非常实用的代码重构技巧
Posted 朱小厮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了非常实用的代码重构技巧相关的知识,希望对你有一定的参考价值。
点击上方“朱小厮的博客”,选择“设为星标”
后台回复"书",获取
后台回复“k8s”,可领取k8s资料
关于重构
为什么要重构

项目在不断演进过程中,代码不停地在堆砌。如果没有人为代码的质量负责,代码总是会往越来越混乱的方向演进。当混乱到一定程度之后,量变引起质变,项目的维护成本已经高过重新开发一套新代码的成本,想要再去重构,已经没有人能做到了。
造成这样的原因往往有以下几点:
编码之前缺乏有效的设计
成本上的考虑,在原功能堆砌式编程
缺乏有效代码质量监督机制
对于此类问题,业界已有有很好的解决思路:通过持续不断的重构将代码中的“坏味道”清除掉。
什么是重构
重构一书的作者Martin Fowler对重构的定义:
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
根据重构的规模可以大致分为大型重构和小型重构:
大型重构:对顶层代码设计的重构,包括:系统、模块、代码结构、类与类之间的关系等的重构,重构的手段有:分层、模块化、解耦、抽象可复用组件等等。这类重构的工具就是我们学习过的那些设计思想、原则和模式。这类重构涉及的代码改动会比较多,影响面会比较大,所以难度也较大,耗时会比较长,引入bug的风险也会相对比较大。
小型重构:对代码细节的重构,主要是针对类、函数、变量等代码级别的重构,比如规范命名和注释、消除超大类或函数、提取重复代码等等。小型重构更多的是使用统一的编码规范。这类重构要修改的地方比较集中,比较简单,可操作性较强,耗时会比较短,引入bug的风险相对来说也会比较小。什么时候重构 新功能开发、修bug或者代码review中出现“代码坏味道”,我们就应该及时进行重构。持续在日常开发中进行小重构,能够降低重构和测试的成本。
代码的坏味道

代码重复
实现逻辑相同、执行流程相同
方法过长
方法中的语句不在同一个抽象层级
逻辑难以理解,需要大量的注释
面向过程编程而非面向对象
过大的类
类做了太多的事情
包含过多的实例变量和方法
类的命名不足以描述所做的事情
逻辑分散
发散式变化:某个类经常因为不同的原因在不同的方向上发生变化
散弹式修改:发生某种变化时,需要在多个类中做修改
严重的情结依恋
某个类的方法过多的使用其他类的成员
数据泥团/基本类型偏执
两个类、方法签名中包含相同的字段或参数
应该使用类但使用基本类型,比如表示数值与币种的Money类、起始值与结束值的Range类
不合理的继承体系
继承打破了封装性,子类依赖其父类中特定功能的实现细节
子类必须跟着其父类的更新而演变,除非父类是专门为了扩展而设计,并且有很好的文档说明
过多的条件判断
过长的参数列
临时变量过多
令人迷惑的暂时字段
某个实例变量仅为某种特定情况而设置
将实例变量与相应的方法提取到新的类中
纯数据类
仅包含字段和访问(读写)这些字段的方法
此类被称为数据容器,应保持最小可变性
不恰当的命名
命名无法准确描述做的事情
命名不符合约定俗称的惯例
过多的注释
坏代码的问题
难以复用
系统关联性过多,导致很难分离可重用部分
难于变化
一处变化导致其他很多部分的修改,不利于系统稳定
难于理解
命名杂乱,结构混乱,难于阅读和理解
难以测试
分支、依赖较多,难以覆盖全面
什么是好代码

代码质量的评价有很强的主观性,描述代码质量的词汇也有很多,比如可读性、可维护性、灵活、优雅、简洁。这些词汇是从不同的维度去评价代码质量的。其中,可维护性、可读性、可扩展性又是提到最多的、最重要的三个评价标准。
要写出高质量代码,我们就需要掌握一些更加细化、更加能落地的编程方法论,这就包含面向对象设计思想、设计原则、设计模式、编码规范、重构技巧等。
如何重构
SOLID原则
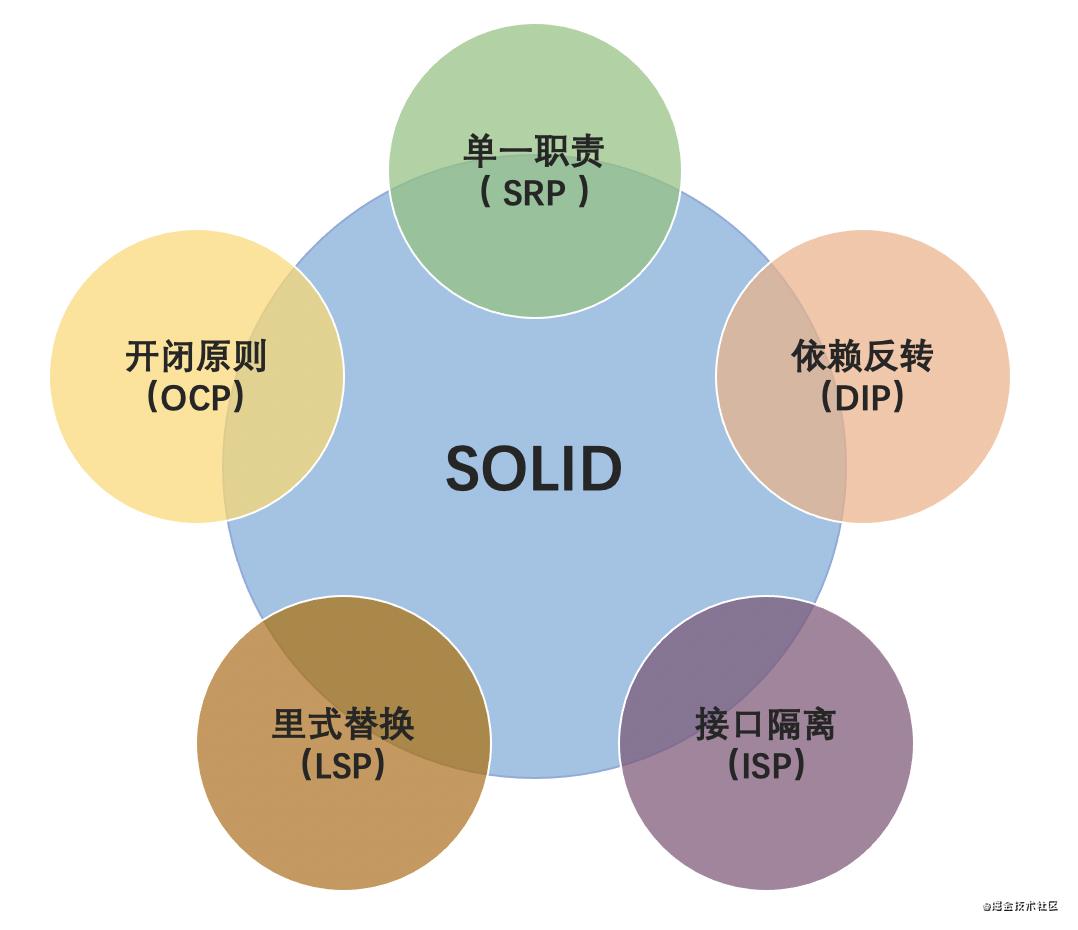
单一职责原则
一个类只负责完成一个职责或者功能,不要存在多于一种导致类变更的原因。
单一职责原则通过避免设计大而全的类,避免将不相关的功能耦合在一起,来提高类的内聚性。同时,类职责单一,类依赖的和被依赖的其他类也会变少,减少了代码的耦合性,以此来实现代码的高内聚、松耦合。但是,如果拆分得过细,实际上会适得其反,反倒会降低内聚性,也会影响代码的可维护性。
开放-关闭原则
添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。
开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。
很多设计原则、设计思想、设计模式,都是以提高代码的扩展性为最终目的的。特别是 23 种经典设计模式,大部分都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为指导原则的。最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、职责链、状态)。
里氏替换原则
子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
子类可以扩展父类的功能,但不能改变父类原有的功能
父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。
接口隔离原则
调用方不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。接口隔离原则提供了一种判断接口的职责是否单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够职责单一。
依赖反转原则
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。
迪米特法则
一个对象应该对其他对象保持最少的了解
合成复用原则
尽量使用合成/聚合的方式,而不是使用继承。
单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲,告诉我们要对扩展开放,对修改关闭。
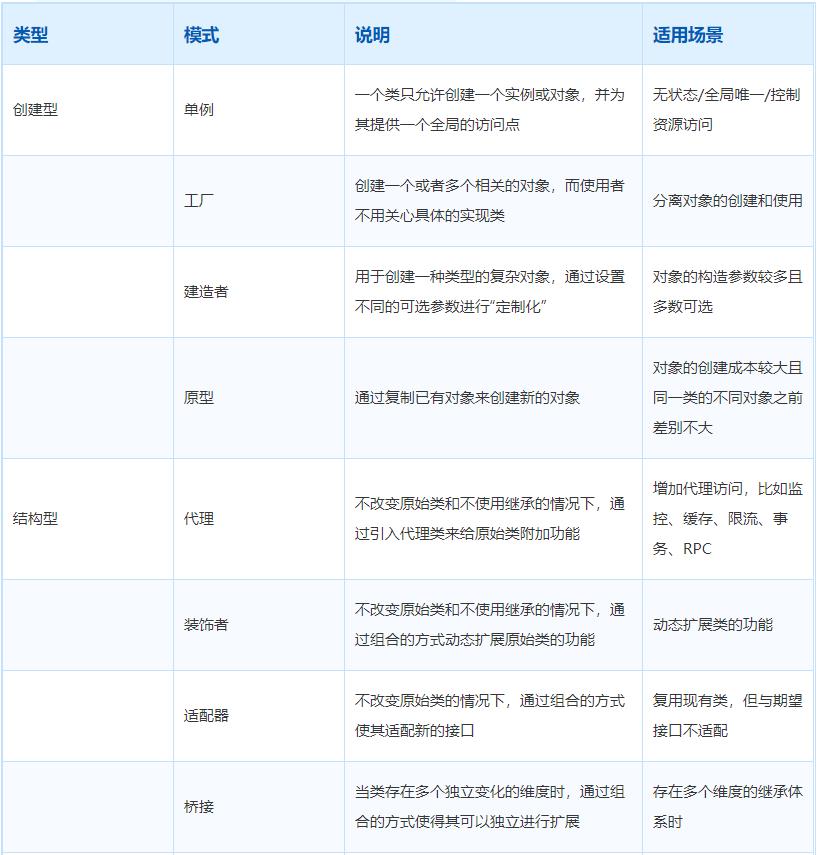
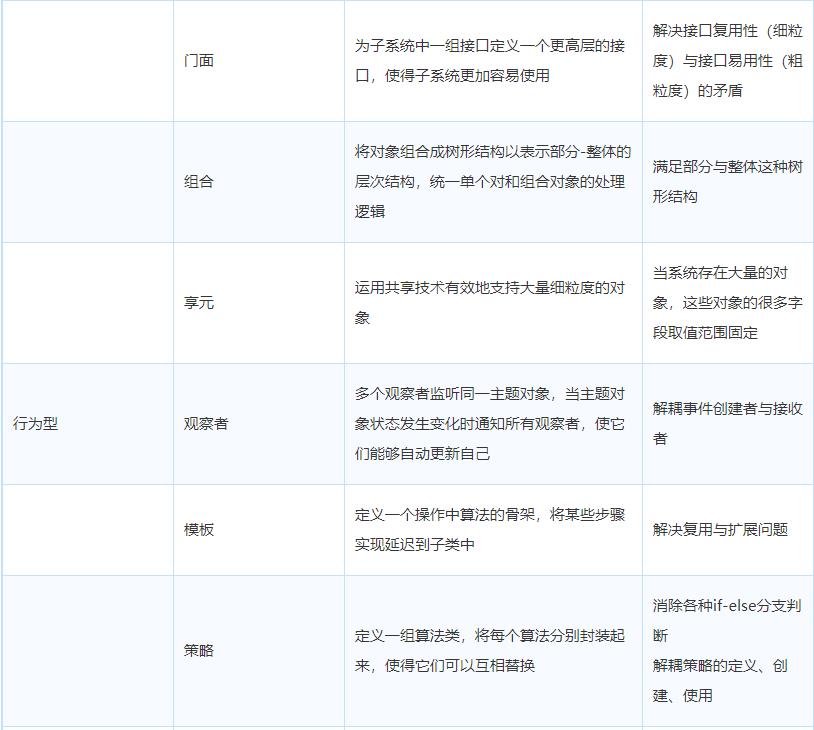
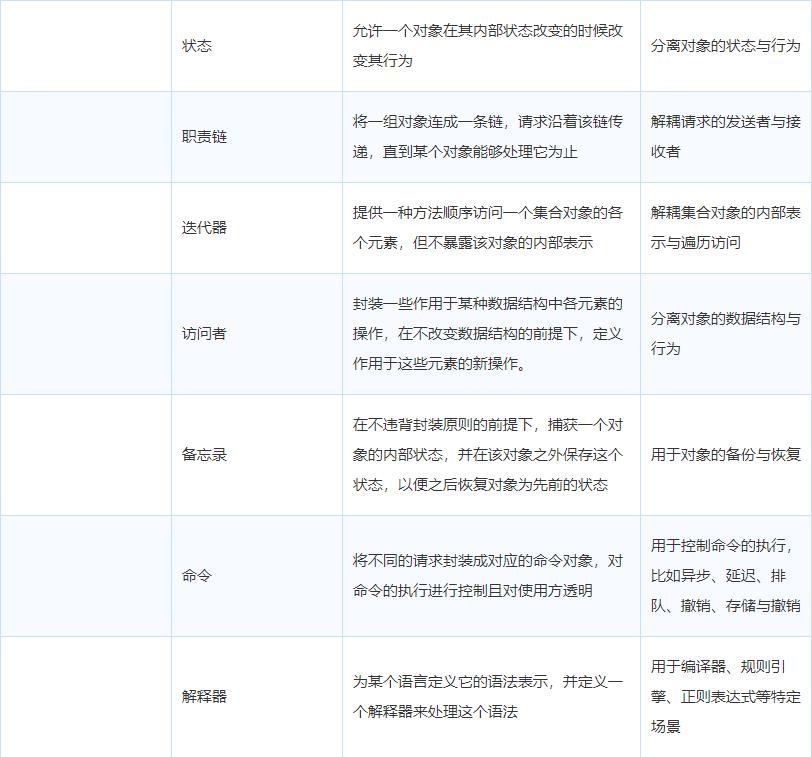
设计模式
设计模式:软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。每种模式都描述了一个在我们周围不断重复发生的问题,以及该问题的核心解决方案。
创建型:主要解决对象的创建问题,封装复杂的创建过程,解耦对象的创建代码和使用代码
结构型:主要通过类或对象的不同组合,解耦不同功能的耦合
行为型:主要解决的是类或对象之间的交互行为的耦合

代码分层
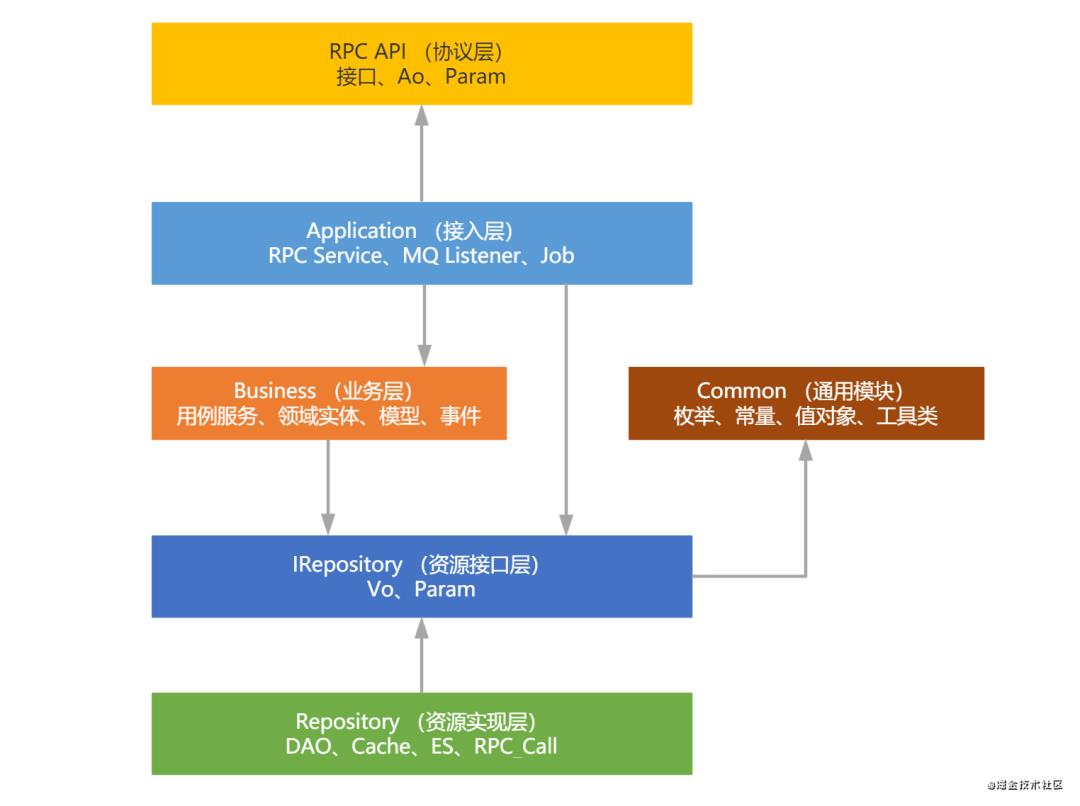
模块结构说明
server_main:配置层,负责整个项目的module管理,maven配置管理、资源管理等;
server_application:应用接入层,承接外部流量入口,例如:RPC接口实现、消息处理、定时任务等;不要在此包含业务逻辑;
server_biz:核心业务层,用例服务、领域实体、领域事件等
server_irepository:资源接口层,负责资源接口的暴露
server_repository:资源层,负责资源的proxy访问,统一外部资源访问,隔离变化。注意:这里强调的是弱业务性,强数据性;
server_common:公共层,vo、工具等
代码开发要遵守各层的规范,并注意层级之间的依赖关系。
命名规范
一个好的命名应该要满足以下两个约束:
准确描述所做得事情
格式符合通用的惯例
如果你觉得一个类或方法难以命名的时候,可能是其承载的功能太多了,需要进一步拆分。
约定俗称的惯例

类命名
类名使用大驼峰命名形式,类命通常使用名词或名词短语。接口名除了用名词和名词短语以外,还可以使用形容词或形容词短语,如 Cloneable,Callable 等,表示实现该接口的类有某种功能或能力。
方法命名
方法命名采用小驼峰的形式,首字小写,往后的每个单词首字母都要大写。和类名不同的是,方法命名一般为动词或动词短语,与参数或参数名共同组成动宾短语,即动词 + 名词。一个好的函数名一般能通过名字直接获知该函数实现什么样的功能。

重构技巧
提炼方法
多个方法代码重复、方法中代码过长或者方法中的语句不在一个抽象层级。
方法是代码复用的最小粒度,方法过长不利于复用,可读性低,提炼方法往往是重构工作的第一步。
意图导向编程:把处理某件事的流程和具体做事的实现方式分开。
把一个问题分解为一系列功能性步骤,并假定这些功能步骤已经实现
我们只需把把各个函数组织在一起即可解决这一问题
在组织好整个功能后,我们在分别实现各个方法函数
/**
* 1、交易信息开始于一串标准ASCII字符串。
* 2、这个信息字符串必须转换成一个字符串的数组,数组存放的此次交易的领域语言中所包含的词汇元素(token)。
* 3、每一个词汇必须标准化。
* 4、包含超过150个词汇元素的交易,应该采用不同于小型交易的方式(不同的算法)来提交,以提高效率。
* 5、如果提交成功,API返回”true”;失败,则返回”false”。
*/
public class Transaction {
public Boolean commit(String command) {
Boolean result = true;
String[] tokens = tokenize(command);
normalizeTokens(tokens);
if (isALargeTransaction(tokens)) {
result = processLargeTransaction(tokens);
} else {
result = processSmallTransaction(tokens);
}
return result;
}
}
以函数对象取代函数
将函数放进一个单独对象中,如此一来局部变量就变成了对象内的字段。然后你可以在同一个对象中将这个大型函数分解为多个小型函数。
引入参数对象
方法参数比较多时,将参数封装为参数对象
移除对参数的赋值
public int discount(int inputVal, int quantity, int yearToDate) {
if (inputVal > 50) inputVal -= 2;
if (quantity > 100) inputVal -= 1;
if (yearToDate > 10000) inputVal -= 4;
return inputVal;
}
public int discount(int inputVal, int quantity, int yearToDate) {
int result = inputVal;
if (inputVal > 50) result -= 2;
if (quantity > 100) result -= 1;
if (yearToDate > 10000) result -= 4;
return result;
}
将查询与修改分离
任何有返回值的方法,都不应该有副作用
不要在convert中调用写操作,避免副作用
常见的例外:将查询结果缓存到本地
移除不必要临时变量
临时变量仅使用一次或者取值逻辑成本很低的情况下
引入解释性变量
将复杂表达式(或其中一部分)的结果放进一个临时变量,以此变量名称来解释表达式用途
if ((platform.toUpperCase().indexOf("MAC") > -1)
&& (browser.toUpperCase().indexOf("IE") > -1) && wasInitialized() && resize > 0) {
// do something
}
final boolean isMacOs = platform.toUpperCase().indexOf("MAC") > -1;
final boolean isIEBrowser = browser.toUpperCase().indexOf("IE") > -1;
final boolean wasResized = resize > 0;
if (isMacOs && isIEBrowser && wasInitialized() && wasResized) {
// do something
}
使用卫语句替代嵌套条件判断
把复杂的条件表达式拆分成多个条件表达式,减少嵌套。嵌套了好几层的if - then-else语句,转换为多个if语句
//未使用卫语句
public void getHello(int type) {
if (type == 1) {
return;
} else {
if (type == 2) {
return;
} else {
if (type == 3) {
return;
} else {
setHello();
}
}
}
}
//使用卫语句
public void getHello(int type) {
if (type == 1) {
return;
}
if (type == 2) {
return;
}
if (type == 3) {
return;
}
setHello();
}
使用多态替代条件判断断
当存在这样一类条件表达式,它根据对象类型的不同选择不同的行为。可以将这种表达式的每个分支放进一个子类内的复写函数中,然后将原始函数声明为抽象函数。
public int calculate(int a, int b, String operator) {
int result = Integer.MIN_VALUE;
if ("add".equals(operator)) {
result = a + b;
} else if ("multiply".equals(operator)) {
result = a * b;
} else if ("divide".equals(operator)) {
result = a / b;
} else if ("subtract".equals(operator)) {
result = a - b;
}
return result;
}
当出现大量类型检查和判断时,if else(或switch)语句的体积会比较臃肿,这无疑降低了代码的可读性。 另外,if else(或switch)本身就是一个“变化点”,当需要扩展新的类型时,我们不得不追加if else(或switch)语句块,以及相应的逻辑,这无疑降低了程序的可扩展性,也违反了面向对象的开闭原则。
基于这种场景,我们可以考虑使用“多态”来代替冗长的条件判断,将if else(或switch)中的“变化点”封装到子类中。这样,就不需要使用if else(或switch)语句了,取而代之的是子类多态的实例,从而使得提高代码的可读性和可扩展性。很多设计模式使用都是这种套路,比如策略模式、状态模式。
public interface Operation {
int apply(int a, int b);
}
public class Addition implements Operation {
@Override
public int apply(int a, int b) {
return a + b;
}
}
public class OperatorFactory {
private final static Map<String, Operation> operationMap = new HashMap<>();
static {
operationMap.put("add", new Addition());
operationMap.put("divide", new Division());
// more operators
}
public static Operation getOperation(String operator) {
return operationMap.get(operator);
}
}
public int calculate(int a, int b, String operator) {
if (OperatorFactory .getOperation == null) {
throw new IllegalArgumentException("Invalid Operator");
}
return OperatorFactory .getOperation(operator).apply(a, b);
}
使用异常替代返回错误码
非正常业务状态的处理,使用抛出异常的方式代替返回错误码
不要使用异常处理用于正常的业务流程控制
异常处理的性能成本非常高
尽量使用标准异常
避免在finally语句块中抛出异常
如果同时抛出两个异常,则第一个异常的调用栈会丢失
finally块中应只做关闭资源这类的事情
//使用错误码
public boolean withdraw(int amount) {
if (balance < amount) {
return false;
} else {
balance -= amount;
return true;
}
}
//使用异常
public void withdraw(int amount) {
if (amount > balance) {
throw new IllegalArgumentException("amount too large");
}
balance -= amount;
}
引入断言
某一段代码需要对程序状态做出某种假设,以断言明确表现这种假设。
不要滥用断言,不要使用它来检查“应该为真”的条件,只使用它来检查“一定必须为真”的条件
如果断言所指示的约束条件不能满足,代码是否仍能正常运行?如果可以就去掉断言
引入Null对象或特殊对象
当使用一个方法返回的对象时,而这个对象可能为空,这个时候需要对这个对象进行操作前,需要进行判空,否则就会报空指针。当这种判断频繁的出现在各处代码之中,就会影响代码的美观程度和可读性,甚至增加Bug的几率。
空引用的问题在Java中无法避免,但可以通过代码编程技巧(引入空对象)来改善这一问题。
//空对象的例子
public class OperatorFactory {
static Map<String, Operation> operationMap = new HashMap<>();
static {
operationMap.put("add", new Addition());
operationMap.put("divide", new Division());
// more operators
}
public static Optional<Operation> getOperation(String operator) {
return Optional.ofNullable(operationMap.get(operator));
}
}
public int calculate(int a, int b, String operator) {
Operation targetOperation = OperatorFactory.getOperation(operator)
.orElseThrow(() -> new IllegalArgumentException("Invalid Operator"));
return targetOperation.apply(a, b);
}
//特殊对象的例子
public class InvalidOp implements Operation {
@Override
public int apply(int a, int b) {
throw new IllegalArgumentException("Invalid Operator");
}
}
提炼类
根据单一职责原则,一个类应该有明确的责任边界。但在实际工作中,类会不断的扩展。当给某个类添加一项新责任时,你会觉得不值得分离出一个单独的类。于是,随着责任不断增加,这个类包含了大量的数据和函数,逻辑复杂不易理解。
此时你需要考虑将哪些部分分离到一个单独的类中,可以依据高内聚低耦合的原则。如果某些数据和方法总是一起出现,或者某些数据经常同时变化,这就表明它们应该放到一个类中。另一种信号是类的子类化方式:如果你发现子类化只影响类的部分特性,或者类的特性需要以不同方式来子类化,这就意味着你需要分解原来的类。
//原始类
public class Person {
private String name;
private String officeAreaCode;
private String officeNumber;
public String getName() {
return name;
}
public String getTelephoneNumber() {
return ("(" + officeAreaCode + ")" + officeNumber);
}
public String getOfficeAreaCode() {
return officeAreaCode;
}
public void setOfficeAreaCode(String arg) {
officeAreaCode = arg;
}
public String getOfficeNumber() {
return officeNumber;
}
public void setOfficeNumber(String arg) {
officeNumber = arg;
}
}
//新提炼的类(以对象替换数据值)
public class TelephoneNumber {
private String areaCode;
private String number;
public String getTelephnoeNumber() {
return ("(" + getAreaCode() + ")" + number);
}
String getAreaCode() {
return areaCode;
}
void setAreaCode(String arg) {
areaCode = arg;
}
String getNumber() {
return number;
}
void setNumber(String arg) {
number = arg;
}
}
组合优先于继承
继承使实现代码重用的有力手段,但这并非总是完成这项工作的最佳工具,使用不当会导致软件变得很脆弱。与方法调用不同的是,继承打破了封装性。子类依赖于其父类中特定功能的实现细节,如果父类的实现随着发行版本的不同而变化,子类可能会遭到破坏,即使他的代码完全没有改变。
举例说明,假设有一个程序使用HashSet,为了调优该程序的性能,需要统计HashSet自从它创建以来添加了多少个元素。为了提供该功能,我们编写一个HashSet的变体。
// Inappropriate use of inheritance!
public class InstrumentedHashSet<E> extends HashSet<E> {
// The number of attempted element insertions
private int addCount = 0;
public InstrumentedHashSet() { }
public InstrumentedHashSet(int initCap, float loadFactor) {
super(initCap, loadFactor);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
通过在新的类中增加一个私有域,它引用现有类的一个实例,这种设计被称为组合,因为现有的类变成了新类的一个组件。这样得到的类将会非常稳固,它不依赖现有类的实现细节。即使现有的类添加了新的方法,也不会影响新的类。许多设计模式使用就是这种套路,比如代理模式、装饰者模式
// Reusable forwarding class
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s;
public ForwardingSet(Set<E> s) { this.s = s; }
@Override
public int size() { return s.size(); }
@Override
public boolean isEmpty() { return s.isEmpty(); }
@Override
public boolean contains(Object o) { return s.contains(o); }
@Override
public Iterator<E> iterator() { return s.iterator(); }
@Override
public Object[] toArray() { return s.toArray(); }
@Override
public <T> T[] toArray(T[] a) { return s.toArray(a); }
@Override
public boolean add(E e) { return s.add(e); }
@Override
public boolean remove(Object o) { return s.remove(o); }
@Override
public boolean containsAll(Collection<?> c) { return s.containsAll(c); }
@Override
public boolean addAll(Collection<? extends E> c) { return s.addAll(c); }
@Override
public boolean retainAll(Collection<?> c) { return s.retainAll(c); }
@Override
public boolean removeAll(Collection<?> c) { return s.removeAll(c); }
@Override
public void clear() { s.clear(); }
}
// Wrappter class - uses composition in place of inheritance
public class InstrumentedHashSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedHashSet1(Set<E> s) {
super(s);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
继承与组合如何取舍
只有当子类真正是父类的子类型时,才适合继承。对于两个类A和B,只有两者之间确实存在“is-a”关系的时候,类B才应该继承A;
在包的内部使用继承是非常安全的,子类和父类的实现都处在同一个程序员的控制之下;
对于专门为了继承而设计并且具有很好的文档说明的类来说,使用继承也是非常安全的;
其他情况就应该优先考虑组合的方式来实现
接口优于抽象类
Java提供了两种机制,可以用来定义允许多个实现的类型:接口和抽象类。自从Java8为接口增加缺省方法(default method),这两种机制都允许为实例方法提供实现。主要区别在于,为了实现由抽象类定义的类型,类必须称为抽象类的一个子类。因为Java只允许单继承,所以用抽象类作为类型定义受到了限制。
接口相比于抽象类的优势:
现有的类可以很容易被更新,以实现新的接口。
接口是定义混合类型(比如Comparable)的理想选择。
接口允许构造非层次结构的类型框架。
接口虽然提供了缺省方法,但接口仍有有以下局限性:
接口的变量修饰符只能是public static final的
接口的方法修饰符只能是public的
接口不存在构造函数,也不存在this
可以给现有接口增加缺省方法,但不能确保这些方法在之前存在的实现中都能良好运行。
因为这些默认方法是被注入到现有实现中的,它们的实现者并不知道,也没有许可
接口缺省方法的设计目的和优势在于:
为了接口的演化
Java 8 之前我们知道,一个接口的所有方法其子类必须实现(当然,这个子类不是一个抽象类),但是 java 8 之后接口的默认方法可以选择不实现,如上的操作是可以通过编译期编译的。这样就避免了由 Java 7 升级到 Java 8 时项目编译报错了。Java8在核心集合接口中增加了许多新的缺省方法,主要是为了便于使用lambda。
可以减少第三方工具类的创建
例如在 List 等集合接口中都有一些默认方法,List 接口中默认提供 replaceAll(UnaryOperator)、sort(Comparator)、、spliterator()等默认方法,这些方法在接口内部创建,避免了为了这些方法而专门去创建相应的工具类。
可以避免创建基类
在 Java 8 之前我们可能需要创建一个基类来实现代码复用,而默认方法的出现,可以不必要去创建基类。
由于接口的局限性和设计目的的不同,接口并不能完全替换抽象类。但是通过对接口提供一个抽象的骨架实现类,可以把接口和抽象类的优点结合起来。 接口负责定义类型,或许还提供一些缺省方法,而骨架实现类则负责实现除基本类型接口方法之外,剩下的非基本类型接口方法。扩展骨架实现占了实现接口之外的大部分工作。这就是模板方法(Template Method)设计模式。
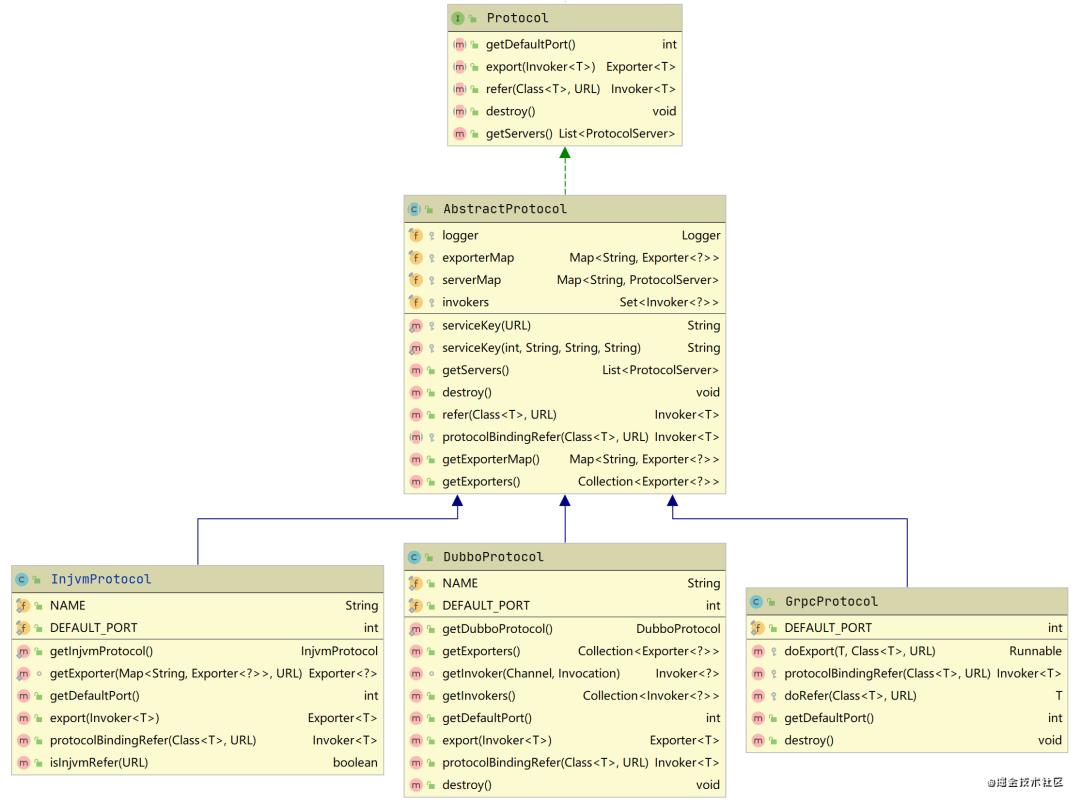
接口Protocol:定义了RPC协议层两个主要的方法,export暴露服务和refer引用服务
抽象类AbstractProtocol:封装了暴露服务之后的Exporter和引用服务之后的Invoker实例,并实现了服务销毁的逻辑
具体实现类XxxProtocol:实现export暴露服务和refer引用服务具体逻辑
优先考虑泛型
声明中具有一个或者多个类型参数(type parameter)的类或者接口,就是泛型(generic)类或者接口。泛型类和接口统称为泛型(generic type)。泛型从Java 5引入,提供了编译时类型安全检测机制。泛型的本质是参数化类型,通过一个参数来表示所操作的数据类型,并且可以限制这个参数的类型范围。泛型的好处就是编译期类型检测,避免类型转换。
// 比较三个值并返回最大值
public static <T extends Comparable<T>> T maximum(T x, T y, T z) {
T max = x;
// 假设x是初始最大值
if ( y.compareTo( max ) > 0 ) {
max = y; //y 更大
} if ( z.compareTo( max ) > 0 ) {
max = z; // 现在 z 更大
} return max; // 返回最大对象
}
public static void main( String args[] ) {
System.out.printf( "%d, %d 和 %d 中最大的数为 %d\\n\\n", 3, 4, 5, maximum( 3, 4, 5 ));
System.out.printf( "%.1f, %.1f 和 %.1f 中最大的数为 %.1f\\n\\n", 6.6, 8.8, 7.7, maximum( 6.6, 8.8, 7.7 ));
System.out.printf( "%s, %s 和 %s 中最大的数为 %s\\n","pear", "apple", "orange", maximum( "pear", "apple", "orange" ) );
}
不要使用原生态类型
由于为了保持Java代码的兼容性,支持和原生态类型转换,并使用擦除机制实现的泛型。但是使用原生态类型就会失去泛型的优势,会受到编译器警告。
要尽可能地消除每一个非受检警告
每一条警告都表示可能在运行时抛出ClassCastException异常。要尽最大的努力去消除这些警告。如果无法消除但是可以证明引起警告的代码是安全的,就可以在尽可能小的范围中,使用@SuppressWarnings("unchecked")注解来禁止警告,但是要把禁止的原因记录下来。
利用有限制通配符来提升API的灵活性
参数化类型不支持协变的,即对于任何两个不同的类型Type1和Type2而言,List既不是List的子类型,也不是它的超类。为了解决这个问题,提高灵活性,Java提供了一种特殊的参数化类型,称作有限制的通配符类型,即List<? extends E>和List<? super E>。使用原则是producer-extends,consumer-super(PECS)。如果即是生产者,又是消费者,就没有必要使用通配符了。
还有一种特殊的无限制通配符List<?>,表示某种类型但不确定。常用作泛型的引用,不可向其添加除Null以外的任何对象。
//List<? extends E>
// Number 可以认为 是Number 的 "子类"
List<? extends Number> numberArray = new ArrayList<Number>();
// Integer 是 Number 的子类
List<? extends Number> numberArray = new ArrayList<Integer>();
// Double 是 Number 的子类
List<? extends Number> numberArray = new ArrayList<Double>();
//List<? super E>
// Integer 可以认为是 Integer 的 "父类"
List<? super Integer> array = new ArrayList<Integer>();、
// Number 是 Integer 的 父类
List<? super Integer> array = new ArrayList<Number>();
// Object 是 Integer 的 父类
List<? super Integer> array = new ArrayList<Object>();
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD || (src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
静态成员类优于非静态成员类
嵌套类(nested class)是指定义在另一个类的内部的类。嵌套类存在的目的只是为了它的外部类提供服务,如果其他的环境也会用到的话,应该成为一个顶层类(top-level class)。 嵌套类有四种:静态成员类(static member class)、非静态成员类(nonstatic member class)、匿名类(anonymous class)和 局部类(local class)。除了第一种之外,其他三种都称为内部类(inner class)。
匿名类(anonymous class)
没有名字,声明的同时进行实例化,只能使用一次。当出现在非静态的环境中,会持有外部类实例的引用。通常用于创建函数对象和过程对象,不过现在会优先考虑lambda。
局部类(local class)
任何可以声明局部变量的地方都可以声明局部类,同时遵循同样的作用域规则。跟匿名类不同的是,有名字可以重复使用。不过实际很少使用局部类。
静态成员类(static member class)
最简单的一种嵌套类,声明在另一个类的内部,是这个类的静态成员,遵循同样的可访问性规则。常见的用法是作为公有的辅助类,只有与它的外部类一起使用才有意义。
非静态成员类(nonstatic member class)
尽管语法上,跟静态成员类的唯一区别就是类的声明不包含static,但两者有很大的不同。非静态成员类的每个实例都隐含地与外部类的实例相关联,可以访问外部类的成员属性和方法。另外必须先创建外部类的实例之后才能创建非静态成员类的实例。
总而言之,这四种嵌套类都有自己的用途。假设这个嵌套类属于一个方法的内部,如果只需要在一个地方创建实例,并且已经有了一个预置的类型可以说明这个类的特征,就要把它做成匿名类。如果一个嵌套类需要在单个方法之外仍然可见,或者它太长了,不适合放在方法内部,就应该使用成员类。如果成员类的每个实例都需要一个指向其外围实例的引用,就要把成员类做成非静态的,否则就做成静态的。
优先使用模板/工具类
通过对常见场景的代码逻辑进行抽象封装,形成相应的模板工具类,可以大大减少重复代码,专注于业务逻辑,提高代码质量。
分离对象的创建与使用
面向对象编程相对于面向过程,多了实例化这一步,而对象的创建必须要指定具体类型。我们常见的做法是“哪里用到,就在哪里创建”,使用实例和创建实例的是同一段代码。这似乎使代码更具有可读性,但是某些情况下造成了不必要的耦合。
public class BusinessObject {
public void actionMethond {
//Other things
Service myServiceObj = new Service();
myServiceObj.doService();
//Other things
}
}
public class BusinessObject {
public void actionMethond {
//Other things
Service myServiceObj = new ServiceImpl();
myServiceObj.doService();
//Other things
}
}
public class BusinessObject {
private Service myServiceObj;
public BusinessObject(Service aService) {
myServiceObj = aService;
}
public void actionMethond {
//Other things
myServiceObj.doService();
//Other things
}
}
public class BusinessObject {
private Service myServiceObj;
public BusinessObject() {
myServiceObj = ServiceFactory;
}
public void actionMethond {
//Other things
myServiceObj.doService();
//Other things
}
}
对象的创建者耦合的是对象的具体类型,而对象的使用者耦合的是对象的接口。也就是说,创建者关心的是这个对象是什么,而使用者关心的是它能干什么。这两者应该视为独立的考量,它们往往会因为不同的原因而改变。
当对象的类型涉及多态、对象创建复杂(依赖较多)可以考虑将对象的创建过程分离出来,使得使用者不用关注对象的创建细节。设计模式中创建型模式的出发点就是如此,实际项目中可以使用工厂模式、构建器、依赖注入的方式。
可访问性最小化
区分一个组件设计得好不好,一个很重要的因素在于,它对于外部组件而言,是否隐藏了其内部数据和实现细节。Java提供了访问控制机制来决定类、接口和成员的可访问性。实体的可访问性由该实体声明所在的位置,以及该实体声明中所出现的访问修饰符(private、protected、public)共同决定的。
对于顶层的(非嵌套的)类和接口,只有两种的访问级别:包级私有的(没有public修饰)和公有的(public修饰)。
对于成员(实例/域、方法、嵌套类和嵌套接口)由四种的访问级别,可访问性如下递增:
私有的(private修饰)--只有在声明该成员的顶层类内部才可以访问这个成员;
包级私有的(默认)--声明该成员的包内部的任何类都可以访问这个成员;
受保护的(protected修饰)--声明该成员的类的子类可以访问这个成员,并且声明该成员的包内部的任何类也可以访问这个成员;
公有的(public修饰)--在任何地方都可以访问该成员;
正确地使用这些修饰符对于实现信息隐藏是非常关键的,原则就是:尽可能地使每个类和成员不被外界访问(私有或包级私有)。这样好处就是在以后的发行版本中,可以对它进行修改、替换或者删除,而无须担心会影响现有的客户端程序。
如果类或接口能够做成包级私有的,它就应该被做成包级私有的;
如果一个包级私有的顶层类或接口只是在某一个类的内部被用到,就应该考虑使它成为那个类的私有嵌套类;
公有类不应直接暴露实例域,应该提供相应的方法以保留将来改变该类的内部表示法的灵活性;
当确定了类的公有API之后,应该把其他的成员都变成私有的;
如果同一个包下的类之间存在比较多的访问时,就要考虑重新设计以减少这种耦合;
可变性最小化
不可变类是指其实例不能被修改的类。每个实例中包含的所有信息都必须在创建该实例时提供,并在对象的整个生命周期内固定不变。不可变类好处就是简单易用、线程安全、可自由共享而不容易出错。Java平台类库中包含许多不可变的类,比如String、基本类型包装类、BigDecimal等。
为了使类成为不可变,要遵循下面五条规则:
声明所有的域都是私有的
声明所有的域都是final的
如果一个指向新创建实例的引用在缺乏同步机制的情况下,从一个线程被传递到另一个线程,就必须确保正确的行为
不提供任何会修改对象状态的方法
保证类不会被扩展(防止子类化,类声明为final)
防止粗心或者恶意的子类假装对象的状态已经改变,从而破坏该类的不可变行为
确保对任何可变组件的互斥访问
如果类具有指向可变对象的域,则必须确保该类的客户端无法获得指向这些对象的引用。并且,永远不要用客户端提供的对象引用来初始化这样的域,也不要从任何访问方法中返回该对象引用。在构造器、访问方法和readObject 方法中使用保护性拷贝技术
可变性最小化的一些建议:
除非有很好的理由要让类成为可变的类,否则它就应该是不可变的;
如果类不能被做成不可变的,仍然应该尽可能地限制它的可变性;
除非有令人信服的理由要使域变成非final的,否则要使每个域都是private final的;
构造器应该创建完全初始化的对象,并建立起所有的约束关系;
质量如何保证
测试驱动开发
测试驱动开发(TDD)要求以测试作为开发过程的中心,要求在编写任何代码之前,首先编写用于产码行为的测试,而编写的代码又要以使测试通过为目标。TDD要求测试可以完全自动化地运行,并在对代码重构前后必须运行测试。
TDD的最终目标是整洁可用的代码(clean code that works)。大多数的开发者大部分时间无法得到整洁可用的代码。办法是分而治之。首先解决目标中的“可用”问题,然后再解决“代码的整洁”问题。这与体系结构驱动(architecture-driven)的开发相反。
采用TDD另一个好处就是让我们拥有一套伴随代码产生的详尽的自动化测试集。将来无论出于任何原因(需求、重构、性能改进)需要对代码进行维护时,在这套测试集的驱动下工作,我们代码将会一直是健壮的。
TDD的开发周期
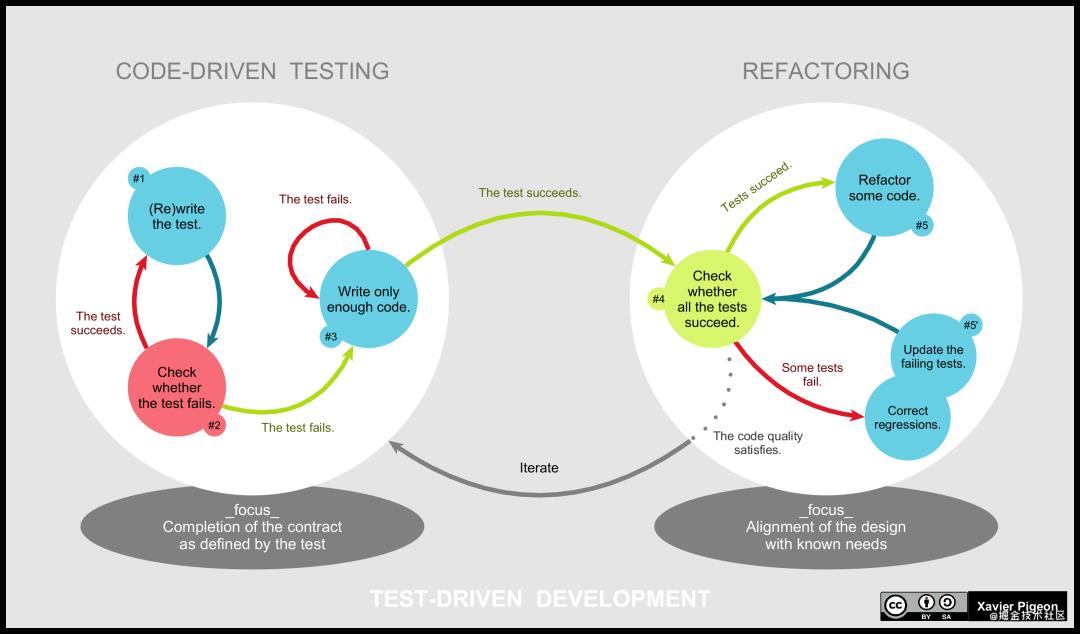
添加一个测试 -> 运行所有测试并检查测试结果 -> 编写代码以通过测试 -> 运行所有测试且全部通过 -> 重构代码,以消除重复设计,优化设计结构
两个基本的原则
仅在测试失败时才编写代码并且只编写刚好使测试通过的代码
编写下一个测试之前消除现有的重复设计,优化设计结构
关注点分离是这两条规则隐含的另一个非常重要的原则。其表达的含义指在编码阶段先达到代码“可用”的目标,在重构阶段再追求“整洁”目标,每次只关注一件事!
分层测试点
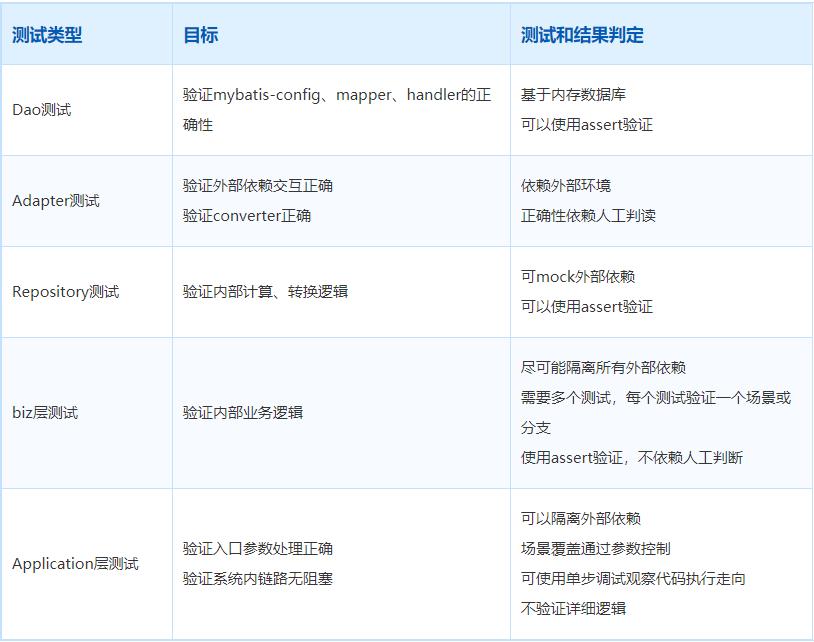
From: juejin.cn/post/6954378167947624484
想知道更多?扫描下面的二维码关注我后台回复"技术",加入技术群后台回复“k8s”,可领取k8s资料
【精彩推荐】
以上是关于非常实用的代码重构技巧的主要内容,如果未能解决你的问题,请参考以下文章