前端再也不用头疼了---分布式系列之网关zuul包揽全局
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端再也不用头疼了---分布式系列之网关zuul包揽全局相关的知识,希望对你有一定的参考价值。
zuul模块搭建 pom 还是之前的项目继续新增zuul模块。zuul模块继承framework-root ,然后在zuul的pom里配置如上坐标 配置文件 配置文件只需要…
zuul模块搭建
pom
<!--eureka-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--zuul网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
- 还是之前的项目继续新增zuul模块。zuul模块继承
framework-root,然后在zuul的pom里配置如上坐标
配置文件
server:
port: 7070
spring:
application:
name: cloud-zuul
#eureka注册中心
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
- 配置文件只需要简单的项目配置。因为我们的order、payment服务是注册在eureka上的。为了zuul能够自动获取实例所以zuul模块也需要注册到eureka上方便获取实例集合。
启动类
- 然后启动类上添加zuul注解。因为eureka所以还需要eureka的注解
@EnableZuulProxy
@EnableEurekaClient
总结
-
就是那么简单,上述步骤只需要三步 ,添加坐标,修改配置,添加启动类。就实现了zuul网关了。
-
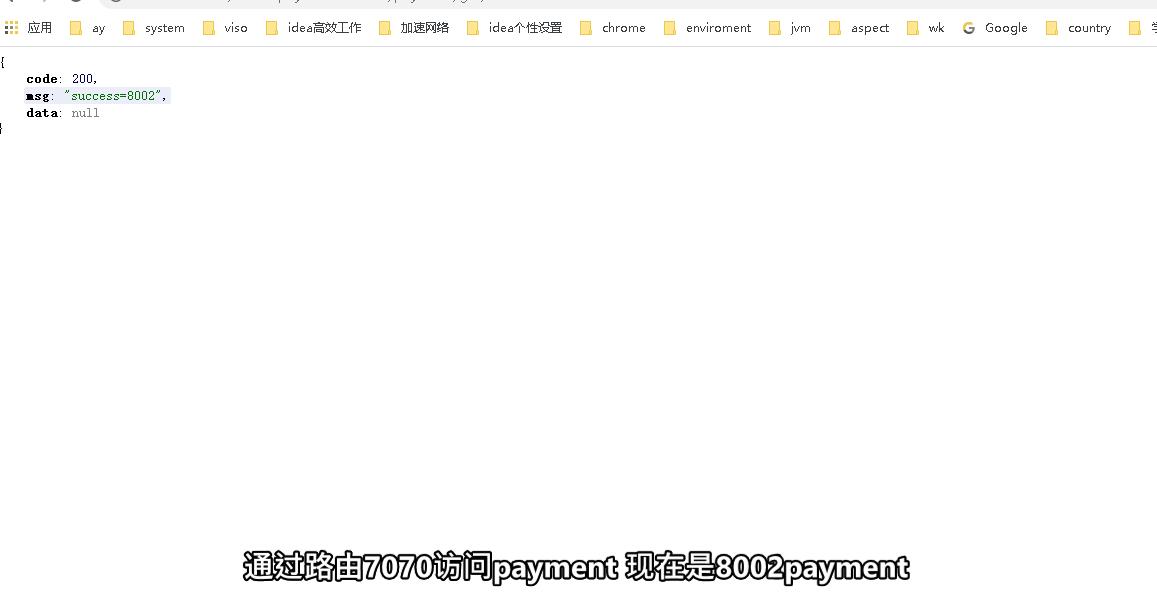
上述zuul启动后
http://localhost:7070/cloud-payment-service/payment/get/1就会被代理到http://localhost:8001/payment/get/1上。这里可能是8002 -
http://localhost:7070/cloud-order-service/order/get?id=123就会被代理到http://localhost/order/get?id=123上 -
但是我们并没有像nginx一样配置相关的请求转发呀 。因为zuul网关给我们配置了默认的转发规则。
-
zuul会为eureka上注册的服务都配置默认拦截。
localhost:7070/[serviceId]/**会被转发到serviceId的其中一台机器上访问对应服务的 下面的接口。
动态路由
定制路由1
zuul:
routes:
payment:
path: /cloud-payment-service2/**
serviceId: cloud-payment-service
- 我们在
cloud-zuul模块新增配置。那么就会实现http://localhost:7070/cloud-payment-service2/payment/get/1就会被代理到http://localhost:8001/payment/get/1上。这里可能是8002。 - 这种配置是在默认配置拦截不满足我们需求时可以配置
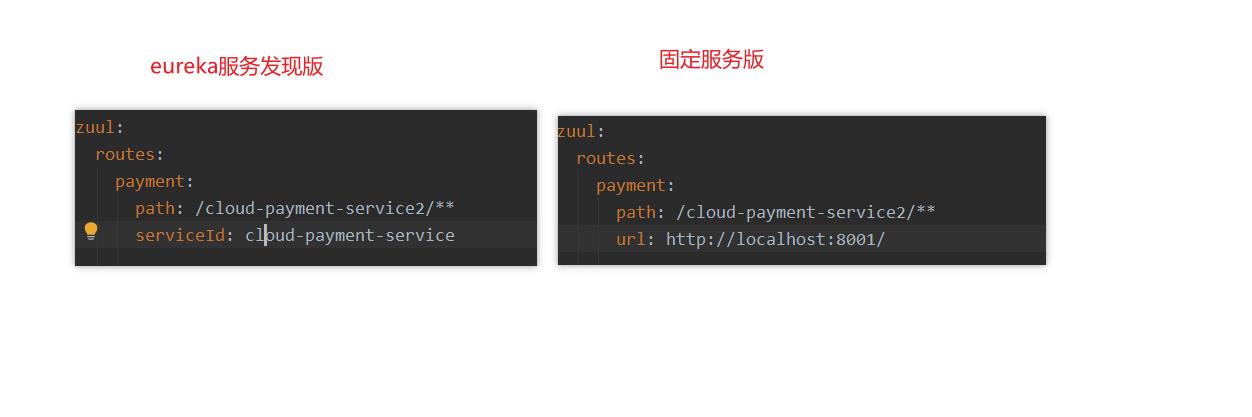
- 在定制路由这块,我们有两种方式,左边的是依赖eureka服务发现转发路由的,内部依赖于ribbon进行负载均衡。
- 右边的是我们传统的项目转发。和nginx类似。将指定的前缀转发到指定的服务器上。缺点也很明显。不能负载均衡
非eureka的多服务转发
- 如果你们的项目没有整合类似eureka的服务发现,我只能说你的项目不适合分布式。但是zuul也是有办法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RhyjeS3y-1620569159007)(http://oytmxyuek.bkt.clouddn.com/20210505image-20210423170731140.png)]
- 值得注意的是path的编写。在后面通配符的书写中主要有三类
| 通配符 | 说明 |
|---|---|
| ? | 匹配任意单个字符 /a , /b , /c |
| * | 匹配任意数量字符 /abc |
| ** | 匹配任意层级的任意字符 /ab/c |
定制路由2
- 上面我们提到了在配置文件中配置我们的路由转发。这个是可以实现我们的定制。但是这样配置起来太麻烦了。服务太多我们配置就会很麻烦。而且正常我们接口转发都是有规律的。下面我们看看如何通过代码定制规则路由转发。
- 我们现在微服务系统中有
cloud-payment-service,cloud-order-service两个微服务。我们在zuul路由时想把cloud、service都去除。这种情况在配置文件可以实现。但是如果有200个服务,在配置文件中该是不是有点low。 - 这种定制是有规则的定制。这时候就需要我们的
PatternServiceRouteMapper登场了。
Matcher
PatternServiceRouteMapper登场之前,我觉得我们有必要整理下java.util.regex.Matcher这个类。因为PatternServiceRouteMapper看名字我们就知道是通过正则进行接口匹配的。内部就是借助Matcher来实现的。- 先来描述下我们上面路由定制的需求。我们需要将
cloud-payment-service,cloud-order-service微服务接口转为类似payment、order的服务名。 - 基于此我们可以写出这样的正则
(\\w+)-(\\w+)-(\\w+)
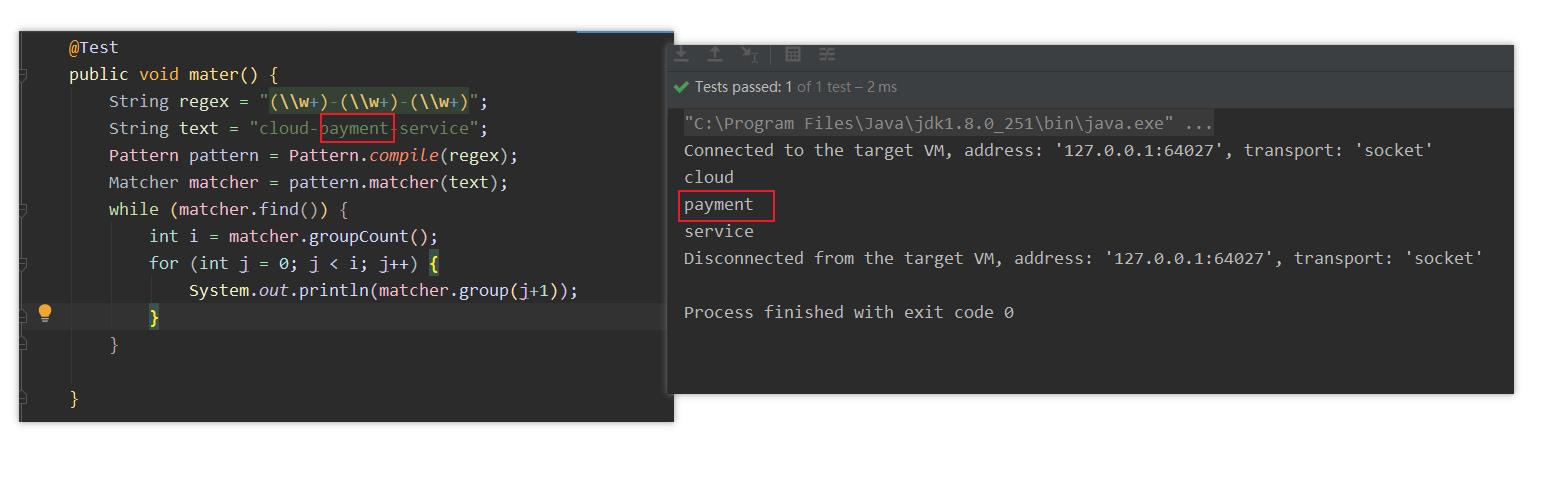
- 通过上面的正则匹配,我们也能够发现我们需要的就是group(2) 。 我们只需要将第三个匹配的内容返回作为访问接口就可以了。上面也是笔者平时获取匹配内容的方式。一开始看
PatternServiceRouteMapper愣是没看懂他写的正则。突然感觉自己的正则白学了。
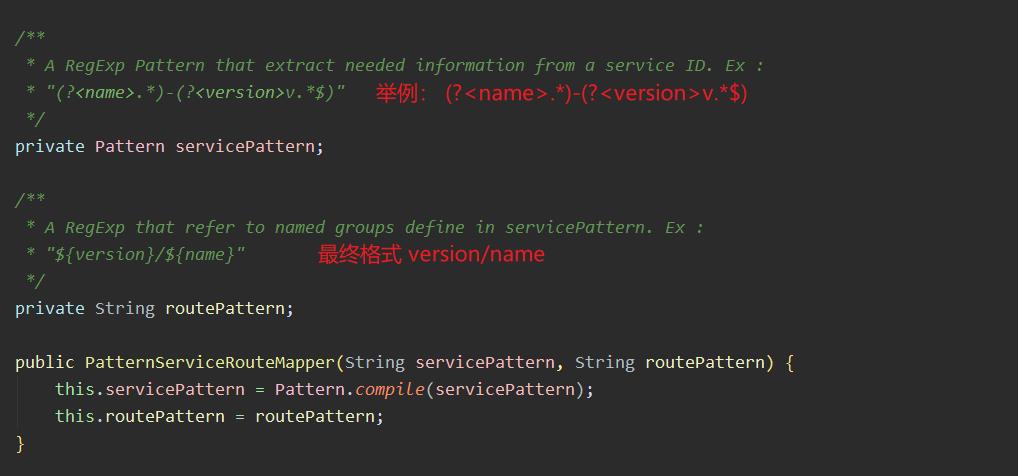
- 上面就是
PatternServiceRouteMapper类中举例的格式。其中<name>这个一开始没看懂。有了这个就会去匹配了。这不就写死了吗。查阅资料才知道这是给group起别名了。
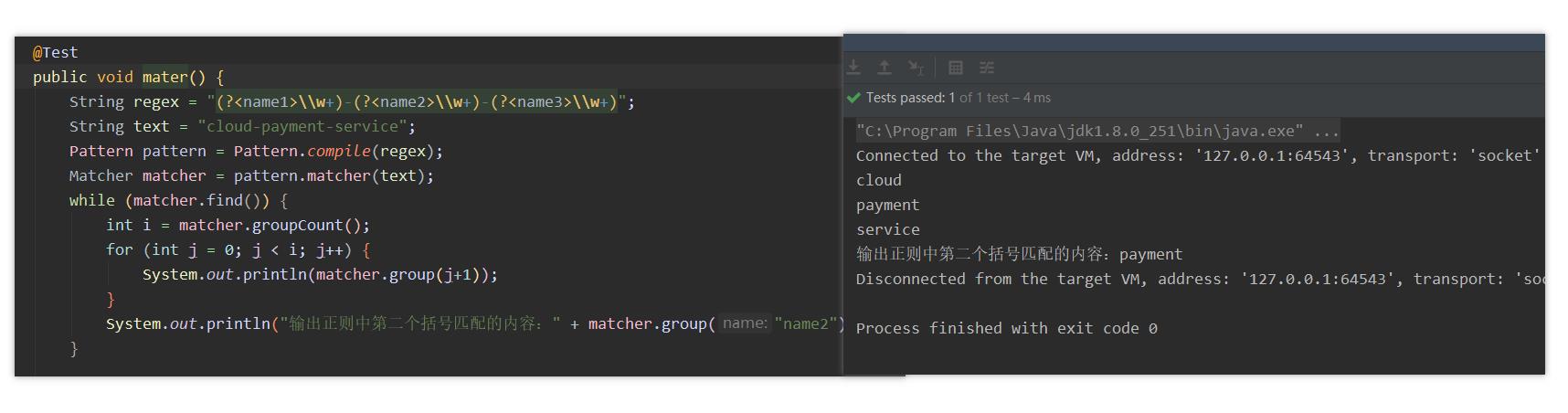
- 然后我们改良了初次的正则代码。发现通过起别名的方式还是很方便的。起别名的方式
?<name>此时name就是括号所在的group的别名。
PatternServiceRouteMapper
- 下面我们正式开始介绍动态路由。
PatternServiceRouteMapper类也很简单。需要两个参数servicePattern,routePattern; 前者是正则,后者是整理后的格式。所以我们配置如下
@Bean
public PatternServiceRouteMapper patternServiceRouteMapper() {
return new PatternServiceRouteMapper(
"(?<project>^.+)-(?<name>.+)-(?<service>.+$)",
"${name}");
}
认证鉴权(过滤器)
- 所谓网关就是我们的门面。只不过这里的门面是我们后端微服务的门面。门面的作用除了将我们统一化,还有一个重要的作用过滤接口。一个网站对外发布难免会遇到恶意攻击。正常的网站我们都是有权限一说的,在微服务架构中我们不可能在每个微服务中都去权限验证,这样维护起来相当的麻烦。
- 在上述问题中我们会相当将鉴权抽离成一个模块,然后在其他的模块中调用该鉴权模块就可以了。咋看好像没什么问题。笔者目前的项目也正是这么做的。但是虽然规模的不断庞大,笔者也意识到这种方式的弊端了。还记得之前我们的鉴权模块做了一些改动。在方法签名上新增了一些信息。这个改动在我们开发者看来真的是无伤大雅。但是偏偏这个小改动引起大波澜我们所有的模块都需要更新鉴权包并新增参数。
- 所带来的问题是我们每个模块都需要重新发包上线。每个模块的排期因此也被打乱了。
- 针对上述的抽离方案,我们今天主角zuul就能完美解决。因为zuul他不在需要其他模块引入。而是将其他模块组成成一道生态。zuul负责这个生态的门卫看护。
需求整理
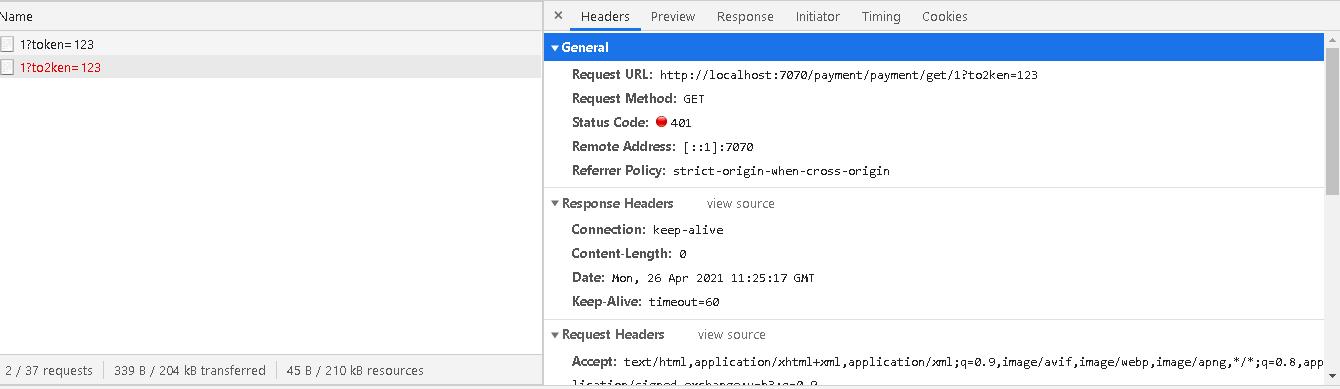
-
假如现在我们要求每个接口参数中必须添加一个token。 为了方便演示我们不对value进行验证。在正规开发中这个value应该也是服务端授予的。
-
如果有token则放行,否则返回报错
实现验证
- 实现验证其实就是实现一个过滤器。我们只需要继承
com.netflix.zuul.ZuulFilter即可。这个类中有四个方法需要我们实现。
| 方法 | 作用 |
|---|---|
| filterType | 过滤器类型 |
| filterOrder | 执行顺序 , 越小越先执行 |
| shouldFilter | 是否需要执行 |
| run | 具体逻辑 |
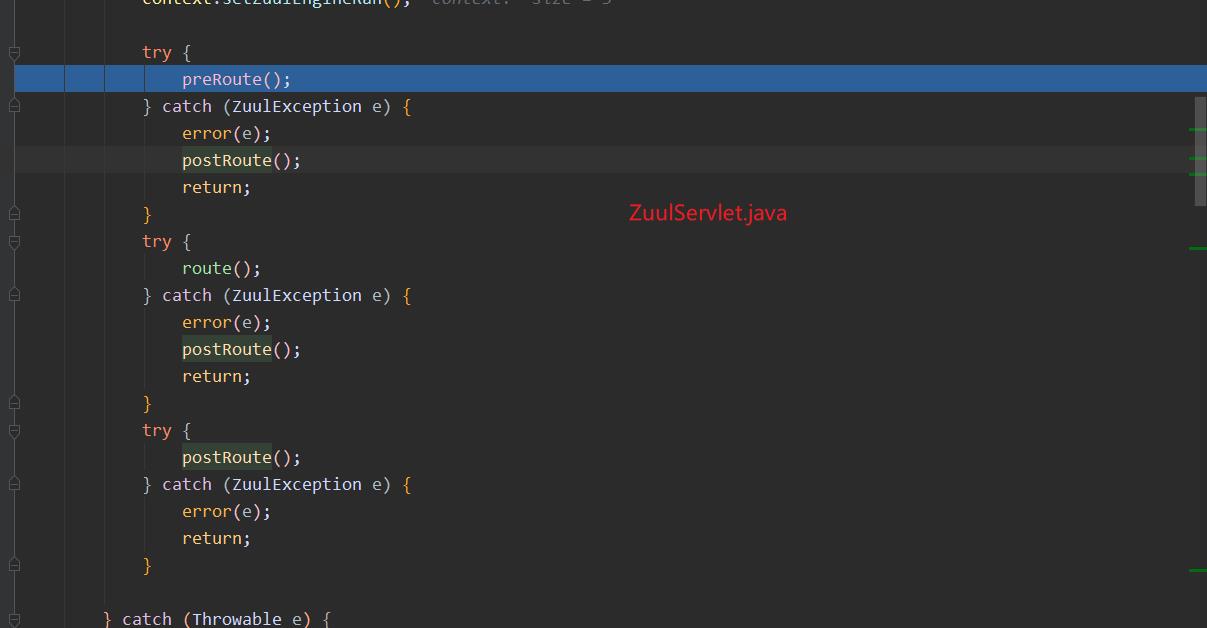
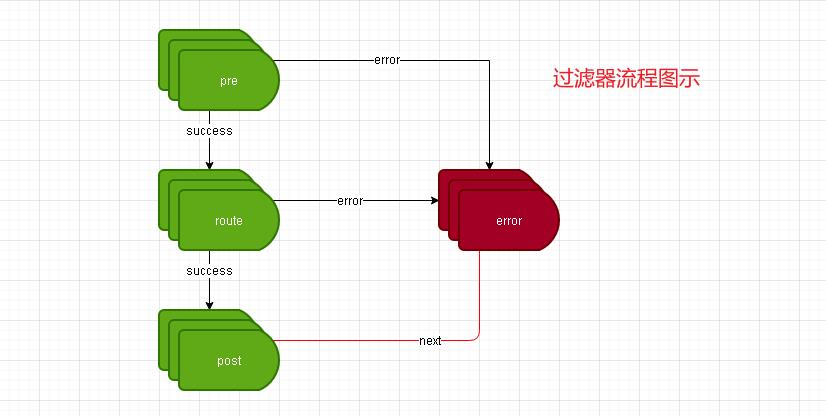
-
关于过滤器类型有pre、route、post、error四种类型。关于他们的执行顺序下面的代码应该解释的很清楚。
-
pre : 在路由之前执行 , 如果出现异常则会直接执行error和route
-
route : 在pre之后执行
-
post : 一切正常情况,会在route路由之后执行
-
error : 异常执行
-
在netflix-zuul中默认如下过滤器
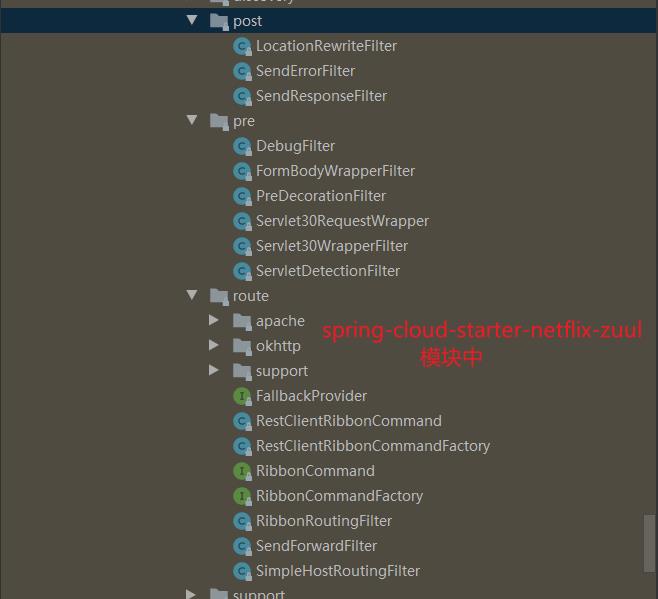
在过滤器之间我们可以通过com.netflix.zuul.context.RequestContext 来获取上下文。我们也可以依赖他来进行数据的传递。
验证逻辑
@Override
public Object run() throws ZuulException {
System.out.println("我是pre过滤器我被执行啦。。。。。。。。。。。。。。。");
RequestContext currentContext = RequestContext.getCurrentContext();
HttpServletRequest request = currentContext.getRequest();
String token = request.getParameter("token");
if (StringUtils.isEmpty(token)) {
currentContext.setSendZuulResponse(false);
currentContext.setResponseStatusCode(401);
return null;
}
return null;
}
- 我们在我们的过滤器中进行判断就可以了。通过set响应状态告知客户端。
动态过滤器
- 上面我们通过两种方式实现如何进行动态路由的转发。但是我们有时候在运营是可能想动态的增减过滤器。这个zuul也是可以实现的主要依赖于groovy来实现动态加载过滤器的
pom
<dependency>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy-all</artifactId>
<version>3.0.0</version>
</dependency>
注册bean
- 我这里为了演示关于动态加载的配置就直接写死了。
- 如果我们正规使用的话,在
FilterFileManager.init接收两个参数 一个是时间间隔、一个是文件数组 - 我们可以将这些配置进行动态化配置或者直接在数据库中配置。在结合页面就可以让运营人员直接在页面上就可以动态增减过滤器了。
@Bean
public FilterLoader filterLoader() {
FilterLoader instance = FilterLoader.getInstance();
instance.setCompiler(new GroovyCompiler());
try {
FilterFileManager.setFilenameFilter(new GroovyFileFilter());
FilterFileManager.init(5,"D:\\\\cloud\\\\filter\\\\pre");
} catch (Exception e) {
throw new RuntimeException("发生错误啦");
}
return instance;
}
编写过滤器
- 在前面的认证鉴权章节已经详细介绍了过滤器的内容。编写一个过滤器也很简单。
- 但是我们这里不再是java类型的过滤器了。而是groovy类型的过滤器。他们有啥区别呢。直接贴代码吧
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.apache.commons.lang.StringUtils;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
public class PreFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
System.out.println("我是被动态加载进来的pre过滤器。。。。。。。。。。。。。。。");
return null;
}
}
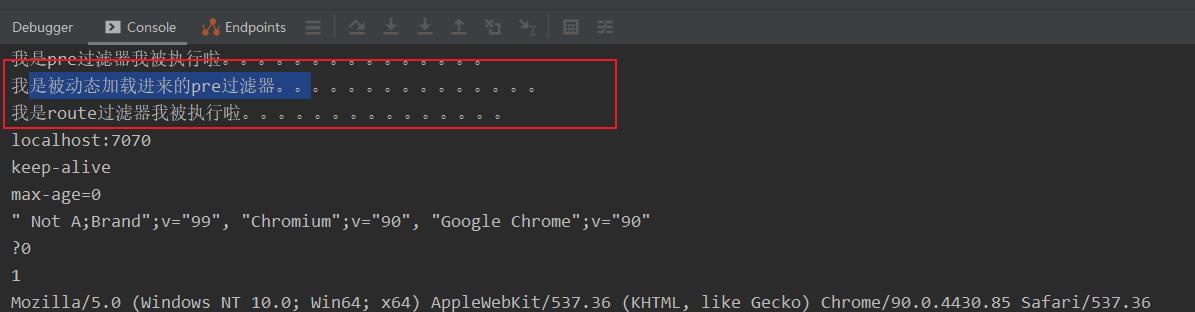
验证结果
- 在zuul不重启的情况下,我们直接将上述写好的PreFilter.groovy这个文件放到本地的
D:\\cloud\\filter\\pre下就可以了 。 然后我们就等待5S在访问路由接口就可以看到我们新加的过滤了。
总结
- 动态过滤的加载原则上不能加太多的逻辑。因为用到其他的包的支持应该是不行的。因为在groovy中内部只有java的东西。
- 还有一个重要的点是我们无法在动态注入的过滤器中与spring进行交互 。
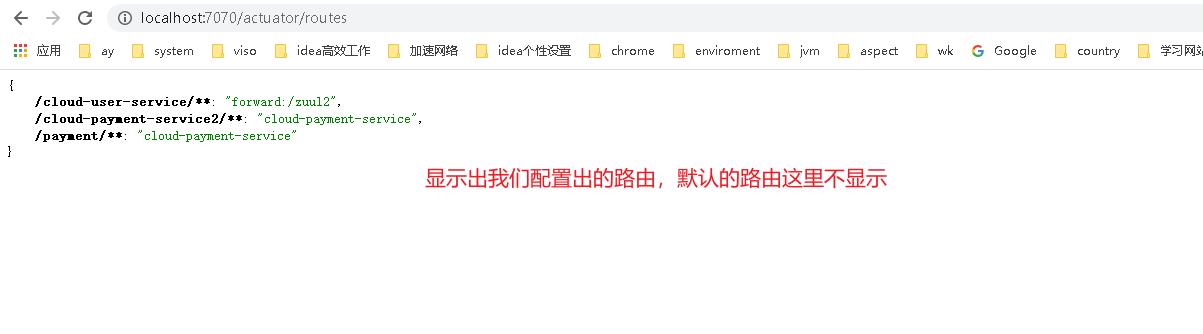
查看routes
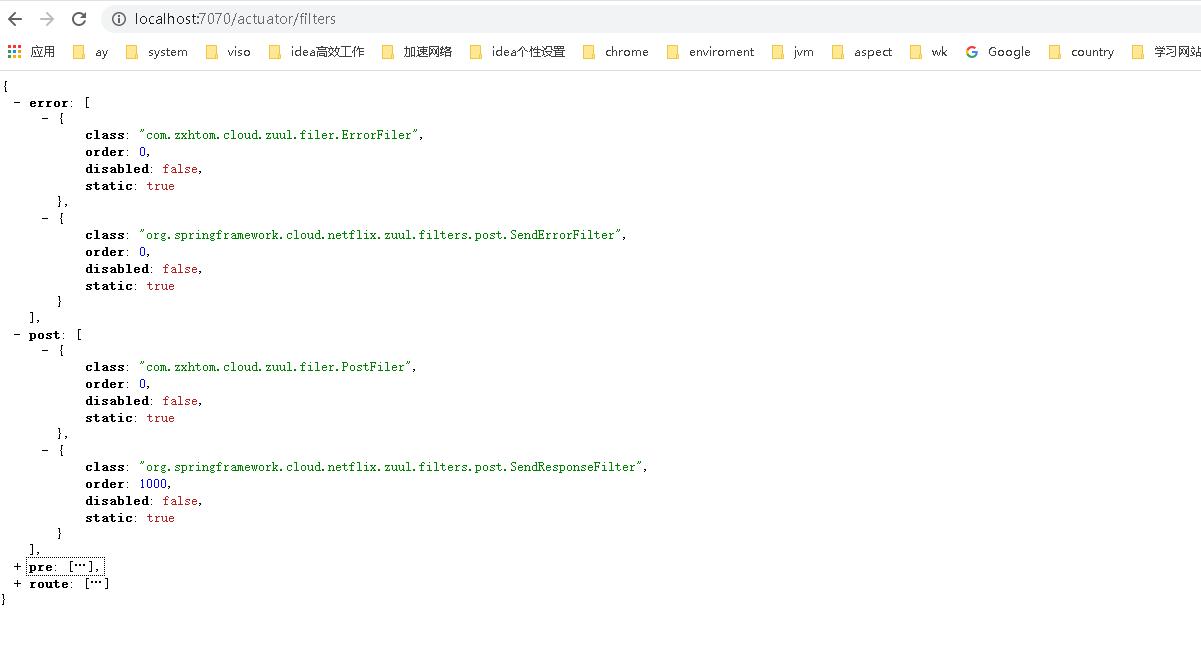
- 一般情况我们在zuul中都会存在两个端点信息,分别是**/routes**、/filters ,如果我们需要看到这些监控信息我们需要在actuator中配置一下
management:
endpoints:
web:
exposure:
include: 'routes,filters'
- 然后启动项目后,我们通过访问
http://localhost:7070/actuator

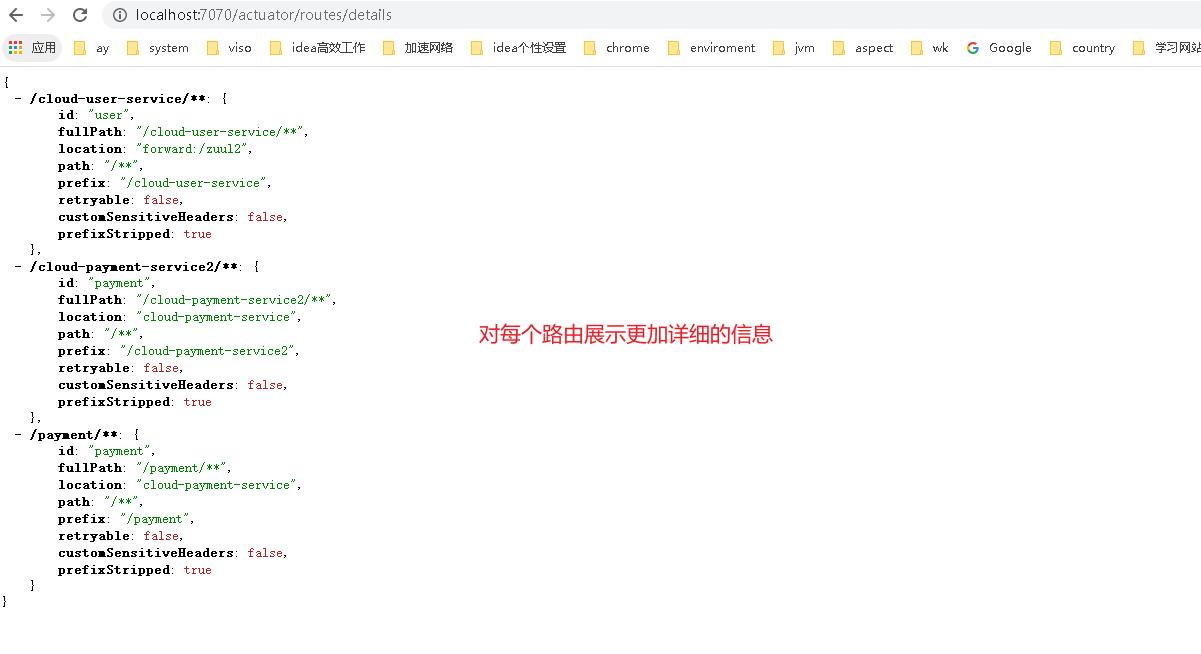
- 除了actuator以外,我们看到有routes、filters两个我们需要的监控。另外有一个/routes/{format} 也是属于routes 。 format就是设置我们routes显示的格式
routes
routes/{format}
filters
灰度发布
- 说到灰度发布我们不得不提其他几种方式
- 蓝绿发布 : 蓝绿发布就是两套环境。两套都是发布环境但是始终只会有一套暴露给外部使用。没有暴露的环境就是我们预发布环境。我们可以在这个环境进行测试。测试通过后再进行流量切换。切换后两套环境的角色也就发生转变。
- 滚动发布: 将线上服务逐个进行替换。A,B,C 三台我们分别进行替换。这样带来的问题是中途出现问题就是个灾难。
那什么是灰度发布呢? 灰度发布就是我们线上资源保留不动。我们只需要将新服务上线。此时原服务和新服务同时运行。这个时候我们将测试流量打向新服务。我们针对这个服务进行测试。测试通过后我们将放少部分流量给新服务试用一段时间然后收集这部分数据使用情况。数据满意后再将全部流量放到新服务上。当然这种发布方式肯定不满足我们传统项目的。灰度发布适用于分布式项目。想要灰度发布我们项目必须支持分布式。比如说我们后台服务的定时任务。多台服务同时在线的话如果不支持分布式那么就会重复执行。
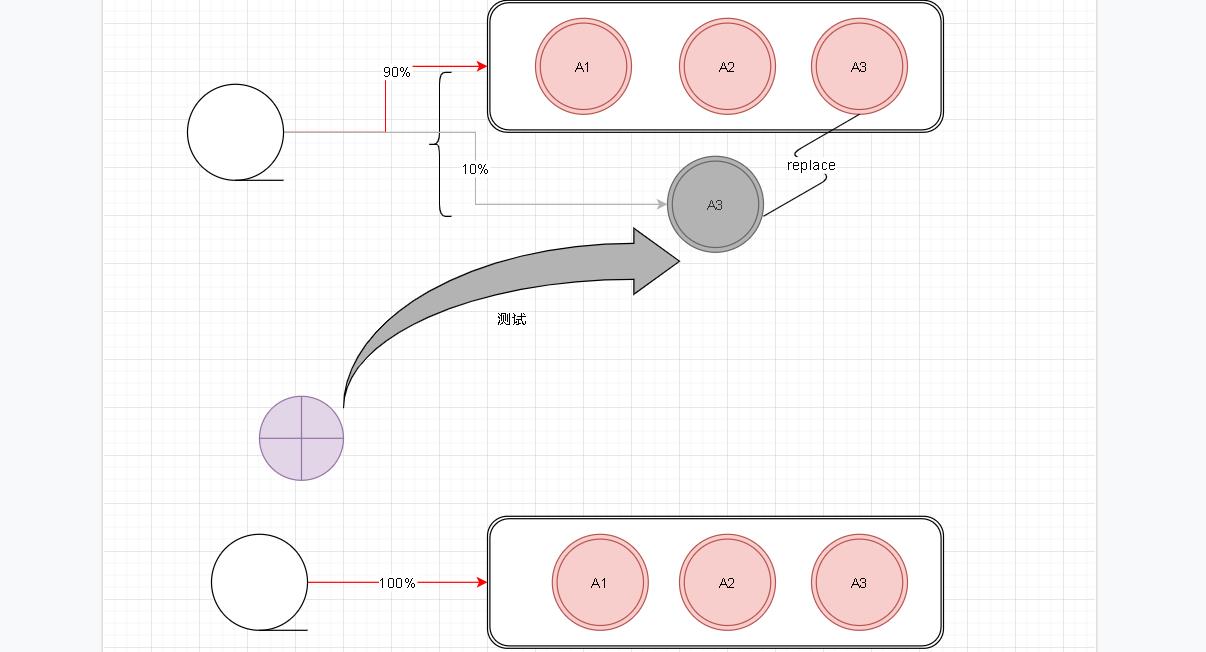
- 最终我们在不停机的前提进行服务的升级。现在互联网公司基本上都是这种模式。升级不能影响客户使用。下面我们通过zuul来简单实现下灰度发布
源码实现
pom引入
- 下面这个jar包主要作用就是过滤服务器列表。在zuul中最终还是依赖于我们ribbon实现负载均衡的。而我们是与eureka结合的。ribbon与eureka又是无缝整合。所以最终我们是在过滤eureka服务列表。我们在eureka专题中我们也提到过eureka-client提供了获取服务列表等操作。而下面的工作就是在获取服务列表时候进行指定规则帅选。
io.jmnarloch.spring.cloud.ribbon.predicate.MetadataAwarePredicate里实现了通过eureka里metadata属性来进行服务过滤的。
<dependency>
<groupId>io.jmnarloch</groupId>
<artifactId>ribbon-discovery-filter-spring-cloud-starter</artifactId>
<version>2.1.0</version>
</dependency>
配置文件
- 我们启动了两台payment , 端口分别是8001,8002 。 其中两台payment中lancher属性分别是1,2 。 相当于给payment服务指定
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
metadata-map:
lancher: 1
实现过滤器
- 结合上面提到的
io.jmnarloch.spring.cloud.ribbon.predicate.MetadataAwarePredicate我们只需要在zuul过滤器中指定我们需要访问的服务器的metadata属性就可以了 。比如说下面我们通过判断请求中参数是否包含new参数来判断请求的服务器
@Component
public class GreenFiler extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
if (request.getParameter("new") != null) {
// put the serviceId in `RequestContext`
RibbonFilterContextHolder.getCurrentContext().add("lancher", "1");
} else {
RibbonFilterContextHolder.getCurrentContext().add("lancher", "2");
}
return null;
}
}
测试
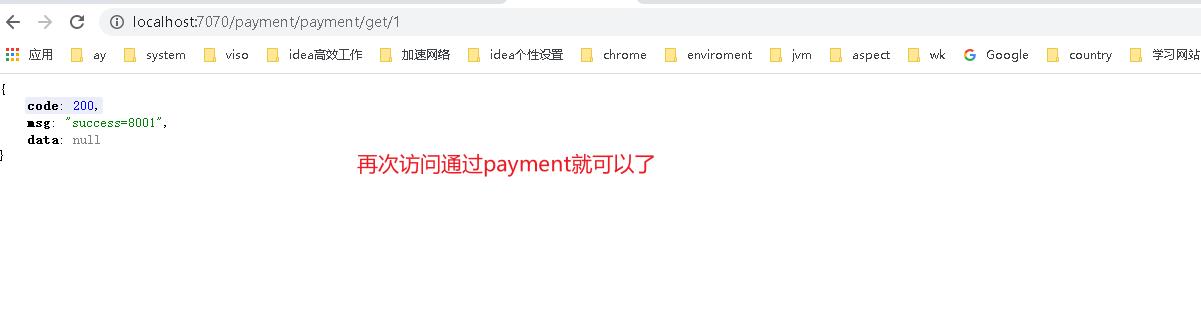
- 结合上面我们定制路由,cloud-payment-service 最终会被我们转换到payment请求上。还有上面我们token的验证所以我们zuul请求需要添加token才能验证通过
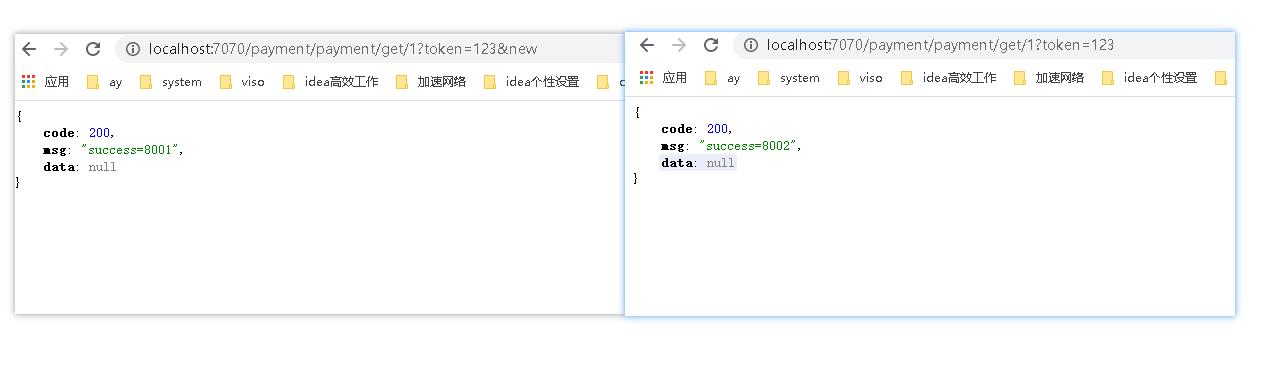
- 我们访问
http://localhost:7070/payment/payment/get/1?token=123&new首先会验证token通过在根据有new参数被路由到lancher=1 的服务上,即最终访问http://localhost:8001/payment/get/1?token=123&new上 - 我们在访问
http://localhost:7070/payment/payment/get/1?token=123会验证token并路由到8002上。
灰度扩展
- 上述我们通过请求中指定的参数实现了路由的转发实现原理是借助了eureka的metadata的参数属性路由的。
- 但是我们在平时应该遇到过有些软件对不同地区进行不同对待。
- 比如说支付宝蚂蚁森林不同城市有不同的策略
- 比如说某软件邀请你参与内侧版本使用
- 上述都统称为灰度发布,原理也很简单实际上就是有多个实例,zuul根据请求的特征转发到不同的实例上。不同城市就是根据地区来路由,邀请内侧就是通过个人用户信息来路由。他们的实现都离不开我们上面描述的
Ribbon.Predicate。想要对灰度发布进行扩展我们就离不开Predicate
Predicate
- 该类的作用就是进行断言,是google提出的思想。具体有关google轻轻点我
- 在ribbon专题中,我们简单的通过源码阅读的方式了解了ribbon是如何进行负载均衡以及内部负载均衡的策略的。有兴趣的可以点击主页查找。
- 今天我们来看看ribbon在负载均衡之前是如何在获取服务列表之后进行过滤的。
//根据输入返回断言 true or false
@GwtCompatible
public interface Predicate<T> {
//针对输入内容进行断言,该方法有且不仅有如下要求: 1、不会造成任何数据污染 2、在T的equals中相等在apply中是相同效果
boolean apply(@Nullable T input);
//返回两个Predicate是否相同。一般情况Predicate实现是不需要重写equals的 。 如果实现可以根据自己需求表明predicate是否相同。什么叫做相同就是两个predicate对象apply的结果相同即为对象相同
@Override
boolean equals(@Nullable Object object);
}
- 下面我们通过Predicate来实现下简单数据过滤。当然有的人会说为什么不用java8 stream过滤呢。这里只是为了为Ribbon中服务过滤铺路。至于ribbon为什么不使用流操作呢?个人角色google的Predicate在解耦上更加的方便吧。
@Test
public void pt() {
List<User> userList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
userList.add(new User(Long.valueOf(i+1), "张三"+(i+1)));
}
Predicate<User> predicate = new Predicate<User>() {
@Override
public boolean apply(User user) {
return user.getId() % 2 == 0;
}
};
ArrayList<User> users = Lists.newArrayList(Iterables.filter(userList, predicate));
System.out.println(users);
}
AbstractServerPredicate
前提回要
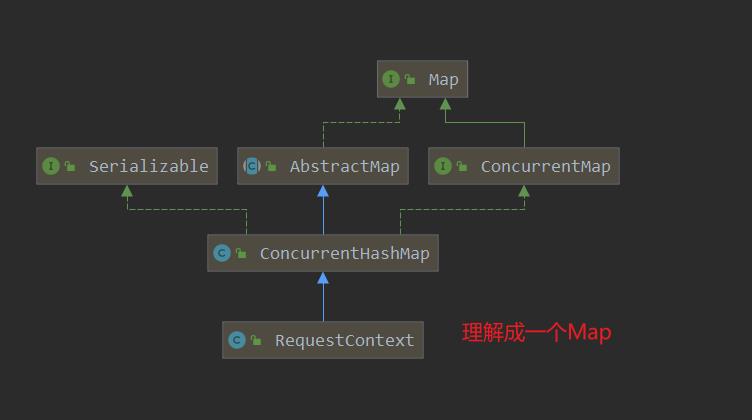
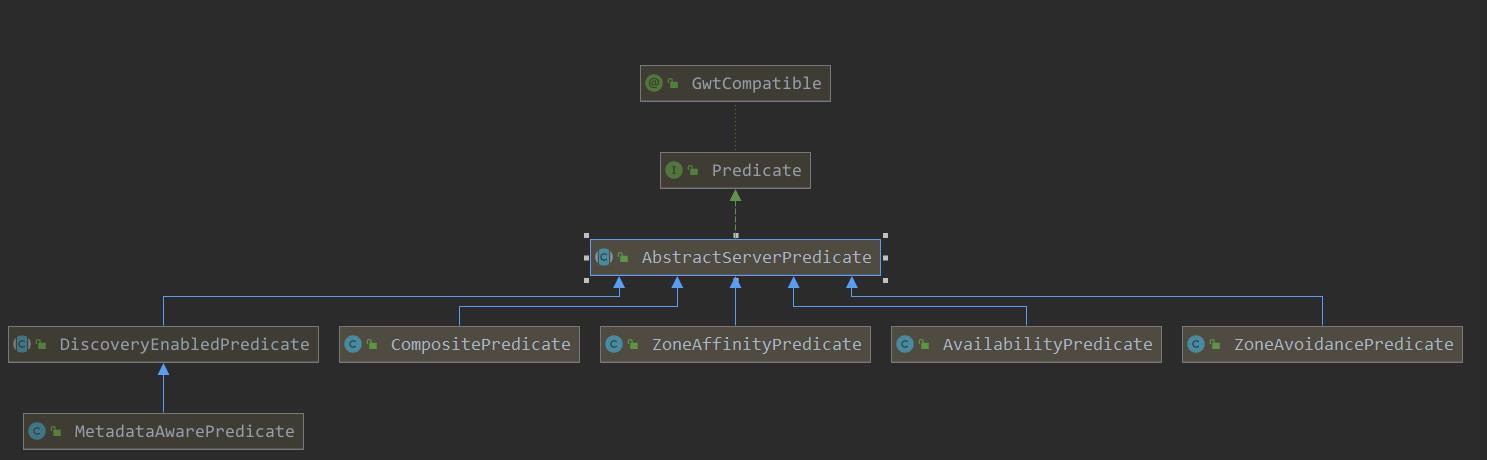
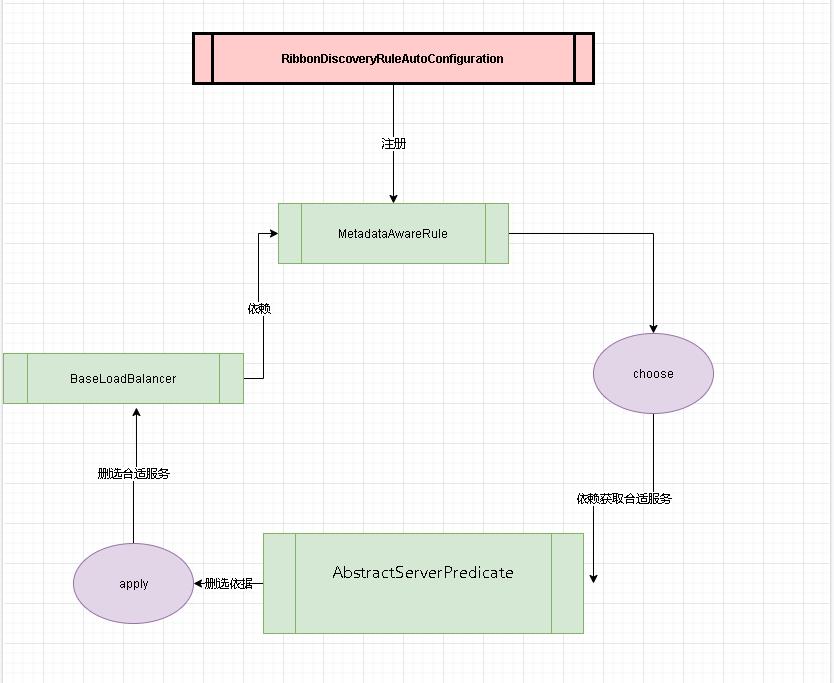
- 上面我们的类结构图中可以看出
AbstractServerPredicate是Predicate的实现类。这个类也是Ribbon在获取服务列表的关键角色。因为后面都是基于这个类进行功能扩展的。
jmnarloch初识
- 这是我在RIbbon中的内容。我们可以知道Ribbon最终是在
BaseLoadBalancer中进行负载均衡的。其内部的rule默认是new RoundRobinRule(),因为我们引入了io-jmnarloch。先看看内部的类结构
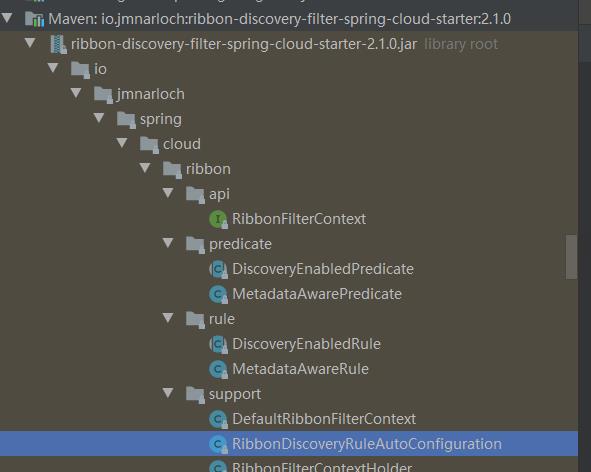
io-jmnarloch内部不是很复杂,至少Ribbon、feign这些比起来他真的是简单到家了。内部一个四个package
| package | 作用 |
|---|---|
| api | 提供上下文,供外部使用 |
| predicate | 提供获取服务列表过滤器 |
| rule | ribbon中的负载均衡策略实现 |
| support | 对上述的辅助包 |
注册负载Rule
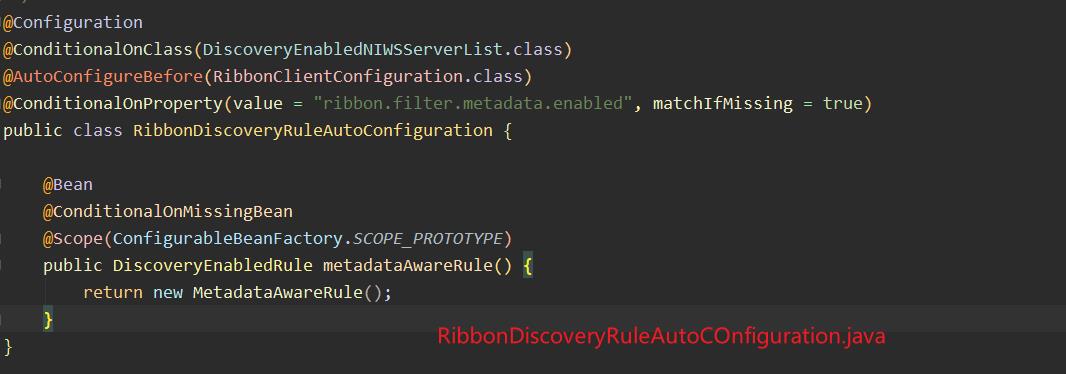
- 我们可以看到在support包中的
RibbonDiscoveryRuleAutoConfiguration中配置了rule包下定义好的Ribbon的负载均衡类Rule。
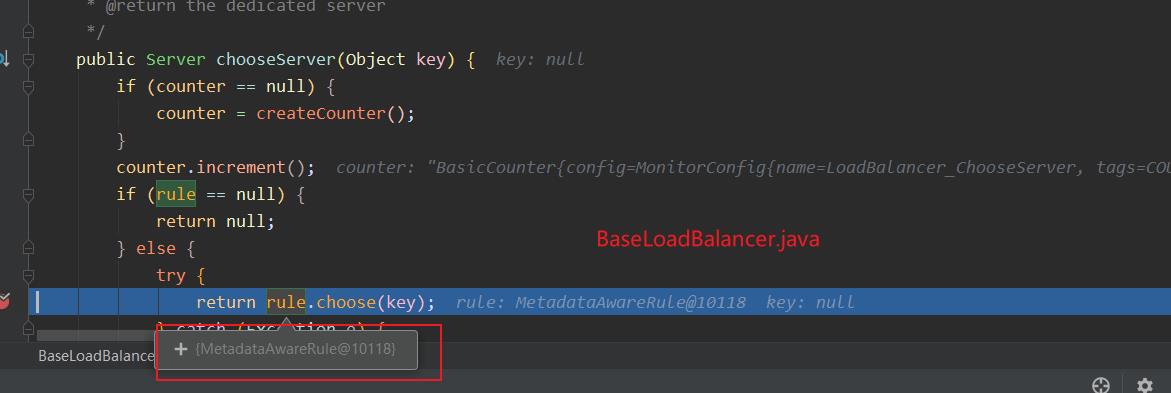
- 断电打到
BaseLoadBalancer中我们可以看到rule就是我们rule.MetadataAwareRule这个类。这里和ribbon章节说的好像有出入,我们在ribbon章节说需要自定义rule的时候需要在@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration = MySelfRule.class)这种方式。 - 其实在配置
DiscoveryEnabledRule的时候在注册的时候有@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)表示作用域
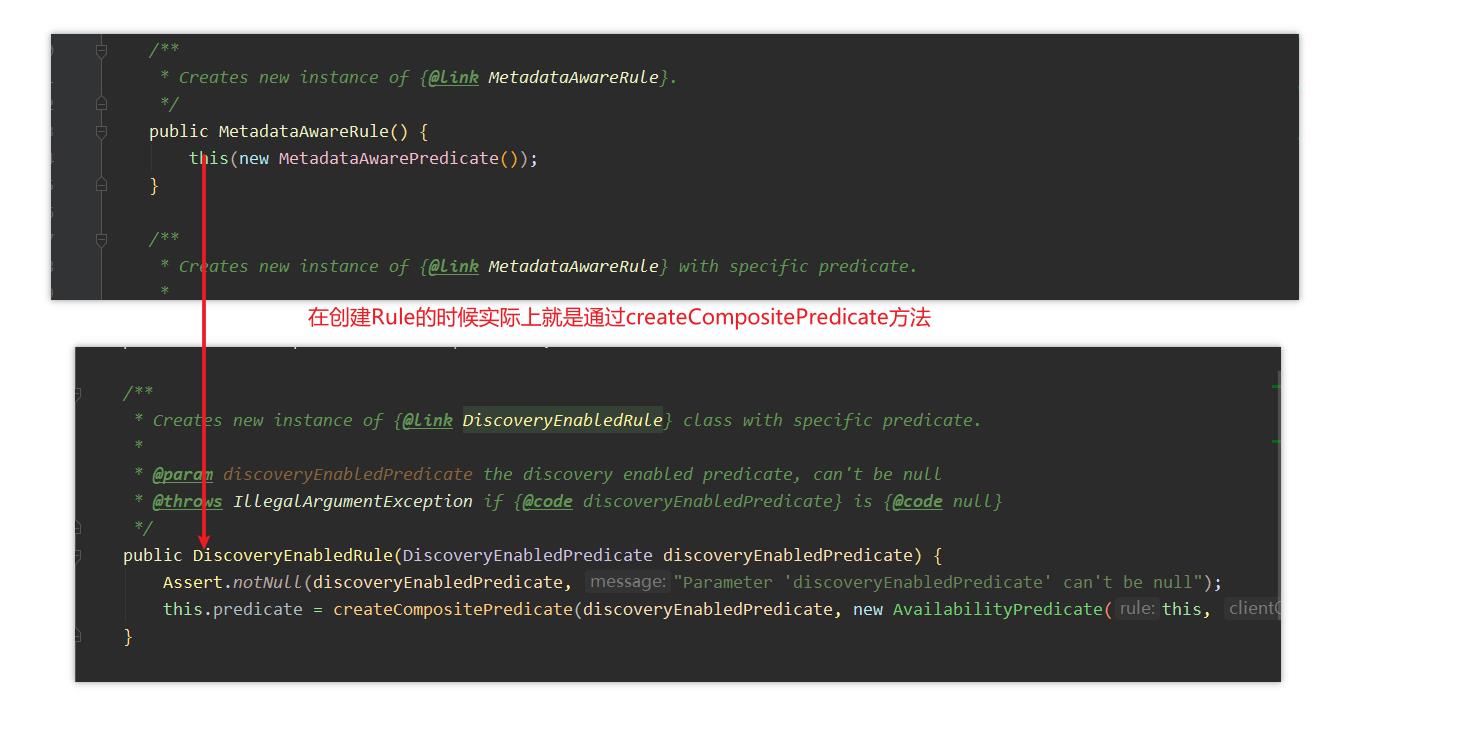
MetadataAwareRule如何过滤服务
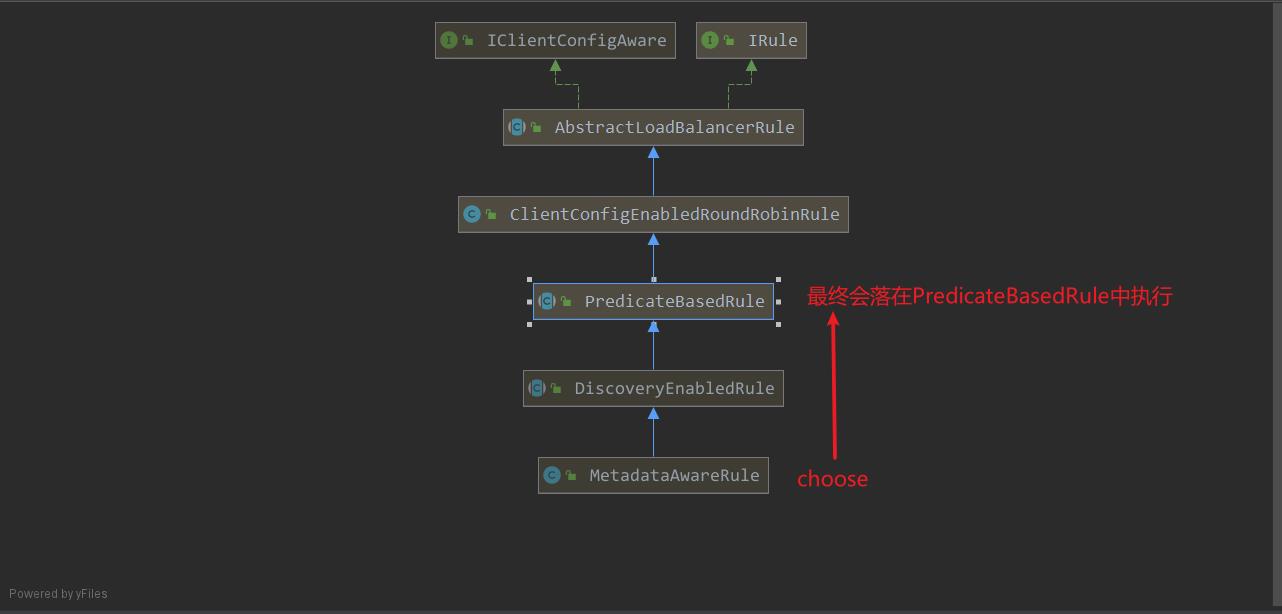
- 通过
MetadataAwareRule结合代码我们可以了解到最终是PredicateBaseRule#choose 在选择服务列表
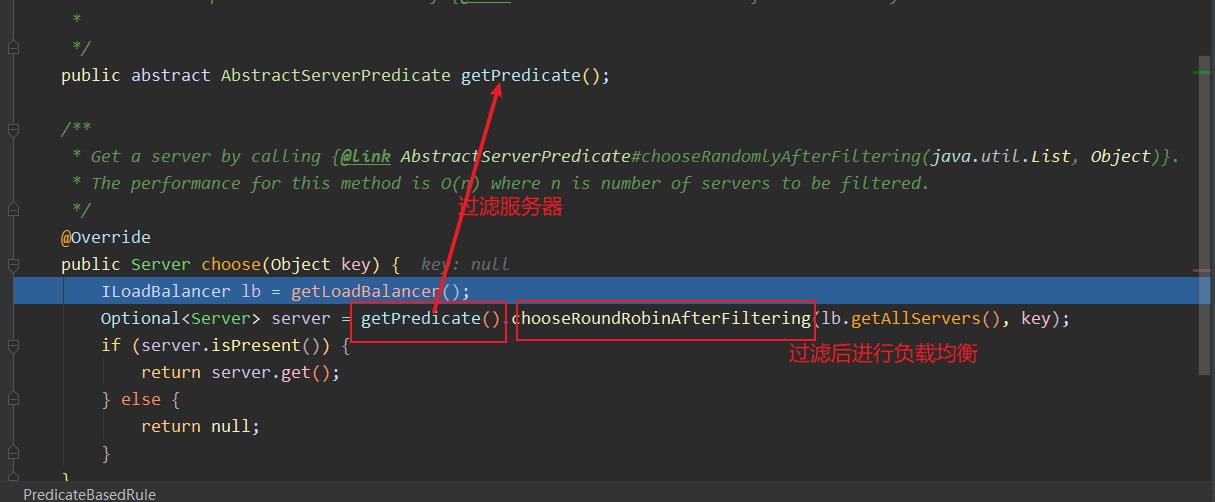
-
这个predicate 就是我们choose中getPredicate()方法获取的。所以在ribbon进行选择服务之前会通过
MetadataAwarePredicate进行过滤服务。 -
获取到过滤器对象后,我们就会执行
chooseRoundRibbinAfterFiltering.
回到AbstractServerPredicate
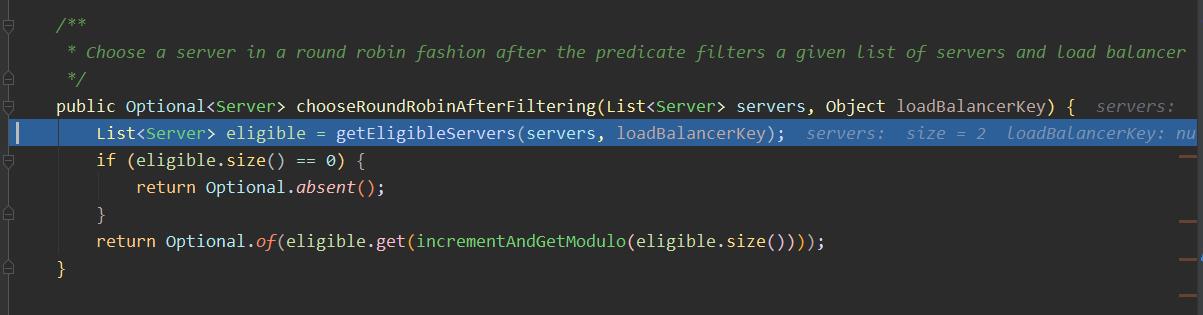
- 上文说到最终会通过Predicate去执行chooseRoundRobinAfterFiltering。 还记得一开始predicate的结构图了吗。
MetadataAwarePredicate最终继承AbstractServerPredicate。 而AbstractServerPredicate#chooseRoundRobinAfterFiltering是依赖getEligibleServers`来获取合适的服务列表的。 - 在
AbstractServerPredicate实现了好多chooseXXX的方法。因为ribbon默认是轮询方式所以在BaseLoadBalance中是选择Round对应的方法。这些我们都可以自己去修改方式。这里不赘述 Eligible译为合适的。getEligibleServers 翻译过来是获取合适的服务列表。

- 我们很明显的可以看到最终过滤的逻辑落在了apply方法上。
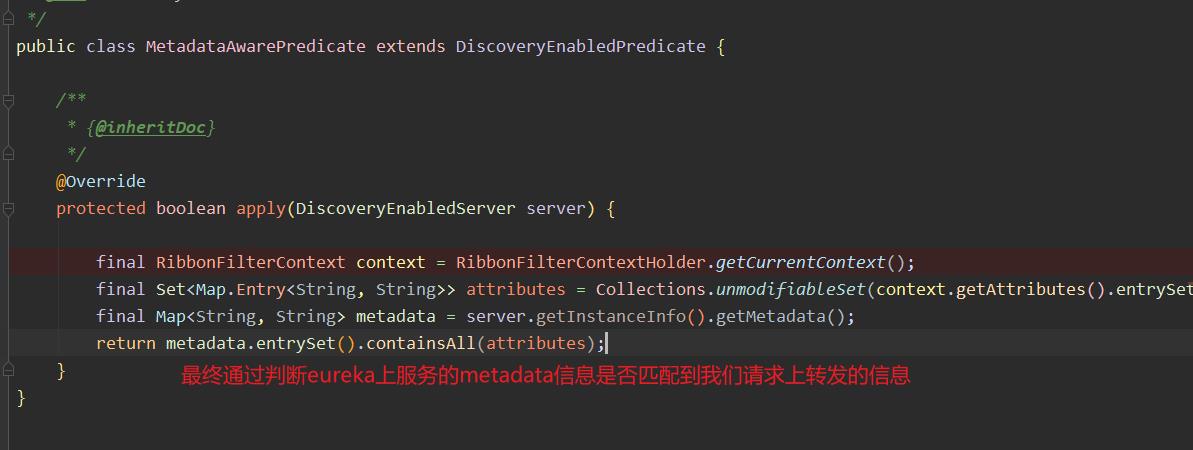
-
这就是我们上述通过
metadata-map:lancher配置我们的服务信息。 -
下面是
AbstractServerPredicate精简后样子。主要就是getEligibleServers这个方法。
子类
- 在上面
AbstractServerPredicate结构图中我们可以看到除了DiscoveryEnabledPredicate这个子类外,还有四个子类。
| 子类 | 作用 |
|---|---|
| AvailabilityPredicate | 过滤不可用服务器 |
| CompositePredicate | 组合模式,保证服务数量一定数量。换句话说就是服务太少则会一个一个fallback知道服务数量达到要求 |
| ZoneAffinityPredicate | 选取指定zone区域内的Server |
| ZoneAvoidancePredicate | 避免使用符合条件的server . 和ZoneAffinityPredicate功能相反 |
其他功能
排除路由
- 有的服务我们可能因为保密,在一段时间内不想让zuul代理路由。比如我们不让zuul路由order接口
zuul.ignored-patterns : /**/order/**
本地跳转
- 这个功能我觉得有点鸡肋。他的功能就是让zuul路由到自己服务上。其实为什么不直接访问自己的接口服务呢?这里我是没搞懂。
- 不过存在即有他的价值。比如我们有一个user模块我们的定位是处理用户的操作。但是他没有开发登陆接口。这个时候我们就可以在zuul中实现登陆接口并将user的登陆接口路由到zuul中的登陆(getTest)接口。
zuul:
routes:
user:
path: /cloud-user-service/**
url: forward:/zuul
http://localhost:7070/cloud-user-service/getTest?token=123此时我们访问的接口会最终路由到/zuul/getTest上。
请求头携带
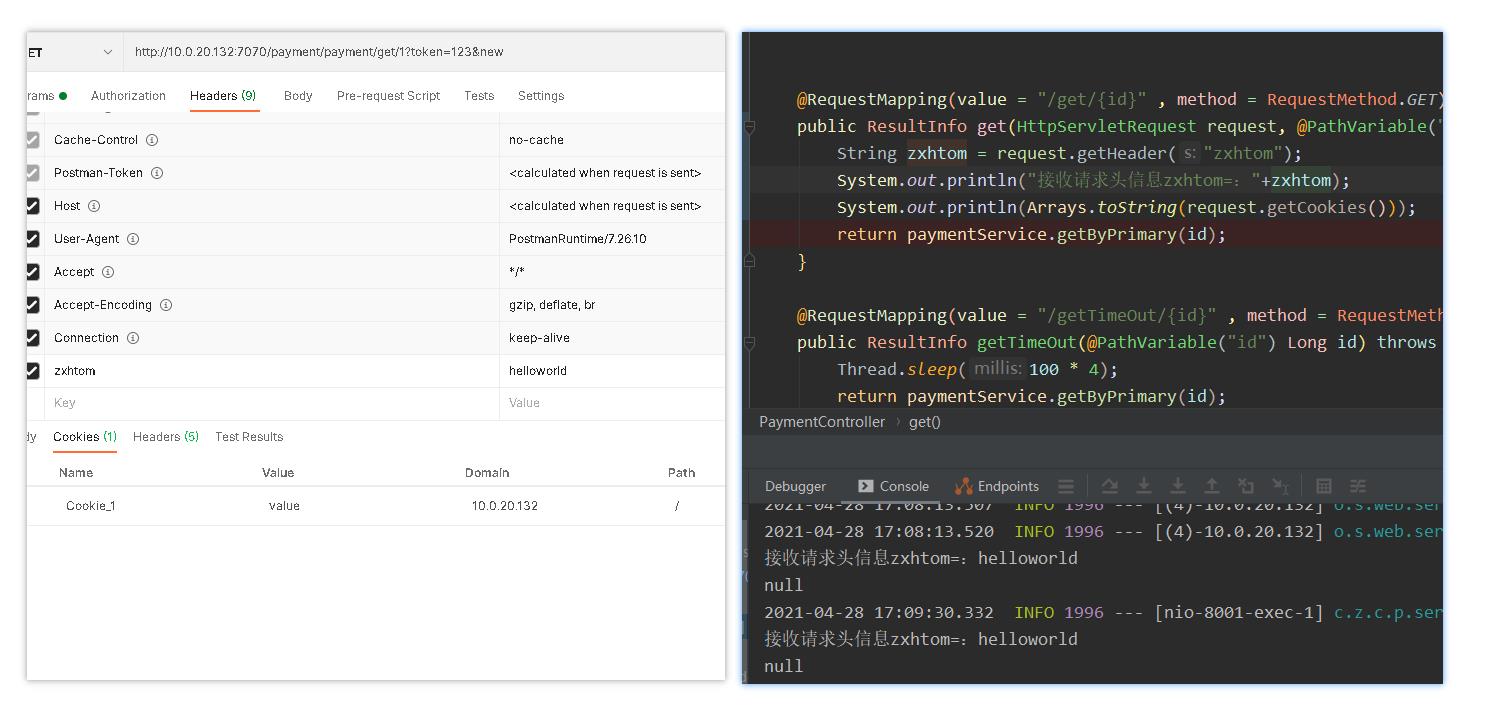
-
上面是我们zuul路由到payment的请求对象中信息。在请求头中我们添加了zxhtom=helloworld 。并且设置cookie对象 : Cookie_1=value
-
但是我们在payment中打印下两个值,cookie却没有带过来。
-
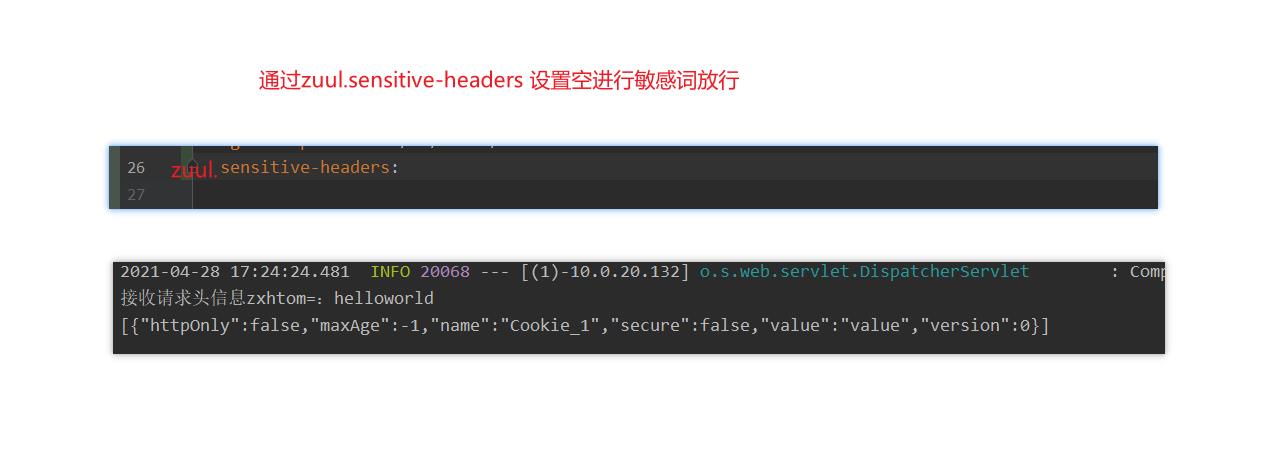
那是因为zuul在进行路由时为什么安全考虑会过滤掉敏感词请求头。 默认的Cookie、Set-Cookie、Authorization三个属性
-
但是我们为什么对路由分别对待。我们经常
zuul.routes.<router>.customSensitiveHeaders=ture
zuul.router.<router>.sensitiveHeaders=
hystrix与zuul
- 在上周我们刚好结束了hystrix的专题,在hystrix里我们提到了服务降级、熔断、限流。而zuul默认是整合hystrix的。我们在zuul路由接口的时候都是基于hystrix
- 但是zuul的hystrix至针对timeout异常进行捕获,其他的异常在zuul看来都是正常的返回信息,需要原模原样返回至客户端的
- 我们在zuul中可以实现统一的timeout的fallback 。 这样我们在服务超时会进行统一格式返回。
- 这里回顾下hystrix的东西,当我们服务zuul路由超时就会被hystrix记录,当达到一定错误比例就会触发熔断。在一定时间后会熔断半开状态,这个时间默认是5000ms , 也就是说我们后台服务宕机到重启后,我们zuul至少会有5S的fallback期 。 这个期间如果没有新的路由的理论上5S后就会恢复启用。
统一fallback
@Component
public class ServerFallback implements FallbackProvider {
@Override
public String getRoute() {
return "cloud-payment-service";
}
@Override
public ClientHttpResponse fallbackResponse(String route, Throwable cause) {
if (cause instanceof HystrixTimeoutException) {
return response(HttpStatus.GATEWAY_TIMEOUT);
} else {
return response(HttpStatus.INTERNAL_SERVER_ERROR);
}
}
private ClientHttpResponse response(HttpStatus status) {
return new ClientHttpResponse() {
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpStatus getStatusCode() throws IOException {
return status;
}
@Override
public int getRawStatusCode() throws IOException {
return status.value();
}
@Override
public String getStatusText() throws IOException {
return status.getReasonPhrase();
}
@Override
public void close() {
}
};
}
}
- 值得注意的是,我们在上面动态路由时将
cloud-payment-service转换成了payment , 但是这个时候我们的getRoute里还是需要指定注册在eureka里的服务名及cloud-payment-service,如果换成了payment是没有效果的。这里读者自行测试下就理解了。
不足之处
- zuul目前对udp、ws支持的不是很友好。笔者这里也没有进行相关的尝试
- 在websocket通过zuul的时候会将回轮询的方式,而且我们还需要处理超时的问题。
源码
有时间准备研读下 以上是关于前端再也不用头疼了---分布式系列之网关zuul包揽全局的主要内容,如果未能解决你的问题,请参考以下文章 SpringCloud学习系列之七 ----- Zuul路由网关的过滤器和异常处理 Spring Cloud Alibaba 系列之 Gateway(网关) SpringCloud系列之四---Zuul网关整合Swaagger2管理APIZuulProxyA