准确性,可以插入 torch.quantization.FakeQuantize() 模块执行训练时量化。计算将在 FP32 中进行,但将值取整并四舍五入以模拟 INT8 的量化效果。具体的量化步骤如下所示:
-
步骤1-准备模型:通过添加 QuantStub 和 DeQuantStub 模块,指定在何处显式量化和反量化激活值;确保不重复使用模块;将需要重新量化的任何操作转换为模块的模式; -
步骤2-将诸如 conv + relu 或 conv + batchnorm + relu 之类的组合操作融合在一起,以提高模型的准确性和性能; -
步骤3-指定伪量化方法的配置,例如选择对称或非对称量化以及 MinMax 或 L2Norm 校准技术; -
步骤4-插入 torch.quantization.prepare_qat() 模块,该模块用来在训练过程中的模拟量化; -
步骤5-训练或者微调模型; -
步骤6-使用 torch.quantization.convert() 模块来转化模型,具体包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现等。
3.3 支持量化的框架
不管是 Post-Training Quantization 还是 Quantization-Aware Training,算法端都还是用伪量化操作实现的,部署时就必须用 INT8 引擎。支持INT8 引擎框架有:
-
DSP/加速芯片平台; -
CPU 平台:Google 的 TensorFlow Lite,Facebook 的 QNNPACK,Tencent 的 NCNN,Alibaba 的 MNN。 -
GPU 平台:NVIDIA 的 TensorRT ,Alibaba 的 MNN 和 TVM。
而伪量化框架则在深度学习框架 (caffe,pytorch,tensorflow) 中开源的较多,如基于 pytorch 的 distiller,NNCF。
对于 ARM 平台,INT8 引擎会通过 NEON 指令集加速;对于 x86 平台,INT8 引擎会通过 SSE 加速;对于 NVIDIA GPU 平台,则通过 dp4a 矩阵运算库加速。dp4a 实现了基础的 INT8 矩阵相乘操作,目前 cuDNN,cuBLAS,TensorRT 均采用该指令集。
4. 模型量化落地的一些问题
阻碍模型量化算法落地核心问题当然是精度问题。虽然学术界大家很早就开始做量化,但现在算法还无法大规模落地。主要存在以下几个问题:
-
可落地的线性量化方案无法很好的刻画一些分布,比如高斯分布; -
比特数越低,精度损失就越大,实用性就越差; -
任务越难,精度损失越大,比如识别任务,就比分类任务要难非常多; -
小模型会比大模型更难量化; -
某些特定结构,如 depthwise,对量化精度十分不友好; -
常见的对部署友好的方法比如合并 BN,全量化,都会给精度带来更大的挑战。
除了模型精度损失外,软硬件支持不好也是一个阻碍:不同的硬件支持的低比特指令是不一样的,同样训练得到的低比特模型,无法直接部署在所有硬件上。除了硬件之外,不同软件库实现的量化方案和细节也不一样,量化细节里包括量化位置、是否支持每个通道、是否混合精度等等。即使硬件支持了量化,但你会发现不是所有硬件可以在低比特上提供更好的速度提升, 造成这个状况的主要原因有多个,一方面是指令集峰值提升可能本身就并不多,而要引入较多的额外计算,另一方面也取决于软件工程师优化指令的水平,同时由于网络结构灵活多样,不一定能在不同网络结构上达到同样好的加速比,需要优化足够多的的 corner case 才可以解决。
参考资料
[1] 模型量化了解一下?
https://zhuanlan.zhihu.com/p/132561405
[2] 【AI不惑境】模型量化技术原理及其发展现状和展望
https://zhuanlan.zhihu.com/p/141641433
[3] 模型量化详解
https://blog.csdn.net/WZZ18191171661/article/details/103332338
[4] Pytorch中的量化
https://pytorch.org/docs/master/quantization.html
以上是关于神经网络模型量化综述(上)的主要内容,如果未能解决你的问题,请参考以下文章