高级数据结构 ---- 跳跃表(Skip List)
Posted whc__
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高级数据结构 ---- 跳跃表(Skip List)相关的知识,希望对你有一定的参考价值。
1.1 什么是跳表?
跳表是一个随机化的数据结构,实际就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
(不仅提高了搜索性能,也提高了插入和删除操作的性能)
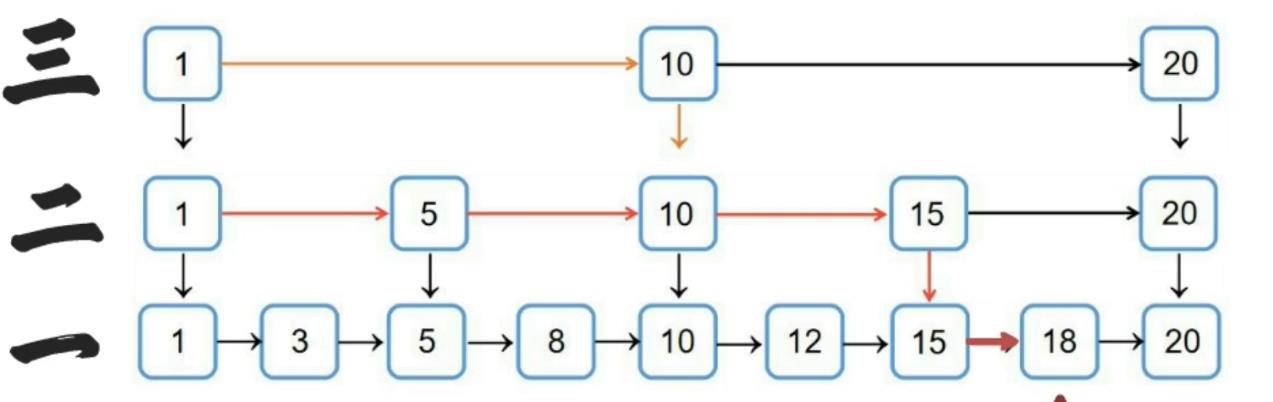
数据结构中的跳跃表
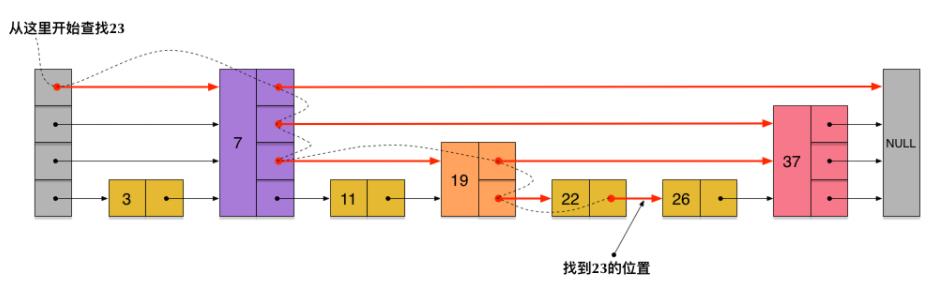
Redis中的跳跃表
1.2 跳跃表的性质
1.2.1 基本性质
- 跳跃表的每一层都是一条有序的链表
- 跳跃表的查询次数近似于层数,时间复杂度为O(logn)、插入、删除也为O(logn)
- 最底层的链表包含所有元素
- 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数),这样做的目的是为了保证平衡,不会出现两个索引之间存在大量数据
- 跳跃表的空间复杂度为O(n)
1.2.1 索引层的随机提拔
跳表的设计者采用了一种有趣的办法:抛硬币。也就是随机决定新节点是否提拔,每向上提拔一层的几率是50%。因为跳跃表的删除和添加节点是不可预测的,很难用一种有效的算法来保证跳表的索引分布始终均匀。这种方法虽然不能保证索引绝对均匀分布。但是可以让大体趋于平均。
1.3 跳跃表与其它结构相比
-
跳跃表 VS 二叉搜索树
二叉搜索树插入、删除、查找平均时间复杂度也为O(logn),但是在最坏情况下,二叉搜索树退化成链表,时间复杂度变为O(n);
另外,跳跃表更适合作为
范围查找,只需要找到最小值即可,然后顺序遍历若干步就可以了;而平衡树的查找需要通过中序遍历顺序查找并不容易实现。 -
跳跃表 VS 红黑树
红黑树插入、删除、查找平均时间复杂度也为O(logn),但是红黑树的插入、删除结点时,是通过调整结构来保持红黑树的平衡,比起跳跃表直接通过一个随机数来决定跨越几层,在时间复杂度的花销上是要高于跳跃表的
-
跳跃表 VS B+树
B+树实现上更复杂,维持结构平衡的成本高,更适合磁盘的索引。
跳跃表比较适合内存查找。
1.4 使用场景
-
Redis使用跳跃表作为有序集合键的底层实现之一
条件: 如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合的底层实现。(由ziplist压缩列表编码转化为skiplist跳跃表编码) 使用skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
1.5 Redis中的跳跃表
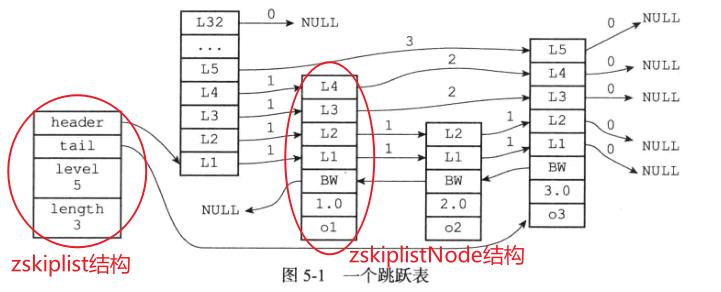
Redis跳跃表实现由 zskiplist 和 zskiplistNode 两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头结点、表尾结点、长度),而zskiplistNode则用于表示跳跃表结点
-
zskiplist结构-
header:指向跳跃表的表头节点
-
tail: 指向跳跃表的表尾节点
-
level: 记录目前跳跃表内,层数最大的那个节点的层数(表头节点不计算在内)
-
length: 记录跳跃表的长度,即跳跃表目前包含节点的数量(表头节点不计算在内)
-
-
zskiplistNode结构-
层(level):节点中用L1、L2、L3等字样标记节点的各个层
-
后退(backward)指针: 节点中用BW字样标记节点的后退指针
-
分值(score): 各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列
-
成员对象(obj):各个节点中的o1、o2、o3是节点所保存的成员对象
如果分值相同的情况下,节点按照成员对象的从小到大进行排序,大的对象在后面(靠近表尾的方向)。
-
以上是关于高级数据结构 ---- 跳跃表(Skip List)的主要内容,如果未能解决你的问题,请参考以下文章