语音识别基于MFCC的GMM语音识别matlab源码
Posted Matlab走起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音识别基于MFCC的GMM语音识别matlab源码相关的知识,希望对你有一定的参考价值。
一、简介
MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。梅尔频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。主要用于语音数据特征提取和降低运算维度。例如:对于一帧有512维(采样点)数据,经过MFCC后可以提取出最重要的40维(一般而言)数据同时也达到了将维的目的。
MFCC一般会经过这么几个步骤:预加重,分帧,加窗,快速傅里叶变换(FFT),梅尔滤波器组,离散余弦变换(DCT).其中最重要的就是FFT和梅尔滤波器组,这两个进行了主要的将维操作。
1.预加重
将经采样后的数字语音信号s(n)通过一个高通滤波器(high pass filter):其中a一般取0.95左右。经过预加重后的信号为:
预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
2.分帧
为了方便对语音分析,可以将语音分成一个个小段,称之为:帧。先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
3.加窗
语音在长范围内是不停变动的,没有固定的特性无法做处理,所以将每一帧代入窗函数,窗外的值设定为0,其目的是消除各个帧两端可能会造成的信号不连续性。常用的窗函数有方窗、汉明窗和汉宁窗等,根据窗函数的频域特性,常采用汉明窗。
将每一帧乘以汉明窗,以增加帧左端和右端的连续性。假设分帧后的信号为S(n), n=0,1…,N-1, N为帧的大小,那么乘上汉明窗后 ,W(n)形式如下:
不同的a值会产生不同的汉明窗,一般情况下a取0.46.
4.快速傅里叶变换
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。设语音信号的DFT为:
式中x(n)为输入的语音信号,N表示傅里叶变换的点数。
这里需要先介绍下Nyquist频率,奈奎斯特频率(Nyquist频率)是离散信号系统采样频率的一半,因哈里·奈奎斯特(Harry Nyquist)或奈奎斯特-香农采样定理得名。采样定理指出,只要离散系统的奈奎斯特频率高于被采样信号的最高频率或带宽,就可以避免混叠现象。在语音系统中我通常采样率取16khz,而人发生的频率在300hz~3400hz之间,按照Nyquist频率的定义就有Nyquist频率等于8khz高于人发生的最高频率,满足Nyquist频率的限制条件。FFT就是根据Nyquist频率截取采样率的一半来计算,具体来说就是,假设一帧有512个采样点,傅里叶变换的点数也是512,经过FFT计算后输出的点数是257(N/2+1),其含义表示的是从0(Hz)到采样率/2(Hz)的N/2+1点频率的成分。也就是说在经过FFT计算时不仅把信号从时域转到了频域并且去除了高于被采样信号的最高频率的点的影响,同时也降低了维度。
5.梅尔滤波器组
由于人耳对不同频率的敏感程度不同,且成非线性关系,因此我们将频谱按人耳敏感程度分为多个Mel滤波器组,在Mel刻度范围内,各个滤波器的中心频率是相等间隔的线性分布,但在频率范围不是相等间隔的,这个是由于频率与Mel频率转换的公式形成的,公式如下:
式中的log是以log10为底,也就是lg。
将能量谱通过一组Mel尺度的三角形滤波器组,定义一个有M个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m),m=1,2,…,M。M通常取22-26。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图所示:
式中的k指经过FFT计算后的点的下标,也就是前面例子中的0~257,f(m)也对应点的下标,具体求法如下:
1.确定语音信号最低(一般是0hz)最高(一般是采样率的二分之一)频率以及Mel滤波器个数
2.计算对应最低最高频率的mel频率
3.计算相邻两个mel滤波器中心频率的距离:(最高mel频率-最低mel频率)/(滤波器个数+1)
4.将各个中心Mel频率转成频率
5.计算频率对应FFT中点的下标
例如:假设采样率为16khz,最低频率为0hz,滤波器个数为26,帧大小为512,则傅里叶变换点数也为512,那么带入Mel频率与实际频率的转换公式中得到最低Mel频率为0,最高Mel频率为2840.02.中心频率距离为:(2840.02-0)/(26+1)=105.19,这样我们就可以得到Mel滤波器组的中心频率:[0,105.19,210.38,…,2840.02],然后再将这组中心频率转成实际频率组(按公式操作即可,这里不列出来了),最后计算实际频率组对应FFT点的下标,计算公式为:实际频率组中的每个频率/采样率*(傅里叶变换点数 + 1)。这样就得到FFT点下标组:[0,2,4,7,10,13,16,…,256],也就是f(0),f(1),…,f(27)。
有了这些,我们在计算每个滤波器的输出,计算公式如下:
式中的M指滤波器的个数,N指FFT中的点数(上述的例子中是257)。经过上面的计算后每帧数据我们得到一个与滤波器个数相等的维数,降低了维数(本例中是26维)。
6.离散余弦变换
离散余弦变换经常用于信号处理和图像处理,用来对信号和图像进行有损数据压缩,这是由于离散余弦变换具有很强的"能量集中"特性:大多数的自然信号(包括声音和图像)的能量都集中在离散余弦变换后的低频部分,实际就是对每帧数据在进行一次将维。其公式如下:
将上述每个滤波器的对数能量带入离散余弦变换,求出L阶的Mel-scale Cepstrum参数。L阶指MFCC系数阶数,通常取12-16。这里M是三角滤波器个数。
7.动态差分参数的提取
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
式中,dt表示第t个一阶差分,Ct表示第t个倒谱系数,Q表示倒谱系数的阶数,K表示一阶导数的时间差,可取1或2。将上式的结果再代入就可以得到二阶差分的参数。
因此,MFCC的全部组成其实是由: N维MFCC参数(N/3 MFCC系数+ N/3 一阶差分参数+ N/3 二阶差分参数)+帧能量(此项可根据需求替换)。
这里的帧能量是指一帧的音量(即能量),也是语音的重要特征,而且非常容易计算。因此,通常再加上一帧的对数能量(定义:一帧内信号的平方和,再取以10为底的对数值,再乘以10)使得每一帧基本的语音特征就多了一维,包括一个对数能量和剩下的倒频谱参数。另外,解释下最开始说的40维是怎么回事,假设离散余弦变换的阶数取13,那么经过一阶二阶差分后就是39维了再加上帧能量总共就是40维,当然这个可以根据实际需要动态调整。
二、源代码
% ====== Load wave data and do feature extraction
clc,clear
waveDir='trainning\\';
speakerData = dir(waveDir);
%Matlab使用dir函数获得指定文件夹下的所有子文件夹和文件,并存放在在一种为文件结构体数组中.
% dir函数可以有调用方式
% dir('.') 列出当前目录下所有子文件夹和文件
% dir('G:\\Matlab') 列出指定目录下所有子文件夹和文件
% dir('*.m') 列出当前目录下符合正则表达式的文件夹和文件
% 得到的为结构体数组每个元素都是如下形式的结构体
% name -- filename
% date -- modification date
% bytes -- number of bytes allocated to the file
% isdir -- 1 if name is a directory and 0 if not
% datenum -- modification date as a MATLAB serial date number
% 分别为文件名,修改日期,大小,是否为目录,Matlab特定的修改日期
% 可以提取出文件名以作读取和保存用.
speakerData(1:2) = [];
speakerNum=length(speakerData);%speakerNum:人数;
% ====== Feature extraction
fprintf('\\n读取语音文件并进行特征提取... ');
% cd('D:\\MATLAB7\\toolbox\\dcpr\\');
for i=1:speakerNum
fprintf('\\n正在提取第%d个人%s的特征\\n', i, speakerData(i,1).name(1:end-4));
[y, fs, nbits]=wavread(['trainning\\' speakerData(i,1).name]);
epInSampleIndex = epdByVol(y, fs); % endpoint detection端点检测
y=y(epInSampleIndex(1):epInSampleIndex(2)); % silence is not used去除静音
speakerData(i).mfcc=wave2mfcc(y, fs);
fprintf(' 完成!!');
end
save speakerData speakerData; % Since feature extraction is slow, you can save the data for future use if the features are not changed.
graph_MFCC; %由于特征提取速度慢,如果功能没有改变,可以保存供日后使用的数据,
fprintf('\\n');
clear all;
fprintf('特征参数提取完成! \\n\\n请点击任意键继续...');
pause;
% ====== GMM training
fprintf('\\n训练每个语者的高斯混合模型...\\n\\n');
load speakerData.mat
gaussianNum=12; % No. of gaussians in a GMM高斯混合模型中的高斯个数
speakerNum=length(speakerData);
for i=1:speakerNum
fprintf('\\n为第%d个语者%s训练GMM……\\n', i,speakerData(i).name(1:end-4));
[speakerGmm(i).mu, speakerGmm(i).sigm,speakerGmm(i).c] = gmm_estimate(speakerData(i).mfcc,gaussianNum);
fprintf(' 完成!!');
end
fprintf('\\n');
save speakerGmm speakerGmm;
pause(10);
clear all;
fprintf('高斯混合模型训练结束! \\n\\n请点击任意键继续...');
pause;
% ====== recognition
fprintf('\\n识别中...\\n\\n');
load speakerData;
load speakerGmm;
[filename, pathname] = uigetfile('*.wav','select a wave file to load');
if pathname == 0
errordlg('ERROR! No file selected!');
return;
end
wav_file = [pathname filename];
[testing_data, fs, nbits]=wavread(wav_file);
pause(10);
match= MFCC_feature_compare(testing_data,speakerGmm);
disp('待测模型匹配中,请等待10秒!')
pause(10);
[max_1 index]=max(match);
if length(filename)>7
fprintf('\\n\\n\\n说话人是%s。',speakerData(index).name(1:end-4));
else
fprintf('\\n\\n\\n说话人是%s。',filename(1:end-4));
end三、运行结果
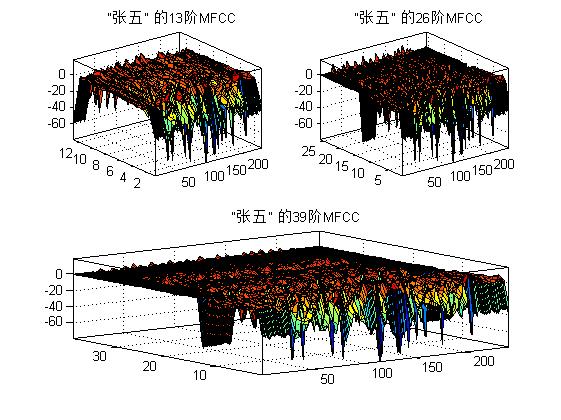
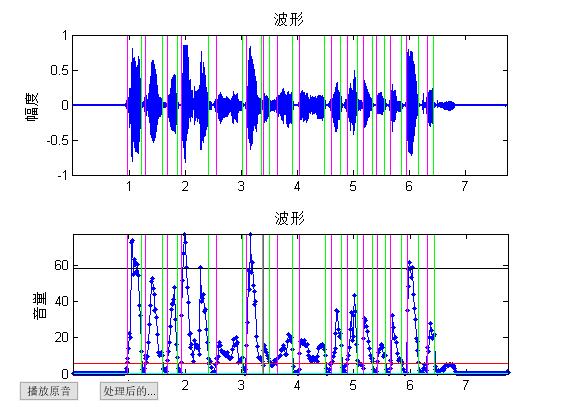
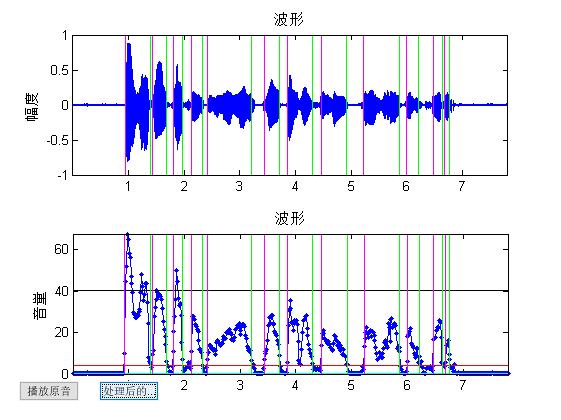
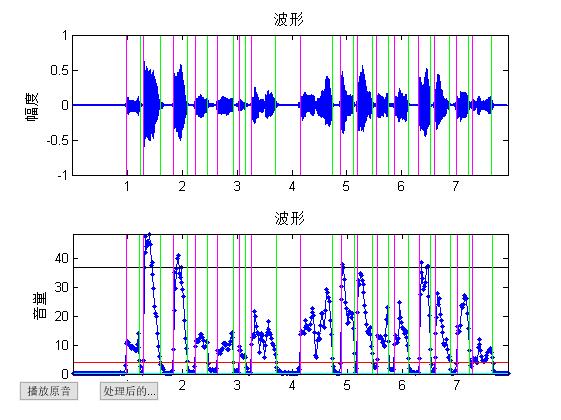
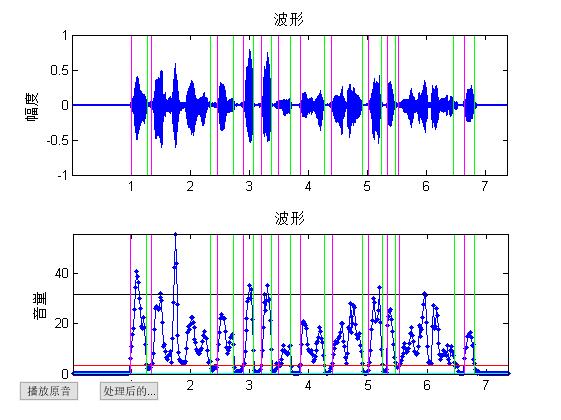
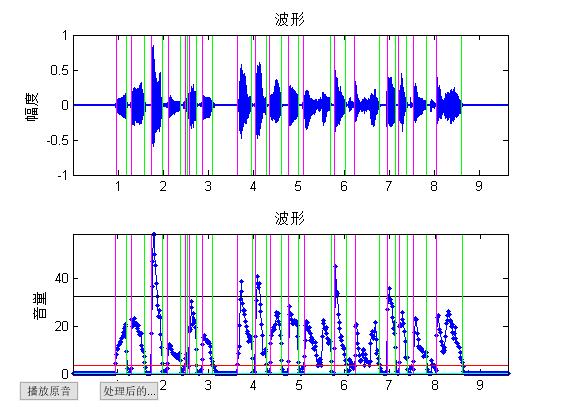
四、备注
完整代码或者代写添加QQ1575304183
以上是关于语音识别基于MFCC的GMM语音识别matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
语音识别基于高斯混合模型(GMM)的语音识别matlab源码
语音识别基于matlab GUI MFCC+VAD端点检测智能语音门禁系统含Matlab源码 451期