自动化运维必须要学的Shell脚本之——正则表达式的详解
Posted 码海小虾米_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动化运维必须要学的Shell脚本之——正则表达式的详解相关的知识,希望对你有一定的参考价值。
正则表达式
一、正则表达式
1.1 什么是正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。在Linux中也就是代表我们定义的模式模板,Linux工具可以用它来过滤文本。
Linux的工具(如sed编辑器或者gawk程序)能够在处理数据时使用正则表达式对数据进行模式匹配,如果数据符合匹配的要求,那么就会进入下一步处理;如果数据不符合匹配的要求,就会被过滤掉。

正则表达式模式利用通配符来描述数据流中的一个或多个字符,在我们学习Linux之前的很多场景中都可以使用通配符来秒速不确定的数据。
我们经常使用ls命令加通配符来完成对数据的简单查找,使用 “ * ” 通配符找出来 .txt结尾的文件,如下图所示:

但是 *.sh 结尾列出了所有txt文本文件,不管前面是数字还是字母,也不管有多少个,反正只要是txt结尾的文件就行了,正则表达式的工作原理和这个类似,但是正则表达式是功能更强大,不仅可以匹配数字和字母的区别,也可以对数字和字母的个数进行过滤。
1.2 基础正则常见元字符
1.2.1 正则表达式的组成
正则表达式是由普通字符与元字符组成:
- 普通字符包括大小写字母、数字、标点符号及一些其他符号。
- 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符( 即位于元字符前面的字符)在目标对象中的出现模式。
1.2.2 常见的元字符(支持的工具:grep、egrep、sed和awk)
-
\\ :转义字符,用于取消特殊符号的含义,例: \\!、 \\n、\\$等
-
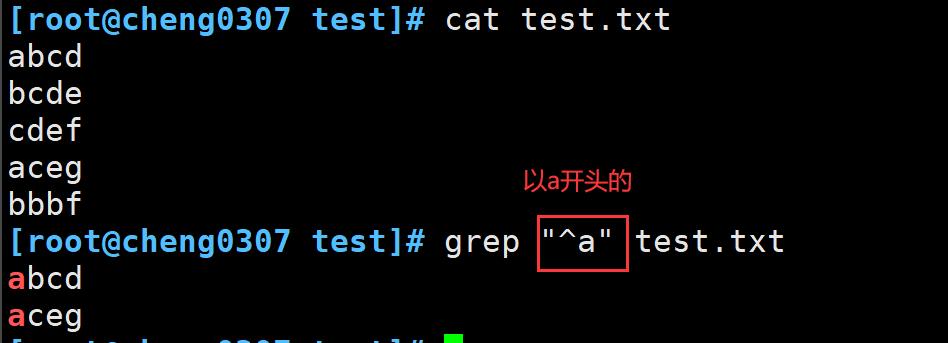
^ :匹配字符串开始的位置,例: ^a、^the、 ^#、^[a-z]
-
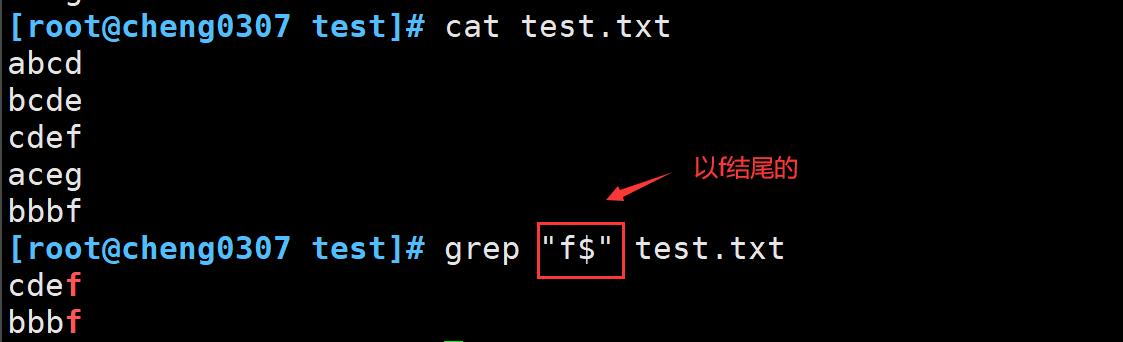
$ :匹配字符串结束的位置,例: word$、 ^$匹配空行
-
. :匹配除\\n之外的任意的一p个字符,例: go.d、 g…d

-
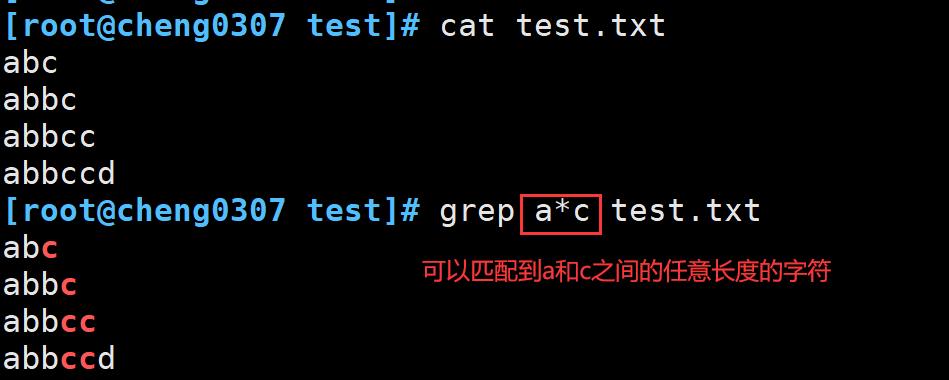
* :匹配前面子表达式0次或者多次,例: goo*d、 go. *d
-
[ list ] :匹配list列表中的一个字符,例: go[ola]d, [abc]、 [a-z]、 [a-z0-9]、 [0-9]匹配任意一位数字
-
[^list] :匹配任意非list列表中的一个字符,例: [^0-9]、 [^A- Z]、 [0-9]、 [^a-z]匹配任意一位非小写字母
-
\\{n\\} :匹配前面的子表达式n次,例: go\\{2\\}d、 '[0-9]\\{2\\} '匹配两位数字
-
\\{n,\\} :匹配前面的子表达式不少于n次,例: go\\{2,\\ }d、 '[0-9]\\{2, \\} '匹配两位及两位以上数字
-
{n,m} :匹配前面的子表达式n到m次,例: go{2,3}d、 '[0-9]{2,3} '匹配两位到三位数字
注: egrep、 awk使用{n}、{n,}、{n,m} 匹配时“{}"前不用加“\\”
1.2.3 扩展正则表达式元字符(支持的工具:egrep、awk)
POSIX ERE模式包括了一些可供Linux应用和工具使用的额外符号,gawk程序能够识别ERE模式,但是sed编辑器不能。
sed编辑器和gawk程序的正则表达式引擎之间是由区别的,gawk程序可以使用大多数扩展正则表达式模式符号,并且能提供一些额外的过滤功能,而这些功能都是sed编辑器所不具备的。但正因为如此,gawk程序处理数据流时才比较慢。
-
问号 ?
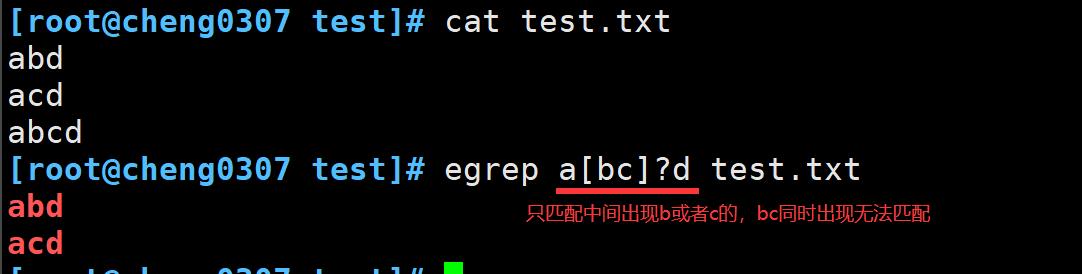
问号类似于星号,不过有点细微的不同,问号表示前面的字符可以出现0次或1次,仅限于此,不会匹配多次出现的字符。
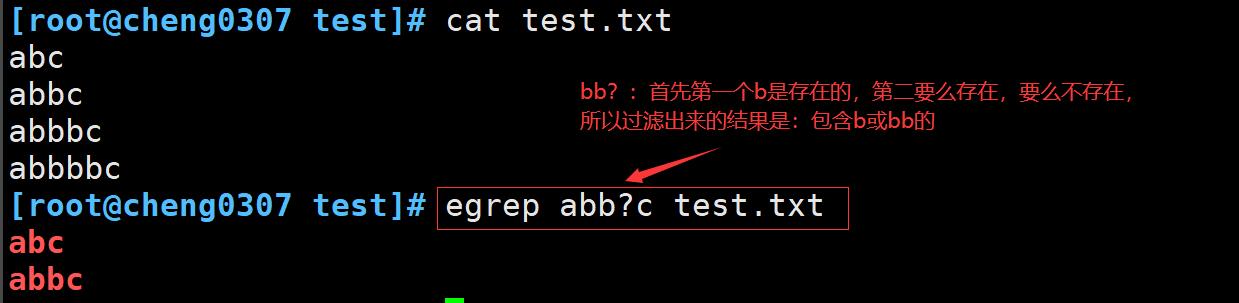
将问号结合字符组一起使用
如果字符组中的字符出现了0次或1次,匹配就会成立,但是如果两个字符都出现了,或者其中一个字符出现了2次,那么匹配都无法成立。案例如下:
-
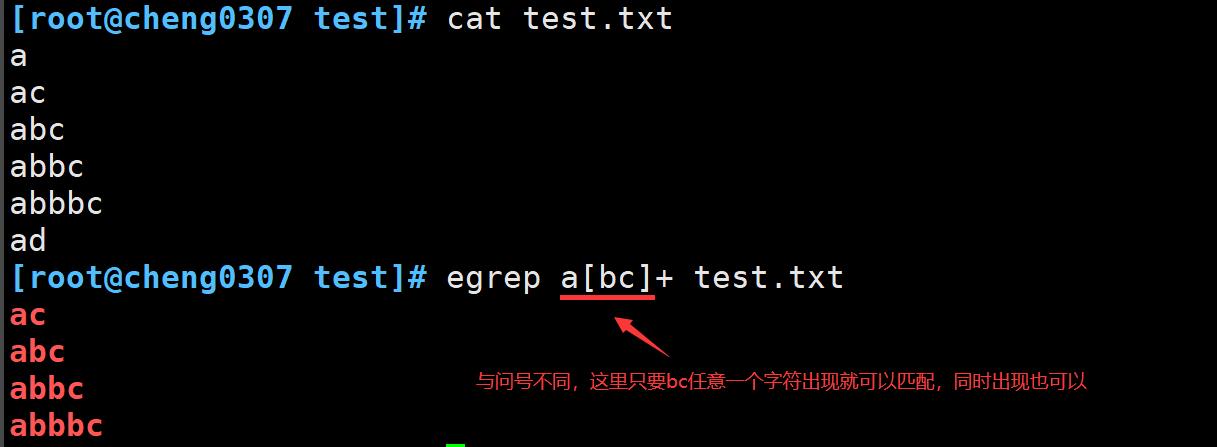
加号 +
加号是类似于星号的另一个模式符号,但跟问号也有所不同,加号表示前面的字符可以出现1次或者多次,但是必须出现1次,如果该字符没有出现,则无法匹配。

将加号结合字符组一起使用
如果字符组中定义的任一字符出现了,文本就会匹配,全部出现也可以匹配到。
-
管道符号 |
管道符号允许在检查数据流时,用逻辑OR(或)方式指定正则表达式要是用的模式,如果任意一个模式匹配了数据流文本,文本就通过,如果没有匹配到,那么数据则匹配失败。
使用管道符号的格式:expr1 | expr2 | expr1....
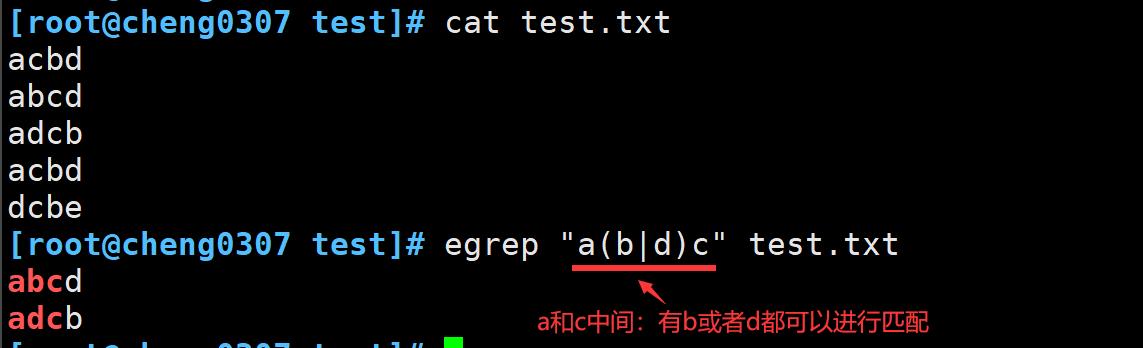
管道符号两侧的正则表达式可以采用任何正则表达式模式(包括字符组)来定义文本。

-
圆括号()
将括号中的字符串作为一个整体。正则表达式模式也可以使用圆括号进行分组,当我们将正则表达式模式分组时,该组会被视为一个标准字符,然后就可以像对普通字符一样给改组使用特殊字符了。
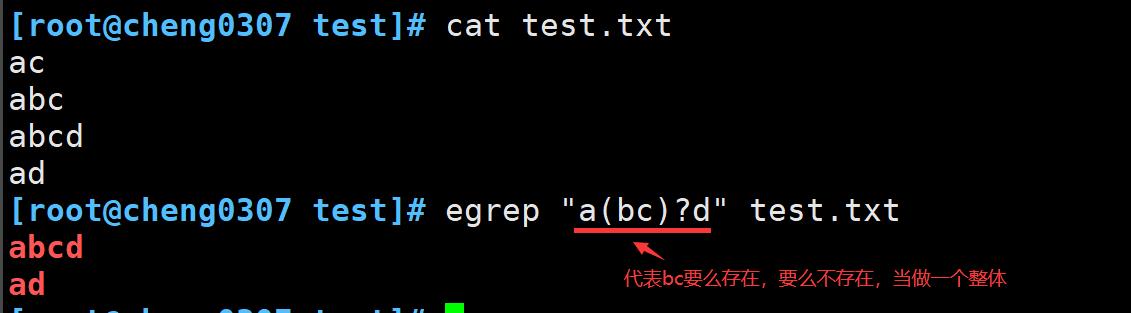
将字符组和管道符号一起使用
(a|b)b(c|d)会匹配第一组中字符的任意组合以及第二组中字符的任意组合。
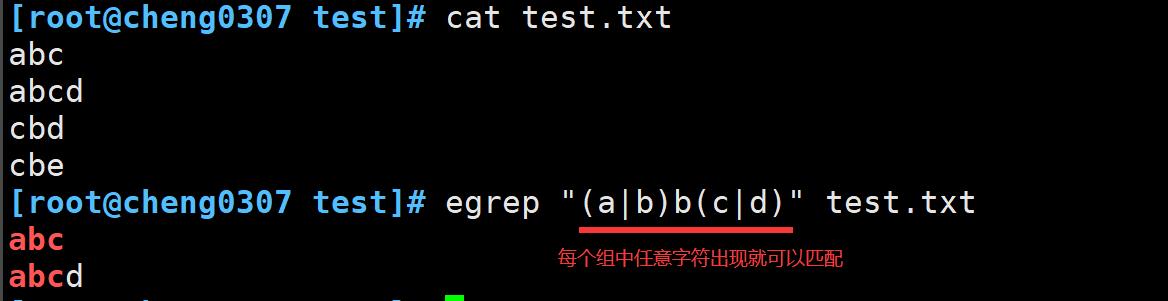
-
花括号 { }
花括号允许为可重复的正则表达式指定一个上限,这通常称为间隔(interval),可以用两种格式来指定区间。
- m:正则表达式准确出现的次数m;
- m,n:正则表达式至少出现m次,最多n次。
这个特性可以精确的调整字符或者字符集在模式中出现的具体次数。
默认情况下,gawk程序不会识别正则表达式间隔,必须指定gawk程序的- -interval命令行选项才能识别正则表达式的间隔。
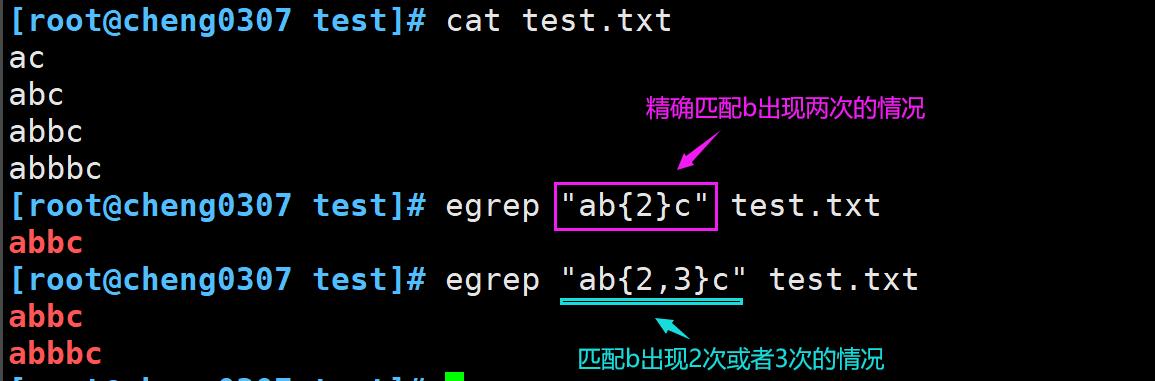
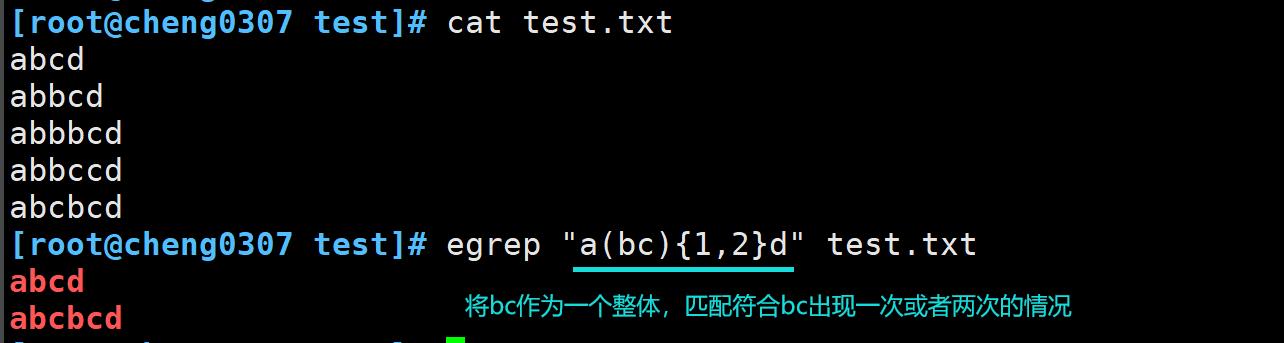
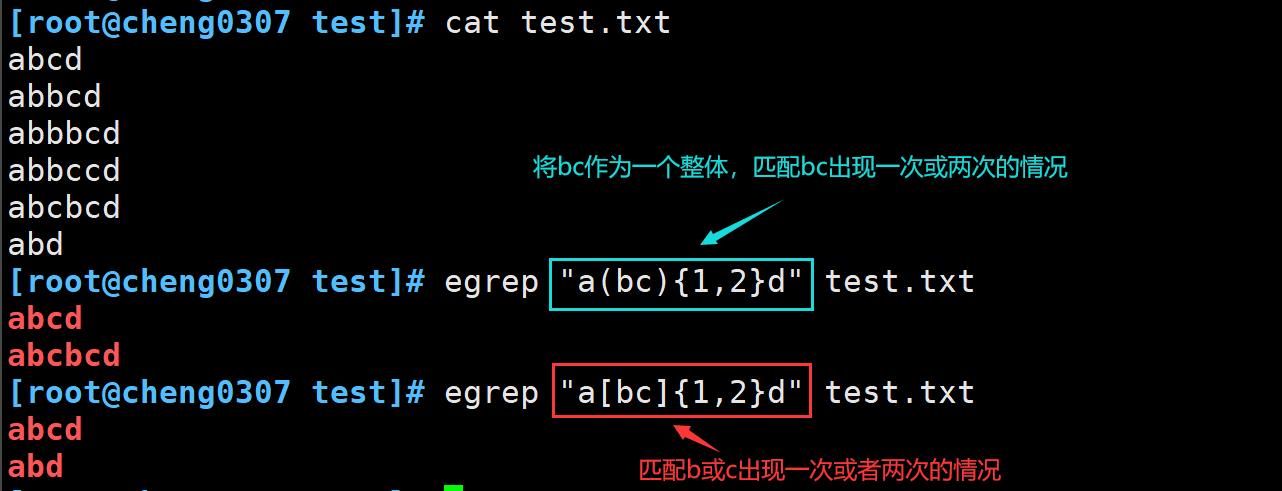
将间隔模式结合分组和字符组一起使用
以上是关于自动化运维必须要学的Shell脚本之——正则表达式的详解的主要内容,如果未能解决你的问题,请参考以下文章
自动化运维必须要学的Shell文本处理三剑客之——grep的高级选项
自动化运维必须要学的Shell脚本之——编程规范和变量详细解读
自动化运维必须要学的Shell脚本之——免交互操作,分分钟解放双手!