2021年大数据Flink(四十八):扩展阅读 Streaming File Sink
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Flink(四十八):扩展阅读 Streaming File Sink相关的知识,希望对你有一定的参考价值。
目录
扩展阅读 Streaming File Sink
介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/streamfile_sink.html
场景描述
StreamingFileSink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
StreamingFileSink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
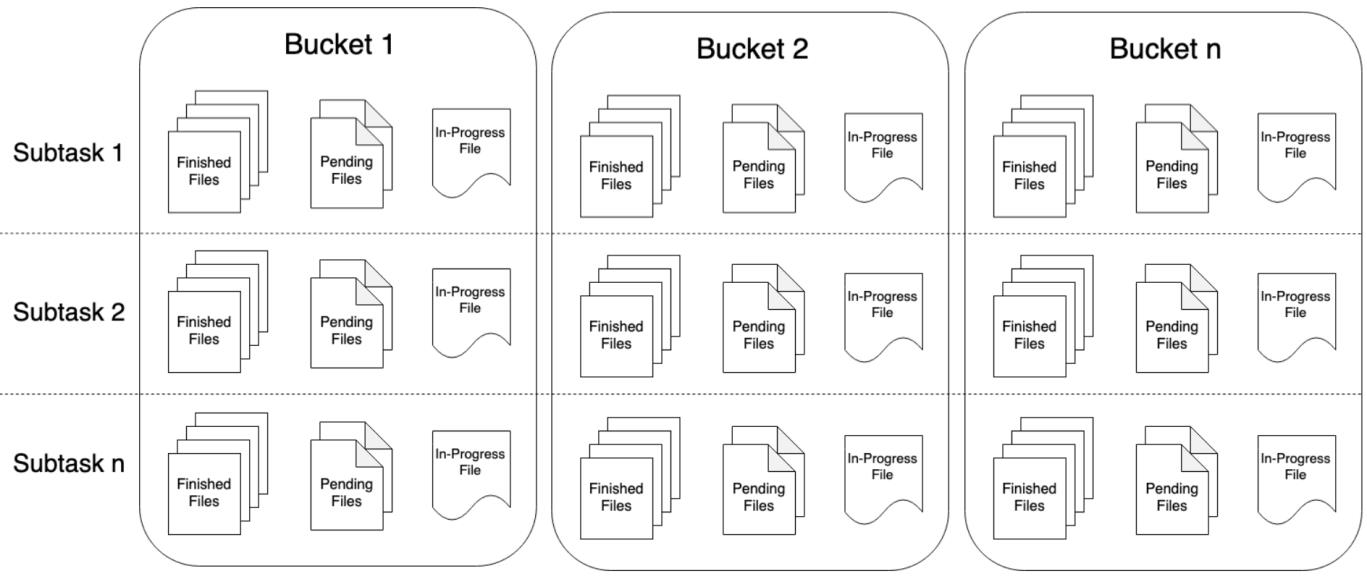
Bucket和SubTask、PartFile
- Bucket
StreamingFileSink可向由Flink FileSystem抽象支持的文件系统写入分区文件(因为是流式写入,数据被视为无界)。该分区行为可配,默认按时间,具体来说每小时写入一个Bucket,该Bucket包括若干文件,内容是这一小时间隔内流中收到的所有record。
每个Bukcket内部分为多个PartFile来存储输出数据,该Bucket生命周期内接收到数据的sink的每个子任务至少有一个PartFile。
而额外文件滚动由可配的滚动策略决定,默认策略是根据文件大小和打开超时(文件可以被打开的最大持续时间)以及文件最大不活动超时等决定是否滚动。
Bucket和SubTask、PartFile关系如图所示
案例演示
- 需求
编写Flink程序,接收socket的字符串数据,然后将接收到的数据流式方式存储到hdfs
- 开发步骤
- 初始化流计算运行环境
- 设置Checkpoint(10s)周期性启动
- 指定并行度为1
- 接入socket数据源,获取数据
- 指定文件编码格式为行编码格式
- 设置桶分配策略
- 设置文件滚动策略
- 指定文件输出配置
- 将streamingfilesink对象添加到环境
- 执行任务
- 实现代码
package cn.lanson.extend;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.util.concurrent.TimeUnit;
public class StreamFileSinkDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(TimeUnit.SECONDS.toMillis(10));
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
//2.source
DataStreamSource<String> lines = env.socketTextStream("node1", 9999);
//3.sink
//设置sink的前缀和后缀
//文件的头和文件扩展名
//prefix-xxx-.txt
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
//设置sink的路径
String outputPath = "hdfs://node1:8020/FlinkStreamFileSink/parquet";
//创建StreamingFileSink
final StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(
new Path(outputPath),
new SimpleStringEncoder<String>("UTF-8"))
/**
* 设置桶分配政策
* DateTimeBucketAssigner --默认的桶分配政策,默认基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH
* BasePathBucketAssigner :将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
*/
.withBucketAssigner(new DateTimeBucketAssigner<>())
/**
* 有三种滚动政策
* CheckpointRollingPolicy
* DefaultRollingPolicy
* OnCheckpointRollingPolicy
*/
.withRollingPolicy(
/**
* 滚动策略决定了写出文件的状态变化过程
* 1. In-progress :当前文件正在写入中
* 2. Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
* 3. Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
*
* 观察到的现象
* 1.会根据本地时间和时区,先创建桶目录
* 2.文件名称规则:part-<subtaskIndex>-<partFileIndex>
* 3.在macos中默认不显示隐藏文件,需要显示隐藏文件才能看到处于In-progress和Pending状态的文件,因为文件是按照.开头命名的
*
*/
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.SECONDS.toMillis(2)) //设置滚动间隔
.withInactivityInterval(TimeUnit.SECONDS.toMillis(1)) //设置不活动时间间隔
.withMaxPartSize(1024 * 1024 * 1024) // 最大尺寸
.build())
.withOutputFileConfig(config)
.build();
lines.addSink(sink).setParallelism(1);
env.execute();
}
}
扩展阅读 配置详解
PartFile
前面提到过,每个Bukcket内部分为多个部分文件,该Bucket内接收到数据的sink的每个子任务至少有一个PartFile。而额外文件滚动由可配的滚动策略决定。
关于顺序性
对于任何给定的Flink子任务,PartFile索引都严格增加(按创建顺序),但是,这些索引并不总是顺序的。当作业重新启动时,所有子任务的下一个PartFile索引将是max PartFile索引+ 1,其中max是指在所有子任务中对所有计算的索引最大值。
return new Path(bucketPath, outputFileConfig.getPartPrefix() + '-' + subtaskIndex + '-' + partCounter + outputFileConfig.getPartSuffix());
- PartFile生命周期
输出文件的命名规则和生命周期。由上图可知,部分文件(part file)可以处于以下三种状态之一:
1. In-progress :
当前文件正在写入中
2. Pending :
当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
3. Finished :
在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态,处于 Finished 状态的文件不会再被修改,可以被下游系统安全地读取。
注意:
使用 StreamingFileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时写入完成。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 'in-progress' 或 'pending' 状态,下游系统无法安全地读取。
- PartFile的生成规则
在每个活跃的Bucket期间,每个Writer的子任务在任何时候都只会有一个单独的In-progress PartFile,但可有多个Peding和Finished状态文件。
一个Sink的两个Subtask的PartFile分布情况实例如下:
初始状态,两个inprogress文件正在被两个subtask分别写入
└── 2021-05-17--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
└── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
当part-1-0因文件大小超过阈值等原因发生滚动时,变为Pending状态等待完成,但此时不会被重命名。注意此时Sink会创建一个新的PartFile即part-1-1:
└── 2020-05-17--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
待下次checkpoint成功后,part-1-0完成变为Finished状态,被重命名:
└── 2021-05-17--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
下一个Bucket周期到了,创建新的Bucket目录,不影响之前Bucket内的的in-progress文件,依然要等待文件RollingPolicy以及checkpoint来改变状态:
└── 2021-05-17--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
└── 2021-05-17--13
└── part-0-2.inprogress.2b475fec-1482-4dea-9946-eb4353b475f1
- PartFile命名设置
默认,PartFile命名规则如下:
- In-progress / Pending
part--.inprogress.uid - Finished
part--
比如part-1-20表示1号子任务已完成的20号文件。
可以使用OutputFileConfig来改变前缀和后缀,代码示例如下:
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
StreamingFileSink sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()得到的PartFile示例如下
└── 2021-05-17--12
├── prefix-0-0.ext
├── prefix-0-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-1-0.ext
└── prefix-1-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
PartFile序列化编码
StreamingFileSink 支持行编码格式和批量编码格式,比如 Apache Parquet 。这两种变体可以使用以下静态方法创建:
- Row-encoded sink:
StreamingFileSink.forRowFormat(basePath, rowEncoder)
//行
StreamingFileSink.forRowFormat(new Path(path), new SimpleStringEncoder<T>())
.withBucketAssigner(new PaulAssigner<>()) //分桶策略
.withRollingPolicy(new PaulRollingPolicy<>()) //滚动策略
.withBucketCheckInterval(CHECK_INTERVAL) //检查周期
.build();
StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)Bulk-encoded sink:
//列 parquet
StreamingFileSink.forBulkFormat(new Path(path), ParquetAvroWriters.forReflectRecord(clazz))
.withBucketAssigner(new PaulBucketAssigner<>())
.withBucketCheckInterval(CHECK_INTERVAL)
.build();
这两种写入格式除了文件格式的不同,另外一个很重要的区别就是回滚策略的不同:创建行或批量编码的 Sink 时,我们需要指定存储桶的基本路径和数据的编码
- forRowFormat行写可基于文件大小、滚动时间、不活跃时间进行滚动,
- forBulkFormat列写方式只能基于checkpoint机制进行文件滚动,即在执行snapshotState方法时滚动文件,如果基于大小或者时间滚动文件,那么在任务失败恢复时就必须对处于in-processing状态的文件按照指定的offset进行truncate,由于列式存储是无法针对文件offset进行truncate的,因此就必须在每次checkpoint使文件滚动,其使用的滚动策略实现是OnCheckpointRollingPolicy。
forBulkFormat只能和 `OnCheckpointRollingPolicy` 结合使用,每次做 checkpoint 时滚动文件。
- Row Encoding
此时,StreamingFileSink会以每条记录为单位进行编码和序列化。
必须配置项:
- 输出数据的BasePath
- 序列化每行数据写入PartFile的Encoder
使用RowFormatBuilder可选配置项:
- 自定义RollingPolicy
默认使用DefaultRollingPolicy来滚动文件,可自定义
- bucketCheckInterval
默认1分钟。该值单位为毫秒,指定按时间滚动文件间隔时间
例子如下:
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
// 1. 构建DataStream
DataStream input = ...
// 2. 构建StreamingFileSink,指定BasePath、Encoder、RollingPolicy
StreamingFileSink sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build()
// 3. 添加Sink到InputDataSteam即可
input.addSink(sink)以上例子构建了一个简单的拥有默认Bucket构建行为(继承自BucketAssigner的DateTimeBucketAssigner)的StreamingFileSink,每小时构建一个Bucket,内部使用继承自RollingPolicy的DefaultRollingPolicy,以下三种情况任一发生会滚动PartFile:
- PartFile包含至少15分钟的数据
- 在过去5分钟内没有接收到新数据
- 在最后一条记录写入后,文件大小已经达到1GB
除了使用DefaultRollingPolicy,也可以自己实现RollingPolicy接口来实现自定义滚动策略。
- Bulk Encoding
要使用批量编码,请将StreamingFileSink.forRowFormat()替换为StreamingFileSink.forBulkFormat(),注意此时必须指定一个BulkWriter.Factory而不是行模式的Encoder。BulkWriter在逻辑上定义了如何添加、fllush新记录以及如何最终确定记录的bulk以用于进一步编码。
需要注意的是,使用Bulk Encoding时,Filnk1.9版本的文件滚动就只能使用OnCheckpointRollingPolicy的策略,该策略在每次checkpoint时滚动part-file。
Flink有三个内嵌的BulkWriter:
- ParquetAvroWriters
有一些静态方法来创建ParquetWriterFactory。
- SequenceFileWriterFactory
- CompressWriterFactory
Flink有内置方法可用于为Avro数据创建Parquet writer factory。
要使用ParquetBulkEncoder,需要添加以下Maven依赖:
<!-- streaming File Sink所需要的jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.avro/avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.12.0</version>
</dependency>
桶分配策略
桶分配策略定义了将数据结构化后写入基本输出目录中的子目录,行格式和批量格式都需要使用。
具体来说,StreamingFileSink使用BucketAssigner来确定每条输入的数据应该被放入哪个Bucket,
默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时创建一个桶:
格式如下:yyyy-MM-dd--HH。日期格式(即桶的大小)和时区都可以手动配置。
我们可以在格式构建器上调用 .withBucketAssigner(assigner) 来自定义 BucketAssigner。
Flink 有两个内置的 BucketAssigners :
- DateTimeBucketAssigner:默认基于时间的分配器
- BasePathBucketAssigner:将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
- DateTimeBucketAssigner
Row格式和Bulk格式编码都使用DateTimeBucketAssigner作为默认BucketAssigner。 默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时以格式yyyy-MM-dd--HH来创建一个Bucket,Bucket路径为/{basePath}/{dateTimePath}/。
- basePath是指StreamingFileSink.forRowFormat(new Path(outputPath)时的路径
- dateTimePath中的日期格式和时区都可在初始化DateTimeBucketAssigner时配置
public class DateTimeBucketAssigner<IN> implements BucketAssigner<IN, String> {
private static final long serialVersionUID = 1L;
// 默认的时间格式字符串
private static final String DEFAULT_FORMAT_STRING = "yyyy-MM-dd--HH";
// 时间格式字符串
private final String formatString;
// 时区
private final ZoneId zoneId;
// DateTimeFormatter被用来通过当前系统时间和DateTimeFormat来生成时间字符串
private transient DateTimeFormatter dateTimeFormatter;
/**
* 使用默认的`yyyy-MM-dd--HH`和系统时区构建DateTimeBucketAssigner
*/
public DateTimeBucketAssigner() {
this(DEFAULT_FORMAT_STRING);
}
/**
* 通过能被SimpleDateFormat解析的时间字符串和系统时区
* 来构建DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(String formatString) {
this(formatString, ZoneId.systemDefault());
}
/**
* 通过默认的`yyyy-MM-dd--HH`和指定的时区
* 来构建DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(ZoneId zoneId) {
this(DEFAULT_FORMAT_STRING, zoneId);
}
/**
* 通过能被SimpleDateFormat解析的时间字符串和指定的时区
* 来构建DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(String formatString, ZoneId zoneId) {
this.formatString = Preconditions.checkNotNull(formatString);
this.zoneId = Preconditions.checkNotNull(zoneId);
}
/**
* 使用指定的时间格式和时区来格式化当前ProcessingTime,以获取BucketId
*/
@Override
public String getBucketId(IN element, BucketAssigner.Context context) {
if (dateTimeFormatter == null) {
dateTimeFormatter = DateTimeFormatter.ofPattern(formatString).withZone(zoneId);
}
return dateTimeFormatter.format(Instant.ofEpochMilli(context.currentProcessingTime()));
}
@Override
public SimpleVersionedSerializer<String> getSerializer() {
return SimpleVersionedStringSerializer.INSTANCE;
}
@Override
public String toString() {
return "DateTimeBucketAssigner{" +
"formatString='" + formatString + '\\'' +
", zoneId=" + zoneId +
'}';
}
}
- BasePathBucketAssigner
将所有PartFile存储在BasePath中(此时只有单个全局Bucket)。
先看看BasePathBucketAssigner的源码,方便继续学习DateTimeBucketAssigner:
@PublicEvolving
public class BasePathBucketAssigner<T> implements BucketAssigner<T, String> {
private static final long serialVersionUID = -6033643155550226022L;
/**
* BucketId永远为"",即Bucket全路径为用户指定的BasePath
*/
@Override
public String getBucketId(T element, BucketAssigner.Context context) {
return "";
}
/**
* 用SimpleVersionedStringSerializer来序列化BucketId
*/
@Override
public SimpleVersionedSerializer<String> getSerializer() {
// in the future this could be optimized as it is the empty string.
return SimpleVersionedStringSerializer.INSTANCE;
}
@Override
public String toString() {
return "BasePathBucketAssigner";
}
}滚动策略
滚动策略 RollingPolicy 定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
Flink 有两个内置的滚动策略:
- DefaultRollingPolicy
- OnCheckpointRollingPolicy
需要注意的是,使用Bulk Encoding时,文件滚动就只能使用OnCheckpointRollingPolicy的策略,该策略在每次checkpoint时滚动part-file。
以上是关于2021年大数据Flink(四十八):扩展阅读 Streaming File Sink的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Flink(四十七):扩展阅读 File Sink
2021年大数据Flink(四十四):扩展阅读 End-to-End Exactly-Once