还不会使用分布式锁?教你三种分布式锁实现的方式
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了还不会使用分布式锁?教你三种分布式锁实现的方式相关的知识,希望对你有一定的参考价值。
摘要:在单进程的系统中,当存在多个线程可以同时改变某个变量时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量,而同步本质上通过锁来实现。
本文分享自华为云社区《还不会使用分布式锁?从零开始基于 etcd 实现分布式锁》,原文作者:aoho 。
为什么需要分布式锁?
在单进程的系统中,当存在多个线程可以同时改变某个变量时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量。而同步本质上通过锁来实现。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。
而在分布式环境下,数据一致性问题一直是难点。相比于单进程,分布式环境的情况更加复杂。分布式与单机环境最大的不同在于其不是多线程而是多进程。多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置。而进程之间甚至可能都不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
常见的是秒杀场景,订单服务部署了多个服务实例。如秒杀商品有 4 个,第一个用户购买 3 个,第二个用户购买 2 个,理想状态下第一个用户能购买成功,第二个用户提示购买失败,反之亦可。而实际可能出现的情况是,两个用户都得到库存为 4,第一个用户买到了 3 个,更新库存之前,第二个用户下了 2 个商品的订单,更新库存为 2,导致业务逻辑出错。
在上面的场景中,商品的库存是共享变量,面对高并发情形,需要保证对资源的访问互斥。在单机环境中,比如 Java 语言中其实提供了很多并发处理相关的 API,但是这些 API 在分布式场景中就无能为力了,由于分布式系统具备多线程和多进程的特点,且分布在不同机器中,synchronized 和 lock 关键字将失去原有锁的效果,。仅依赖这些语言自身提供的 API 并不能实现分布式锁的功能,因此需要我们想想其它方法实现分布式锁。
常见的锁方案如下:
- 基于数据库实现分布式锁
- 基于 Zookeeper 实现分布式锁
- 基于缓存实现分布式锁,如 redis、etcd 等
下面我们简单介绍下这几种锁的实现,并重点介绍 etcd 实现锁的方法。
基于数据库的锁
基于数据库的锁实现也有两种方式,一是基于数据库表,另一种是基于数据库的排他锁。
基于数据库表的增删
基于数据库表增删是最简单的方式,首先创建一张锁的表主要包含下列字段:方法名,时间戳等字段。
具体使用的方法为:当需要锁住某个方法时,往该表中插入一条相关的记录。需要注意的是,方法名有唯一性约束。如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。执行完毕,需要删除该记录。
对于上述方案可以进行优化,如应用主从数据库,数据之间双向同步。一旦主库挂掉,将应用服务快速切换到从库上。除此之外还可以记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给该线程,实现可重入锁。
基于数据库排他锁
我们还可以通过数据库的排他锁来实现分布式锁。基于 mysql 的 InnoDB 引擎,可以使用以下方法来实现加锁操作:
public void lock(){
connection.setAutoCommit(false)
int count = 0;
while(count < 4){
try{
select * from lock where lock_name=xxx for update;
if(结果不为空){
//代表获取到锁
return;
}
}catch(Exception e){
}
//为空或者抛异常的话都表示没有获取到锁
sleep(1000);
count++;
}
throw new LockException();
}在查询语句后面增加 for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。其他没有获取到锁的就会阻塞在上述 select 语句上,可能的结果有 2 种,在超时之前获取到了锁,在超时之前仍未获取到锁。
获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行业务逻辑,执行完业务之后释放锁。
基于数据库锁的总结
上面两种方式都是依赖数据库的一张表,一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。优点是直接借助现有的关系型数据库,简单且容易理解;缺点是操作数据库需要一定的开销,性能问题以及 SQL 执行超时的异常需要考虑。
基于 Zookeeper
基于 Zookeeper 的临时节点和顺序特性可以实现分布式锁。
申请对某个方法加锁时,在 Zookeeper 上与该方法对应的指定节点的目录下,生成一个唯一的临时有序节点。当需要获取锁时,只需要判断有序节点中该节点是否为序号最小的一个。业务逻辑执行完成释放锁,只需将这个临时节点删除即可。这种方式也可以避免由于服务宕机导致的锁无法释放,而产生的死锁问题。
Netflix 开源了一套 Zookeeper 客户端框架 curator,你可以自行去看一下具体使用方法。Curator 提供的 InterProcessMutex 是分布式锁的一种实现。acquire 方法获取锁,release 方法释放锁。另外,锁释放、阻塞锁、可重入锁等问题都可以有效解决。
关于阻塞锁的实现,客户端可以通过在 Zookeeper 中创建顺序节点,并且在节点上绑定监听器 Watch。一旦节点发生变化,Zookeeper 会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是就获取到锁,便可以执行业务逻辑。
Zookeeper 实现的分布式锁也存在一些缺陷。在性能上可能不如基于缓存实现的分布式锁。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。
此外,Zookeeper 中创建和删除节点只能通过 Leader 节点来执行,然后将数据同步到集群中的其他节点。分布式环境中难免存在网络抖动,导致客户端和 Zookeeper 集群之间的 session 连接中断,此时 Zookeeper 服务端以为客户端挂了,就会删除临时节点。其他客户端就可以获取到分布式锁了,导致了同时获取锁的不一致问题。
基于缓存实现分布式锁
相对于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点,存取速度快很多。而且很多缓存是可以集群部署的,可以解决单点问题。基于缓存的锁有好几种,如memcached、redis、本文下面主要讲解基于 etcd 实现分布式锁。
通过 etcd txn 实现分布式锁
通过 etcd 实现分布式锁,同样需要满足一致性、互斥性和可靠性等要求。etcd 中的事务 txn、lease 租约以及 watch 监听特性,能够使得基于 etcd 实现上述要求的分布式锁。
思路分析
通过 etcd 的事务特性可以帮助我们实现一致性和互斥性。etcd 的事务特性,使用的 IF-Then-Else 语句,IF 语言判断 etcd 服务端是否存在指定的 key,即该 key 创建版本号 create_revision 是否为 0 来检查 key 是否已存在,因为该 key 已存在的话,它的 create_revision 版本号就不是 0。满足 IF 条件的情况下则使用 then 执行 put 操作,否则 else 语句返回抢锁失败的结果。当然,除了使用 key 是否创建成功作为 IF 的判断依据,还可以创建前缀相同的 key,比较这些 key 的 revision 来判断分布式锁应该属于哪个请求。
客户端请求在获取到分布式锁之后,如果发生异常,需要及时将锁给释放掉。因此需要租约,当我们申请分布式锁的时候需要指定租约时间。超过 lease 租期时间将会自动释放锁,保证了业务的可用性。是不是这样就够了呢?在执行业务逻辑时,如果客户端发起的是一个耗时的操作,操作未完成的请情况下,租约时间过期,导致其他请求获取到分布式锁,造成不一致。这种情况下则需要续租,即刷新租约,使得客户端能够和 etcd 服务端保持心跳。
具体实现
我们基于如上分析的思路,绘制出实现 etcd 分布式锁的流程图,如下所示:
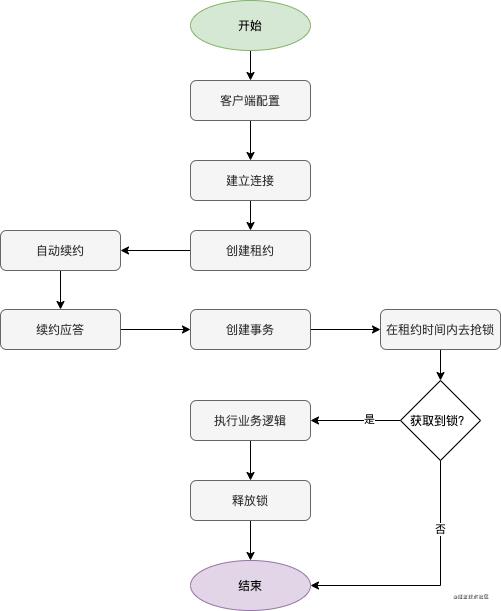
基于 Go 语言实现的 etcd 分布式锁,测试代码如下所示:
func TestLock(t *testing.T) {
// 客户端配置
config = clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
}
// 建立连接
if client, err = clientv3.New(config); err != nil {
fmt.Println(err)
return
}
// 1. 上锁并创建租约
lease = clientv3.NewLease(client)
if leaseGrantResp, err = lease.Grant(context.TODO(), 5); err != nil {
panic(err)
}
leaseId = leaseGrantResp.ID
// 2 自动续约
// 创建一个可取消的租约,主要是为了退出的时候能够释放
ctx, cancelFunc = context.WithCancel(context.TODO())
// 3. 释放租约
defer cancelFunc()
defer lease.Revoke(context.TODO(), leaseId)
if keepRespChan, err = lease.KeepAlive(ctx, leaseId); err != nil {
panic(err)
}
// 续约应答
go func() {
for {
select {
case keepResp = <-keepRespChan:
if keepRespChan == nil {
fmt.Println("租约已经失效了")
goto END
} else { // 每秒会续租一次, 所以就会受到一次应答
fmt.Println("收到自动续租应答:", keepResp.ID)
}
}
}
END:
}()
// 1.3 在租约时间内去抢锁(etcd 里面的锁就是一个 key)
kv = clientv3.NewKV(client)
// 创建事务
txn = kv.Txn(context.TODO())
//if 不存在 key,then 设置它,else 抢锁失败
txn.If(clientv3.Compare(clientv3.CreateRevision("lock"), "=", 0)).
Then(clientv3.OpPut("lock", "g", clientv3.WithLease(leaseId))).
Else(clientv3.OpGet("lock"))
// 提交事务
if txnResp, err = txn.Commit(); err != nil {
panic(err)
}
if !txnResp.Succeeded {
fmt.Println("锁被占用:", string(txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 抢到锁后执行业务逻辑,没有抢到退出
fmt.Println("处理任务")
time.Sleep(5 * time.Second)
}预期的执行结果如下所示:
=== RUN TestLock
处理任务
收到自动续租应答: 7587848943239472601
收到自动续租应答: 7587848943239472601
收到自动续租应答: 7587848943239472601
--- PASS: TestLock (5.10s)
PASS总得来说,如上关于 etcd 分布式锁的实现过程分为四个步骤:
- 客户端初始化与建立连接;
- 创建租约,自动续租;
- 创建事务,获取锁;
- 执行业务逻辑,最后释放锁。
创建租约的时候,需要创建一个可取消的租约,主要是为了退出的时候能够释放。释放锁对应的步骤,在上面的 defer 语句中。当 defer 租约关掉的时候,分布式锁对应的 key 就会被释放掉了。
小结
本文主要介绍了基于 etcd 实现分布式锁的案例。首先介绍了分布式锁产生的背景以及必要性,分布式架构不同于单体架构,涉及到多服务之间多个实例的调用,跨进程的情况下使用编程语言自带的并发原语没有办法实现数据的一致性,因此分布式锁出现,用来解决分布式环境中的资源互斥操作。接着介绍了基于数据库实现分布式锁的两种方式:数据表增删和数据库的排它锁。基于 Zookeeper 的临时节点和顺序特性也可以实现分布式锁,这两种方式或多或少存在性能和稳定性方面的缺陷。
接着本文重点介绍了基于 etcd 实现分布式锁的方案,根据 etcd 的特点,利用事务 txn、lease 租约以及 watch 监测实现分布式锁。
在我们上面的案例中,抢锁失败,客户端就直接返回了。那么当该锁被释放之后,或者持有锁的客户端出现了故障退出了,其他锁如何快速获取锁呢?所以上述代码可以基于 watch 监测特性进行改进,各位同学可以自行试试。
以上是关于还不会使用分布式锁?教你三种分布式锁实现的方式的主要内容,如果未能解决你的问题,请参考以下文章