图神经网络——NIPS 2017GraphSAGE
Posted 卓寿杰_SoulJoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图神经网络——NIPS 2017GraphSAGE相关的知识,希望对你有一定的参考价值。
先了解两个概念:
- 直推式(transductive)学习:从特殊到特殊,仅考虑当前数据。在图中学习目标是学习目标是直接生成当前节点的embedding,例如DeepWalk、LINE,把每个节点embedding作为参数,并通过SGD优化,又如GCN,在训练过程中使用图的拉普拉斯矩阵进行计算,
- 归纳(inductive)学习:平时所说的一般的机器学习任务,从特殊到一般:目标是在未知数据上也有区分性。
直推式(transductive)学习方法是在一个固定的图上直接学习每个节点embedding,但是大多情况图是会演化的,当网络结构改变以及新节点的出现,直推式学习需要重新训练(复杂度高且可能会导致embedding会偏移),很难落地在需要快速生成未知节点embedding的机器学习系统上。
本文提出归纳学习—GraphSAGE(Graph SAmple and aggreGatE)框架,通过训练聚合节点邻居的函数(卷积层),使GCN扩展成归纳学习任务,对未知节点起到泛化作用。
embedding 过程
下图展示了 GraphSAGE 学习目标节点(中心的红色节点) embedding 的过程:
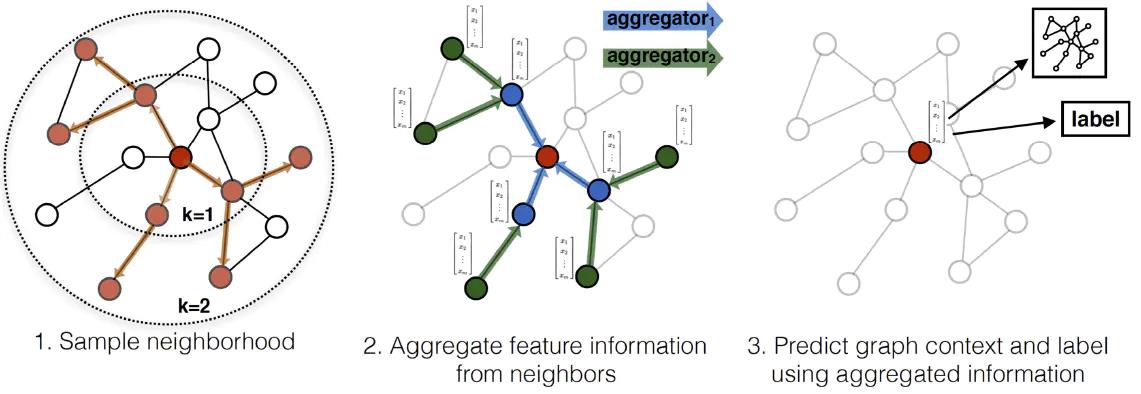
- 先对邻居节点采样:上图仅对2跳内的邻居采样,2跳邻居节点采样5个节点,1跳邻居采样个节点。
- 生成目标节点embedding:先聚合2跳邻居节点特征,生成1跳邻居节点embedding,再聚合1跳邻居节点 embedding,生成目标节点 embedding。
- 将 embedding 结果作为全连接层输入,预测目标节点标签。
聚合
- 平均聚合:先对邻居embedding中每个维度取平均,然后与目标节点embedding拼接后进行非线性转换。

- 归纳式聚合:直接对目标节点和所有邻居emebdding中每个维度取平均,后再非线性转换:

- LSTM聚合:LSTM函数不符合“排序不变量”的性质,需要先对邻居随机排序,然后将随机的邻居序列embedding 作为LSTM输入。
- Pooling聚合:每个邻居节点的embedding向量都输入到全连接神经网络中,然后对得到的embedding进行 max pooling 操作

训练(无监督和有监督)
损失函数根据具体应用情况,可以使用基于图的无监督损失和有监督损失。
- 无监督:希望节点u与“邻居”v的embedding也相似(对应公式第一项),而与负采样(没有交集)的节点
v
n
v_n
vn不相似(对应公式第二项)。
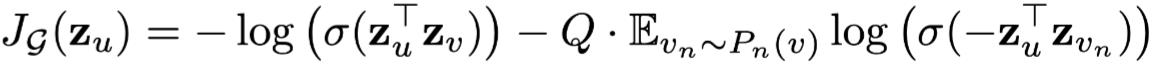
- 有监督:无监督损失函数的设定来学习节点embedding 可以供下游多个任务使用,若仅使用在特定某个任务上,则可以替代上述损失函数符合特定任务目标,如交叉熵。
以上是关于图神经网络——NIPS 2017GraphSAGE的主要内容,如果未能解决你的问题,请参考以下文章