利用 Python 爬取了 37483 条上海二手房信息,我得出的结论是?
Posted 程序员小濠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用 Python 爬取了 37483 条上海二手房信息,我得出的结论是?相关的知识,希望对你有一定的参考价值。
本文数据来源于链家网,搜集时间为2020年7月23日。
本次项目使用 Scrapy-Redis 分布式爬取链家网数据,请自备代理ip。完整代码已放在文首,本文不再赘述爬虫细节,源码中有详细注释。
仪表板展示
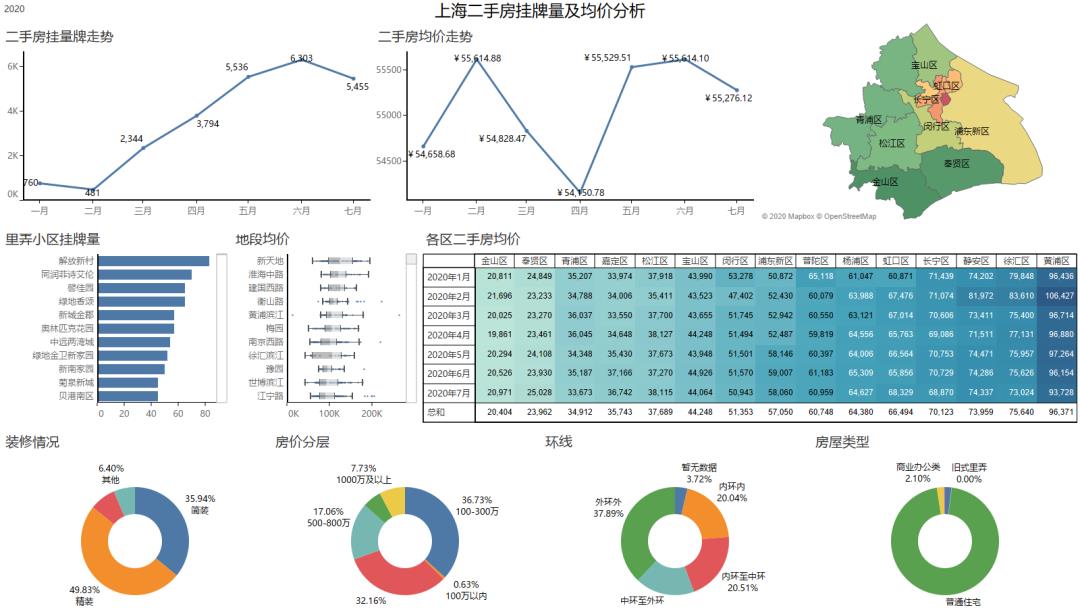
项目背景
去面试的时候被问上海二手房的一些情况,作为一个土著,我只知道上海这个区挺贵的那个区大概这个价,但是具体数值却说不上来。所以,就有了本文。
从政策上来看,自从 2016 年国家喊出“房住不炒”的口号之后中国的房价就出现了明显的降温。2019 年国家为了“救市”又宣布了几条政策:
1、 政府不再垄断住房供应,缓解了开发商的资金压力,新房销售价格降低,导致新房市场火热而二手房市场冷清。
2、 调整公积金贷款利率,提高了二房的房贷利率,打击市场投机需求。
3、 鼓励租售并举,鼓励以住房租赁为主营业务的企业买房。
4、 居住证降低申请门槛新政,让落户买房更加容易。
5、 农民购房有补助,帮助农民工朋友们省去一部分买房成本。
从经济上来看,2020 年上半年上海人均可支配收入以 36577 元笑傲全国,同比增长3.64%。看似美丽的数值背后,隐藏着多少被平均的普通老百姓。

从社会上来看,2019 年我国人口出生率创下 1949 年以来的最低值,即使在 2016 年开放二胎政策以来,人口出生率也没有大幅提高。
从技术上来看,中国造楼能力世界第一!“基建狂魔”岂是浪得虚名!
分析目的
1、 2020年上半年上海二手房整体挂牌量及均价走势如何?
2、 目前上海二手房价位、房源有何特点?
3、 上海各区县的挂牌情况,找出抛压最大的区域
数据清洗
首先我们看一下爬取的数据。维度不是太多,但是有些列我们可以拆分,例如地区、所在楼层、抵押信息等。

在对数据进行清洗前我们可以使用pandas_profiling进行快速的统计分析。
import pandas_profiling
pandas_profiling.ProfileReport(data).to_file("./report/html")
复制代码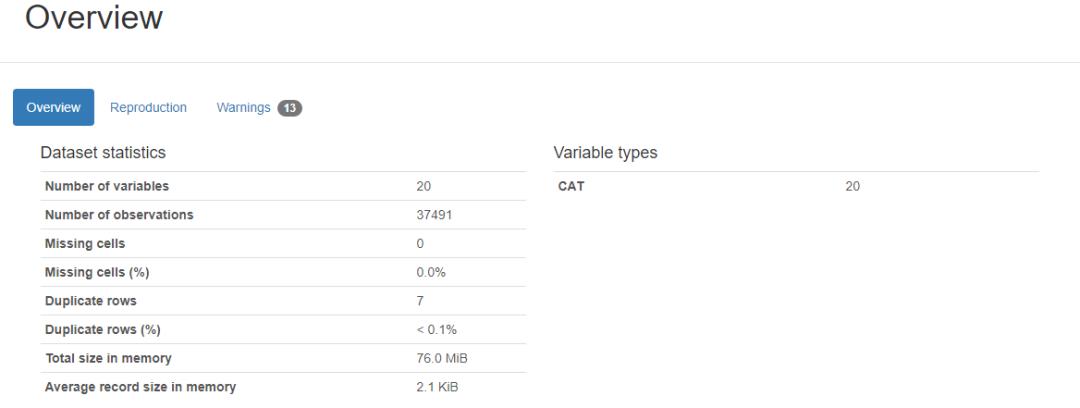
根据报告内容我们可以看到本次数据总共有 37491 行,20 列,存在 7 行重复,重复占比小于 0.1%,报告继续下拉可以看到每一列的统计情况。
我们需要清洗的几点:
1、 去除重复行
2、 替换 None 值
3、 将地区、房屋户型、所在楼层、抵押信息进行切分合并
4、 转换数据类型
5、 删除多余字符
6、 由于爬取时出现的错误,对价格列进行重新赋值
7、 剔除异常数据
# 如果有重复值,则保留第一个
data.drop_duplicates(keep='first', inplace=True)
# 替换None
data = data.applymap(lambda x: '暂无数据' if x == 'None' else x)
# 切分地区、房屋户型、所在楼层、抵押信息后删除原列,将拆分出的新列合并至原data
data = pd.concat([data, data['地区'].str.extract(pat='(?P<区>.*?)\\s(?P<镇>.*?)\\s(?P<环>.*)'),
data['房屋户型'].str.extract(
pat='(?P<室>\\d+)室(?P<厅>\\d+)厅(?P<厨>\\d+)厨(?P<卫>\\d+)卫'),
data['所在楼层'].str.extract(
pat='(?P<所处楼层>.+)\\(共(?P<总层数>\\d+)层\\)'),
data['抵押信息'].map(lambda x:x.strip()).str.extract(pat='(?P<有无抵押>.{1})抵押(?P<抵押情况>.*)?')], axis=1)
data.drop(['地区', '所在楼层', '抵押信息'], axis=1, inplace=True)
data['区'] = data['区']+'区'
# 去除建筑面积后面的平米单位,并转为float
data['建筑面积'] = data['建筑面积'].map(lambda x: float(x[:-1]))
# 转换数据类型
data['价格'] = data['价格'].astype(float)
# 转换日期类型
data['挂牌时间'] = pd.to_datetime(data['挂牌时间'])
# 如果存在非时间类型的字符串则替换为NaT
data['上次交易'] = pd.to_datetime(data['上次交易'], errors="coerce")
# 存在括号几期、某区,都暂且删除
data['小区'] = data['小区'].str.replace("[\\(\\(].*?[\\)\\)]", "")
# 筛选出价格小于20的数据,我们可以发现这些房源的面积及所属区域都是比较好的,记录的数据可能有所错误
# 返回链家网站搜索这几套房源后发现,这些价格的单位都是"亿",所以我们需要对所有数据再一次进行清洗
# 统一使用'万'作为总价的单位
data['价格'] = data['价格'].map(lambda x: x*10000 if x < 20 else x)
# 计算每平米单价
data['均价'] = round(data['价格']/data['建筑面积']*10000, 2)
复制代码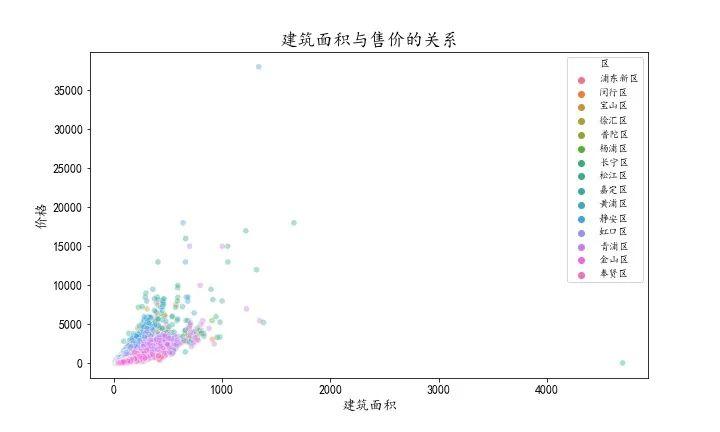
从上面的散点图我们可以看出右边有一个异常点,建筑面积4702平米,总价68万,我返回链家网查询该套房源发现在网站上他就是这么标价的。而同小区的价格如下所示。

该区域的均价都在 14000元/平米~20000元/平米,所以认为是链家网数据录入出现了问题。我们需要剔除掉该数据。
描述性分析
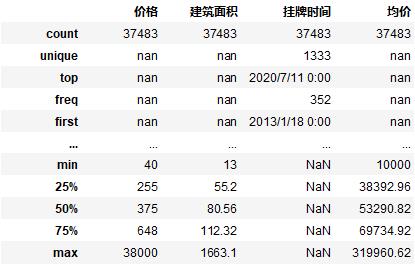
1、 清洗好后总共剩下 37483 条数据
2、 数据的统计周期是 2013-01-18 2020-07-24
3、 上海目前出售的二手房面积从 13 平米 ~ 1663.1 平米不等
4、 根据爬取数据来看上海最贵的二手房均价为 319960.62 元/平米,整体均价为 56466.26 元/平米
均价超过 30 万元/平米的房源到底在哪里?

可以看到挂牌的四套花园洋房均价超过 30 万元/平米,挂牌时间都已经挺久的了。大家可能对兴国路不大熟悉,但是相信大家在不少拍摄背景为上海的影视剧中都见到过一幢大楼。

没错,就是武康大楼,最早称为“诺曼底公寓”,而我们更喜欢叫它“九层楼”,这已经是清除了电线后的模样,其实我小时候的印象是这样的。

电线编织如蜘蛛网,这才是老底子的上海味道。
“九层楼”所处位置是个六岔路口,大家若要打卡请注意安全不要停留在路中间。旁边的武康路也是一条很有历史底蕴的“名人路”。
热门商圈
hot_list = ['四川北路', '中山公园', '漕河泾', '徐家汇', '陆家嘴', '南京西路',
'南京东路', '人民广场', '淮海中路', '虹桥', '北外滩', '新天地', '静安寺']
hot = data[data['镇'].isin(hot_list)].groupby(by='镇')['均价'].agg(
['mean', 'count']).sort_values(by='count', ascending=True)
pyc.Bar().add_xaxis(hot.index.to_list()).add_yaxis(series_name="", yaxis_data=hot['count'].tolist(), label_opts=opts.LabelOpts(is_show=False)).reversal_axis(
).set_global_opts(title_opts=opts.TitleOpts(title="热门商圈挂牌数", subtitle="崇明区缺少相应房源数据;数据截至2020年7月\\n数据来源:链家网 "), toolbox_opts=opts.ToolboxOpts()).render_notebook()
复制代码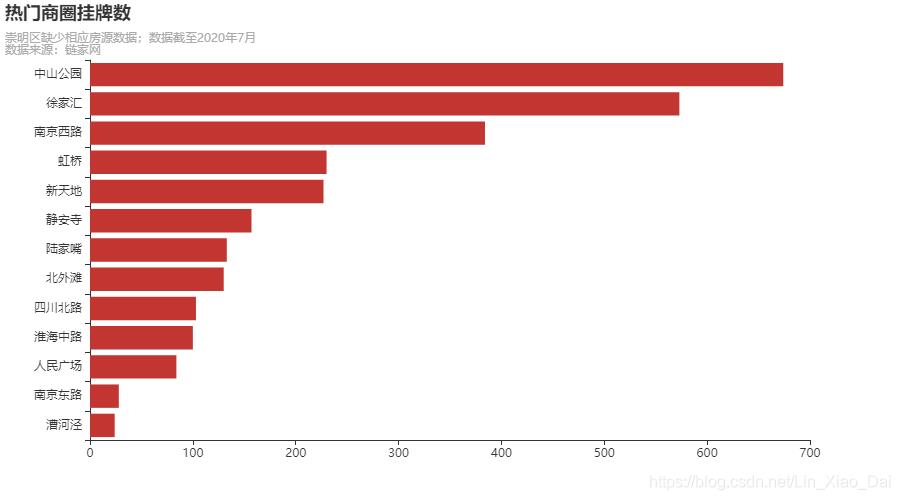
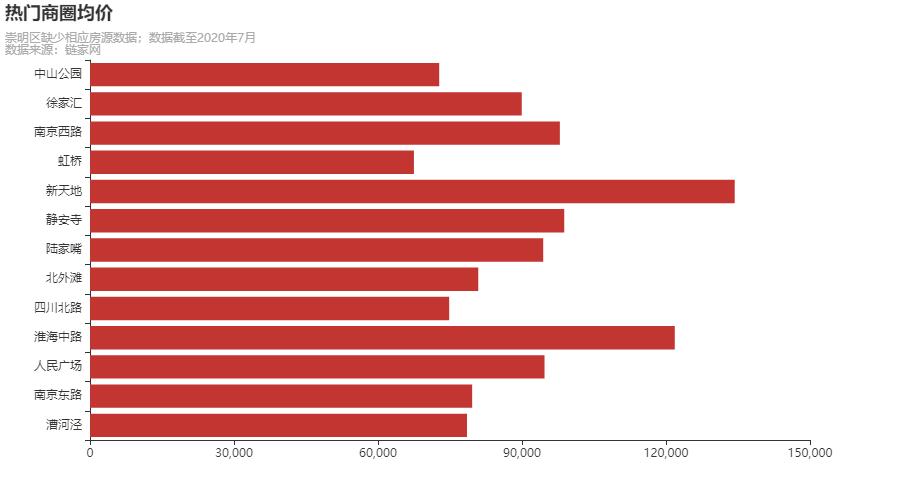
中山公园在售 674 套,均价 72750 元/平米,算是几个地块中比较便宜的了。

户型
huxing = data['房屋户型'].where(data['房屋户型'].isin(
['2室1厅1厨1卫', '1室1厅1厨1卫', '2室2厅1厨1卫', '3室2厅1厨2卫', '3室1厅1厨1卫', '2室1厅1厨2卫']), other='其他', errors='ignore')
pyc.Pie(init_opts=opts.InitOpts(height='600px', width='600px')).add(series_name='房屋户型', data_pair=huxing.value_counts().items(), radius=(100, 150), rosetype="radius", label_opts=opts.LabelOpts(
is_show=True, formatter="{b}\\n{c}套\\n{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="上海二手房挂牌房屋户型", subtitle="崇明区缺少相应房源数据;数据截至2020年7月\\n数据来源:链家网 "), toolbox_opts=opts.ToolboxOpts()).render_notebook()
复制代码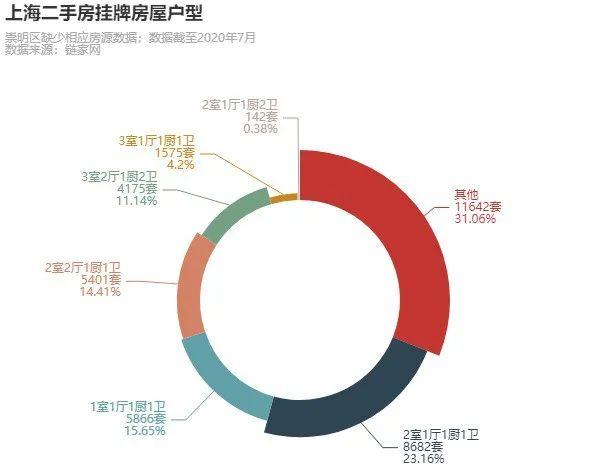
上海二手房挂牌的户型千奇百怪,但还是以两室户居多,一室户偏少。
二手房价位
data['房价分层'] = pd.cut(data['价格'], bins=[-np.inf, 100, 300, 500, 800, 1000, np.inf], right=True,
labels=['100万以内', '100-300万', '300-500万', '500-800万', '800-1000万', '1000万及以上'])
pyc.Pie(init_opts=opts.InitOpts(height='500px', width='500px')).add(series_name="房价", data_pair=data['房价分层'].value_counts().items(), radius=(100, 150), rosetype=True, label_opts=opts.LabelOpts(
formatter="{b}\\n{c}套\\n{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="上海房价分层", subtitle="崇明区缺少相应房源数据;数据截至2020年7月\\n数据来源:链家网 "), toolbox_opts=opts.ToolboxOpts()).render_notebook()
复制代码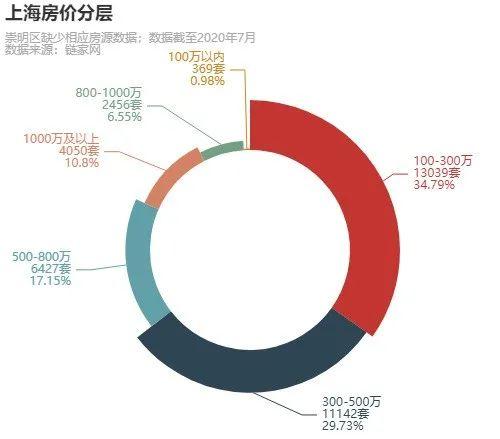
100 万以内想在上海买套房基本是不可能的了。可以往鹤岗考虑一下。同志们努把力,100-300 万有 13000 多套房源等着你!
房屋所属环线
pyc.Pie(init_opts=opts.InitOpts(height='500px', width='500px')).add(series_name="环线", data_pair=data['环'].replace("", "暂无数据").value_counts().items(), radius=(100, 150), rosetype=True, label_opts=opts.LabelOpts(
formatter="{b}\\n{c}套\\n{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="二手房所属环线", subtitle="崇明区缺少相应房源数据;数据截至2020年7月\\n数据来源:链家网 "), toolbox_opts=opts.ToolboxOpts()).render_notebook()
复制代码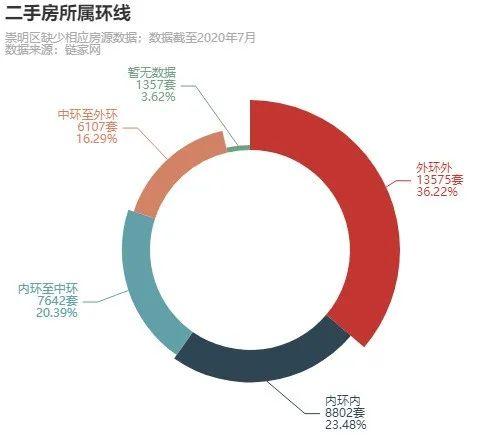
外环外的房源明显是最多的,很可能是外环外房价偏低,所以比较火热吧,我们继续向下看。
上海均价地图
pyc.Map(init_opts=opts.InitOpts(height='500px', width='500px')).add(maptype="上海", series_name="均价", data_pair=[list(i) for i in data[data['挂牌时间'].dt.year == 2020].groupby(by=['区'])['均价'].mean().apply(round).items()], is_map_symbol_show=False, is_selected=True, label_opts=opts.LabelOpts(
is_show=False)).set_global_opts(tooltip_opts=opts.TooltipOpts(formatter="{b}:{c}元/平米"), visualmap_opts=opts.VisualMapOpts(max_=100000, pos_right='5%', pos_bottom='20%', is_calculable=True), title_opts=opts.TitleOpts(title="2020年上半年上海二手房均价图", subtitle="崇明区缺少相应房源数据;数据截至2020年7月\\n数据来源:链家网 "), toolbox_opts=opts.ToolboxOpts(), legend_opts=opts.LegendOpts(is_show=False)).render_notebook()
复制代码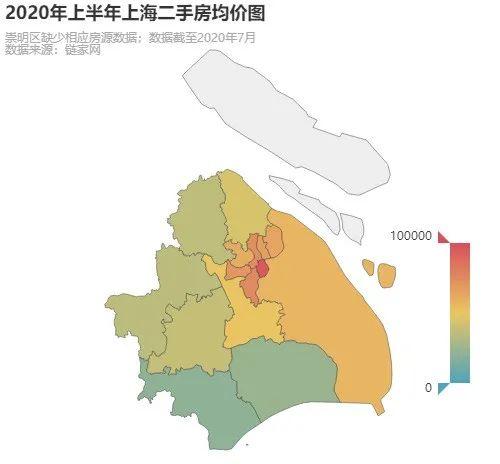
看看中间那红彤彤的区域,市中心的价格远远高于市区外。
挂牌量
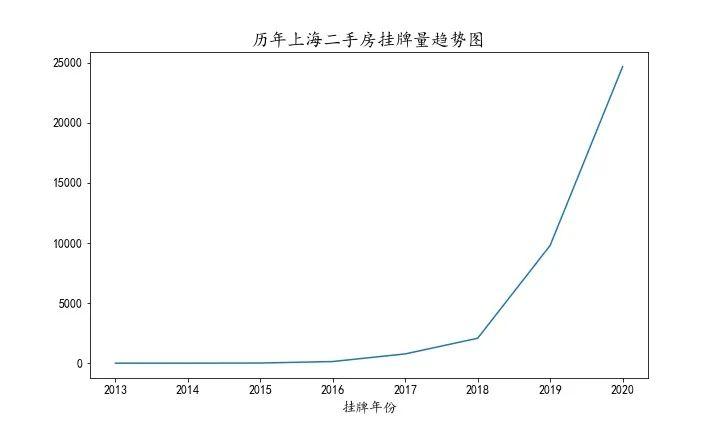
虽然从上图来看上海二手房挂牌量逐年递增,但是考虑到数据爬取日期为2020年7月23日,可能前些年挂牌的二手房已经出售,所以爬取不到挂牌信息。故不能由此判断今年二手房市场较往年更活跃。
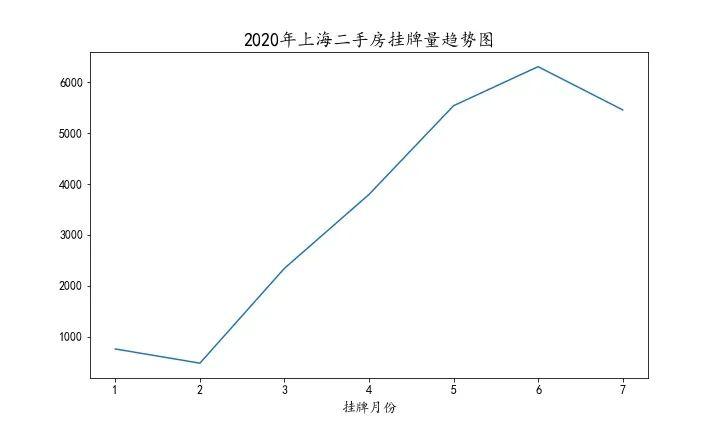
今年一二月受疫情影响,上海二手房挂牌量较低,随着疫情情况缓和,从三月起上海二手房挂牌量逐渐增加。2020年上半年6月份的挂牌量是最大的。
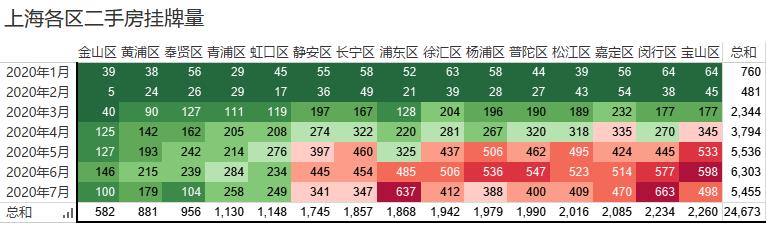
从交叉表来看,2020年1月1日至2020年7月23日链家网上已经挂牌 24673 套二手房。其中嘉定、闵行、宝山等区的抛压较大,7月浦东的挂牌量激增。
所以验证了上面外环外抛售房源较多的现象。
均价
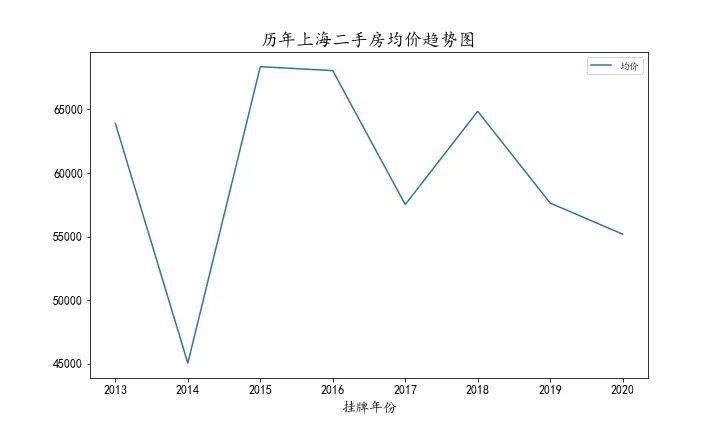
虽然上海房价呈现着下跌趋势,但我还是买不起。
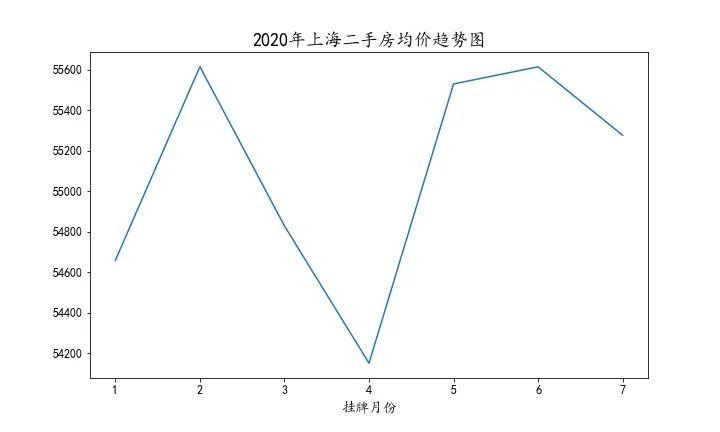
2020年上半年上海二手房均价在55100元/平米附近波动,4月份更是跌至54150元/平米。

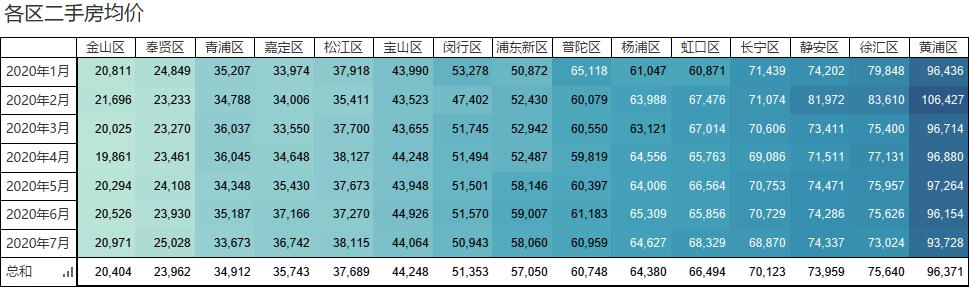
看看这可爱的渐变色,黄浦区这房价,一年赚的钱还不够买个厕所的。
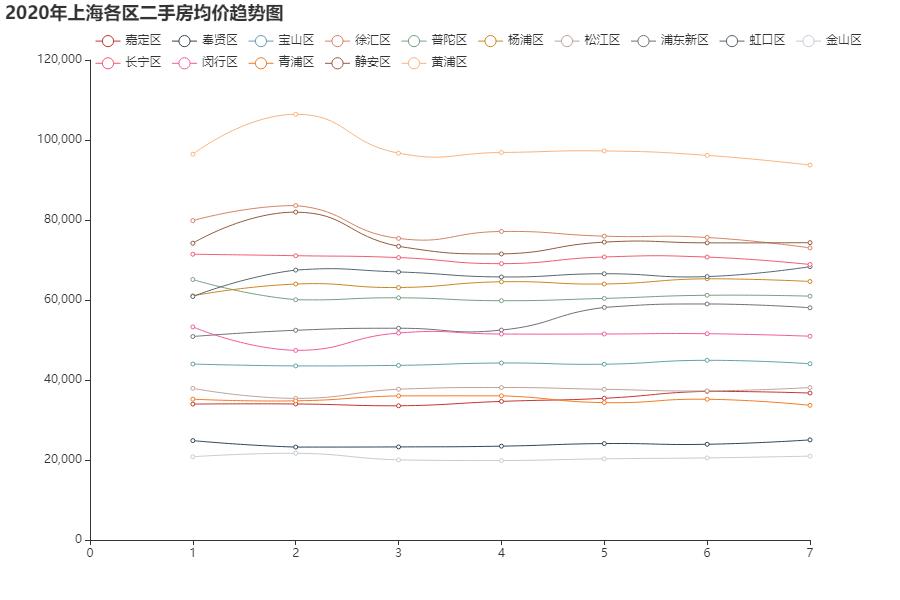
用折线图来看看趋势,好像各区都挺平缓的,浦东新区倒是在四月份之后有所上涨,虹口区在七月也有一小波上涨。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!
总结
1、 2020年上半年上海二手房挂牌量稳步上涨,均价在55100元/平米附近波动。
2、 除了虹口区以外各区的二手房均价在第二季度都趋于缓和。
3、 100万以下的房源几乎所剩无几,主要价位集中在100-300万。
4、 外环外的房源占比较大,是因为嘉定、闵行、宝山等区的挂牌量较高。
5、 单身贵族喜欢的一室一厅房源仅剩下15.65%,连二手房房型的意思都是叫你赶紧找对象!
最后:【可能给予你帮助】然后下面分享一些我的自学资料,希望可以帮到大家。
这份资料整体是围绕着【软件测试】来进行整理的,主体内容包含:python自动化测试专属视频、Python自动化详细资料、全套面试题等知识内容。对于软件测试的的朋友来说应该是最全面和完整的备战仓库了,这个仓库也陪伴我走过了很多坎坷的路,希望也能帮助到你。加入软件测试交流qq群:175317069,就可以直接获取了最后呢,感谢相遇,感谢缘分,感谢支持,感谢选择,感谢信任。
以上是关于利用 Python 爬取了 37483 条上海二手房信息,我得出的结论是?的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫爬取人人车(二手车)利用padasmatplotlib生成图表
用Python爬取了几千条相亲文案,终于发现了告别单身的秘密