shell的sort排序uniq重复行整理tr对字符集替换压缩删除
Posted 他和晚风一样温柔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell的sort排序uniq重复行整理tr对字符集替换压缩删除相关的知识,希望对你有一定的参考价值。
sort命令
定义:以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
sort [选项] 参数
cat file | sort 选项
常用选项:
- -f:忽略大小写,会将小写字母都转换为大写字母来进行比较
- -b:忽略每行前面的空格
- -n:按照数字进行排序
- -r:反向排序
- -u:等同于uniq,表示相同的数据仅显示一行
- -t:指定字段分隔符,默认使用[Tab]键分隔
- -k:指定排序字段
- -o<输出文件>:将排序后的结果转存至指定文件
例如:
sort -n testfile2
sort -t ':' -k 3 -n /etc/passwd
du -a | sort -nr -o du.txt
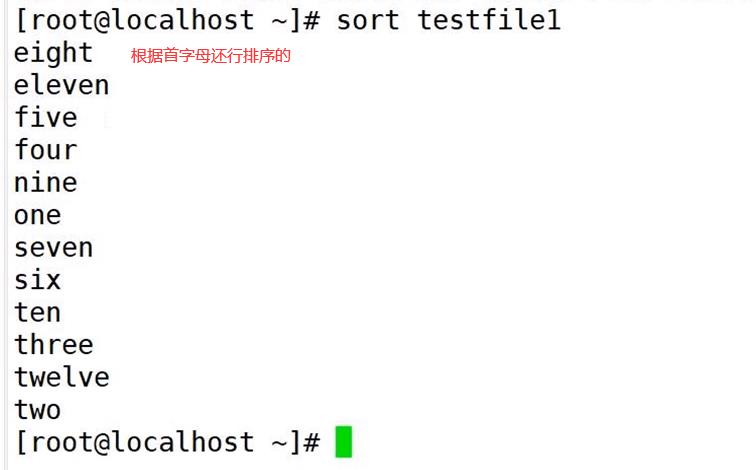
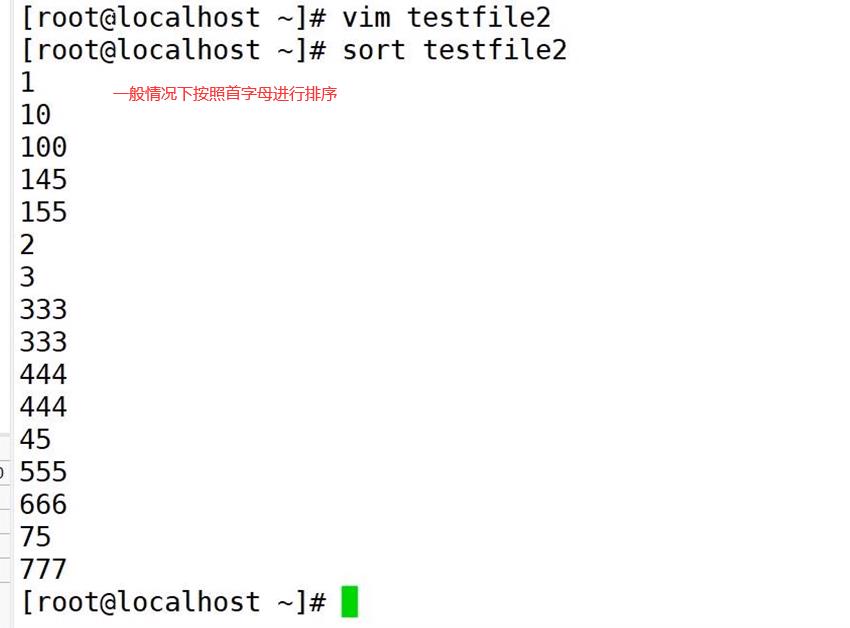
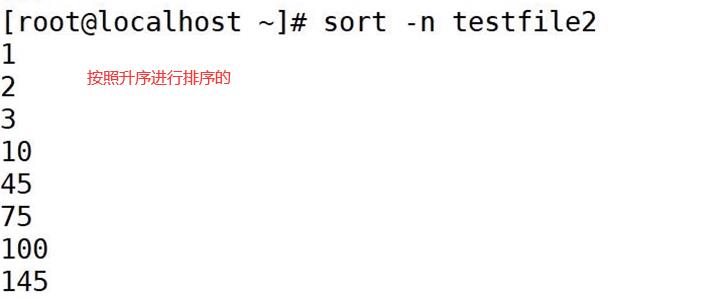
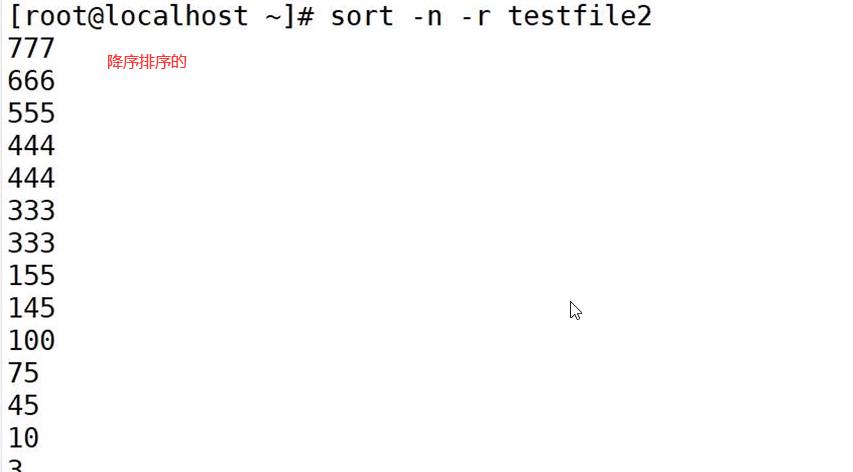
uniq命令
定义:用于报告或者忽略文件中连续的重复行,常与sort命令结合使用
语法格式:
uniq [选项] 参数
cat file | uniq 选项
常用选项
- -c:进行计数,并删除文件中重复出现的行
- -d:仅显示连续的重复行
- -u:仅显示出现一次的行
例如:
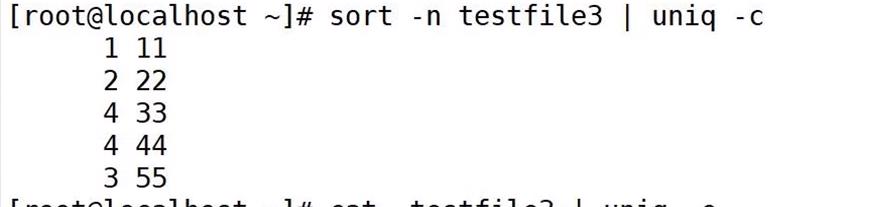
uniq testfile3
sort -n testfile3 | uniq -c


tr命令
定义:常用来对来自标准输入的字符进行替换、压缩和删除
语法格式:
tr [选项] [参数]
常用选项
- -c:保留字符集1的字符,其他的字符(包括换行符\\n)用字符集2替换
- -d:删除所有属于字符集1的字符
- -s:将重复出现的字符串压缩为一个字符串;用字符集2替换字符集1
- -t:字符集2替换字符集1,不加选项同结果。
参数:
- 字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数"字符集2"指定转换的目标字符集。但执行删除操作时,不需要参数"字符集2”
- 字符集2:指定要转换成的目标字符集。
示例;
echo "abc" | tr 'a-z' 'A-Z'
echo -e "abc\\ncabcdab" | tr -c "ab\\n" "O"
echo -e "abc\\ncabcdab" | tr -c "ab" "O"
echo 'hello world' | tr -d 'od'
echo "thissss is a text linnnnnnne." | tr -s 'sn'
删除空行
echo -e "aa\\n\\n\\n\\n\\nbb" | tr -s "\\n"
cat testfile5 | tr -s " \\n"
如图
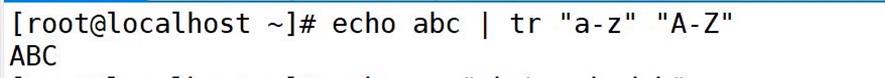


删除空行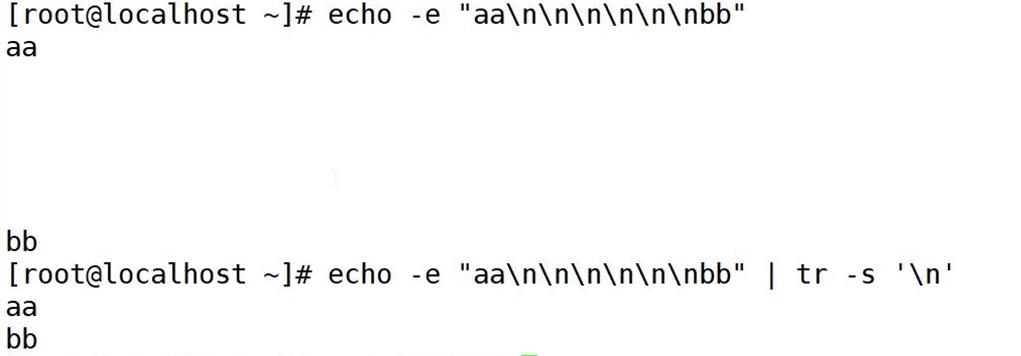
把路径变量中的冒号": “,替换成换行符”\\n"
echo $PATH l tr -s " :" " \\n"
echo -e "aa\\n \\n\\n\\n \\nbb" | tr -s "\\n" ":"
删除windows文件"造成”的’^M’字符:
cat abc.txt | tr -s " \\r" "\\n" > new_file或cat abc.txt | tr -d " lr" >new_file
Linux中遇到换行符("\\n")会进行回车+换行的操作,回车符反而只会作为控制字符("“N”)显示,不发生回车的操作。而windows中要回车符+换行符("’\\r\\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。


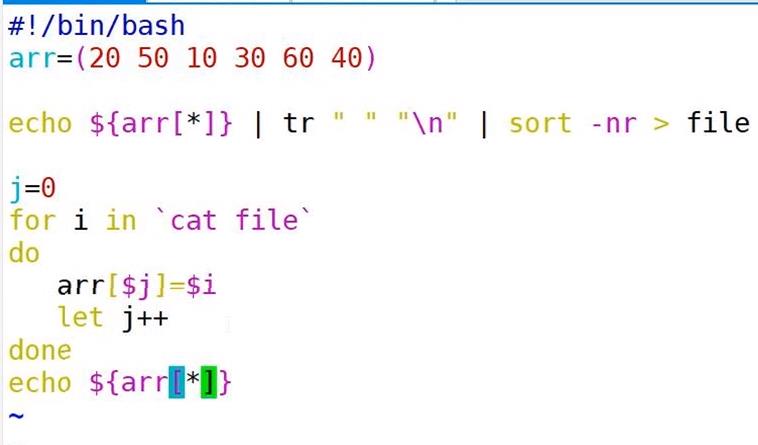
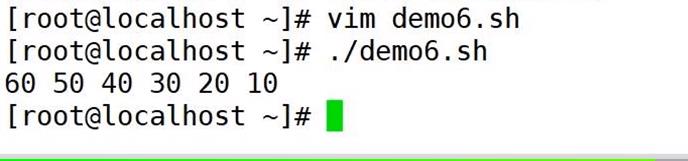
数组排序
echo ${array[* ] } | tr ' ' 'ln' | sort -n > file
a=0
for i in $ (cat file)
do
array[$a]-$i
let a++
#array+=($i)
done
cut命令
定义:显示行中的指定部分,删除文件中指定字段
语法格式:
cut 选项 参数
cat file | cut 选项
常用选项
- -f :通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符。
- -d : "TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符。
- –complement : 此选项用于排除所指定的字段。
- –output-delimiter :更改输出内容的分隔符。
cut -d ' : ' -f 1 /etc/passwd
grep '/bin/bash' /etc/passwd | cut -d ':'-f 1-4,6,7 #以-分隔的开始字段和结束字段指定字段的范围
grep '/bin/bash'/etc/passwd | cut -d ':' ' --complement -f 2 #排除第二个字段
cut -d ':'-f1,7 --output-delimiter=' ' /etc/passwd #输出分隔符使用空格分隔
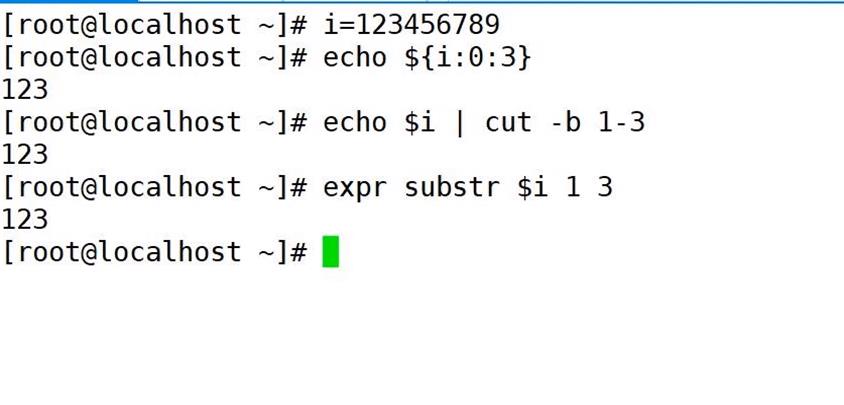
i=123456789
echo $i | cut -b 1-3 #起始位置从1开始
123
echo ${i:0:3} #起始位置从0开始
expr substr $i 1 3 #起始位置从1开始
以上是关于shell的sort排序uniq重复行整理tr对字符集替换压缩删除的主要内容,如果未能解决你的问题,请参考以下文章