京东到家多数据源同步的架构设计与实践
Posted 达达集团技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东到家多数据源同步的架构设计与实践相关的知识,希望对你有一定的参考价值。
从最初的单机应用到现在的大型互联网分布式系统,数据源一直在业务系统中扮演着重要的角色,多样的需求造就了mysql、Memcached、Redis、Elasticsearch等这些耳熟能详的存储组件,因各自的特点,在系统中承担着不同的职能。因为数据量、访问量等挑战,我们时常又面临着各种维度的分库分表,数据冗余复杂度。本文从京东到家提示音的需求出发,探讨多数据源的职责分工,数据异构同步实践和问题总结,大致分为以下三个部分
提示音业务背景
履约系统的数据源职责分工
数据异构的实践、问题和总结
提示音业务背景
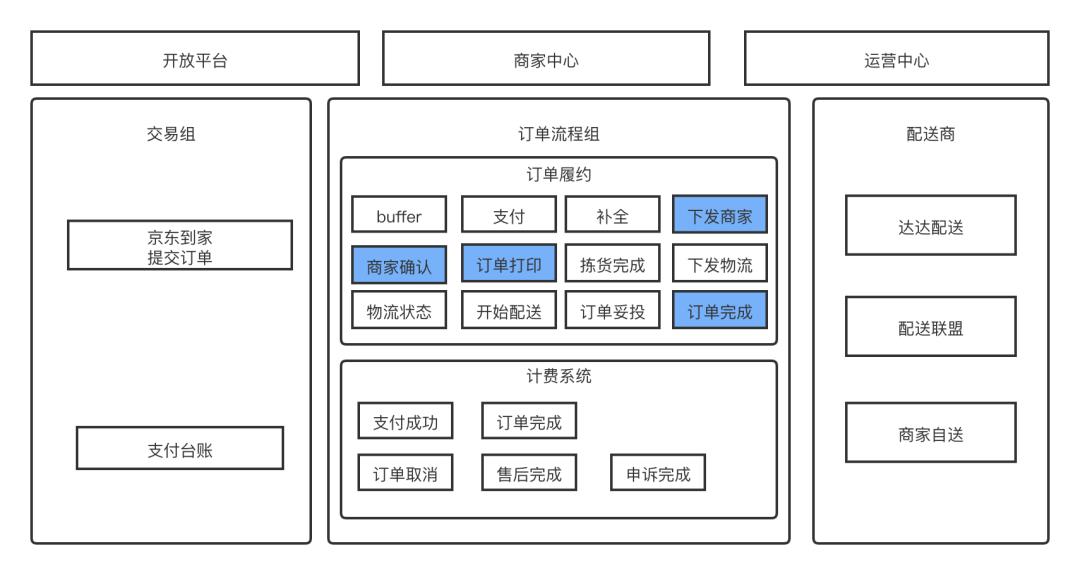
订单履约系统是电商系统的核心生产流程,对于京东到家来说也不例外,到家的履约系统涉及到用户、商家、物流多端的交互。如下图所示,从用户提交订单到服务履约系统,大致经历了支付、下发商家、商家确认、订单打印、拣货、下发物流、配送、妥投等环节,这是一个基本的即时零售履约流程。标蓝的流程是到家和商家交互的功能点,比如:下发商家、订单打印等环节。把订单下发给商家时,首当其冲的环节是商家要确认这个订单,并且开始履约流程。但是,在实际业务中,商家在有些情况往往会出现履约瓶颈,比如过分忙碌或闲暇的时间段,商家不会一直盯着管理系统等待新订单的来临。这时商家需要一个提示功能,即提示音需求。
提示音需求需要不断的查询底层存储Es,并提示给商家有订单到达了,需要商家开始履约流程,如果商家没有响应。就不断查询,不断提示。就是这样的一个循环提醒的功能,在大促期间,订单量级增大导致查询量级也对应增大。基本上每次大促都会把ES查到CPU飙高,甚至出现不可用的情况。为了保护履约系统,临时方案是做一个功能开关,在大促期间对提示音功能降级,不再查询和提示商家,由商家主动查看管理系统。可是降级并不是我们想要的方案。因为最终商家收不到提示。导致履约质量下降,于是提示音就面临一个问题,即“存储组件无法支撑提示音业务的查询体量”。
底层数据源职责分工
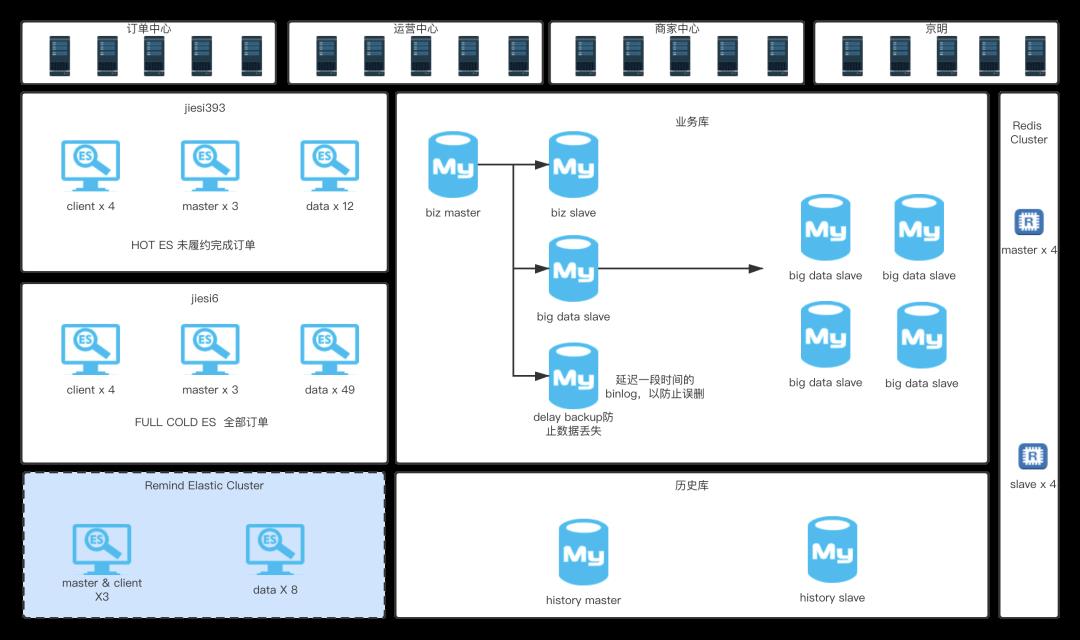
要解决面临的查询量级问题,就必须首先分析一下底层的存储方案。以下是对到家订单履约系统底层存储的一个整体概括,分职责进行介绍.
Redis
Redis在履约系统中主要承载的一个职责是worker跑批任务的存储和查询。因履约系统中大量运用了跑批任务来实现最终一致性设计,而Redis的Zset结构比较匹配这样的需求,将时间作为分值,不断的提供近期任务的查询是Redis在履约系统中充当的最大职能。为什么Redis没有承载过多的查询职能呢?一般Redis是应用于缓存场景,得益于其高性能,多样的数据结构特点。但是,在数据量和复杂的查询条件上,没有Es支持的好,关键点是业务系统查询条件复杂度是比较高的,所以,Redis没有承载过多的查询职能
Mysql
Mysql在履约系统存储中的职能是持久化存储订单数据,主要还是使用其强大的事务机制,以保障我们的数据写入正确性、可靠性。从履约流程上来看,将数据做冷热分离,热点数据是我们在履约中的订单.(也就是未完成的订单),而完成的订单,由于其使用率较低,我们称之为冷数据。这样的一个拆分也就是上图中对应的业务库和历史库。业务库是热库,而历史库则是冷库。冷热分离思想,使单库单表数据量维持在千万级别。从而避免了对应的分库分表复杂度。
从部署架构上看,我们对业务库进行了大量的主从分割。
biz slave是业务库从库,它也承载一些履约中的订单查询职能。
big data slave集群是大数据抽数据用做统计分析的职能。
delay slave设置延迟一定时间消费binlog是为了防止master被误操作而兜底的。比如错误执行了删除db的命令,这样的延迟消费机制就可以利用binlog进行兜底回滚。
Elasticsearch
Es在数据存储中承担了大量的查询职责,这主要取决于它优秀的查询能力,并有天然分布式的特点。在数据量复杂度解决方案上,避免了mysql分库分表的复杂度。这里我们一共有3个Es集群。其中HOT ES和FULL ES也是进行了冷热分离,这样对查询流量进行拆分,保证生产履约流程的独立性,从而保证履约系统的稳定性。
第三套ES集群Remind Elastic Cluster则是为了解决上述提示音的问题。在部署提示音集群之前,所有的提示音查询流量都是打到热集群的。也正是这样的访问量请求,导致了热集群时有发生CPU飙高,接口响应缓慢,卡顿业务线程,影响主流程生产。所以,我们对热集群进行了进一步的拆分,即提示音单独集群的方案。
数据写入复杂度问题
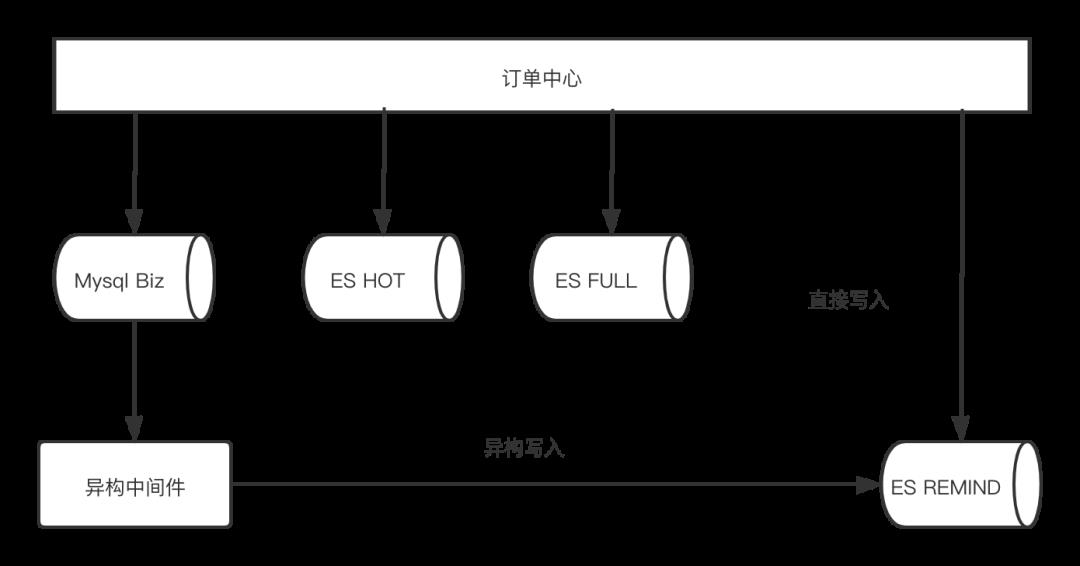
当确定冗余一套提示音集群以后,面临的问题就转变为了上图的写入复杂度问题,从图上来看,我们在拆分这套集群之前,订单中心每次操作订单写入。面临的是三个数据源的写入工作,现在提出第四套数据源 ES REMIND,如果仍然采用直接写入的方式,维护难度过大,这对研发人员是非常不友好的。于是考虑用异构中间件的方式来去写入ES REMIND的数据
异构中间件的优势是屏蔽了数据同步的复杂度,但是随之而来的是数据写入链路可靠性、及时性等问题。而且,数据传输本身一般都具有高可用的需求,之前,高可用在业务应用上,因为业务应用的集群方式本身是计算高可用的。但异构中间件则要在高可用、可靠性、及时性三个维度上满足我们的要求,于是我们了进行如下调研。
| 特性\产品 | Canal | Maxwell | Databus | CloudCanal |
|---|---|---|---|---|
| 社区活跃度 | 高 | 中 | 高 | 商业化产品 |
| 可用性 | 高 | 低 | 高 | 高 |
| 产品熟练度 | 高 | 低 | 低 | 高 |
首先,在常用的数据存储支撑上没有太大差别,常用的存储组件,这些异构中间件都是支持的。所以,我们更加着眼于以上3个指标。
社区活跃度代表了后续的维护性以及开源产品问题的快速响应
可用性方面的需求是非常强烈的,数据传输是不能中断的,提示音数据允许少量延迟,但不允许中断
最终采用Canal的根本原因还是在学习成本和熟练度上。
Canal简介和实践
经过对业务背景、底层数据存储支持、异构中间件的调研,我们最终采用了Canal作为本次需求异构的方案。
Canal工作流程简介
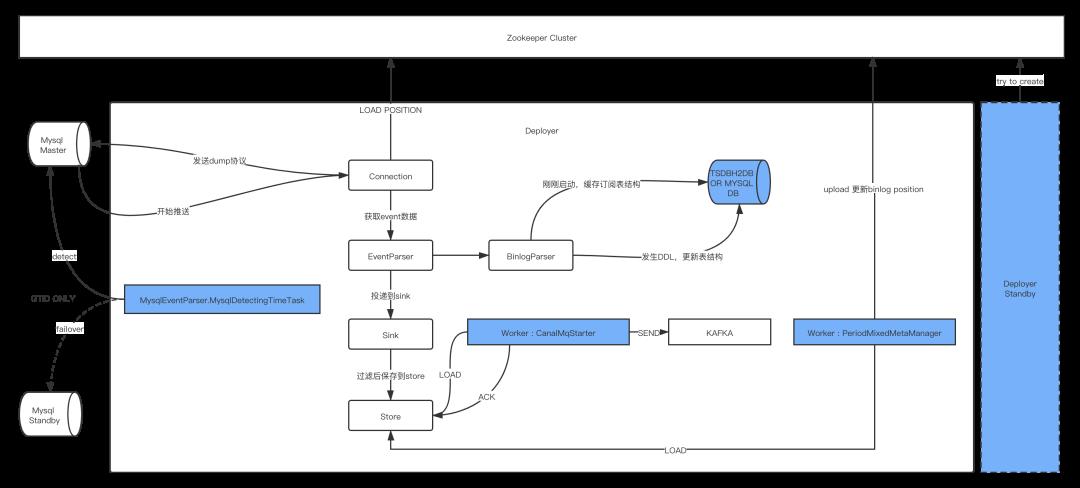
从职责拆分上,Canal主流程大致如上图所示,同步数据的工作大致分为以下几个步骤,Canal这种异步通信的设计要求你的系统必须具备可回溯、重试、幂等、延迟等特点,业务数据也必须有相应的容忍度。
Step1 Load&Store:Connection 从Zookeeper 获取到当前消费的binlog filename和position信息。随后将该信息附带到dump协议里,Mysql Master接到dump请求,开始推送binlog数据。Binlog经过Parser解析之后投递到Sink,Sink则承载了过滤消息的作用,过滤掉没有订阅的binlog事件,最终把消息存储到Store中。
Step2:Send&Ack:用任务worker的方式,不断扫描Store,最终将Store中的数据发送到目的地,目的地可以是具体的存储组件,也可以是mq产品。图中,Kafka是我们的实践方案所用,投递消息完成之后将消息ACK给Store组件。
Step3:Update MetaInfo:这个时候数据虽然发送了。但是,我们的元信息binlog的filename和position仍然没有更新,在这个操作上,Canal仍然采取了异步的方式去同步该信息,将最新的position同步到zookeeper上。
Canal的两种HA
Deployer的HA是靠Zookeeper的临时节点和重试机制实现的,一台Deployer实例成功启动后,就会在Zookeeper上创建对应的目录节点。此时,另外一台节点不断的检测目录是否存在,当启动中的主机故障,临时目录丢失,standby主机得以启动,从而保证Deployer的高可用
Mysql的HA则是靠一个单独的线程不断的Detect来实现的。但是,Mysql的HA,只能用GTID的模式,这是因为mysql master和slave的binlogfile name position是不一致的。如果用master的binlog filename和position去slave发送dump协议,这会出现无法匹配的问题。但是GTID是全局有序的,这也就导致了Mysql的HA只在GTID模式下才可用。
部署实践
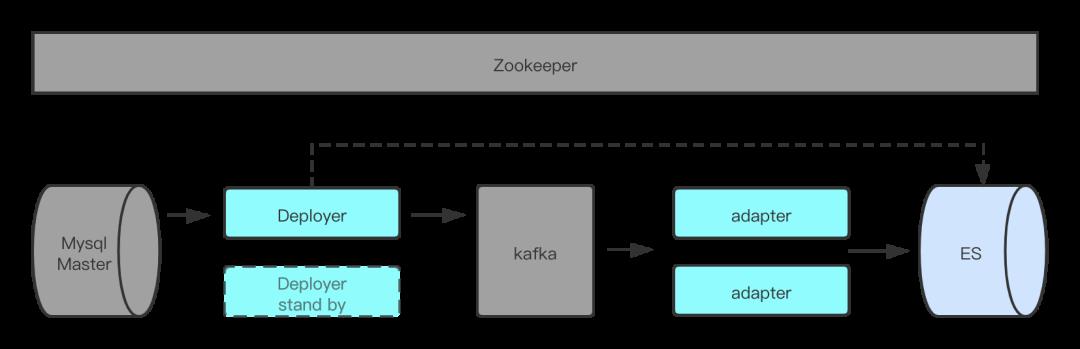
有了上面对Canal的大致了解,就有了到家的提示音异构实践,部署方式如上图。我们部署了两台Deployer用于数据传输的高可用。同时把消息投递到了kafka,利用adapter的集群部署进行批量消费,插入到提示音集群的Es中。在顺序性保障上采用了订单id hash的策略,保证在partition上是有序的。这样也就保证了在订单业务操作上是整体有序的。
在链路上采用kafka来传输,主要还是应对大促期间binlog数据量级的特点,保证插入到Es之前有缓冲buffer作用。这也是直连方式的弱点,直连方式在大数据量短时间写入时,对目的地存储组件有可能会造成瞬间的大量插入,从而损耗目的地存储组件的资源,可能影响到业务使用。但是,长链路也有数据延迟的缺点,如果对数据时效要求比较高的业务。还是建议用直连方式来搭建对应的异构方案。具体采用直连还是mq的方式同步,需要根据实际情况具体分析。
Meta Manager使用Zookeeper来存储,与Deployer的HA形成有效持久化配合。
实践问题&总结
问题一:kafka不可用
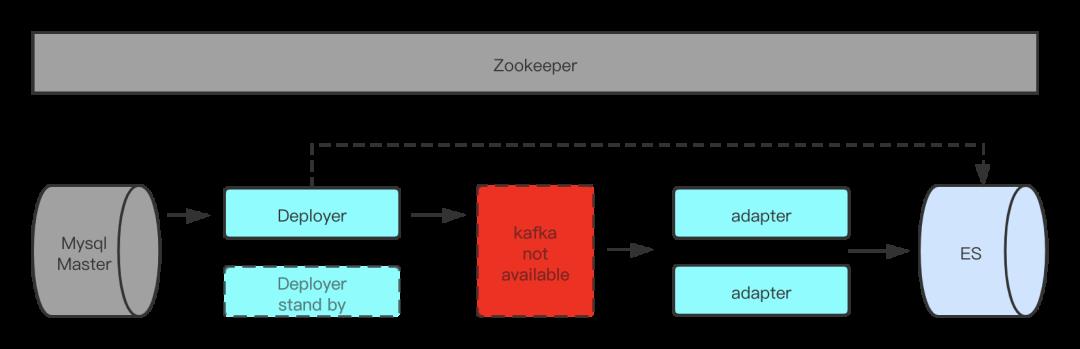
如上图,第一个比较有代表性的问题是kafka集群不可用,直接导致Es数据断层,从而影响到用户的履约体验。首先,kafka集群所在的网络环境和机器主机发生问题,Deployer的Store数据存满,直接导致数据delay了8个小时。提示音虽然没有提示,商家端也会有PC端的管理系统同步订单,但是需要商家主动刷新才可以刷新出来新的订单。所以,并不是所有的订单都履约超时,这导致过了很久才发现这个问题。紧急把访问切到之前的ES热集群。之后,重新把kafka服务部署到可用状态,数据虽然慢慢的追上了,但是原来在kafka中没有被adapter消费的一部分数据却丢掉了,这主要还是因为贪图了性能,设置了kafka落盘频率问题。
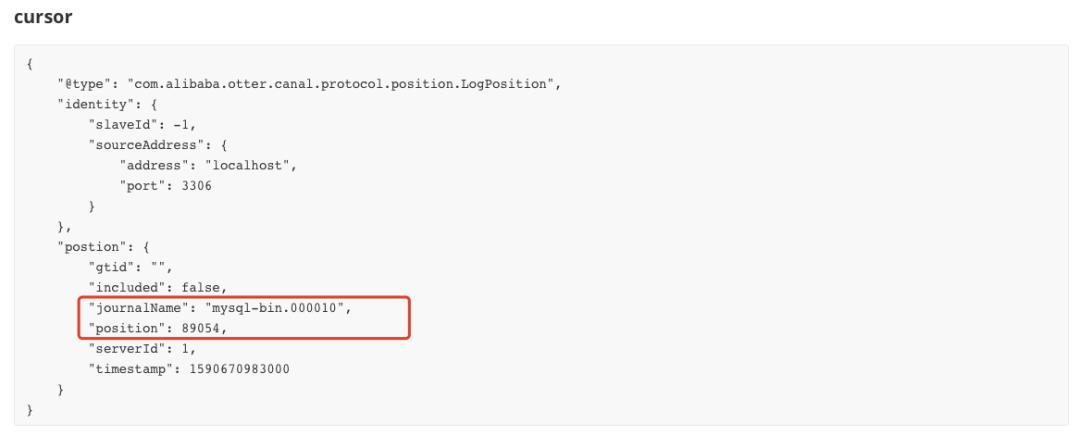
丢数据在数据异构的需求中是不可容忍的事情,索性这次事故基本上锁定了丢数据的原因。所以,我们将Zookeeper中存储的Canal元信息jouralName和position设置到对应的事故之前的位置,将数据重新跑到ES中,至此问题解决。
问题总结之一:报警和监控手段
在分布式系统的链路复杂度和数据量复杂度背景下,监控手段和必要的报警机制是至关重要的,如果没有发现问题更谈不上解决问题。比如kafka不可用问题很久都没有发现。引入了数据异构方案,但是却没有监控手段。这相当于自己在身边埋了一颗定时炸弹,真正发现的时候,可能已经无法挽回对应的损失了。在问题解决之后,搭建了对应的监控系统Promethos Grafana。并且,针对Promethos的Delay指标设置报警阈值,实时报警.
问题总结之二:数据异构的兜底方案
数据异构相比较业务系统来说,是一个需要非常谨慎的功能。毕竟数据是一切的根本。一般来说,如果没有数据异构的实践经验,不建议将该方案引入到生产的核心业务中。如果确实要引入数据异构方案,那必须考虑到所有可能的情况。错误情况多的话,势必会影响到业务迭代和功能落地的效率。由此,得出结论,如果无法穷举可能遇到的问题情况,那么,最起码要预见到最坏的情况。并考虑该情况下,业务应该如何的快速降级到可用情况,以求最小损失。这样才可以在之后的运行中,慢慢发现,慢慢解决。这要比一次性构想所有错误情况容易落地的多。比如kafka机器故障或网络故障情况,到家的做法是降级到了热集群做临时方案。想象一下,引入了数据异构组件,没有降级方案。出现故障,数据断层时所面临的业务影响和修复问题的压力是无比巨大的。
问题二:Deployer故障,自动HA
如上图所示,第二个遇到的问题是Deployer机器发生故障,系统自动HA到备机,任务得以继续消费。总起来说,问题二并没有给业务带来直接影响,但是,还是比较经典的一个案例。这需要回归到设计环节的讨论上,Canal实践初期,在成本视角,如下两个问题有很大的代表性,当初还是经过了一个比较有意义的讨论:
出于成本考虑,仅部署一台Deployer实例是否可以?
一台机器部署两个Deployer实例是否可以?
答案是不可以!单例部署,或在机器维度上的多例部署,都不能解决机器维度的故障,从而导致数据链路断层问题。出于总结,回顾一下高可用的范围:多机器、多机房、多地区、多国家。范围越大,高可用自然越是稳定。但是带来的成本和数据传输要求也越高,一般都是根据业务量级和业务重要程度进行取舍。
总结
以上就是到家履约系统在数据异构方面的实践,我们从业务背景出发,分析了底层存储以及面临的写入复杂度问题。最终实践了Canal的数据异构,在实践中,我们主要得出以下3个经验教训,希望对大家有所帮助!
数据异构的链路、监控、报警尤其重要,有必要在第一期引入,及时发现问题,及时解决。否则,带来的损失将是非常巨大的。
如果无法穷举所有可能的错误情况,有必要冗余一条写入链路用来降级存储,这样可以及时的降级到可用的备用方案上
冗余机器+状态监测 = 高可用。单台机器部署,不是高可用,不要为了节约成本选择单台部署多个实例。
以上是关于京东到家多数据源同步的架构设计与实践的主要内容,如果未能解决你的问题,请参考以下文章