图像隐藏基于LDPC编码译码改进DCT变换算法实现水印嵌入提取matlab源码
Posted Matlab走起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像隐藏基于LDPC编码译码改进DCT变换算法实现水印嵌入提取matlab源码相关的知识,希望对你有一定的参考价值。
一、LDPC码简介
低密度校验码(LDPC码)是一种前向纠错码,LDPC码最早在20世纪60年代由Gallager在他的博士论文中提出,但限于当时的技术条件,缺乏可行的译码算法,此后的35年间基本上被人们忽略,其间由Tanner在1981年推广了LDPC码并给出了LDPC码的图表示,即后来所称的Tanner图。1993年Berrou等人发现了Turbo码,在此基础上,1995年前后MacKay和Neal等人对LDPC码重新进行了研究,提出了可行的译码算法,从而进一步发现了LDPC码所具有的良好性能,迅速引起强烈反响和极大关注。经过十几年来的研究和发展,研究人员在各方面都取得了突破性的进展,LDPC码的相关技术也日趋成熟,甚至已经开始有了商业化的应用成果,并进入了无线通信等相关领域的标准。
1.1.1 LDPC码的特点
LDPC码是一种分组码,其校验矩阵只含有很少量非零元素。正是校验矩阵的这种稀疏性,保证了译码复杂度和最小码距都只随码长呈现线性增加。除了校验矩阵是稀疏矩阵外,码本身与任何其它的分组码并无二致。其实如果现有的分组码可以被稀疏矩阵所表达,那么用于码的迭代译码算法也可以成功的移植到它身上。然而,一般来说,为现有的分组码找到一个稀疏矩阵并不实际。不同的是,码的设计是以构造一个校验矩阵开始的,然后才通过它确定一个生成矩阵进行后续编码。而LDPC的编码就是本文所要讨论的主体内容。
译码方法是LDPC码与经典的分组码之间的最大区别。经典的分组码一般是用ML类的译码算法进行译码的,所以它们一般码长较小,并通过代数设计以减低译码工作的复杂度。但是LDPC码码长较长,并通过其校验矩阵H的图像表达而进行迭代译码,所以它的设计以校验矩阵的特性为核心考虑之一。
1.1.2 LDPC码的构造
构造二进制LDPC码实际上就是要找到一个稀疏矩阵H作为码的校验矩阵,基本方法是将一个全零矩阵的一小部分元素替换成1,使得替换后的矩阵各行和各列具有所要求的数目的非零元素。如果要使构造出的码可用,则必须满足几个条件,分别是无短环,无低码重码字,码间最小距离要尽可能大。
1.1.3 Tanner图
LDPC码常常通过图来表示,而Tanner图所表示的其实是LDPC码的校验矩阵。Tanner图包含两类顶点:n个码字比特顶点(称为比特节点),分别与校验矩阵的各列相对应和m个校验方程顶点(称为校验节点),分别与校验矩阵的各行对应。校验矩阵的每行代表一个校验方程,每列代表一个码字比特。所以,如果一个码字比特包含在相应的校验方程中,那么就用一条连线将所涉及的比特节点和校验节点连起来,所以Tanner图中的连线数与校验矩阵中的1的个数相同。以下图是矩阵
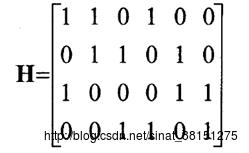
的Tanner图,其中比特节点用圆形节点表示,校验节点用方形节点表示,加黑线显示的是一个6循环:
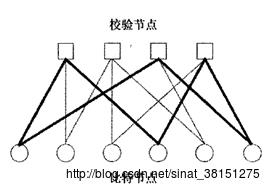
Tanner图中的循环是由图中的一群相互连接在一起的顶点所组成的,循环以这群顶点中的一个同时作为起点和终点,且只经过每个顶点一次。循环的长度定义为它所包含的连线的数量,而图形的围长,也可叫做图形的尺寸,定义为图中最小的循环长度。如上图中,图形的尺寸,即围长为6,如加黑线所示。
1.2 LDPC编码
方法一:设H=[A | B],对H进行高斯消元可得到H=[I| P],设编码完成的码字为u=[c| s],其中c为监督位,s为信息位。因为H*u' = u*H' = 0,可以得到I*c' + P*s' = 0 即 I*c' = P*s' (在GF(2)上),从而可求 c' = P*s'。如果高斯消元过程中进行了列交换,则只需记录列交换,并以相反次序对编码后的码字同样进行列交换即可。解码时先求出u,再进行列交换得到u1=[c| s],后面部分即是想要的信息。
方法一示例:

方法二:首先推导出根据校验矩阵直接编码的等式。将尺寸为m*n校验矩阵H写成如下形式:H=[H1 | H2],其中H1矩阵的大小为m*k,H2的大小为m*m,设编码完成的码字为u=[s | p],s为信息位,p为监督位。因为H*u' =u*H' = 0求得p*H2'=s*H1',最后得p=s* H1'* (H2')-

上述两种方法可以不通过生成矩阵而直接由校验矩阵进行编码的等式,一切只依赖校验矩阵的编码都是通过这两个式子实现的。但方法二要考虑H2是否满秩(可逆)。
1.3 LDPC码H矩阵的构造
规则的LDPC码和非规则的LDPC码
如果校验矩阵中各行非零元素的个数相同,各列中非零元素的个数也相同,这样的LDPC码称为规则码,与规则码对照,如果校验矩阵的各行中非零元素的个数不同或各列中非零元素个数不同,此时的LDPC码称为非规则的LDPC码。
1.3.1 非规则的LDPC码
构造方法:码率R=M/N=0.5,构造的H矩阵列重固定,而行重是随机的。下面通过一个大小为6*12,列重为2的H矩阵来说明。因为列重固定为2,所以其列坐标集合为[1,1,2,2,3,3,4,4…….12,12],而行坐标可以随机构造。

1. 先构造一个6*12,每一列为1到6随机排列的矩阵onesInCol。
2. 选取onesInCol的前2行(和列重一致),如上图所示。
3. 将所选取的矩阵按列依次排列如下

4. 构造矩阵tmp

5. 矩阵tmp重排成c1

6. full 把稀疏矩阵转换为满阵显示, sparse 创建稀疏矩阵生成M*N阶稀疏矩阵H在以向量r1和c1为坐标的位置上的对应元素值为向量1的对应值。


1.3.2 规则的LDPC 码
对于码率R=0.5的规则的LDPC码其行重与列重有关,行重是列重的2倍。以6*12的H矩阵为例,假设其列重为2,每列1的个数为2,总的1的个数为2*12=24,H矩阵有6行,行重相同则每行1的个数为24/6=4,即行重为4。假设其列重为3,其行重为6。
构造方法:与构造行重类似,行重列重固定之后,其在矩阵中的位置坐标集合固定,如列重为2,行重为4,列坐标集合为[1,1,2,2,3,3,…..],行坐标集合为[1,1,1,1,2,2,2,2,3,3,3,3,……],下面考虑的就是如何将行列坐标组合起来而不重复。这里采用的是保持行坐标集合不变,列坐标集合打乱重排。以构造大小5*10,列重为2,行重为4的H矩阵为例说明。

1. 先构造一个5*10,每一列为1到5随机排列的矩阵onesInCol。
2. 选取onesInCol的前2行(和列重一致)构成1*20的矩阵
3. 将r按升序排列得到

4. 记录下排列前的位置索引

5. 因为列坐标集合为[1,1,2,2,3,3,4,4,……9,9,10,10],将列坐标集合根据上面的位置索引重新排列,得到c

6. 行坐标集合如下,与列坐标一一对应,确定矩阵H中1的位置。

7. 最后结果

1.3.3 LDPC码的环
在 LDPC 码的 Tanner 图中,从一个顶点出发,经过不同顶点后回到同一个顶点的一些“边”组成的回路称为“环”。经过的边的个数称为环的长度。所有环中周长最小的环称为 LDPC码的围长(girth) 。
Tanner 图中的环不可避免的会对译码结果造成非常大的干扰。由于迭代概率译码会使信息在节点间交互传递,若存在环,从环的某一个节点出发的信息会沿着环上的节点不断传递并最终重新回到这个节点本身,从而使得节点自身信息不断累加,进而使得译码的最终结果失败的概率变大。显然,环长越小,信息传递回本身所需走的路径就越短,译码失败的概率就变得越高。Tanner 图形成一个环至少需要 4 个节点组成4 条相连的边,即环长最小为4,这类短环对码字的译码结果干扰最大。定义 LDPC码的行列(RC)约束为:两行或两列中不存在元素 1 的位置有 1 个以上相同的情况。显然,满足 RC 约束的 LDPC 码最低就是 6 环,去除了4 环的干扰。由于4环的检测以及避免最为简单并且必要,因此绝大部分构造方法都会满足 RC 约束。而构造大圈长的码字则需要精确的设计。
1.4 LDPC译码
Gallager 在描述 LDPC 码的时候,分别提出了硬判决译码算法和软判决译码算法两种。经过不断发展,如今的硬判决算法已在 Gallager 算法基础上进展很多,包含许多种加权比特翻转译码算法及其改进形式。硬判决和软判决各有优劣,可以适用于不同的应用场合。
1.4.1 比特翻转算法(BF)
硬判决译码算法最早是 Gallager 在提出 LDPC 码软判决算法时的一种补充。硬判决译码的基本假设是当校验方程不成立时,说明此时必定有比特位发生了错误,而所有可能发生错误的比特中不满足校验方程个数最多的比特发生错误的概率最大。在每次迭代时均翻转发生错误概率最大的比特并用更新之后的码字重新进行译码。具体步骤如下:
1. 设置初始迭代次数 k1及其上限kmax 。对获得的码字y=(y1,y2…yn)按照下式展开二元硬判决得到接收码字的硬判决序列Zn 。

2. 若k1=kmax ,则译码结束。不然,计算伴随式s=(s0,s1,…sm-1),sm表示第m个校验方程的值。若伴随式的值均为 0,说明码字正确,译码成功。否则说明有比特位错误。继续进行步骤3。
3. 对每个比特,统计其不符合校验方程的数量fn (1<=n<=N)

4. 将最大fn所对应的比特进行翻转,然后k=k+1,返回步骤2。
BF 算法的理论假设是若某个比特不满足校验方程的个数最多,则此比特是最有可能出错的比特,因此,选择这个比特进行翻转。BF 算法舍弃了每个比特位的可靠度信息,单纯的对码字进行硬判决,理论最为简单,实现起来最容易,但是性能也最差。当连续两次迭代翻转函数判断同一个比特位为最易出错的比特时,BF 算法会陷入死循环,大大降低了译码性能。
二、DCT变换
DCT变换的全称是离散余弦变换(Discrete Cosine Transform),离散余弦变换相当于一个长度大概是它两倍的离散傅里叶变换,这个离散傅里叶变换是对一个实偶函数进行的。通过数字信号处理的学习我们知道实函数的傅立叶变换获得的频谱大多是复数,而偶函数的傅立叶变换结果是实函数。以此为基础,使信号函数成为偶函数,去掉频谱函数的虚部,是余弦变换的特点之一。它可以将将一组光强数据转换成频率数据,以便得知强度变化的情形。若对高频的数据做些修饰,再转回原来形式的数据时,显然与原始数据有些差异,但是人类的眼睛却是不容易辨认出来。压缩时,将原始图像数据分成8*8数据单元矩阵,例如亮度值的第一个矩阵内。


2.DCT产生的工程背景:
视频信号的频谱线在0-6MHz范围内,而且1幅视频图像内包含的大多数为低频频谱线,只在占图像区域比例很低的图像边缘的视频信号中才含有高频的谱线。因此,在视频信号数字处理时,可根据频谱因素分配比特数:对包含信息量大的低频谱区域分配较多的比特数,对包含信息量低的高频 谱区域分配较少的比特数,而图像质量并没有可察觉的损伤,达到码率压缩的目的。然而,这一切要在低熵(Entropy)值的情况下,才能达到有效的编码。能否对一串数据进行有效的编码,取决于每个数据出现的概率。每个数据出现的概率差别大,就表明熵值低, 可以对该串数据进行高效编码。反之,出现的概率差别小,熵值高,则不能进行高效编码。视频信号的数字化是在规定的取样频率下由A/D转换器对视频电平转换而来的,每个像素的视频信号幅度随着每层的时间而周期性地变化。每个像素的平均信息量的总和为总平均信息量,即熵值。由于每个视频电平发生几乎具有相等的概率,所以视频信号的熵值很高。 熵值是一个定义码率压缩率的参数,视频图像的压缩率依赖于视频信号的熵值,在多数情况下视频信号为高熵值,要进行高效编码,就要将高熵值变为低熵值。怎样变成低熵值呢?这就需要分析视频频谱的特点。大多数情况下,视频频谱的幅度随着频率的升高而降低。其中 低频频谱在几乎相等的概率下获得0到最高的电平。与此相对照,高频频谱通常得到的是低电平及稀少的高电平。显然,低频频谱具有较高的熵值,高频频谱具有较低的熵值。据此,可对视频的低频分量和高频分量分别处理,获得高频的压缩值。
自从Ahmed和Rao于1974年给出了离散余弦变换(DCT)的定义以来,离散余弦变换(DCT)与改进型离散余弦变换(MDCT)就成为广泛应用于信号处理和图像处理特别是用于图像压缩和语音压缩编解码的重要工具和技术,一直是国际学术界和高科技产业界的研究热点。现在的很多图像和视频编码标准(如MPEG-1 , MEPG-2 ,MEPG-4中的第二部分)都要求实现整数的8×8 的DCT和IDCT,而MDCT 和IMDCT 则主要被应用于音频信号的编解码中(如MPEG-1 ,MEPG-2 和AC-]等标准的音频编码部分)。正是由于这类变换被广泛采用,对于这类变换的快速算法的研究才显得尤为重要。特别是针对特定的应用条件下的快速算法的研究对于提高整个系统的性能表现有很大帮助。
由上面的引用可见,码率压缩基于变换编码和熵值编码两种算法。前者用于降低熵值,后者将数据变为可降低比特数的有效编码方式。在MPEG标准中,变换编码采用的是DCT,变换过程本身虽然并不产生码率压缩作用,但是变换后的频率系数却非常有利于码率压缩。 实际上压缩数字视频信号的整个过程分为块取样、DCT、量化、编码4个主要过程进行-----首先在时间域将原始图像分成N(水平)×N(垂直)取样块,根据需要可选择4×4、4×8、8×8、8×16、16×16等块,这些取样的像素块代表了原图像帧各像素的灰度值,其范围在139-163之间,并依序送入DCT编码器,以便将取样块由时间域转换为频率域的DCT系数块。DCT系统的转换分别在每个取样块中进行,这些块中每个取样是数字化后的值,表示一场中对应像素的视频信号幅度值
3.离散余弦变换的实现:
实现DCT的方法很多,最直接的是根据DCT的定义来计算。以二维8xSDCT为例,需要作4096次乘法和3584次加法。这种算法的实现需要巨大的计算量,不具有实用价值。在应用中,需要寻找快速而又精确的算法。较为常用的方法是利用DCT的可拆分特性,同样以二维8xSDCT为例,先进行8行一维DCT需要64xS次乘法和56xS次加法,再进行8列一维DCT要64xS次乘法和56xS次加法,共需要64x8xZ=1024次乘法和56x8xZ=896次加法,计算量大为减少。
除此之外,DCT还有很多公开的快速算法。快速算法主要是通过减少运算次数而减少运算时间,这对于设计快速的硬件系统非常有效。二维DCT的快速算法则一般采用行列分离DCT算法,即转换为两次一维变换,其间通过转置矩阵连接。最为经典和常用的快速算法是由Arai等人于1988年提出的AAN算法以及Loeffier等人于1989年提出的LLM算法。但是,由于行列分离DCT算法能够重复使用一维变换结构,因此在实际实现上,尤其在硬件上比二维直接计算算法更有优势。



完整代码或者代写添加QQ1575304183
以上是关于图像隐藏基于LDPC编码译码改进DCT变换算法实现水印嵌入提取matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
图像隐藏基于DCT(离散余弦变换)与SVD(奇异值分解)域实现自适应嵌入水印含攻击
图像隐藏基于DCT(离散余弦变换)与SVD(奇异值分解)域实现自适应嵌入水印含攻击
图像处理基于DWT+DCT+PBFO改进图像水印隐藏提取matlab源码含GUI