Pytorch学习----数据模块(数据集导入;DataLoader数据读取机制;transforms图像预处理模块)
Posted 小葵花幼儿园园长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch学习----数据模块(数据集导入;DataLoader数据读取机制;transforms图像预处理模块)相关的知识,希望对你有一定的参考价值。
载入数据集
载入CIFAR10数据集
- 导入各种模块
#encoding=utf-8
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
- 定义数据类型
-
ImageFolder()— 将要训练的数据放在一个路径为path的文件夹下,假如这个文件名为train。在我们的train文件夹下有N个子文件,每个子文件夹代表一个分类,一共N类。 -
transforms.Compose()— 把几个transform语句合并到一起 -
transform.Resize()— 可以传入两类参数。一类是(h,w)把图片缩放到(h,w)大小(长宽比会改变);另一类是(x),单个参数,把图片经过缩放后(保持长宽比不变),将最短的边缩放到传入的参数。- 这里图片大小的设置是根据网络架构来决定的。
-
transform.ToTenser()—数据类型的转换。转换为tenser
def loadtraindata():
path = r"/home/********/folder/train" # 路径
trainset = torchvision.datasets.ImageFolder(path,
transform=transforms.Compose([
transforms.Resize((32, 32)), # 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.CenterCrop(32),
transforms.ToTensor()])
)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
return trainloader
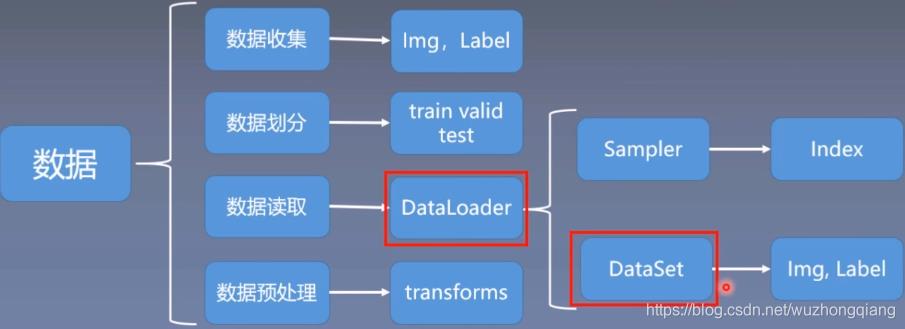
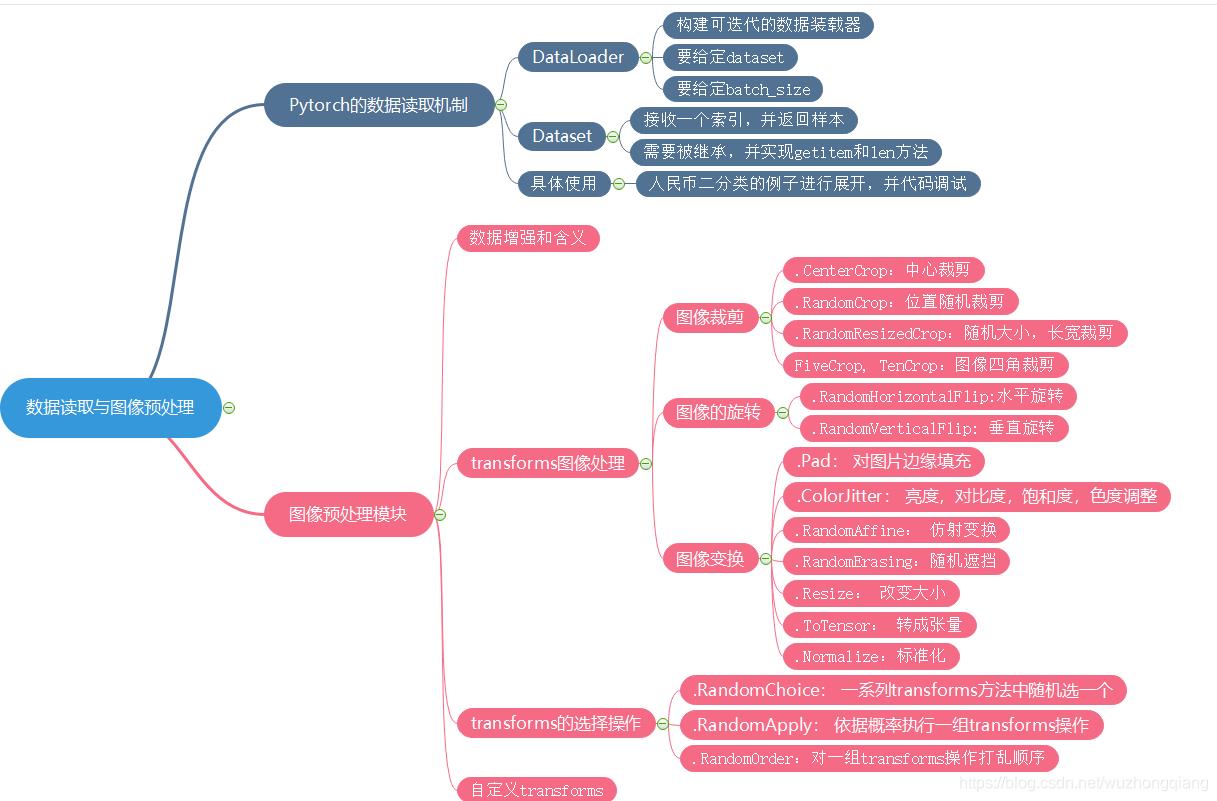
DataLoader
torch.utils.data.DataLoader():构建可迭代的数据装载器,在训练的时候,每一个for循环,每一个iteration,就是从DataLoader中获取一个batch_size大小的数据

DataLoader() 主要参数:
dataset: Dataset类,决定数据从哪读取以及如果读取batchsize: 批大小num_works: 是否多进程读取机制shuffle: 每一个epoch是否乱序drop_last: 当样本数不能被batchsize整除时,是否舍弃最后一批数据
要理解这个drop_last, 首先,得先理解Epoch, Iteration和Batchsize的概念:
Epoch: 所有训练样本都已输入到模型中,称为一个EpochIteration: 一批样本输入到模型中,称为一个IterationBatchsize: 批大小, 决定一个Epoch有多少个Iteration
Dataset
torch.utils.data.Dataset():Dataset的抽象类,所有自定义的Dataset都需要继承它,必须复写_getitem_() 这个方法.

__getitem__方法的是Dataset的核心,作用是接收一个索引, 返回一个样本, 看上面的函数,参数里面接收index,然后我们需要编写究竟如何根据这个索引去读取我们的数据部分。
参考
以上是关于Pytorch学习----数据模块(数据集导入;DataLoader数据读取机制;transforms图像预处理模块)的主要内容,如果未能解决你的问题,请参考以下文章