第二章:音频入门
Posted 想文艺一点的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二章:音频入门相关的知识,希望对你有一定的参考价值。
目录
一、音频基础知识
1、音频处理的流程
首先对于音频的处理是包括两个层面的:
- 直播客户端的处理流程(音频的采集、编码、解码、播放)
- 音频数据的流转 ( 采集后是什么格式?编码后又是什么格式)
(1)直播客户端的处理流程
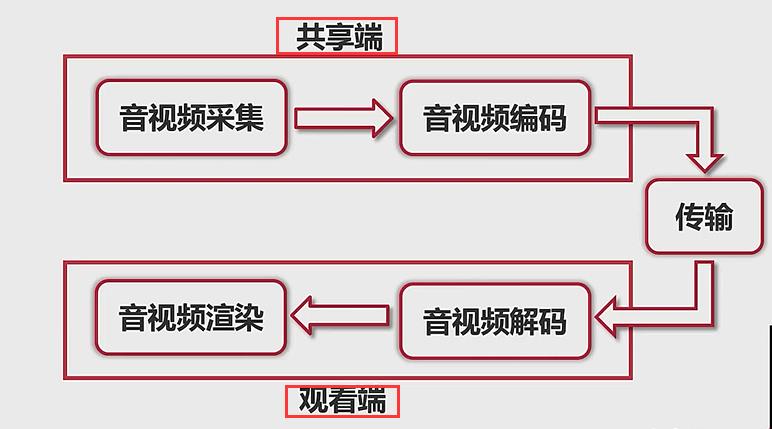
- 音视频采集:从麦克风上面抓取音频数据。
- 音视频编码:刚刚采集的数据量是非常大的,所以需要经过编码来将它进行压缩。
- 传输
- 音视频解码:我们不能直接将压缩后的数据直接丢给扬声器来进行播放。
- 音视频渲染:将解码器输出的数据交给对应的驱动,驱动再让硬件进行播放。 (音频:喇叭、视频:渲染器)
(2)音频数据的流转:


- PCM 数据:利用 audio_recoder 、video_recoder 这些API 采集来的数据就是 PCM 数据(后面有详细介绍)
- aac/mps :两个编码器,经过编码器之后就会生成对应编码格式的数据
- mp4/flv :给他套一层衣服,生成一个多媒体文件
2、声音是如何被听到的
(1)人耳是怎么听到声音的? 物体振动——> 介质传输 ——> 振动耳膜
- 必须有物体发生振动 (在真空中振动我们也是听不到的)
- 必须通过空气、固体、液体、等进行传输。
- 振动耳膜 (这个振动经过我们大脑的神经系统就会产生一个信号)
(2)我们来分析人耳怎么处理声音
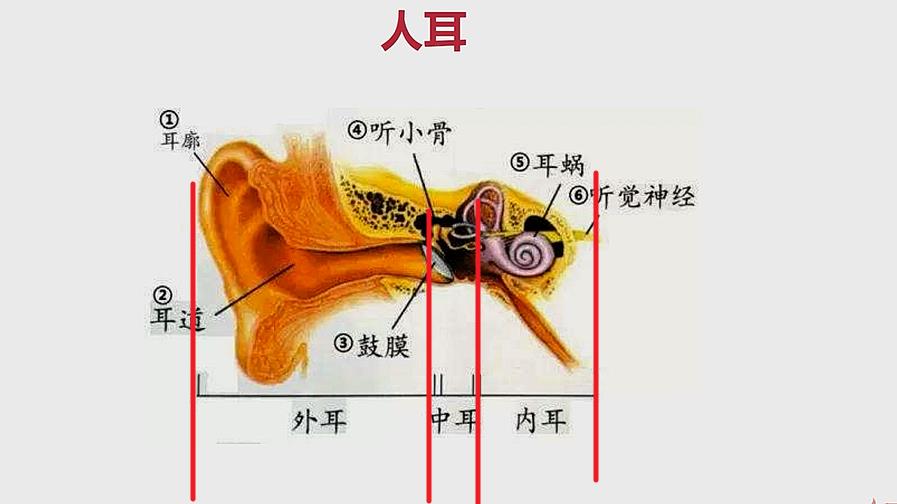
- 耳廓:将所有声音聚拢在一起
- 耳道:将声音传递进去,使声音有一个放大的效果。(耳道越长,听觉系统越敏感)(举例:将纸筒放到耳朵上面,感觉声音被放大了)
- 鼓膜:声音通过耳道,然后使鼓膜振动
- 听觉系统:将鼓膜振动产生的声音交给神经系统
(3)人类听觉范围和其他动物的听觉范围:
赫兹(HZ):每秒钟,物体振动的次数。

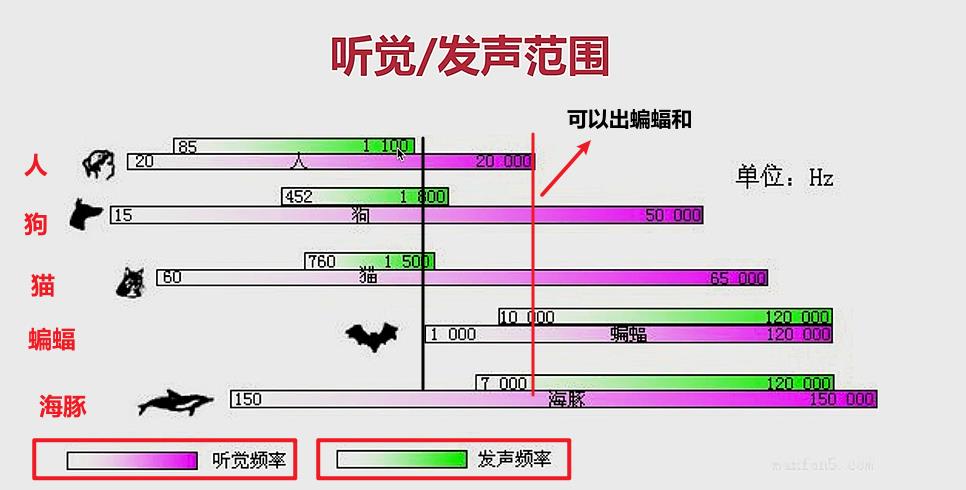
- 可以看出,蝙蝠和海豚发出的一部分声音,我们是听不到的。
- 我们人类说话发出的声音,蝙蝠也是听不到的。
3、声音的三要素

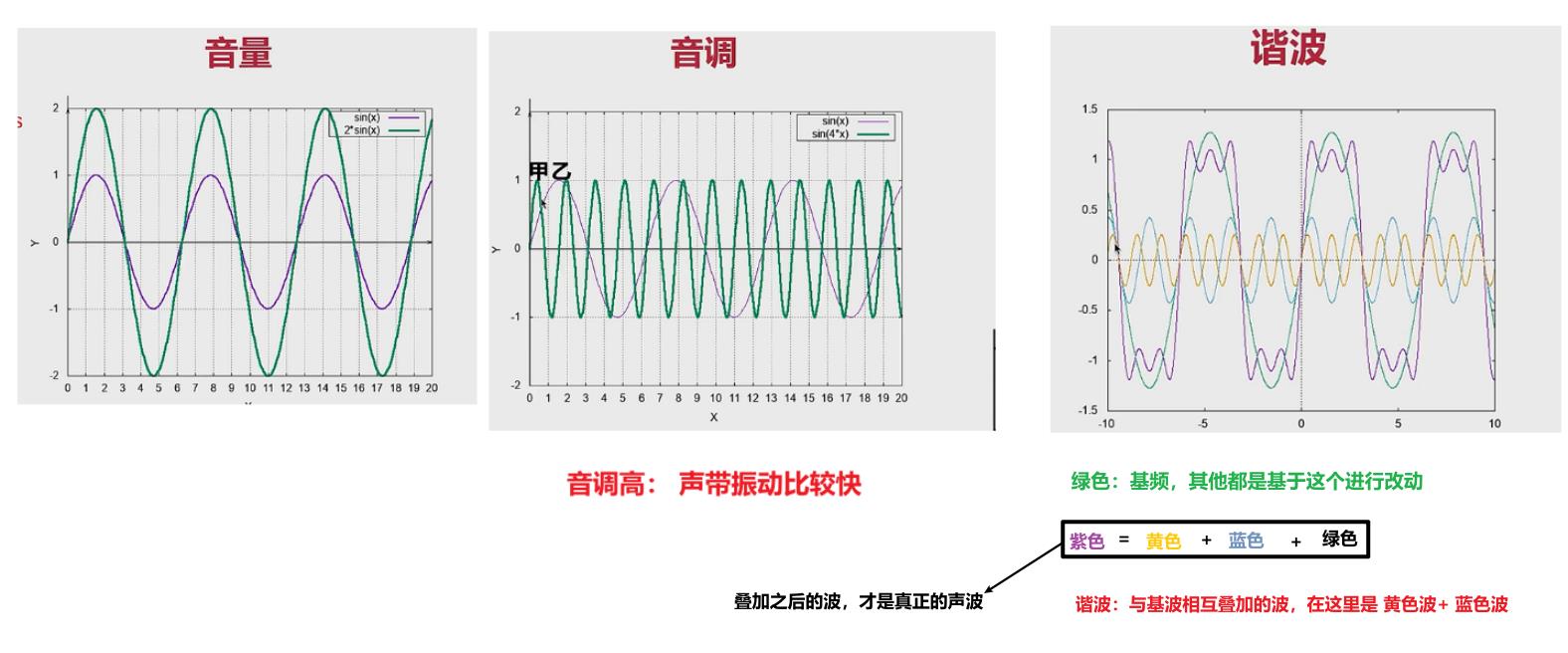
- 音调:音频的快慢
- 音量:振动的幅度
- 音色:谐波:除了基波之后,剩下与基波进行叠加的波。(音色不一样,说明基波不一样)
4、模数转换
- 实际的声波:模拟量,是连续不断的。
- 计算机声波:数字量,是离散的点。
模拟 ——> 数字: 关键就是量化 ,量化的关键又是 采样
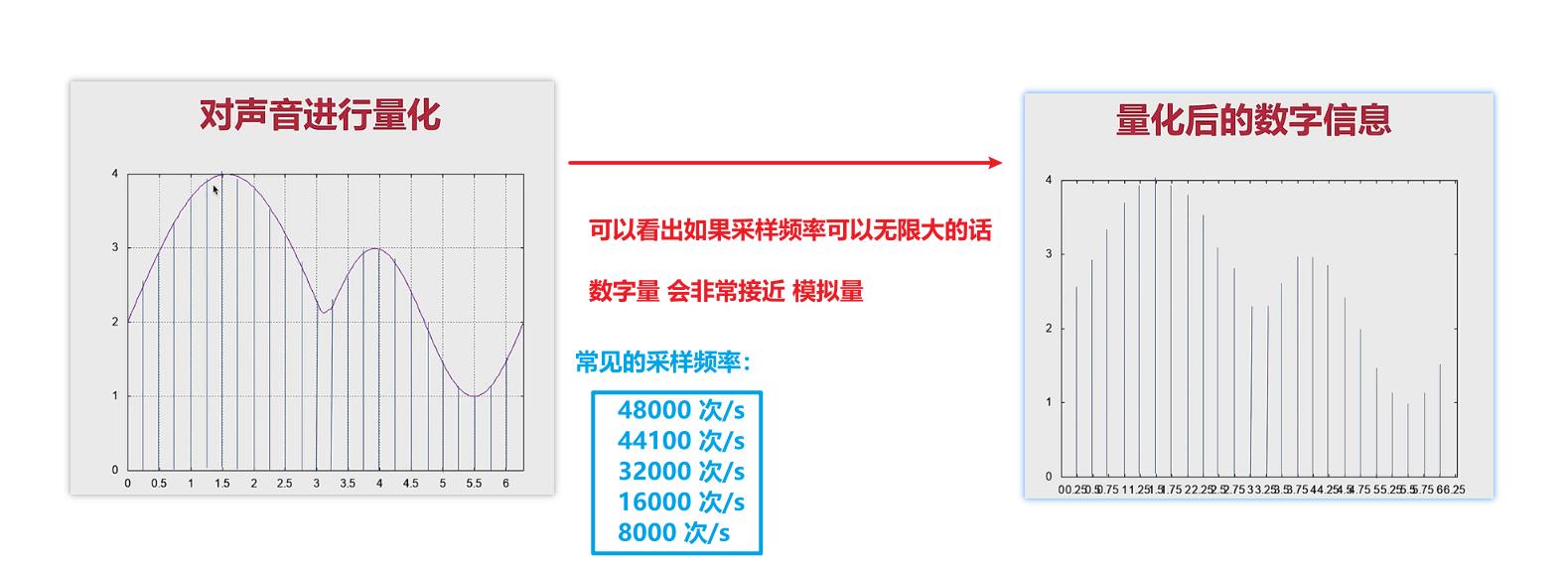
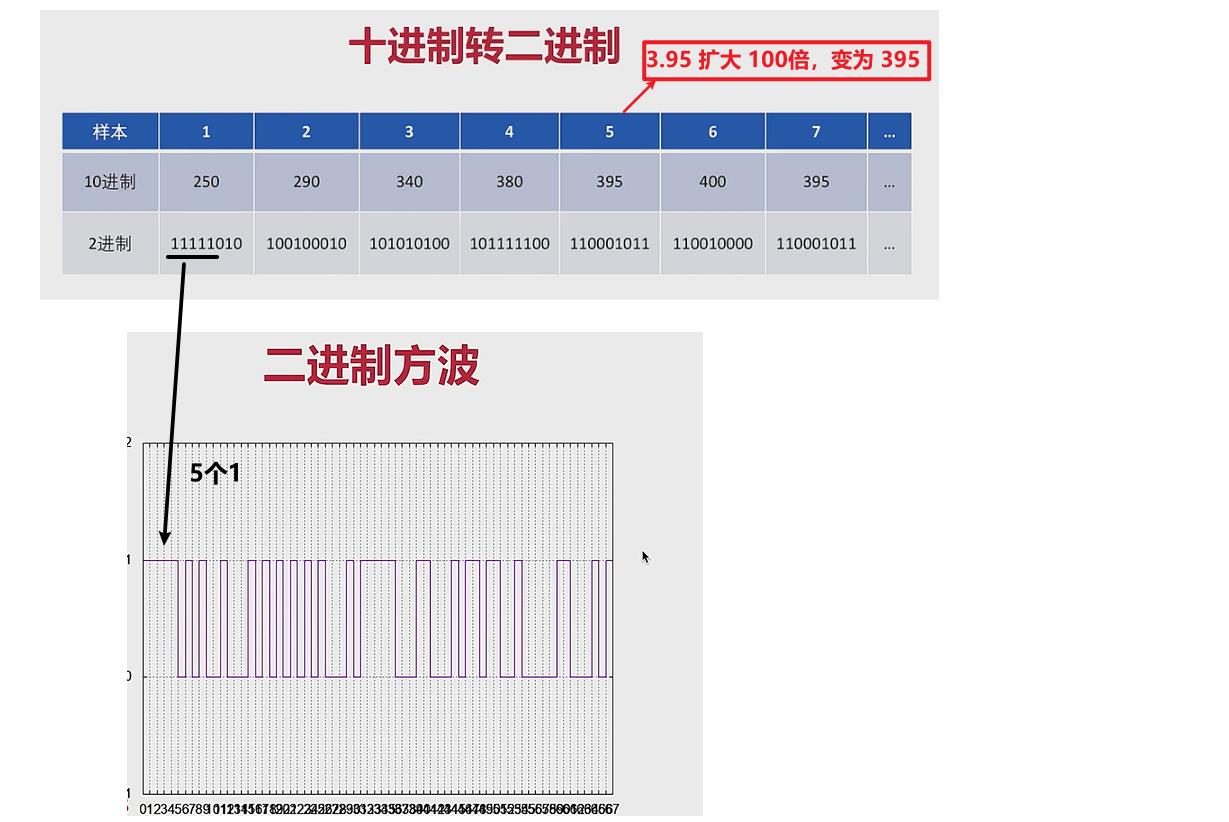
注意:
- 计算机当中的格式是二进制,但是这里的格式是十进制,所以要进行转换。
- 二进制的方波就可以应用到电路当中
- 计算机当中没有小数点,将十进制扩大10倍,就可以消除一个小数点。
- 十进制的扩大范围与位深有关
概念:
- 位深(采样大小):表述 采样数值 的最大范围。8位(0-255) 16位(0-65535)
- 采样率:8k、16k、32k、44.1k、48k。 (一秒钟采样的次数)
- 声道数:单声道、双声道、多声道。 (几个通道进行采样)
5、PCM 与 WAV
PCM
- (Pulse-Code Modulation),翻译一下是脉冲调制编码。
- 是没有任何文件格式的
- 码率 == 采样率 × 位深 × 声道数 ➗ 8 ,单位是 字节。

- 可以看出原始码流的数据大小,是非常大的。网络要是传输这么大的数据,就会被卡死。
WAV
- 是一种文件格式
- 既可以存放原始数据,可以存放压缩过后的数据。 但是 99% 情况下存放原始数据。
- 本质:在 PCM 数据上面加了一个头,包含了一些最基本的信息, 便于播放器使用正确的参数来播放PCM数据
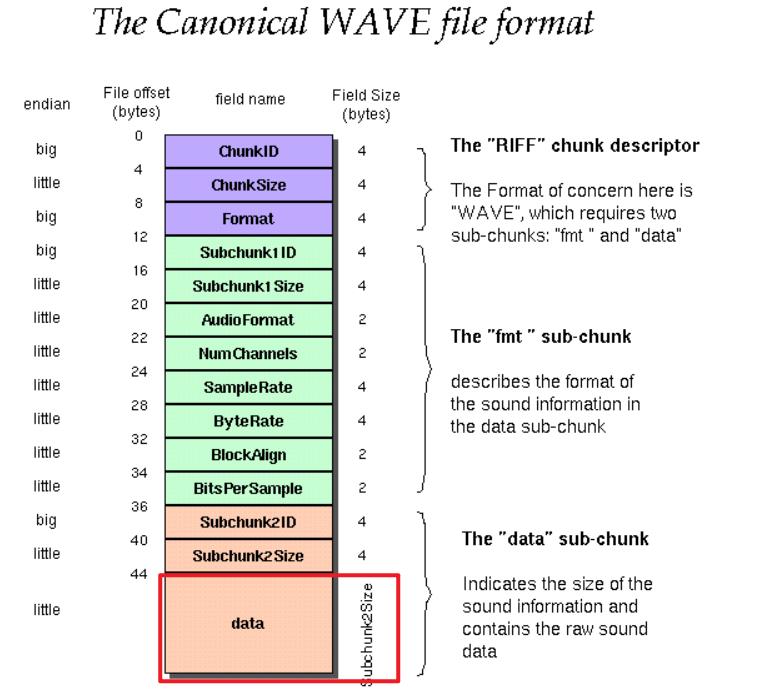
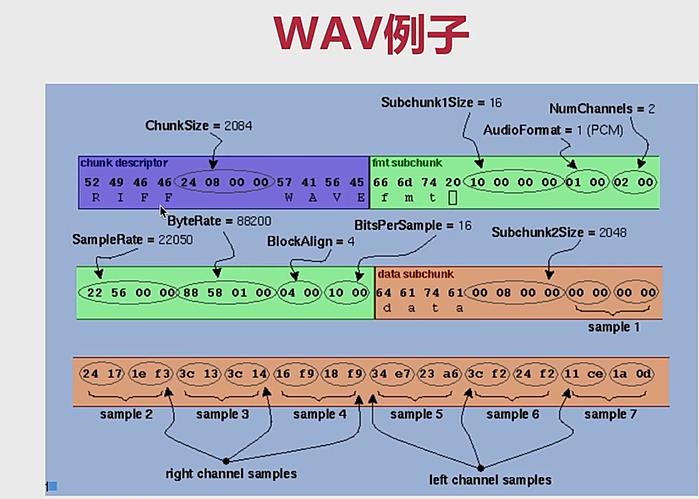
表 3 WAVE 文件头格式
| 偏移 地址 | 字节数 | 数据 类型 | 字段名称 | 字段说明 |
|---|---|---|---|---|
| 00H | 4 | 字符 | 文档标识 | 大写字符串"RIFF",标明该文件为有效的 RIFF 格式文档。 |
| 04H | 4 | 长整型数 | 文件数据长度 | 从下一个字段首地址开始到文件末尾的总字节数。该字段的数值加 8 为当前文件的实际长度。 |
| 08H | 4 | 字符 | 文件格式类型 | 所有 WAV 格式的文件此处为字符串"WAVE",标明该文件是 WAV 格式文件。 |
| 0CH | 4 | 字符 | 格式块标识 | 小写字符串,"fmt "。 |
| 10H | 4 | 长整型数 | 格式块长度。 | 其数值不确定,取决于编码格式。可以是 16、 18 、20、40 等。(见表 2) |
| 14H | 2 | 整型数 | 编码格式代码。 | 常见的 WAV 文件使用 PCM 脉冲编码调制格式,该数值通常为 1。(见表 3) |
| 16H | 2 | 整型数 | 声道个数 | 单声道为 1,立体声或双声道为 2 |
| 18H | 4 | 长整型数 | 采样频率 | 每个声道单位时间采样次数。常用的采样频率有 11025, 22050 和 44100 kHz。 |
| 1CH | 4 | 长整型数 | 数据传输速率 | 该数值为:声道数×采样频率×每样本的数据位数/8。 |
| 20H | 2 | 整型数 | 数据块对齐单位 | 采样帧大小。该数值为:声道数×位数/8。播放软件需要一次处理多个该值大小的字节数据,用该数值调整缓冲区。 |
| 22H | 2 | 整型数 | 采样位数 | 存储每个采样值所用的二进制数位数。常见的位数有 4、8、12、16、24、32 |
| 24H | 对基本格式块的扩充部分(详见扩展格式块,格式块的扩充) |
二、音频采集(实战)
1、通过命令方式采集音频数据
- 对于做直播系统来说,音频的采集要在不同的平台上面都可以实现。 平台包括:ios、android 、Linux 、windows、MAC 端。
- 对于不同的平台,采用的 API 都是不同的。
- 如果我们为了采集音频,要对所有平台的 API 都要熟悉的话,那工作量就太大了。
- 解决办法:使用 ffmpeg 的 API 即可,不同的平台的差异,都被 ffmpeg 封装好了。
FFmpeg 采集音频的两种方式:
- 通过命令的方式:较为基础,不够灵活。
- 通过 API 的方式:做 native 开发的话,更多使用 API 来进行操作。
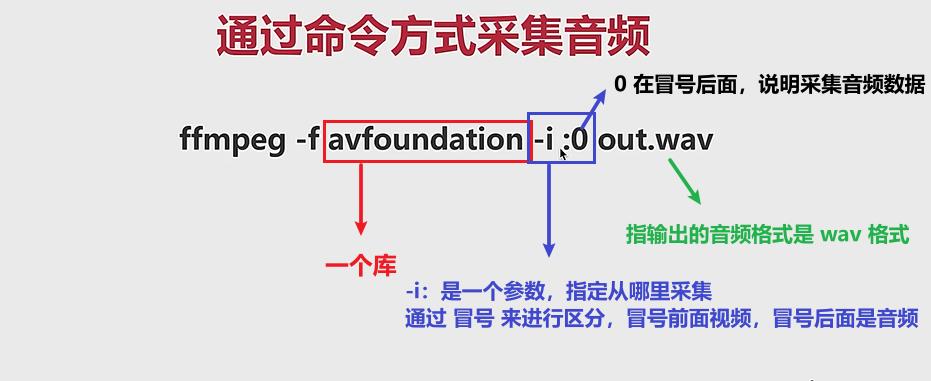
注意:
- avfoundation :只应用于 MAC 平台,如果是其他平台需要更换其他的库。
- :0 :在 MAC 表示采集音频信号,但是其他平台的表示也不同。

三、音频编码原理
有几个常识:
- 采样率为44.1KHz ,采样大小为16bit ,双声道的PCM编码的WAV文件,它的码率 44.1Kx16x2=1411.2Kb/s. (大概一兆)
- 一般用户的上传和下载速度不匹配,如果不经过压缩,音频的传输会很吃力。对于实时通讯来说就更是如此了
- 对于压缩来说有两个极端:(1)压缩的数据量越小越好 (2)压缩的速度越快越好
对于音频的压缩来说 我们关注两个点
- 消除冗余信息(人的听觉范围在 20-20khz,在这个范围之外的我们可以进行剔除) (有损压缩)
- 无损压缩 (rar,zip,.jz) (含义:压缩过后,通过解码可以进行完全还原)
1、有损压缩和无损压缩
消除冗余信息的压缩:本身就是有损压缩,因为剔除之后,我们无法同解压缩来进行恢复。
分析:冗余信息、频域遮蔽 和 时域遮蔽
- 冗余信息:包括人耳听觉范围外的音频信号以及被掩蔽掉的音频信号。
- 信号的遮蔽:可以分为频域遮蔽和时域遮蔽
概念铺垫:
- 我们能听到的所有声音:都是复合声音,(这些声音都是被叠加过的)
- 比如说话的时候,可能电脑风扇在转,可能楼下有人走动。 但是我们不可能听到所有的声音。
- 因为有一部分的声音被屏蔽了
分析下图:
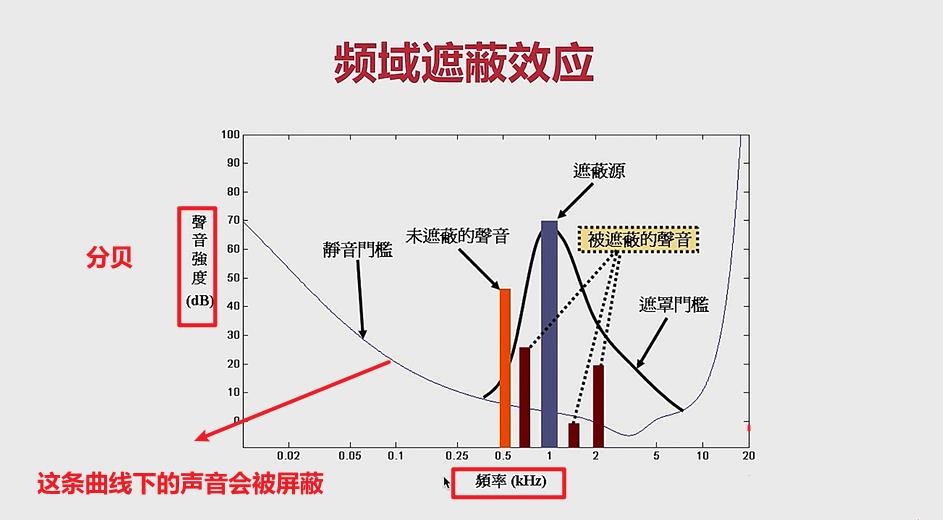
- 横轴:频率(赫兹) ; 纵轴:声音强度(分贝)
- 静音门槛:在这条曲线下面的声音,是被屏蔽的,我们听不到。(大概分析:频率越低,对声音强度要求就比较高,频率高一点的时候,对声音强度要求就比较低)
比如:(1)男人和女人说话,分贝一样的时候,女人的声音更容易被听到。
同理:(2)走步的声音,频率很低,所以很容易被屏蔽 - 遮蔽源:可以理解为,最敏感的声音,容易将其他声音遮蔽。
- 被遮蔽的声音:在遮蔽源的曲线下面的声音,都会被遮蔽。
- 未遮蔽的声音:它的强度比较高,没有被遮蔽。
时域遮蔽:随着时间的推移,有些声音就会被遮蔽。
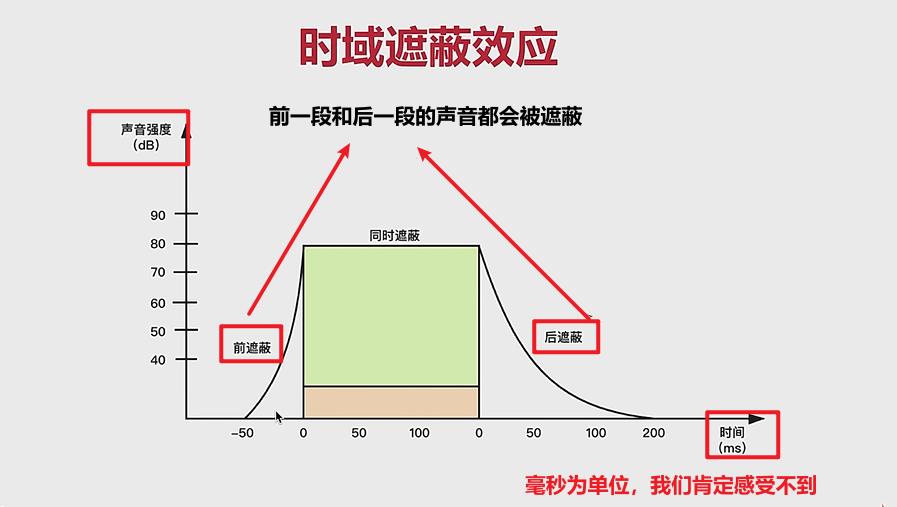
- 给定条件:在某个时刻,一个声音被另外一个声音遮蔽,会产生前屏蔽和后屏蔽。
- 同一个频率下面,声音强度高的会屏蔽声音强度低的。
- 在被屏蔽的时候,前一段时间和后一段时间的声音也会被屏蔽。
- 后屏蔽的时间作用比较长。
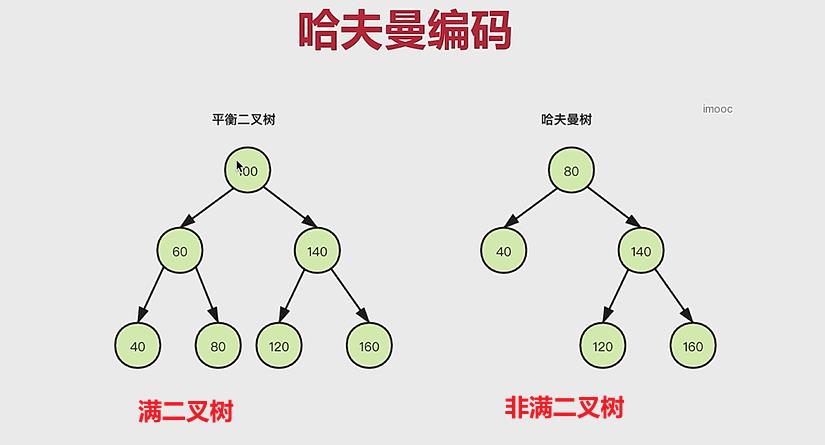
无损压缩:熵编码包括:
- 哈夫曼编码:
- 算术编码:
- 香农编码:
重点分析哈夫曼编码:
2、音频的编码过程:
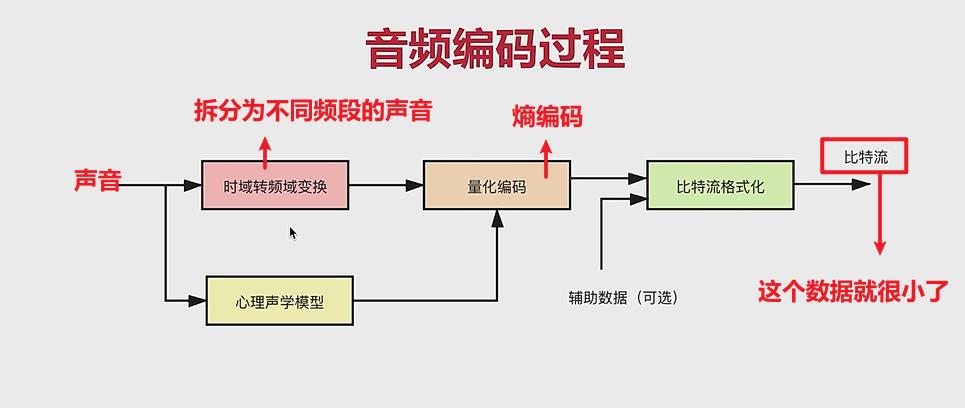
- 时域转频域:我们将其拆分成不同频段的数据,方便我们进行剔除,进行压缩
- 心理声学模型:就是确认哪些数据可以被去掉。
- 量化编码:无损压缩,进行熵编码
- 比特流格式化:加一些特定的头,从而变成一个特定格式的文件。
3、编码器介绍
- 常见的音频编码器包括OPUS、AAC、 Ogg、 Speex、 iLBC、AMR、G.711等。
- 最常见的是:OPUS(新星编码器、WebRTC默认使用)、AAC(AAC 已经做好了硬件的编码器)
- Ogg:收费的一个编解码器
- Speex:支持了回音消除
- G.711:固话使用这个
音频编解码器质量的比较:(横轴:码流大小、纵轴:质量)
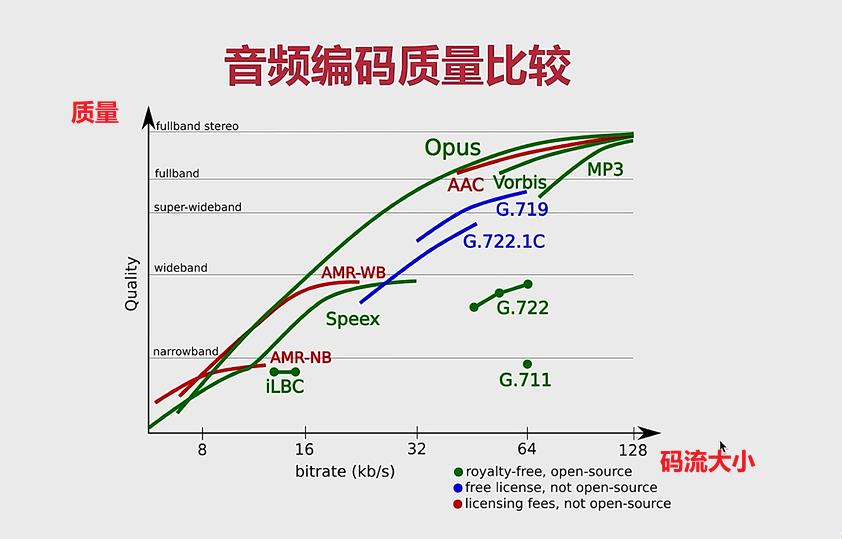
- 质量分为:窄频带、宽频带、超宽频带、满频带。
- Opus 的跨度非常大,说明适用范围很广。质量小——码流小, 质量大——码流大。
- AAC适用于全带:32k——128k
- G.711 适用于窄带:而且它编码后的码流还是很大
音频编码器中,码率和延迟关系

- opus 的延迟很底,所以适用于实时通信。网页直播
AAC 编码器介绍
- AAC ( Advanced Audio Coding )由Fraunhofer IIS、杜比实验室、AT&T、Sony等公司共同开发。
- 目的是取代MP3格式。
- 最开始是基于 MPEG-2 的音频编码技术,MPEG- 4标准出现后,AAC重新集成了其特性,加入了SBR技术和 PS 技术。
- 目前常用的规格有 AACLC、AAC HE V1、AAC HE V2
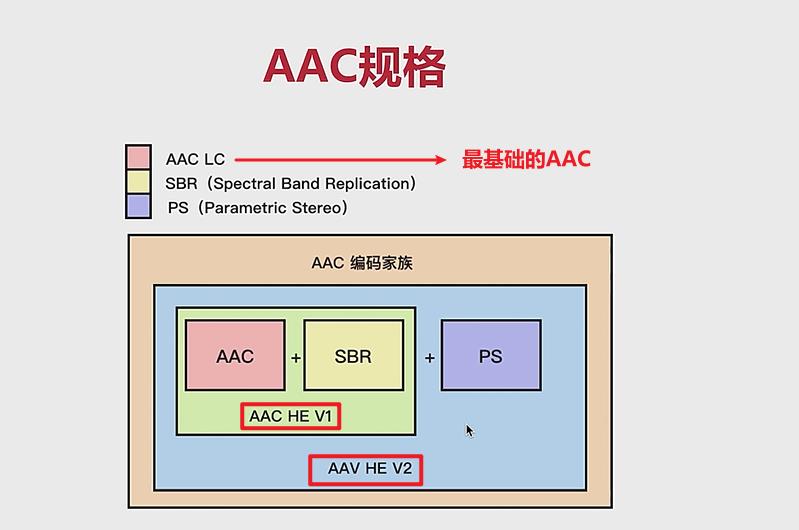

- AAC LC : (Low Complexity)低复杂度规格,码流是128k ,音质好。
- AACHE:等于AAC LC + SBR (Spectral Band Replication)。其核心思相是按频谱分保存。低频编码保存主要成分,高频单独放大编码保存音质。码流在64k左右。
(低频——代表基波,表示主要的音频内容) (高频——代表谐波,代表音色,音色保存越好,音质越好) - AACHE V2 :等于AAC LC + SBR + PS (Parametric Stereo)。其核心思相是双声道中的声音存在某种相似性**,只需存储一个声道的全部信息**,然后,花很少的字节用参数描述另一个声道和它不同的地方。
AAC 格式:

- ADIF:相当于直接在 AAC 数据前面添加一个头。这个头里面描述了音频数据的开始。
- ADTS:在每一帧都有一个同步字,(每一帧前面都有一个头)
4、ADTS格式
AAC音频文件的每一帧都由一个ADTS头和AAC ES(AAC音频数据)组成。
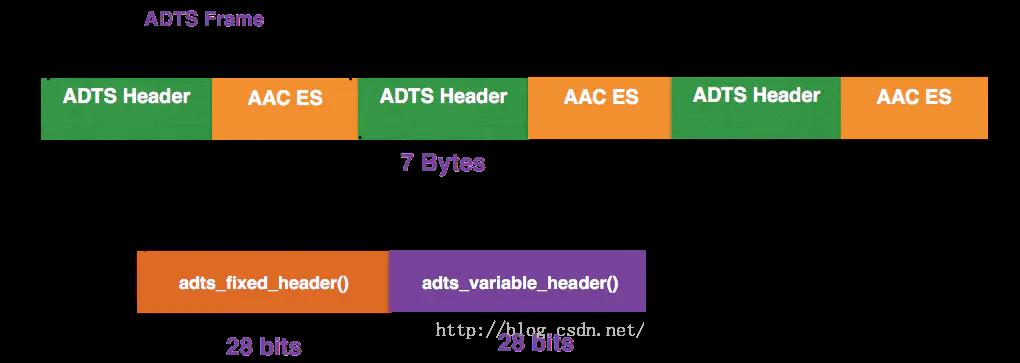
- ADTS 头中相对有用的信息 采样率、声道数、帧长度。 有了这些标识信息,我们的解码器才可以对数据进行解码。
- ADTS头分为固定头信息和可变头信息两个部分,固定头信息在每个帧中的是一样的。
- 可变头信息在各个帧中并不是固定值。ADTS头一般是7个字节((28+28)/ 8)长度,如果需要对数据进行CRC校验,则会有2个Byte的校验码,所以ADTS头的实际长度是7个字节或9个字节。
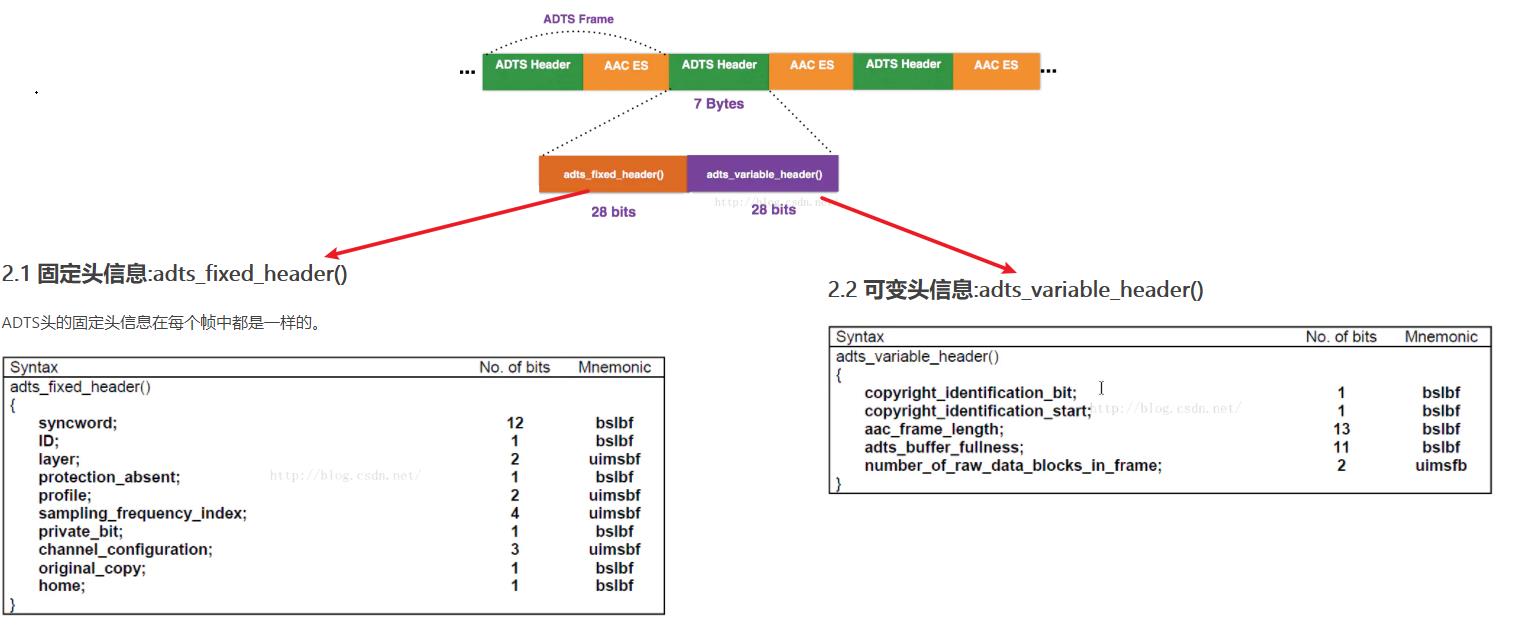
固定头信息
| 名称 | 大小(bit) | 作用 |
|---|---|---|
| syncword | 12 | 帧同步标识一个帧的开始,固定为0xFFF |
| ID | 1 | 0表示MPEG-4,1表示MPEG-2 (默认是MPEG-4) |
| layer | 2 | 固定为’00’ |
| protection_absent | 1 | 0表示有CRC校验,1表示没有CRC校验 (决定是7字节,还是9字节) |
| profile | 2 | 1: AAC Main 2:AAC LC (Low Complexity) 3:AAC SSR(Scalable Sample Rate) 4:AAC LTP (Long Term Prediction) |
| sampling_frequency_index | 4 | 标识使用的采样率的下标 |
| private_bit | 1 | 私有位,编码时设置为0,解码时忽略 |
| channel_configuration | 3 | 标识声道数 |
| original_copy | 1 | 编码时设置为0,解码时忽略 |
| home | 1 | 编码时设置为0,解码时忽略 |
可变头信息:
| 名称 | 大小(bit) | 作用 |
|---|---|---|
| copyrighted_id_bit | 1 | 编码时设置为0,解码时忽略 |
| copyrighted_id_start | 1 | 编码时设置为0,解码时忽略 |
| aac_frame_length | 13 | ADTS帧长度包括ADTS长度和AAC声音数据长度的和。即 aac_frame_length = (protection_absent == 0 ? 9 : 7) + audio_data_length |
| adts_buffer_fullness | 11 | 固定为0x7FF。表示是码率可变的码流 |
| number_of_raw_data_blocks_in_frame | 2 | 表示当前帧有number_of_raw_data_blocks_in_frame + 1 个原始帧(一个AAC原始帧包含一段时间内1024个采样及相关数据)。 |
分析几个重要的参数:

因为采样率的本身数字太大了,所以进行了一个编号。

通过 ffmpeg 生成AAC文件

分析实验参数
-i :指定输入的视频文件(视频文件当中包含音频)
-vn:(video no)去掉音频
-c:a : (encoder : audio) 指定音频的编码器
-ar :设置采样率
-channels :设置通道数
-profile:a : 给 audio 指定参数
四、音频编码
1、音频重采样
什么是音频重采样?
- 将音频三元组(采样率、采样大小、通道数) 的值转成另外一组值
- 例如:将 44100/16/2 转成 48000/16/2 (将采样率进行改变)
为什么要进行重采样?
- 从设备采集的音频数据 与 编码器要求的数据不一致。
- 扬声器要求的音频数据 与 要播放的音频数据不一致。
- 便于运算,例如在回音消除的时候,我们一般将他设置为单声道。
如何知道是否需要进行重采样?
- 要了解音频设备的参数
- 查看 ffmpeg 源码 (ffmpeg 是跨平台的,所以它的源码都有各个平台的参数)(ffmpeg 实现所有常见的编解码器,所以源码里面肯定又编码器的要求参数)
重采样的步骤:
- 创建采样上下文(链接上面一个过程和下一个过程的桥梁)
- 设置参数
- 初始化重采样
- 进行重采样
几个重要的 API:
- swr_ alloc_ set_ opts:创建了一个上下文 + 传入参数的设置
- swr_ init :对上下文的初始化
- swr_ convert:实际的重采样
- swr_ free : 上下文的释放
2、创建 AAC 编码器
ffmpeg 的编码过程
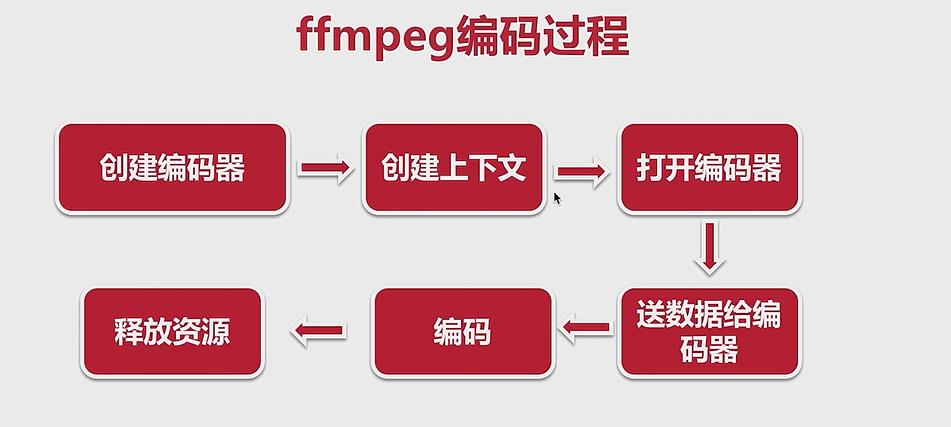
创建并且打开编码器:

留个坑
以上是关于第二章:音频入门的主要内容,如果未能解决你的问题,请参考以下文章