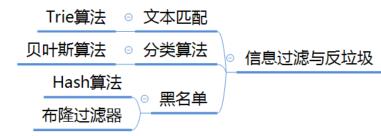
27 信息过滤与反垃圾
Posted water___Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了27 信息过滤与反垃圾相关的知识,希望对你有一定的参考价值。
我国的信息过滤技术是走在世界前列的,尽管如此,在各种社区网站和个人邮箱中, 广告和垃圾信息仍然屡见不鲜、泛滥成灾。
常用的信息过滤与反垃圾手段有以下几种。
1 文本匹配
文本匹配主要解决敏感词过滤的问题。通常网站维护一份敏感词列表,如果用户发 表的信息含有列表中的敏感词,则进行消毒处理(将敏感词转义为***)或拒绝发表。
那么如何快速地判断用户信息中是否含有敏感词呢?如果敏感词比较少,用户提交 信息文本长度也较短,可直接使用正则表达式匹配。但是正则表达式的效率一般较差, 当敏感词很多,用户发布的信息也很长,网站并发量较高时,就需要更合适的方法来完 成,这方面公开的算法有很多,基本上都是Trie树的变种,空间和时间复杂度都比较好 的有双数组Trie算法等。
Trie算法的本质是确定一个有限状态自动机,根据输入数据进行状态转移。双数组Trie算法优化了 Trie算法,利用两个稀疏数组存储树结构,base数组存储Trie树的节点, check数组进行状态检查。双数组Trie数需要根据业务场景和经验确定数组大小,避免数组过大或者冲突过多。
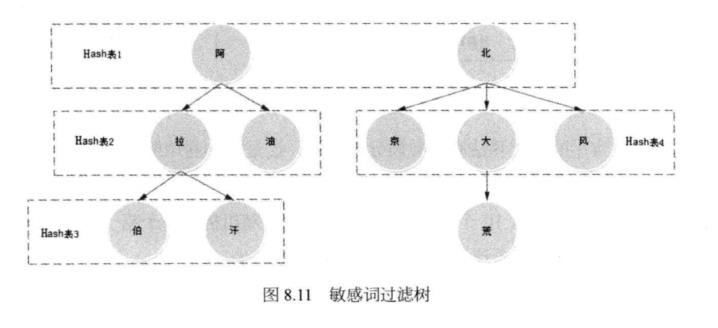
另一种更简单的实现是通过构造多级Hash表进行文本匹配。假设敏感词表包含敏感 词:阿拉伯、阿拉汗、阿油、北京、北大荒、北风。那么可以构造如图8.11所示的过滤 树,用户提交的信息逐字顺序在过滤树中匹配。过滤树的分支可能会比较多,为了提高 匹配速度,减少不必要的查找,同一层中相同父节点的字可放在Hash表中。该方案处理 速度较快,稍加变形,即可适应各种过滤场景,缺点是使用Hash表会浪费部分内存空间,如果网站敏感词数量不多,浪费部分内存还是可以接受的。
有时候,为了绕过敏感词检查,某些输入信息会被做一些手脚,如“阿_拉_伯”,这 时候还需要对信息做降噪预处理,然后再进行匹配。
2 分类算法
早期网站识别垃圾信息的主要手段是人工方式,后台运营人员对信息进行人工审核。 对大型网站而言,特别是以社交为主的Web2.0网站,如Facebook或Linkedin这样的网 站,每天用户提交的信息数千万计,许多垃圾信息混杂其中,影响用户体验;而对于B2B 类的电子商务交易撮合网站,用户主要通过站内信等手段进行商品信息咨询,有时候站 内信充斥大量广告,甚至淹没正常询盘,引起用户严重不满和投诉。
对如此海量的信息进行人工审核是不现实的,对广告贴、垃圾邮件等内容的识别比 较好的自动化方法是采用分类算法。
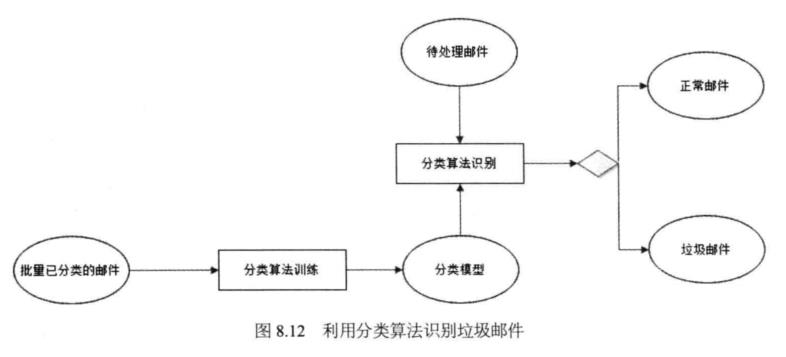
以反垃圾邮件为例说明分类算法的使用,如图8.12所示。先将批量已分类的邮件样 本(如50000封正常邮件,2000封垃圾邮件)输入分类算法进行训练,得到一个垃圾邮 件分类模型,然后利用分类算法结合分类模型对待处理邮件进行识别。
比较简单实用的分类算法有贝叶斯分类算法,这是一种利用概率统计方法进行分类的算法。贝叶斯算法解决概率论中的一个典型问题:一号箱子放有红色球和白色球各20 个,二号箱子放有白色球10个,红色球30个,现在随机挑选一个箱子,取岀来一个球 的颜色是红色的,请问这个球来自一号箱子的概率是多少。
利用贝叶斯算法进行垃圾邮件的识别基于同样原理,根据已分类的样本信息获得一 组特征值的概率,如“茶叶”这个词出现在垃圾邮件中的概率为20%,出现在非垃圾邮 件中的概率为1%,就得到分类模型。然后对待处理邮件提取特征值,比如取到了茶叶这 个特征值,结合分类模型,就可以判断其分类。贝叶斯算法得到的分类判断是一个概率 值,因此会存在误判(非垃圾邮件判为垃圾邮件)和漏判(垃圾邮件判为非垃圾邮件)。
贝叶斯算法认为特征值之间是独立的,所以也被称作是朴素贝叶斯算法(Native Bayes ),这个假设很多时候是不成立的,特征值之间具有关联性,通过对朴素贝叶斯算法 增加特征值的关联依赖处理,得到TAN算法。更进一步,通过对关联规则的聚类挖掘, 得到更强大的算法,如ARCS算法(Association Rule Clustering System )等。但是由于贝 叶斯分类算法简单,处理速度快,仍是许多实时在线系统反垃圾的首选。
分类算法除了用于反垃圾,还可用于信息自动分类,门户网站可用该算法对采集来 的新闻稿件进行自动分类,分发到不同的频道。邮箱服务商根据邮件内容推送的个性化 广告也可以使用分类算法提高投送相关度。
3 黑名单
对于垃圾邮件,除了用分类算法进行内容分类识别,还可以使用黑名单技术,将被 报告的垃圾邮箱地址放入黑名单,然后针对邮件的发件人在黑名单列表中查找,如果查 找成功,则过滤该邮件。
黑名单也可用于信息去重,如将文章标题或者文章关键段落记录到黑名单中,以减 少搜索引擎收录重复信息等用途。
黑名单可以通过Hash表实现,该方法实现简单,时间复杂度小,满足一般场景使用。 但是当黑名单列表非常大时,Hash表需要占据极大的内存空间。例如在需要处理10亿个 黑名单邮件地址列表的场景下,每个邮件地址需要8个字节的信息指纹,即需要8GB内 存,为了减少Hash冲突,还需要一定的Hash空间冗余,假如空间利用率为50%,则需 要16GB的内存空间。随着列表的不断增大,一般服务器将不可承受这样的内存需求。而 且列表越大,Hash冲突越多,检索速度越慢。
在对过滤需求要求不完全精确的场景下,可用布隆过滤器代替Hash表。布隆过滤器 是用它的发明者巴顿•布隆的名字命名的,通过一个二进制列表和一组随机数映射函数实现,如图8.13所示。
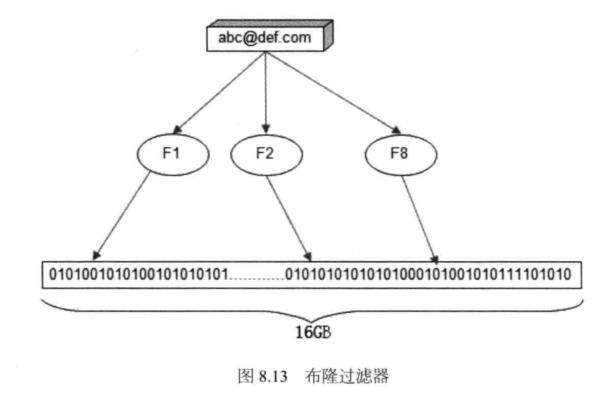
仍以需要处理10亿邮件地址黑名单列表为例,在内存中建立一个2GB大小的存储空间,即16GB个二进制bit,并全部初始化为0。要将一个邮箱地址加入黑名单时,使用8 个随机映射函数(F1,F2,…,F8 )得到0〜16GB范围内的8个随机数,从而将该邮箱地址映 射到16GB-进制存储空间的8个位置上,然后将这些位置置为"当要检查一个邮箱地
址是否在黑名单中时,使用同样的映射函数,得到16GB空间8个位置上的bit,如果这
可以看到,处理同样数量的信息,布隆过滤器只使用Hash表所需内存的1/8。但是布隆过滤器有可能导致系统误判(布隆过滤器检查在黑名单中,但实际却并未放入过)。因为一个邮箱地址映射的8个bit可能正好都被其他邮箱地址设为1 了,这种可能性极小, 通常在系统可接受范围内。但如果需要精确的判断,则不适合使用布隆过滤器。
以上是关于27 信息过滤与反垃圾的主要内容,如果未能解决你的问题,请参考以下文章