Vit: 图像识别上的Transformer
Posted 雨石记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vit: 图像识别上的Transformer相关的知识,希望对你有一定的参考价值。
Transformer出现以来,不但在NLP领域大放异彩,在CV领域也是跃跃欲试。
有很多的工作试图把Transformer引入到图像中去,比如尝试在CNN中引入self-attention,或者直接用transformer替换卷积块。后者限于没有底层的优化实现,理论上能高效但其实不能大规模。
本文介绍的Vit, Vision Transformer,将标准的Transformer直接应用到图像上进行处理。
Vit中比较重要的发现就是,在中等size的数据集上,比如ImageNet,Vit并不能超过CNN中的模型,比如ResNet。这点似乎说明了CNN中还是有些固有的特性可以让它归纳泛化的更好,比如图像的局部性,平移不变性等。但在更大的数据集上训练Vit,能解决这个问题。
模型结构
模型结构如下图,模型结构就是使用的标准的Transformer Encoder结构。但Transformer的输入是词语的1D embedding的序列,所以为了适应这个结构,对图像做了处理。即将HxWxC(高x宽x通道)大小的图像切成一系列PxP的2D块(patch),然后再将2D块展平,形成长度为N=HW/P^2的图像序列。
图像序列会先经过一个线性转换层做变换,变换后的结果被称为patch embedding。
得到patch embedding之后,就和位置embedding做加法,然后输入给Transformer Encoder。这里的位置信息使用的就是在序列里的位置信息,而不是patch在图像中的2D位置信息,因为实验表明2D位置信息并没有明显提升。
然后类似Bert,在序列的开始prepend了一个特殊token [class],然后这个位置上的输出被当做整个凸显的embedding,在之上又添加了一个MLP head用来做分类。
如上右图所示,Transformer Encoder有L个这样的模型结构块组成。可以看到,Multi-head attention和MLP轮番交替出现,在这两个结构之前都分别有一个LayerNorm,在LayerNorm之前有残差连接。
下图为具体的模型公式。
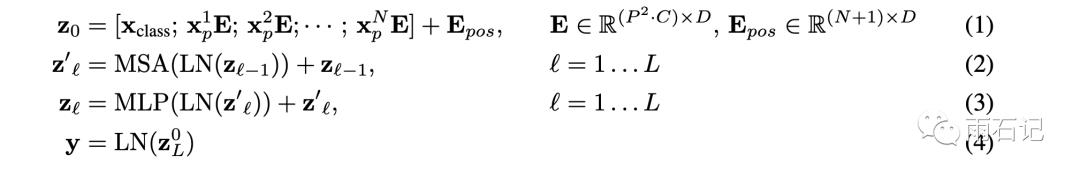
另外一种可选的结构是将原始的图像patch替换成CNN提取的feature。
微调
类似Bert,Vit在大规模数据上做预训练,然后在小数据集上做微调。一个常用的有用技巧是在微调的时候,可以用分辨率比预训练时高的图像,这样往往能达到更好的效果。
多提问,勤思考是每个合格工程师的必备技能。
Q: 如果微调时的图片size比预训练时的大,该怎么办?
以上是关于Vit: 图像识别上的Transformer的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch CIFAR10图像分类 Vision Transformer(ViT) 篇
Pytorch CIFAR10图像分类 Vision Transformer(ViT) 篇
20亿参数,大型视觉Transformer来了,刷新ImageNet Top1
vision_transformer实战总结:非常简单的VIT入门教程,一定不要错过