ext4文件系统布局
Posted 程序猿Ricky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ext4文件系统布局相关的知识,希望对你有一定的参考价值。
ext4文件系统块组
ext4中的数据是按照块组进行管理的,一个块组来中包含有多个块。其中有1个块用于保存数据块位图,因此位图中包含有多少个bit就决定了块组中块的个数。
比如,对于一个块大小为4096Byte的设备,块位图中的比特位数为32768(4096 * 8),那么单个块组中最大就只能具有32768(4096 * 8)个块。那么也可以计算出单个块组的大小为32768*4096=128MB。
块组的结构布局如下所示:

超级块
ext4超级块(super block)记录了文件系统的很多关键信息,如果一个文件系统中只存在一个超级块,那么如果超级块损坏将导致整个文件系统的损坏,因此整个块设备上存在很多超级块的备份,
对于超级块的备份,如果每个块组中都备份一个,又会占据太多的文件系统空间,ext4中支持 sparse_super 特性,如果打开该特性,超级块将只在特定的块组中备份,它的备份块需要满足如下规定:
- 块组0
- 块组的组ID为3、5、7的幂
需要注意的是,块组0是一个特殊的块组,它的最前面1024字节是预留给boot sector使用的,因此super block的起始位置需要跳过块组0的前1024字节。而对于其他的备份块则直接保存在对应块组的起始位置处。
根据这个关系,就可以找到对应的超级块以及备份块:
| 块组id | 第N块 |
|---|---|
| 0 | 0(前面需要跳过1024byte) |
| 1(3^0) | 32768 |
| 3(3^1) | 32768*3 |
| 5(5^0) | 32768*5 |
| 7(7^0) | 32768*7 |
| 9(3^2) | 32768*9 |
| … | … |
作为测试,可以把对应的super block dump出来:
dd if=/dev/sda1 of=sb0.txt bs=4096 count=1
dd if=/dev/sda1 of=sb1.txt bs=4096 count=1 skip=32768
dd if=/dev/sda1 of=sb2.txt bs=4096 count=1 skip=98304
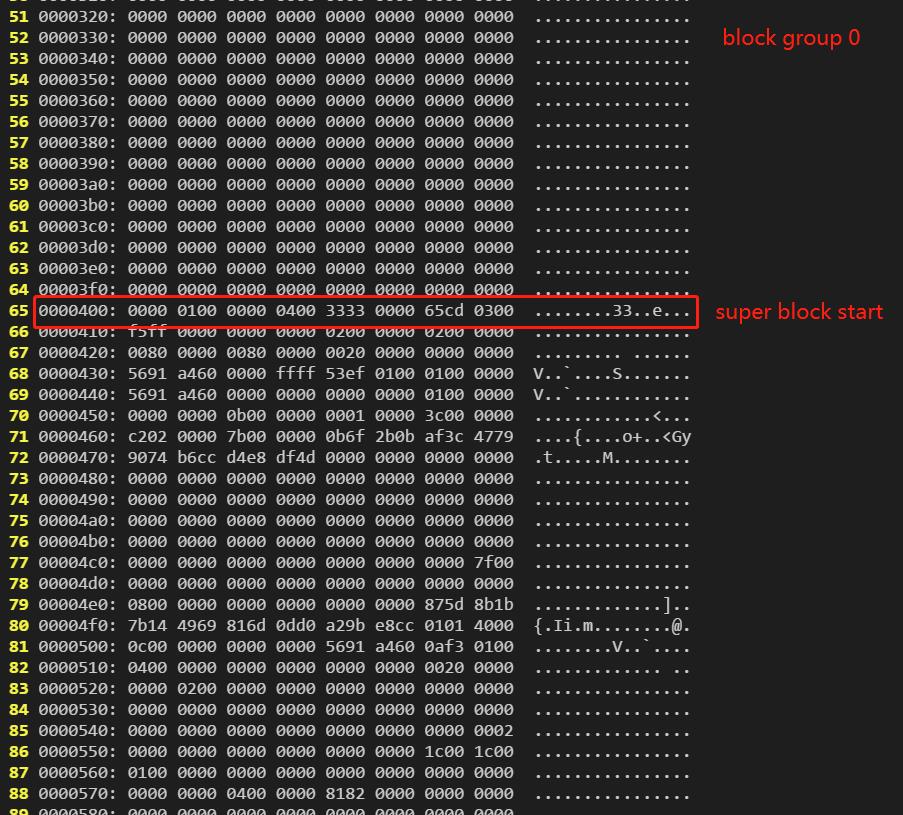
查看第0号块组中的super block,可以发现它确实是从1024字节之后开始的:
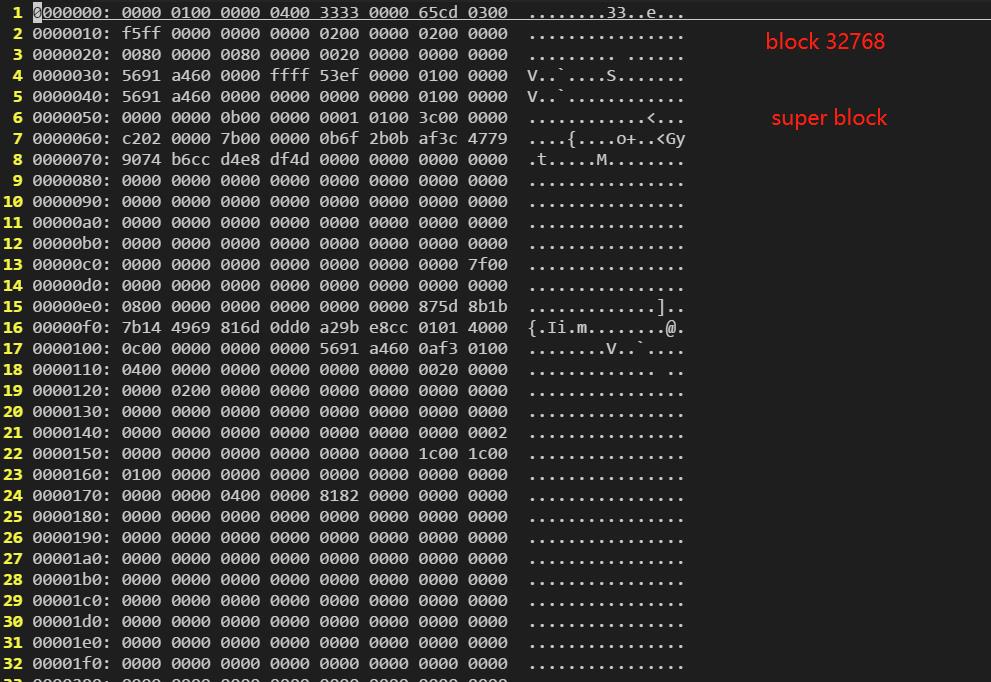
而第1号块组中的备份超级块(backup super block),直接就是从该块组的起始位置开始:
inode
ext4文件系统中,inode也是在块组中进行管理的,块组中存在1个块用于保存inode位图和多个块用于保存inode表。块组大小的计算类似,对于块大小为4096Byte的文件系统,inode位图的比特位最大是32768(40968),
那么也就说明该块组中最大只能申请32768个inode,块组中最大管理文件个数也就是32768个。单个inode占用大小为256Byte,那么inode表最大占用32768256=8M空间,转换为块个数为2048个。
实际上对于一个块组来说,按照最大限制来预留inode是没有必要的,因为我们一个块组128M,如果分成32768个文件,相当于平均单个文件才4K,这种情况还是比较少见的,因此可以少分配一些空间给inode表,这样就能节省空间。
因此正常在创建文件系统时,会传入参数到mkfs.ext4中的-i选项来设定单个文件占用的空间预计为多少,工具会根据文件size设定来确定inode的个数。
# dumpe2fs test.image | grep -i inode
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Inode count: 65536
Free inodes: 65525
Inodes per group: 8192
Inode blocks per group: 512
First inode: 11
Inode size: 256
Journal inode: 8
Journal backup: inode blocks
flex_bg
前面介绍的是经典ext4文件系统布局,ext4还引入了flex_bg的特性,就是把多个块组放在一起管理,简单来讲,就是把多个块组的block bitmap聚合在一起,inode bitmap聚合在一起,inode table 也聚合在一起,形成一个更大的逻辑块组。它的好处就是能够充分发挥内核预读取的作用,减少了inode零散分布带来的查找开销,提升了文件系统性能。一般使用mkfs.ext4工具创建文件系统时默认都是开着该选项的。
参考文档:
https://bean-li.github.io/EXT4-packet-meta-blocks/
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout
以上是关于ext4文件系统布局的主要内容,如果未能解决你的问题,请参考以下文章