prometheus cAdvisor 监控docker CPU利用率 教程
Posted 软件工程小施同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了prometheus cAdvisor 监控docker CPU利用率 教程相关的知识,希望对你有一定的参考价值。
一、方案
1. 背景
promethus,原理是获取所有全量标签,然后按需过滤
监控Docker容器,Prometheus提供了几种方法来监控Docker,包括一些自定义exporter。
然而,这些exporter一般都不会用到,推荐的方法是使用Google的cAdvisor工具。
在Docker守护进程上,cAdvisor作为Docker容器运行,单个cAdvisor容器返回针对Docker守护进程和所有正在运行的容器的指标。
Prometheus支持通过它导出指标,并将数据传输到其他各种存储系统。
(https://www.talkwithtrend.com/Question/437051)
2. 配置
(1)监控服务器
需要安装2个服务:
Prometheus Server(普罗米修斯监控主服务器 )
Grafana (展示普罗米修斯监控界面)
(2)被监控的
只需安装2个:
Node Exporter (收集Host硬件和操作系统信息)
cAdvisor (负责收集Host上运行的容器信息)
二、安装
1. 安装Node Exporter
所有被监控节点运行以下命令安装Node Exporter 容器
安装命令:docker pull prom/node-exporter:latest
制作启动脚本: vi node-export-start.sh
docker run -d -p 9100:9100 \\
-v "/proc:/host/proc" \\
-v "/sys:/host/sys" \\
-v "/:/rootfs" \\
-v "/etc/localtime:/etc/localtime" \\
prom/node-exporter \\
--path.procfs /host/proc \\
--path.sysfs /host/sys \\
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"启动Node Exporter组件:./node-export-start.sh
验证是否成功:访问网址 http://本机ip:9100/metrics ,虚拟机数据上报成功!

2.安装Prometheus主服务(监控汇总)
主服务节点运行以下命令安装Prometheus容器
安装命令:docker pull prom/prometheus:latest
制作启动脚本: vi prometheus-start.sh
docker run -d -p 9090:9090 \\
-v /home/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \\
-v "/etc/localtime:/etc/localtime" \\
--name prometheus \\
prom/prometheus配置数据文件:prometheus.yml
sudo mkdir -p /home/docker/prometheus
cd /home/docker/prometheus
vim prometheus.yml配置文件中的 static_configs要修改
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090','192.168.64.137:9100','192.168.64.138:9100','192.168.64.139:9100','192.168.64.140:9100']启动Prometheus组件:./prometheus-start.sh
验证是否成功:访问网址 http://本机ip/targets ,监控数据汇总成功!
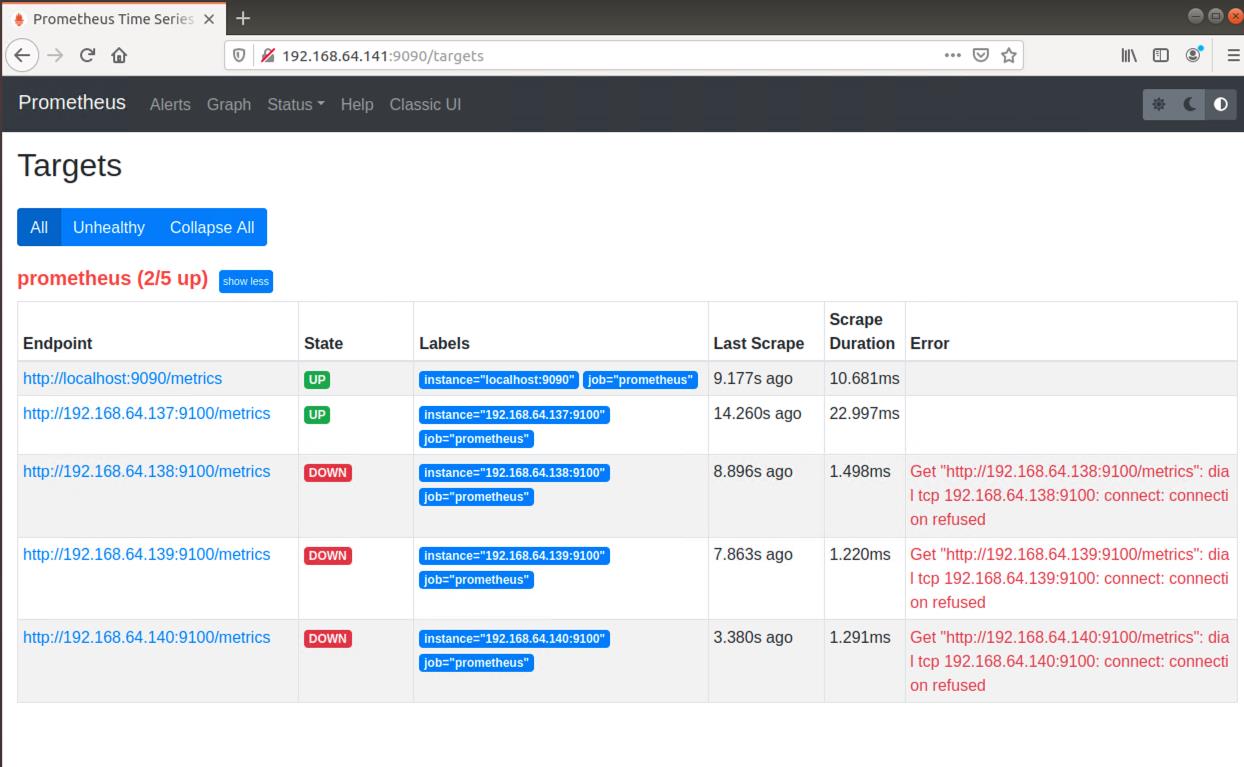
3. 安装Grafana组件(图形化展示)
(1)安装Grafana
安装命令:docker pull grafana/grafana:latest
制作启动脚本: vi grafana-start.sh
docker run -d -i -p 3000:3000 \\
-v "/etc/localtime:/etc/localtime" \\
-e "GF_SERVER_ROOT_URL=http://grafana.server.name" \\
-e "GF_SECURITY_ADMIN_PASSWORD=admin123" \\
grafana/grafana启动Grafana组件:./grafana-start.sh
验证是否成功:访问网址 http://本机ip:3000/metrics 或者 登录界面 http://本机ip:3000,用户名/密码:admin/admin123,登录成功!
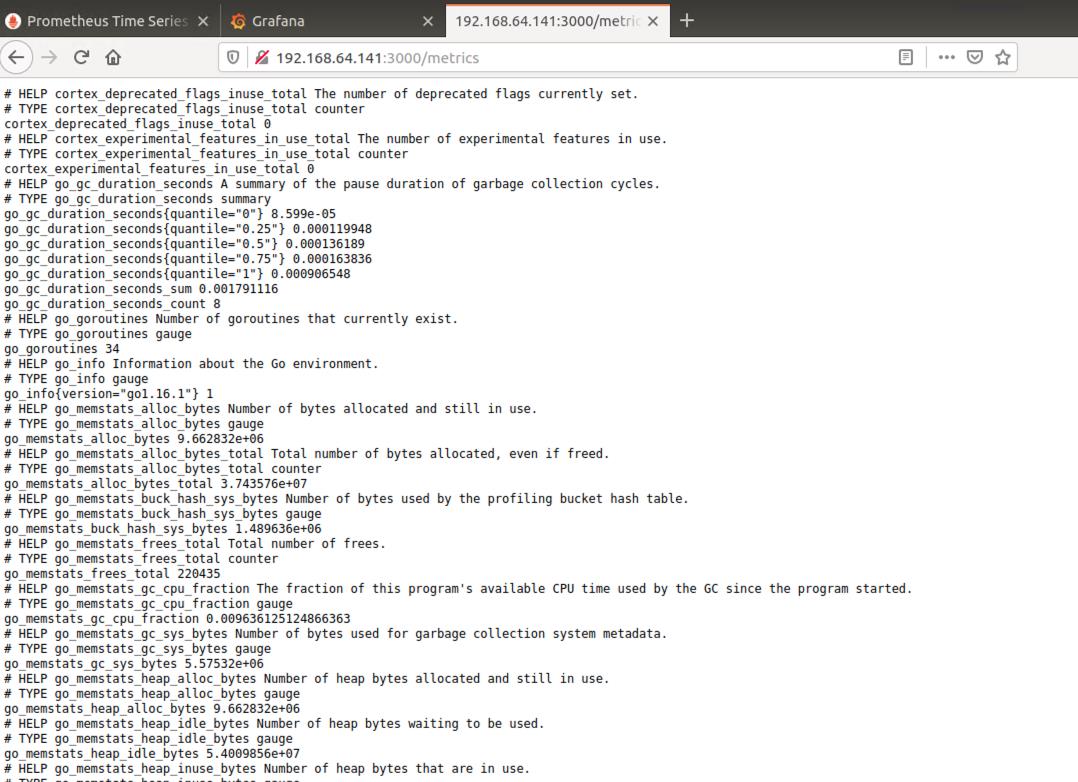

(2)Grafana组件使用简介
添加prometheus数据源
下面我们把prometheus服务器收集的数据做为一个数据源添加到 grafana,让grafana可以得到prometheus的数据。
选择prometheus
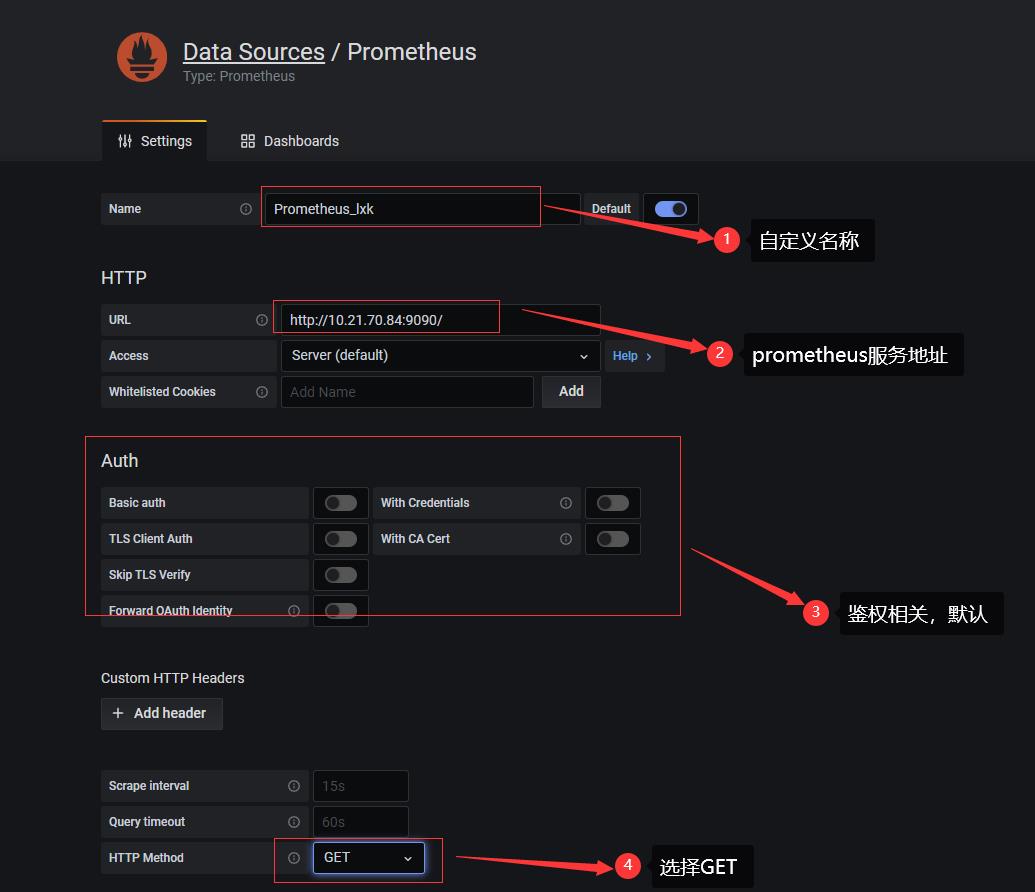
然后点击save and test
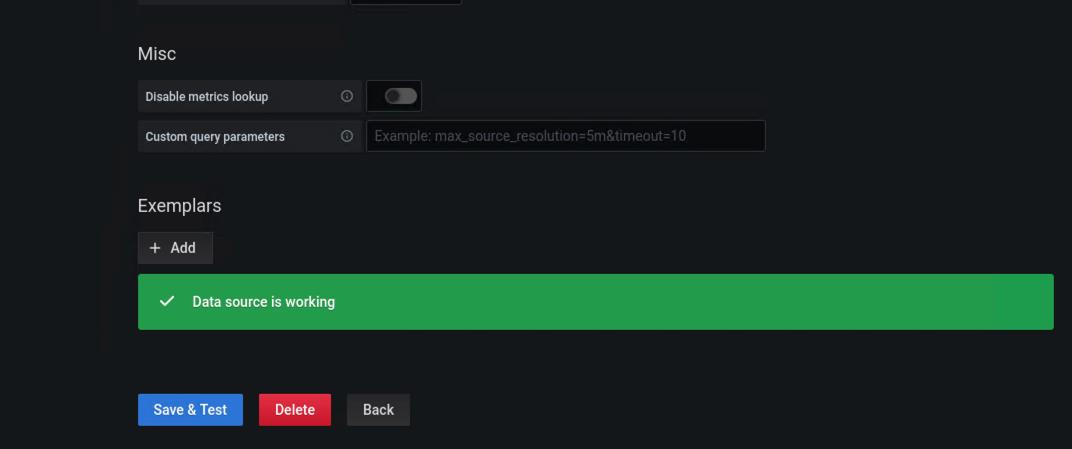
选取数据源做图形显示

导入模板
官网下载地址:https://grafana.com/grafana/dashboards
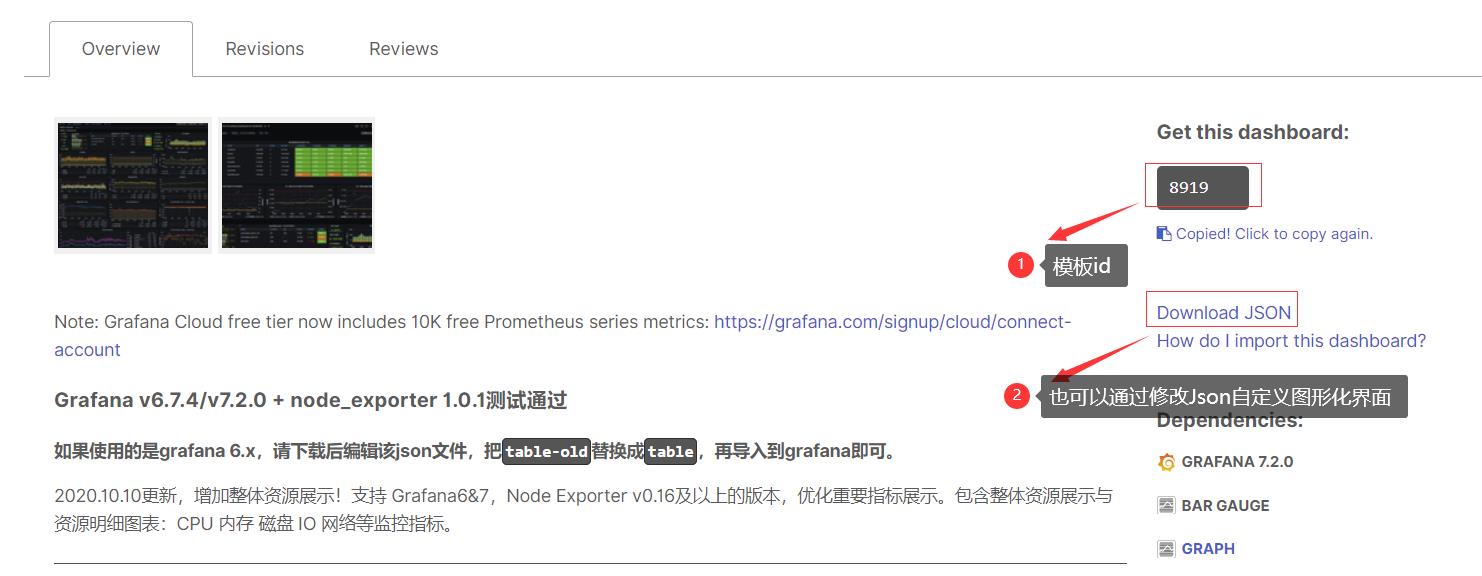
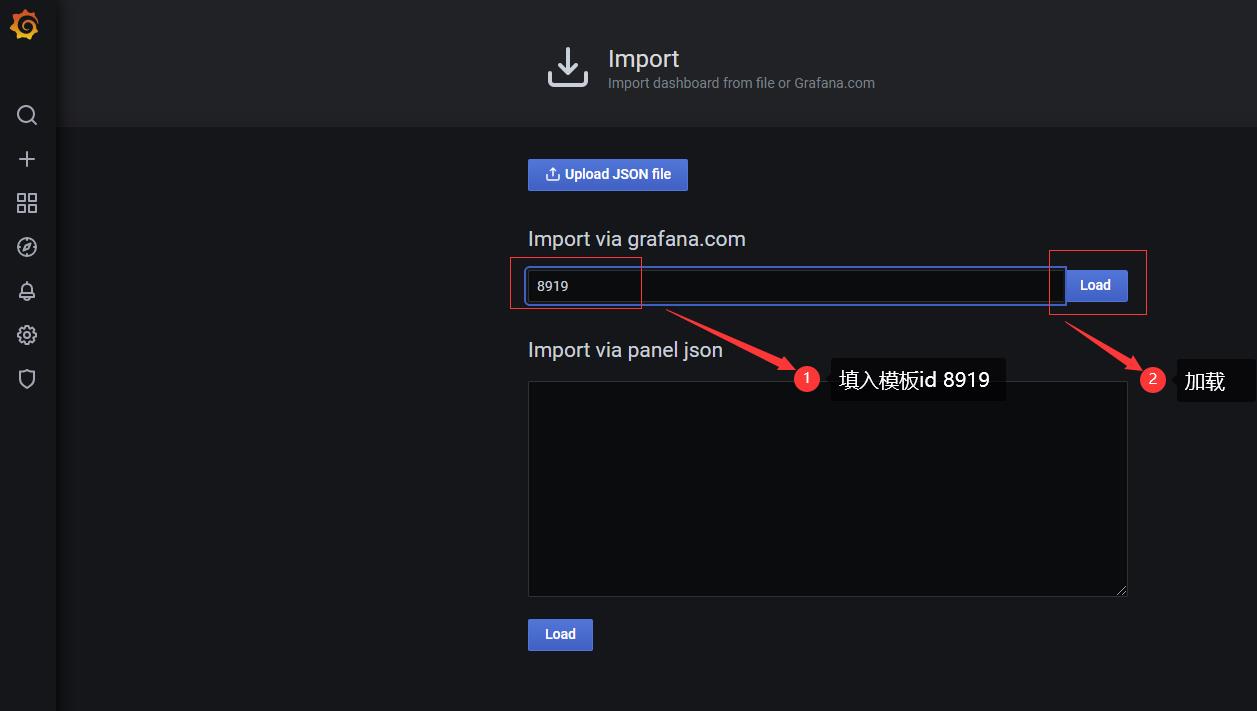
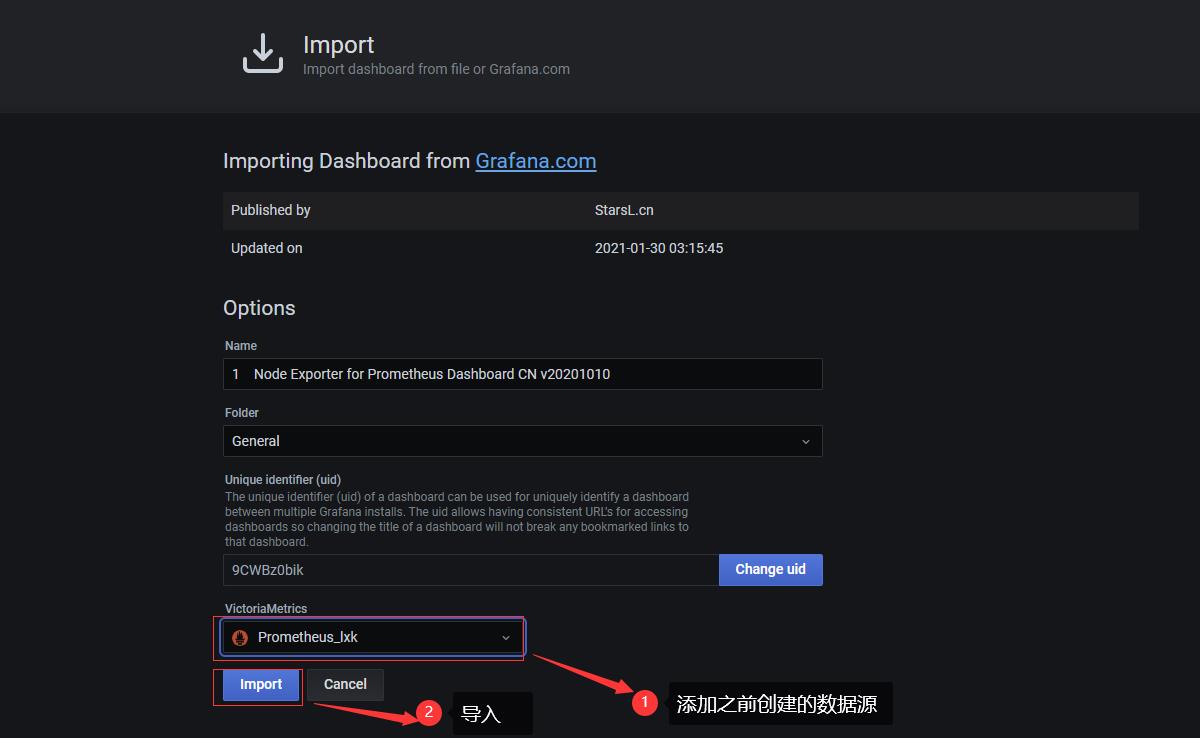
在dashboard可以查看到
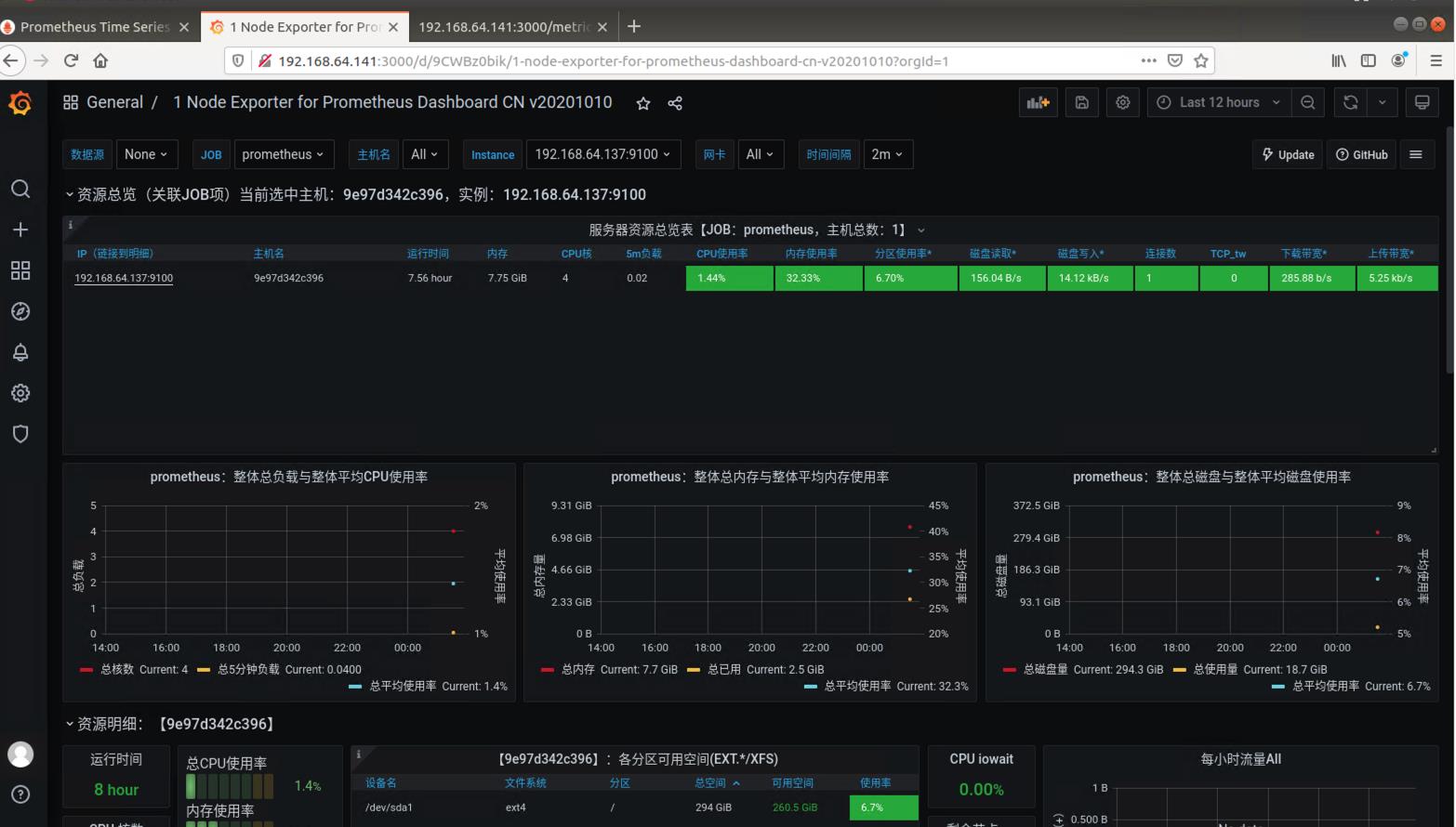
4. 安装cadvisor
cadvisor 不仅可以搜集一台机器上所有运行的容器信息还提供基础查询界面和 http 接口,方便 Prometheus 进行数据抓取。
使用 docker pull 下载最新版本的 cadvisor
docker pull google/cadvisor:latest启动脚本
vim cadvisor-start.shdocker run \\
--volume=/:/rootfs:ro \\
--volume=/var/run:/var/run:rw \\
--volume=/sys:/sys:ro \\
--volume=/var/lib/docker/:/var/lib/docker:ro \\
--volume=/dev/disk/:/dev/disk:ro \\
--publish=18104:8080 \\
--detach=true \\
--name=cadvisor \\
google/cadvisor:latest启动
./cadvisor-start.sh当启动成功后,使用 docker ps 你会看到 cadvisor 的启动情况

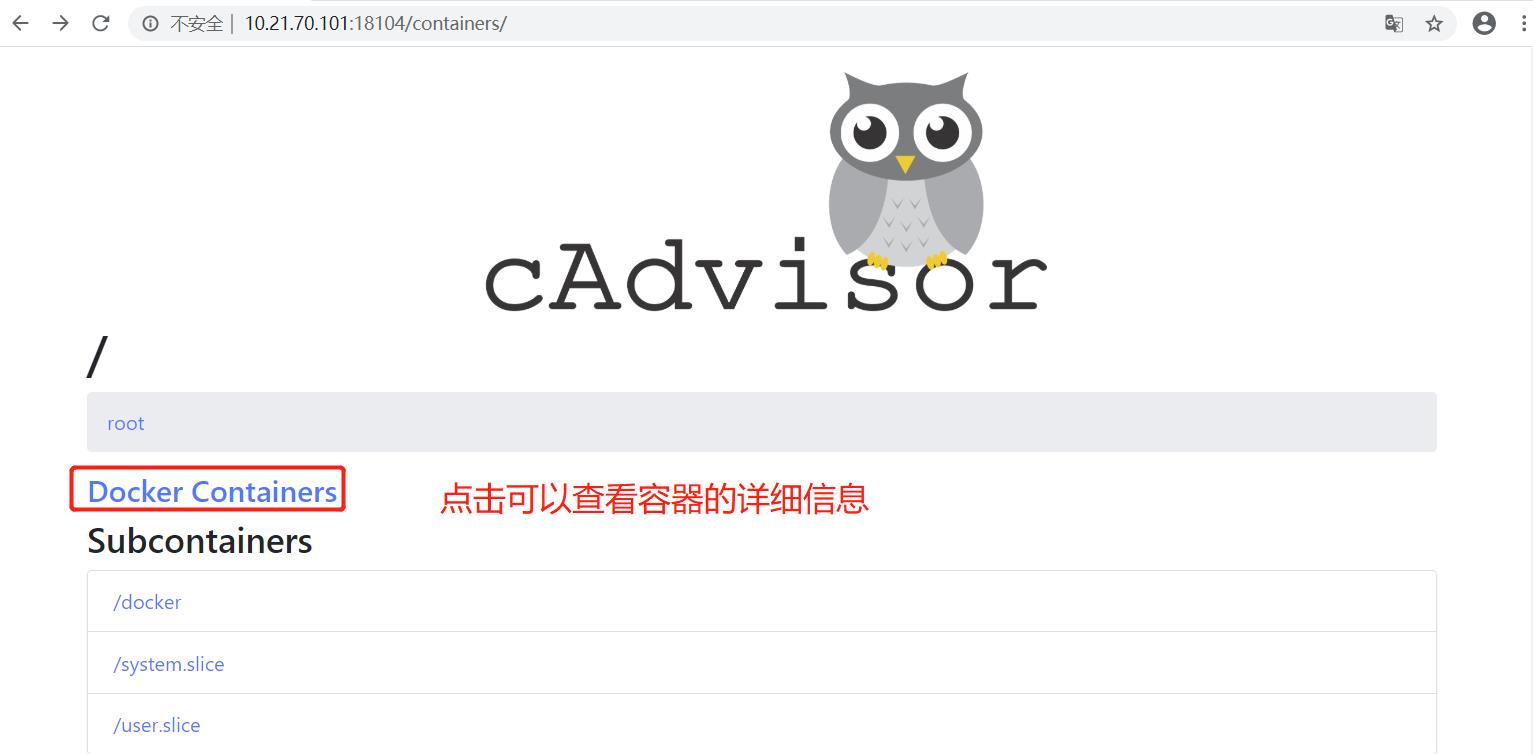
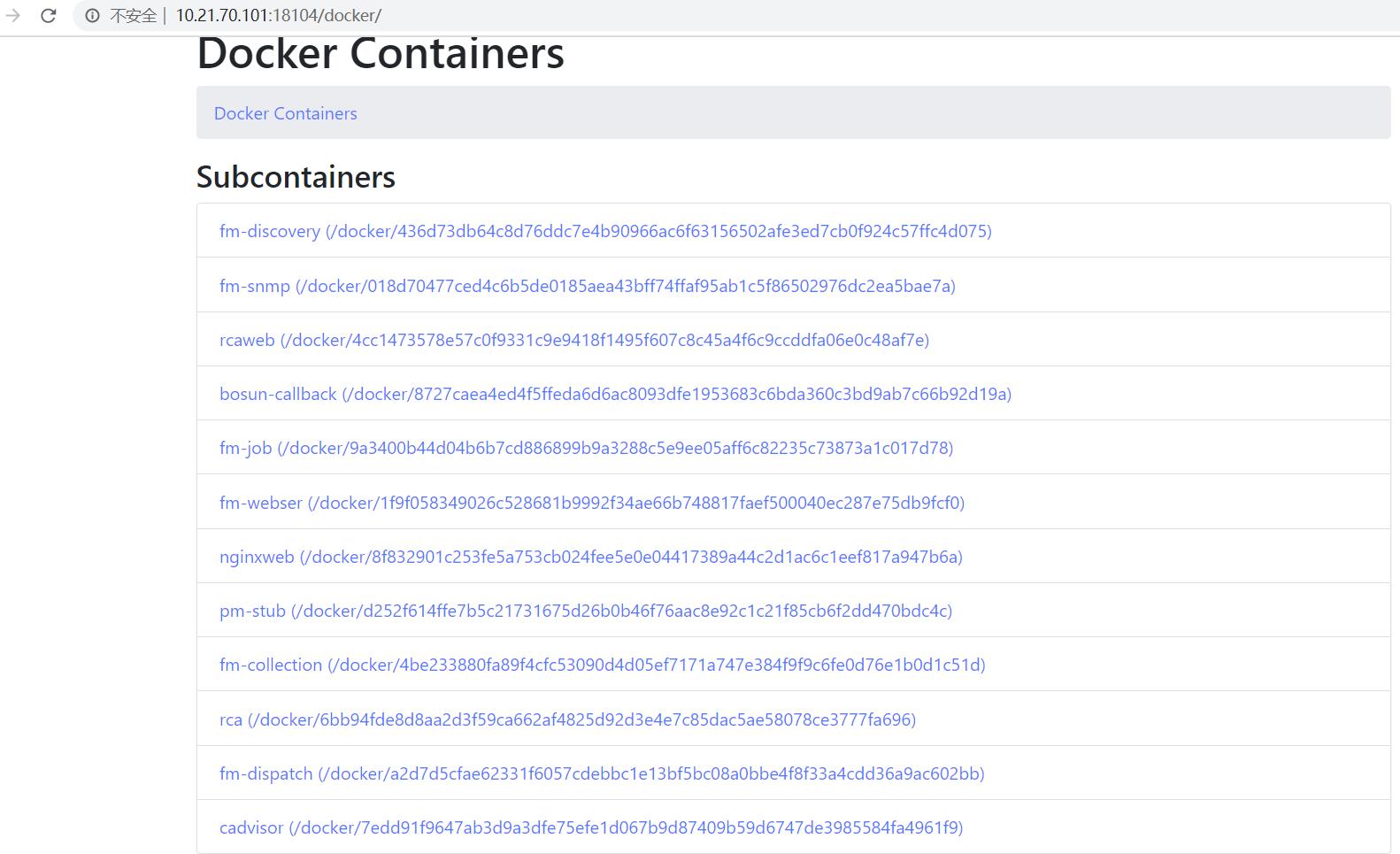
访问http://本机ip:18104/metrics 可以查看其暴露给 Prometheus 的所有数据(我访问不到这个网址)
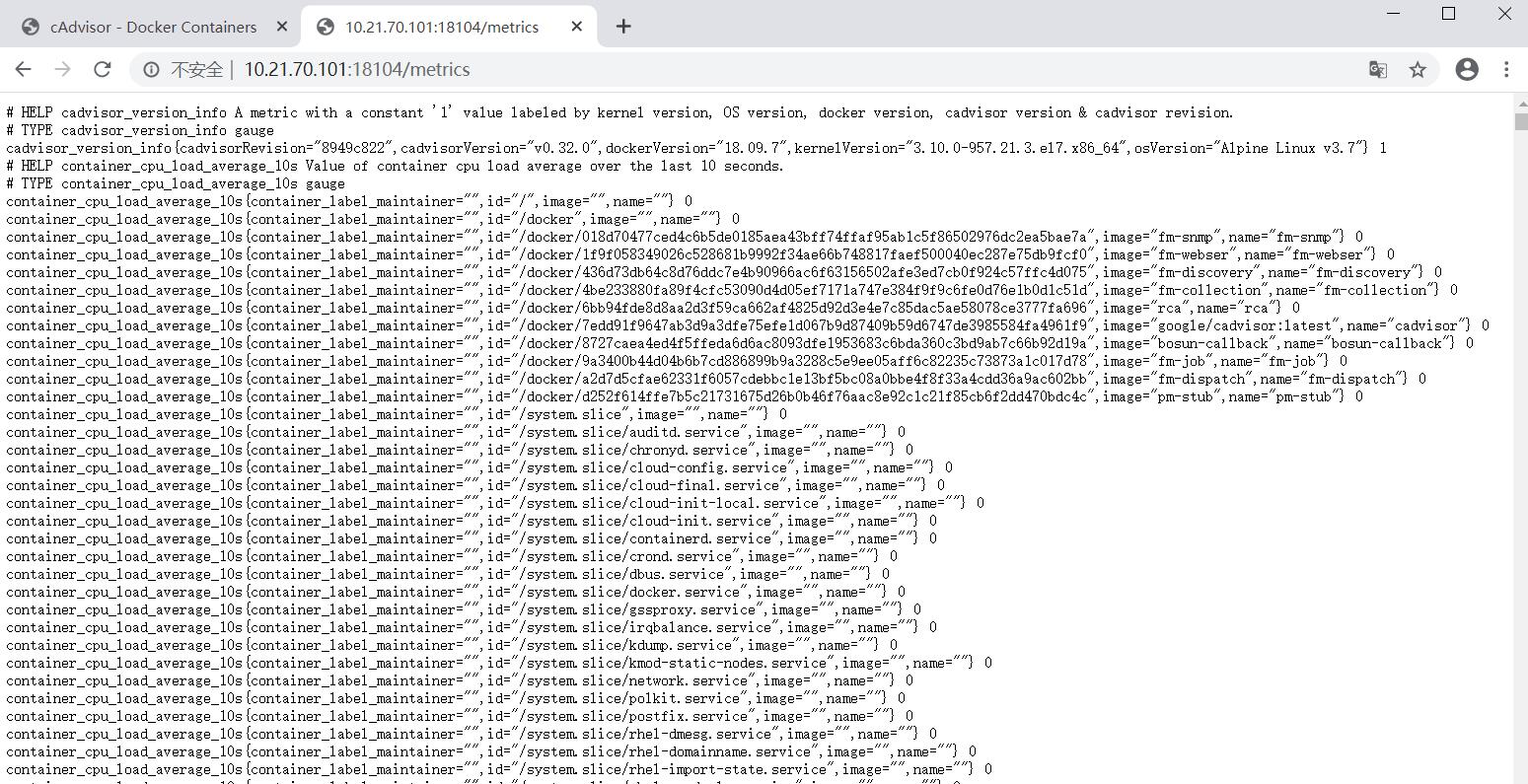
5. 修改Prometheus Server配置:
修改vi prometheus.yml 文件,添加cAdvisor 信息
cd /home/docker/prometheus/
vim prometheus.yml
# my global config
global:
scrape_interval: 1s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 1s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090','192.168.64.137:9100','192.168.64.138:9100','192.168.64.139:9100','192.168.64.140:9100']
- job_name: 'cadvisor'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.64.137:18104','192.168.64.138:18104','192.168.64.139:18104','192.168.64.140:18104']
labels:
lable: "docker"
重启Prometheus Server服务
[root@slave1 prometheus]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9237d501c6af grafana/grafana "/run.sh" 2 hours ago Up 2 hours 0.0.0.0:3000->3000/tcp dazzling_khorana
abe5e13d00d1 prom/prometheus "/bin/prometheus --c…" 2 hours ago Up 2 hours 0.0.0.0:9090->9090/tcp prometheus
[root@slave1 prometheus]#
[root@slave1 prometheus]# docker stop abe5e13d00d1
abe5e13d00d1
[root@slave1 prometheus]# docker rm abe5e13d00d1
abe5e13d00d1
[root@slave1 prometheus]# ./prometheus-start.sh
c6b6902ddd080a25e1a56cabdff84fa06bc548993fa3d6e75dc3f1c520fcde29加载配置

或者重启


FAQ: 监控数据为空或者 N/A
Prometheus监控各个节点对时间要求严格,在部署服务之前务必将所有机器的时间进行同步,包括用来展示和查询的windows机器。
相关请查看该issue https://github.com/prometheus/prometheus/issues/1022
Prometheus监控docker容器
https://blog.csdn.net/lixinkuan328/article/details/107780118
https://lixinkuan.blog.csdn.net/article/details/113631550
https://lixinkuan.blog.csdn.net/article/details/107780219
三、监控Linux主机CPU、内存、磁盘使用率
1.监控CPU使用率
CPU的监控项名称是:node_cpu_seconds_total,使用总量
直接执行node_cpu_seconds_total查询后会出现很多监控指标,显然不是想要的
node_cpu_seconds_total执行后会出现很多监控指标,其中各种类型的比如系统态、用户态都会由mode标签来区分
我们想要查询CPU的使用率的思路是:
查出当前空闲的CPU百分比,最后用100减去,mode标签值idle就表示当前空闲的CPU值
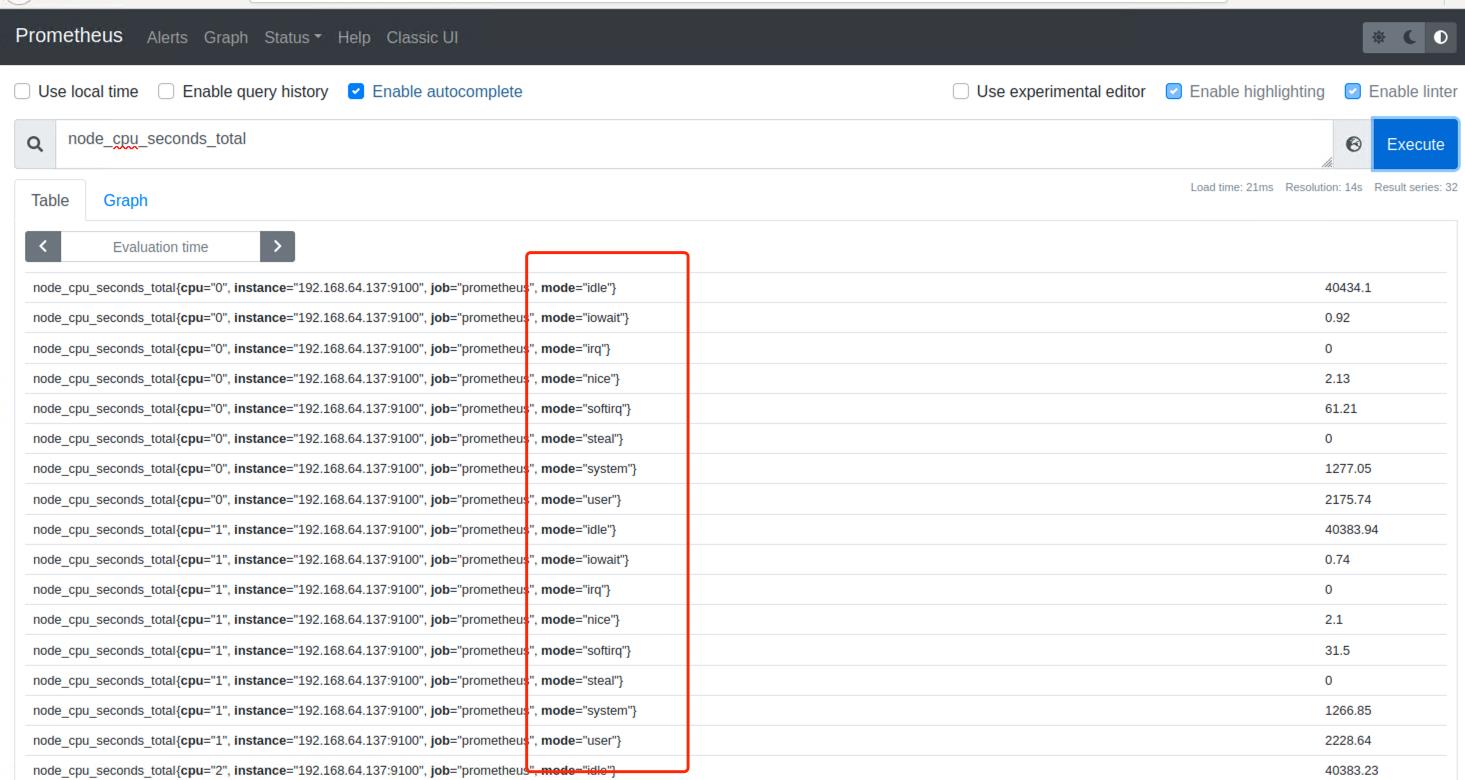
1.1.获取空闲CPU监控数据
mode标签值为idle的为空闲
node_cpu_seconds_total{mode='idle'}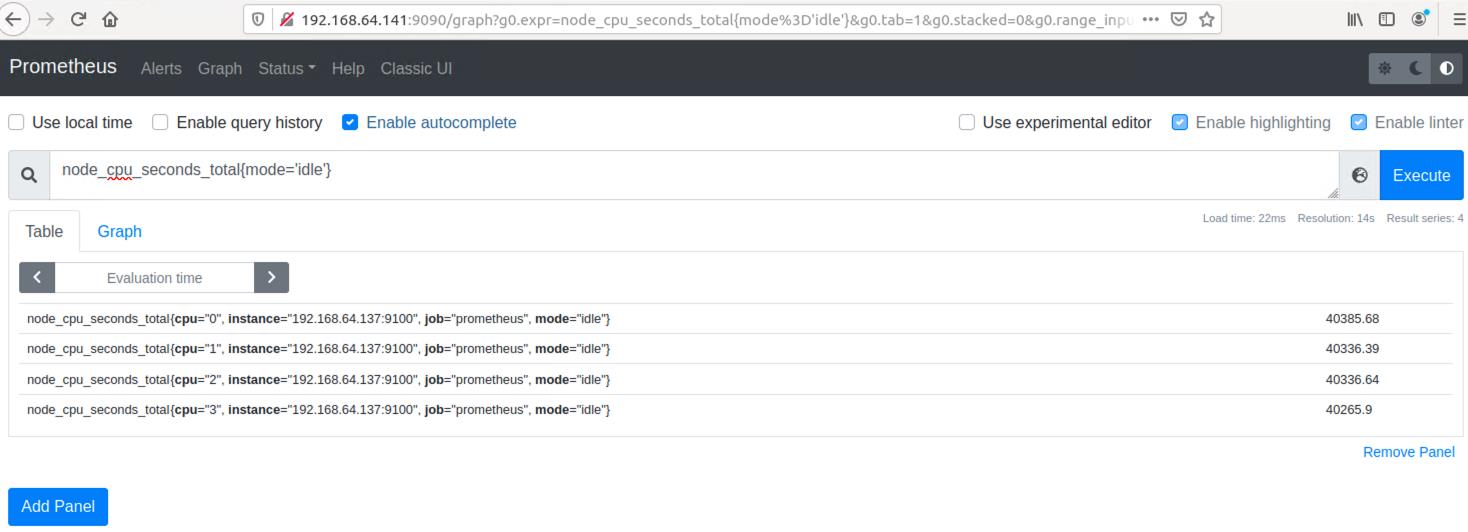
1.2.获取5分钟内的监控数据
上一步虽然可以查出来结果,但是不太理想,因为CPU是不断波动的,我们可以在增加一个条件,查询5分钟内的一个CPU使用情况
node_cpu_seconds_total{mode='idle'}[5m]
1.3.获取5分钟内的CPU平均空闲情况
我们可以使用irate和avg函数结合刚才查询出5分钟内数据做一个平均情况展示
irate和rate都会用于计算某个指标在一定时间间隔内的变化速率。但是它们的计算方法有所不同:irate取的是在指定时间范围内的最近两个数据点来算速率,而rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果。
所以官网文档说:irate适合快速变化的计数器(counter),而rate适合缓慢变化的计数器(counter)。
https://blog.csdn.net/palet/article/details/82763695
函数的使用方法:函数(指标获取方式)
avg(irate(node_cpu_seconds_total{mode=‘idle’}[5m])) by (instance)by(instance)表示以instance标签进行分组
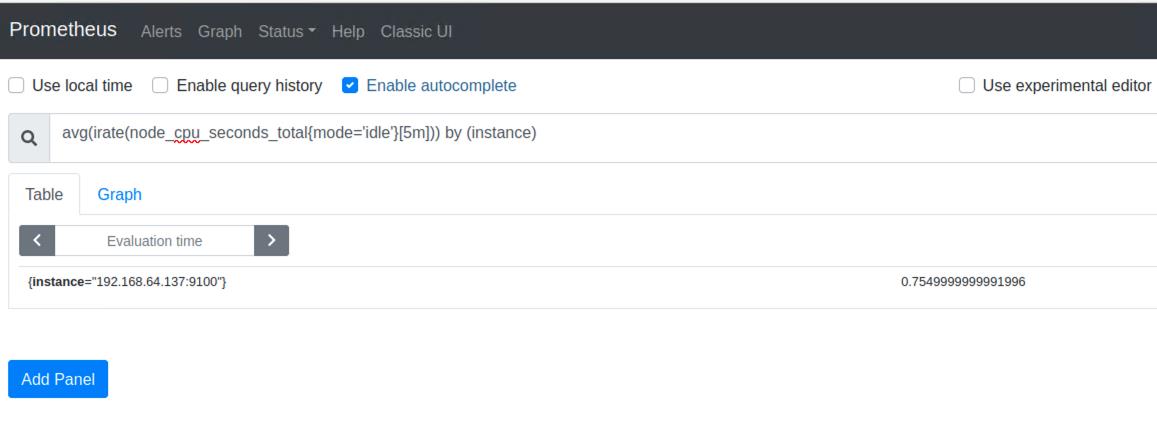
1.4.获取CPU5分钟内使用率
最后我们可以*100得出一个百分比的空闲率,再由100-即可得到CPU的使用率
100 - (avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance) *100)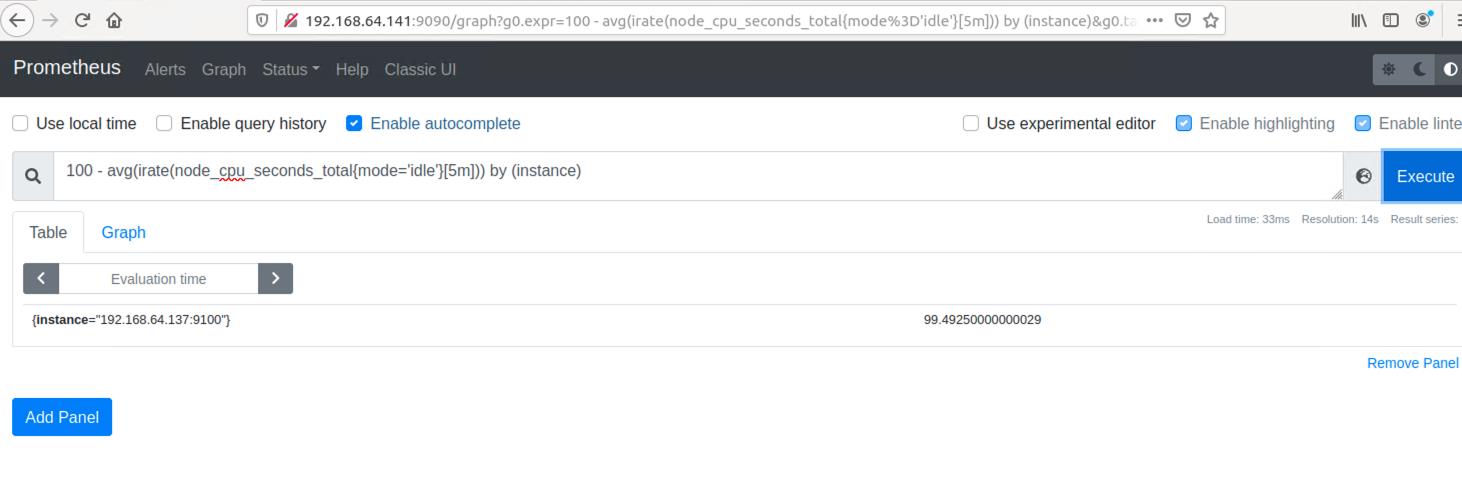
2.监控内存使用率
由于内存的监控项没有像CPU一样区分了很多标签,因此内存监控相较于CPU则需要结合很多个监控项
node_memory_MemFree_bytes //空闲内存
node_memory_MemTotal_bytes //总内存
node_memory_Cached_bytes //缓存
node_memory_Buffers_bytes //缓冲区内存
监控内存使用的思路:
1.空闲内存+缓存+缓冲区内存得出空闲总内存
2.得出的空闲总内存再除总内存大小再乘100,得出空闲率
3.再用100-空闲率就得出使用率
2.1.获取空闲内存
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)
2.2.获取空闲内存率
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100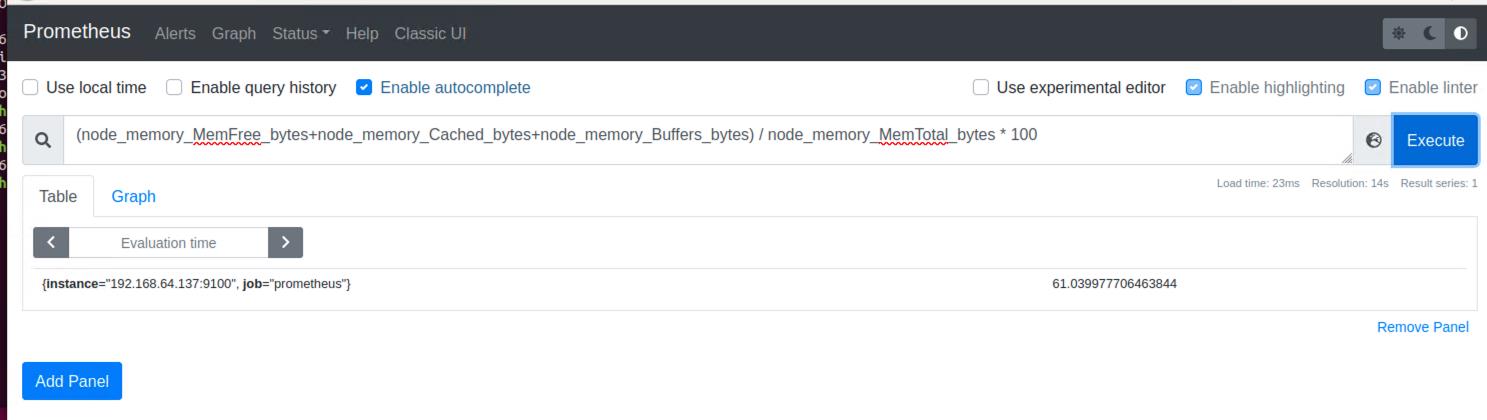
2.3.获取内存使用率
100 - ((node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100)
3.监控磁盘使用率
关于磁盘使用率,这里我们用到的主要有:
node_filesystem_free_bytes //剩余磁盘空间
node_filesystem_size_bytes //磁盘空间总大小
这两个监控项中都有相同的标签可以关联,我们这里用到的标签有fstype,fstype标签值是关于磁盘的文件系统类型,对于磁盘监控,我们主要对xfs、ext4等文件系统的磁盘进行监控,像tmpfs这种的不必要监控,另一个主要的标签是mountpoint,这个标签值主要用来储存磁盘的挂载点,我们可以通过标签来选择要对那个挂载点的磁盘进行监控
磁盘使用率实现思路:
1.由磁盘空闲容量除磁盘总容量乘100即可得到磁盘空闲率
2.用100减磁盘空闲率即可得到磁盘使用率
在使用逻辑运算时最好习惯性加一个()防止错误
我们监控/目录的磁盘使用情况
3.1.获取磁盘空闲率
node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} *100可以看到得出的结果和系统df命令查到的是一致的,空闲93,代表已经使用7
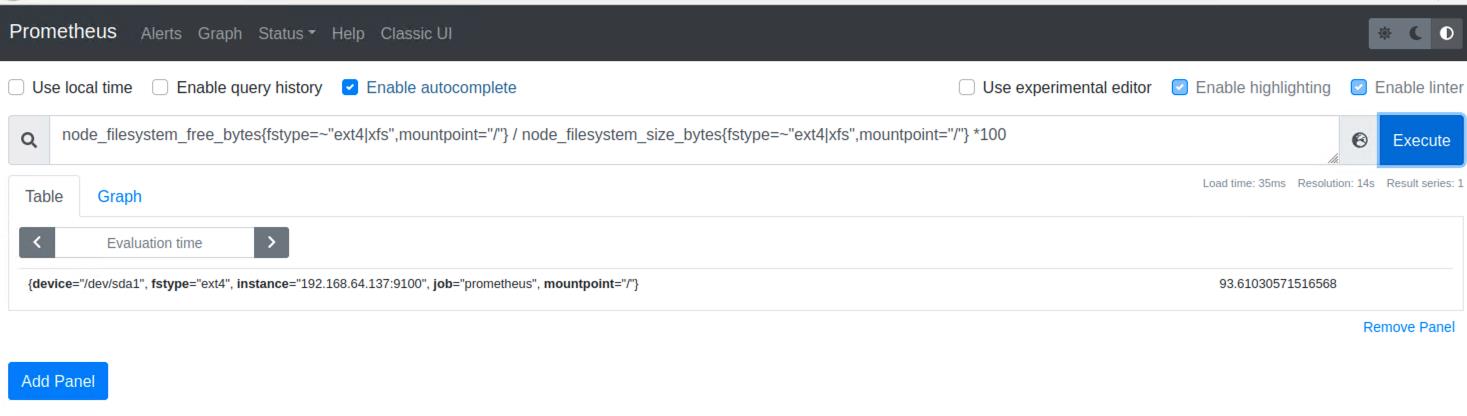
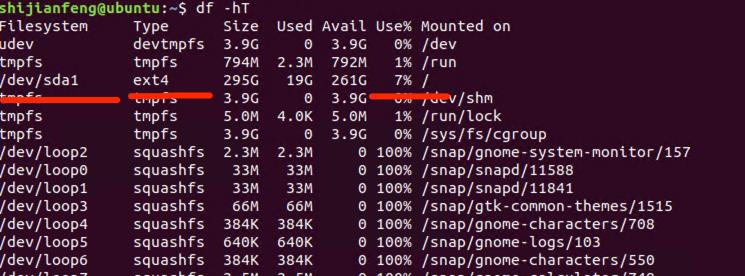
3.2.获取磁盘使用率
100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} *100)
4.监控系统服务状态
https://blog.csdn.net/weixin_44953658/article/details/113586179
四、监控docker的CPU、内存、磁盘使用率
container_cpu_usage_seconds_total
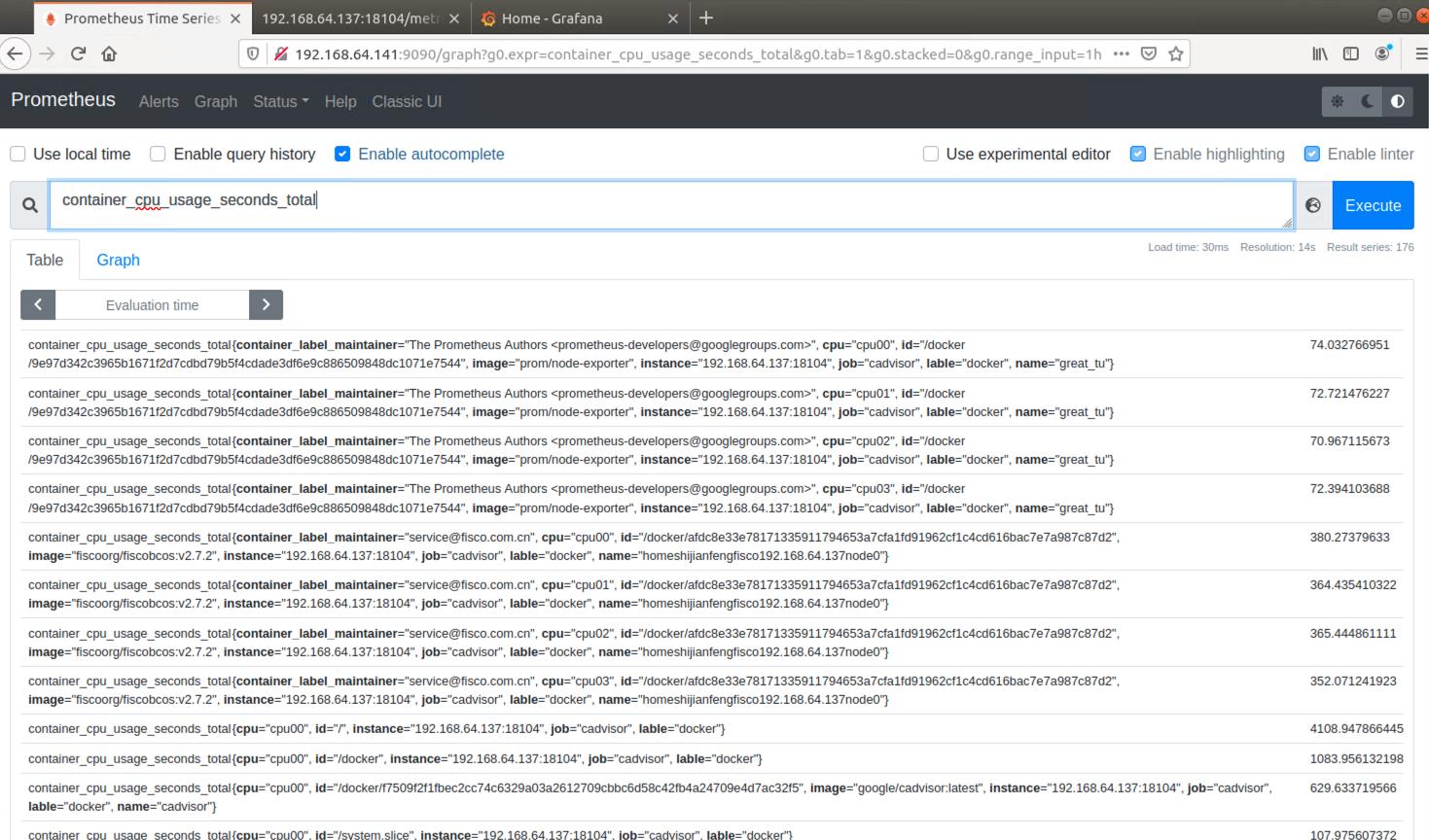
只能根据镜像名称筛选
表达式计算容器
容器CPU使用率:
sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu)
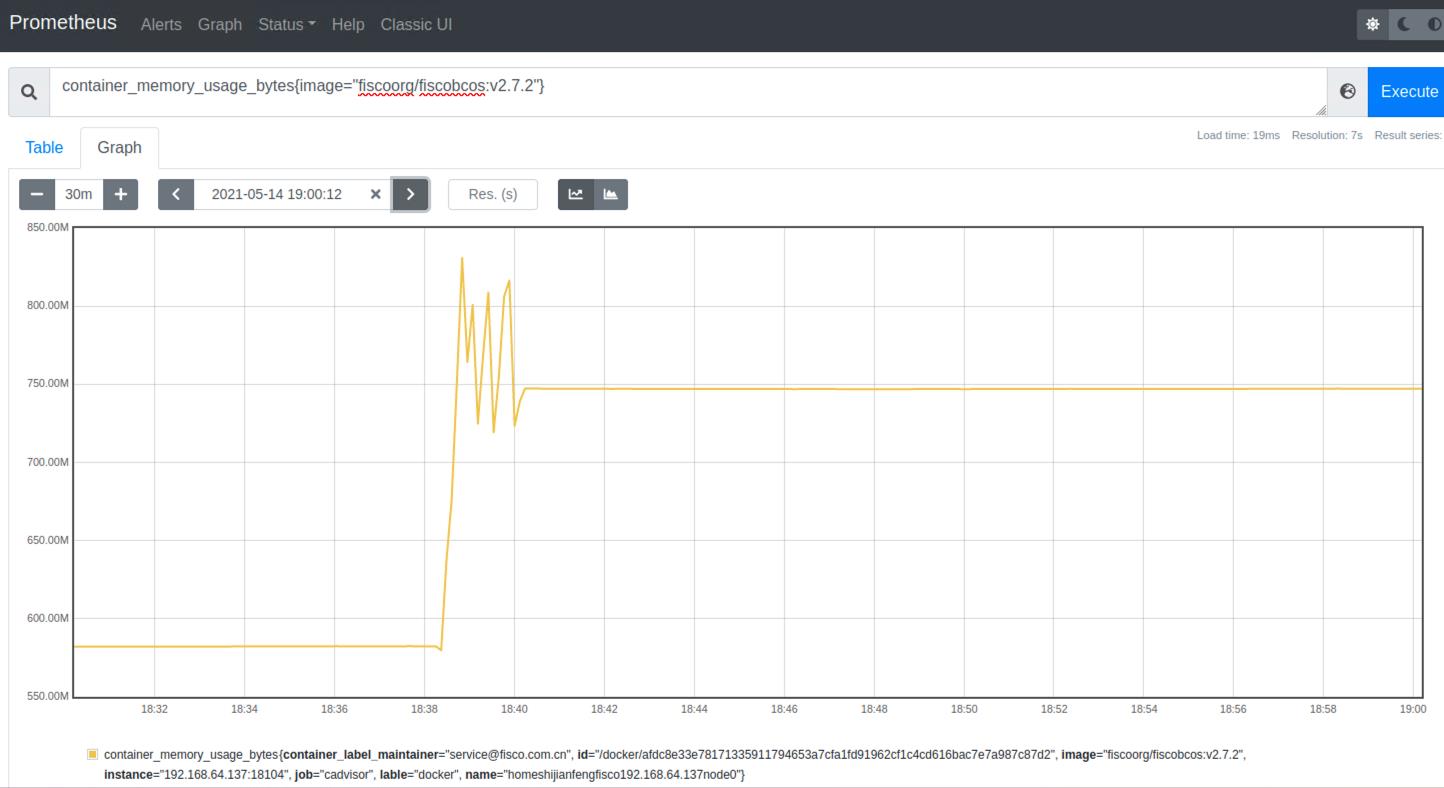
查询容器内存使用量(单位:字节):
container_memory_usage_bytes{image!=""}
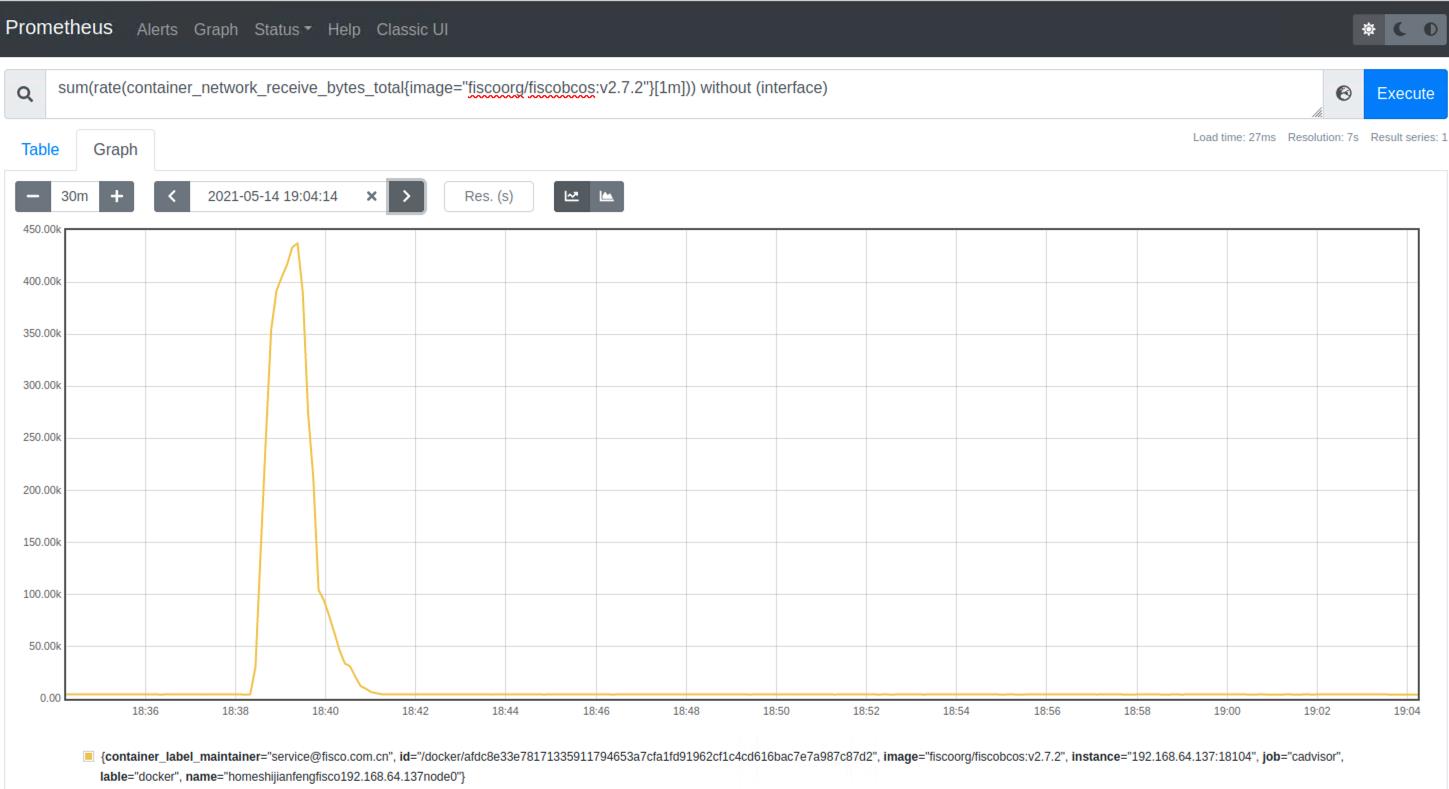
查询容器网络接收量速率(单位:字节/秒):
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without (interface)
查询容器网络传输量速率(单位:字节/秒):
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without (interface)
查询容器文件系统读取速率(单位:字节/秒):
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device)
查询容器文件系统写入速率(单位:字节/秒):
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device)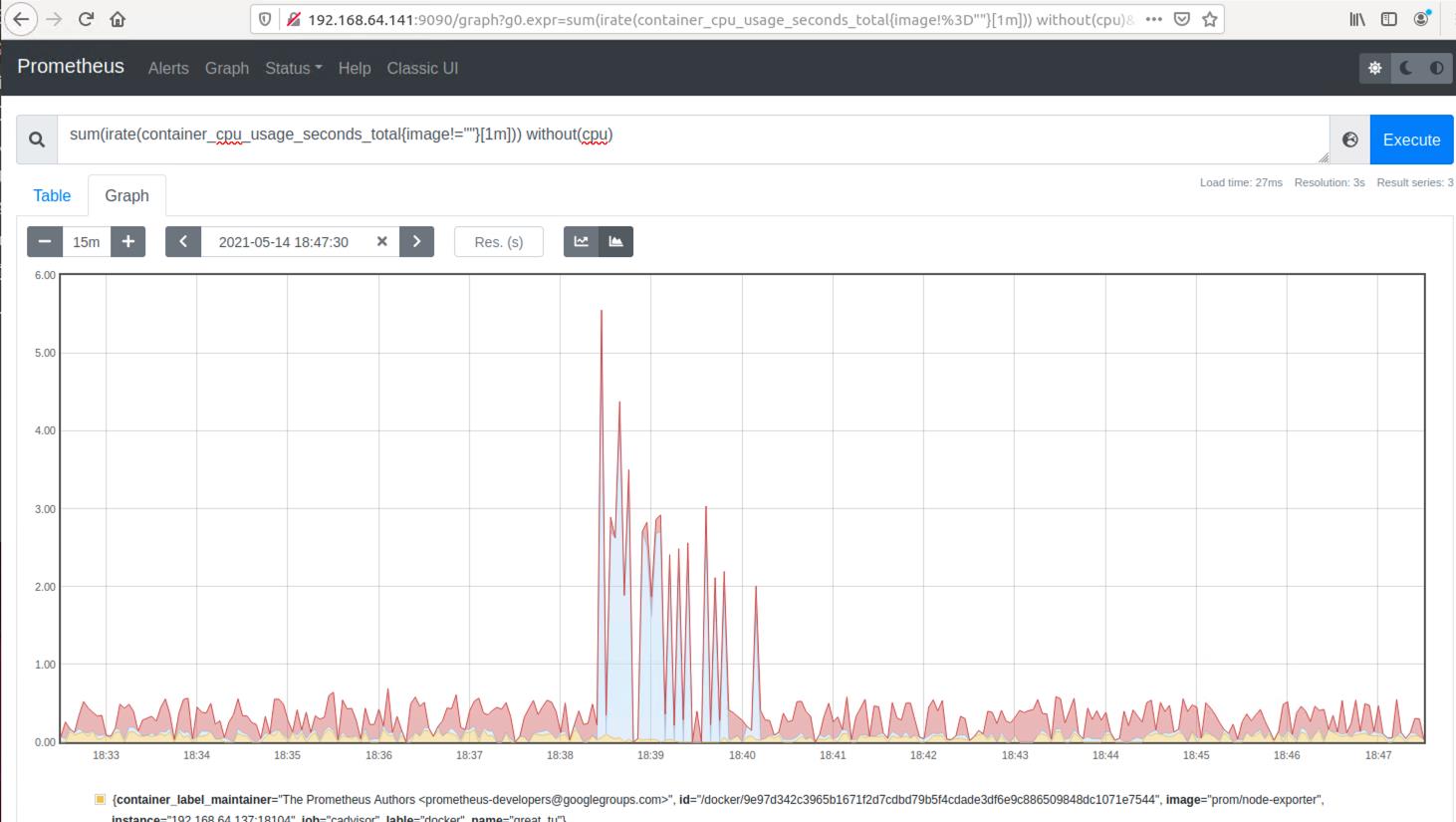
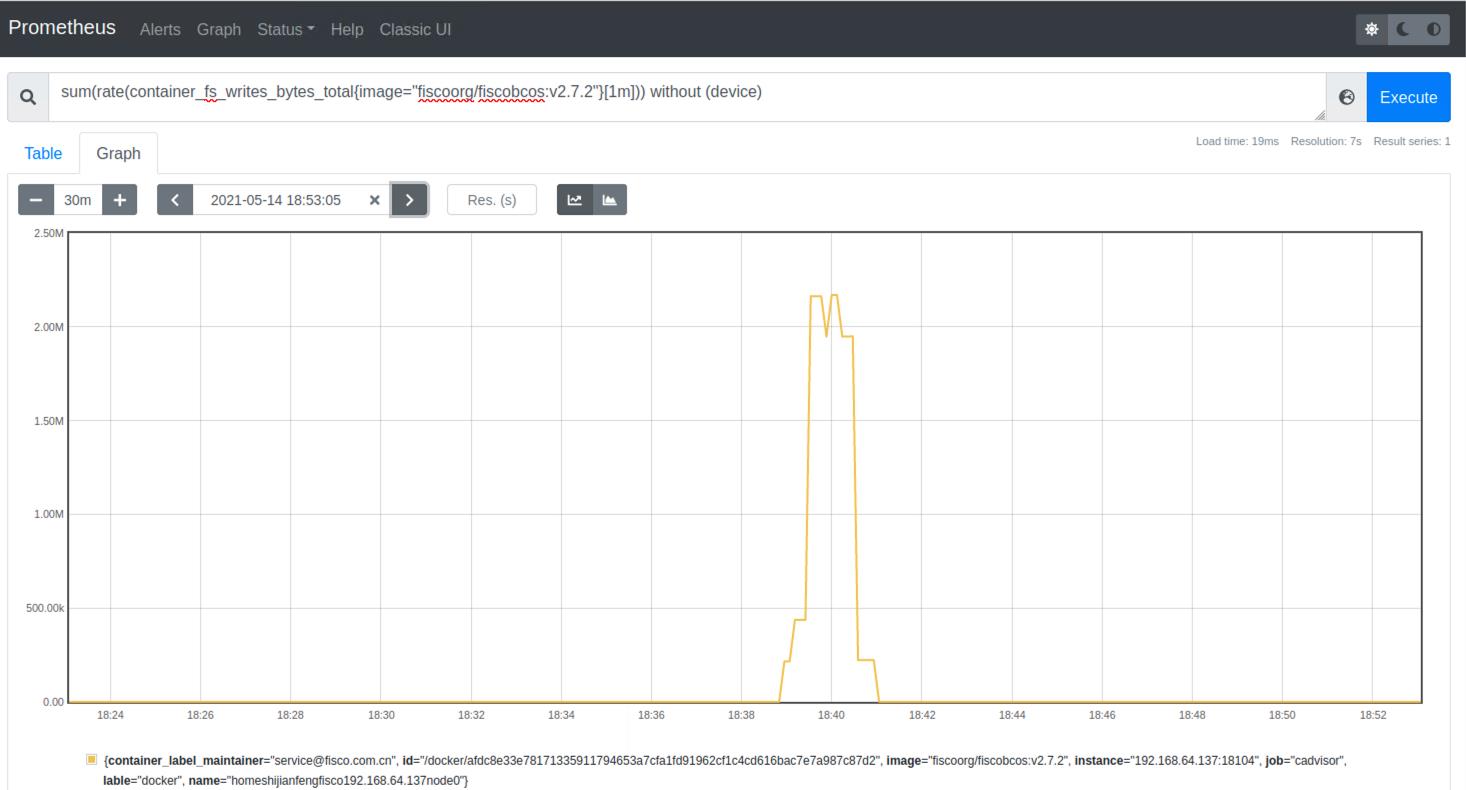
prometheus 监控Docker
模板: https://grafana.com/dashboards/893 或者 179
https://www.jianshu.com/p/efc7c66638cc
prometheus - node_exporter - CPU利用率(入门基础)
https://blog.csdn.net/shm19990131/article/details/107162470/
以上是关于prometheus cAdvisor 监控docker CPU利用率 教程的主要内容,如果未能解决你的问题,请参考以下文章
14Docker监控方案(Prometheus+cAdvisor+Grafana)
Prometheus+Grafana监控系统配合Cadvisor监控Docker容器 #yyds干货盘点#
只监控一个命名空间 pod - Prometheus & Kubernetes & cadvisor