二叉搜索树(KV模型,二叉搜索树删除节点)
Posted 楠c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉搜索树(KV模型,二叉搜索树删除节点)相关的知识,希望对你有一定的参考价值。
目录
1. 二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树
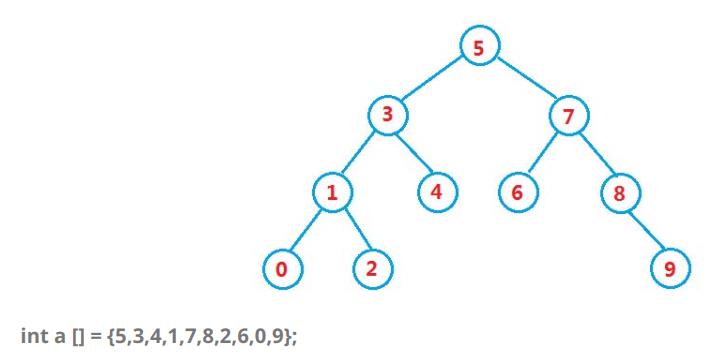
每个子树均满足这个特征。
他可以用来搜索,在我们以前怎么搜索呢,之前的数据结构不仅能存储数据,也能查找数据。最优搜索便是二分查找,但是二分查找前提必须有序,最快的一个排序也是n*logn,并且二分查找必须要在Vector中,头插,中间插,头删,中间删的挪动数据的复杂度也很高。他是一种华而不实的查找方式。而二叉搜索树是一个非常适合用于查找的结构,复杂度为(O(logN)-O(N)之间),最坏是找高度次,而且他天然的一个特性,中序遍历为有序。
2. 二叉搜索树的实现
2.1 插入
插入,大于就去右子树比较,小于就去左子树在比较。需要保证搜索树的性质。
怎么保证呢,我们维护两个节点,parent和cur,在每次走之前,parent保存这次的位置,当key大于当前节点,cur往右走,当key小于当前节点,cur往右走。不允许相等,假如相等直接返回false,cur一直走,当节点为空的时候,再拿key和parent节点的值进行比较,如果小于parent对应的值,则连接在左边,否则连接在右边。
插入的时间复杂度,最坏是O(N),注意别和,完全二叉树和满二叉树搞混了,因为他可能是单支结构。
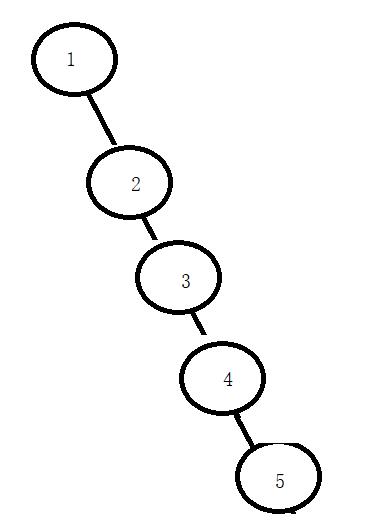
所以他不在极端情况下是比链表顺序表要优一些,但是极端情况也只是相同O(N)。所以基于搜索二叉树上又加了一层平衡,比较均匀高度就是可控的,平衡搜索二叉树接近O(logN),看做O(logN)
2.2 查找
明白了二叉搜索树的性质之后,查找也是容易了许多。
当前树不为空
只要给定值大于当前节点的值,往右走,小于当前节点的值往左走,等于就返回这个节点。
当前树为空
返回空值
时间复杂度
最坏与链表相同O(N),假如是优化后的平衡搜索二叉树近似于O(logN)
2.3 遍历
这里我们采用中序,因为它的性质给他带来一种天然的属性,中序遍历的时候是有序的。
左—根---右
这里有个编码的小tips,假如成员函数是递归函数,你要用到私有的成员变量。

但是你在main函数中,无法调用因为你访问不到,私有的root节点。
这时我们可以写一个函数获取root节点,但是这样不好看。我们将这个递归函数做再一次的封装。

这样就好看多了。
打印出来是有序的。
2.4 删除
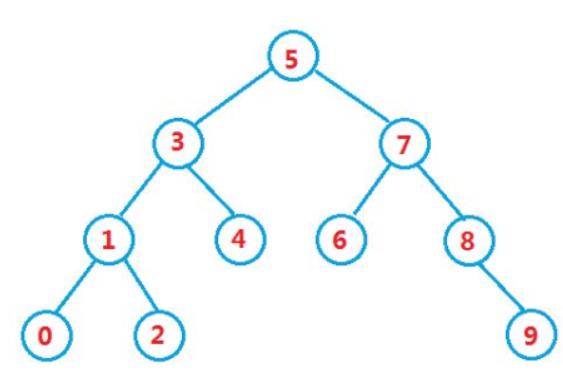
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
a. 要删除的结点无孩子结点
b. 要删除的结点只有左孩子结点
c. 要删除的结点只有右孩子结点
d. 要删除的结点有左、右孩子结点(剩余节点)
2.5 被删除节点无孩子节点
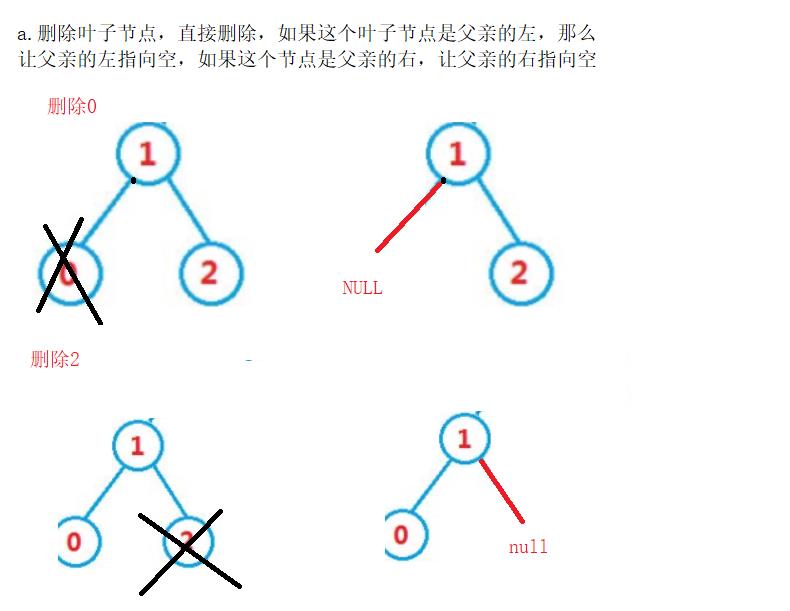
2.6 被删除节点只有右孩子(左边为空)

假如要删头,就是一个右单枝二叉树
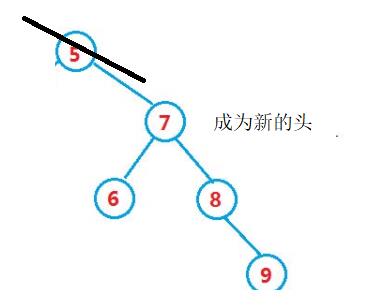
假如被删除节点是父亲的右节点,将被删除节点的右孩子连接父亲的右节点。

假如被删除节点是父亲的左节点,将被删除节点的右孩子连接至父亲的左节点

2.7 被删除节点只有左孩子(右边为空)
和左边为空的逻辑,一模一样。相对的需要注意左单枝二叉树
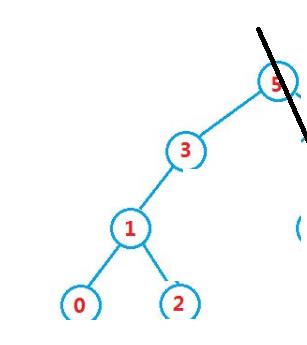
2.8 归纳
叶子节点就可以看做,左右为空的任意情况之一,在其中一并判断。
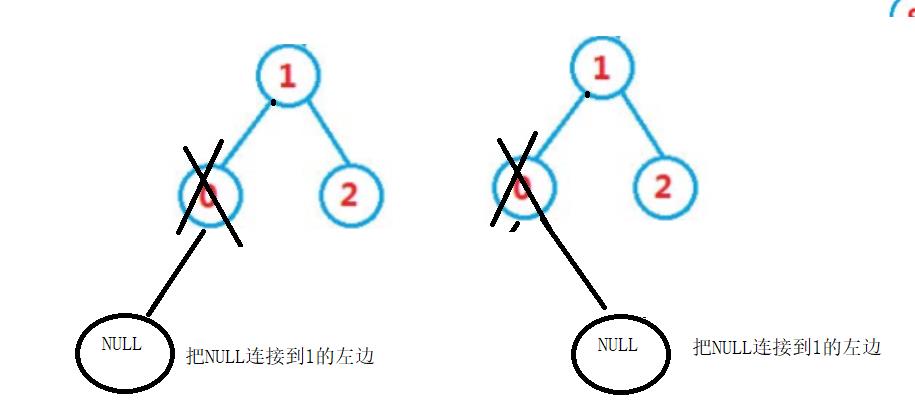
无论将它看做左为空,还是右为空,逻辑都是可以处理。
2.9 被删除节点,左右都不为空
首先这个节点删除不能影响它的性质,直接删除掉,后续的节点怎么连起来呢,很难处理。
所以我们思路得变成,在树中找一个合适的节点,将它覆盖掉。同时又可以保证它的性质不变。
经过研究,我们可以取,被删除节点的,左子树最大值或者右子树最小值。将要删除的节点覆盖。同时可以保证它的性质。
怎么找出左子树的最大值呢?
由于其子树也满足二叉搜索树的性质,所以就是左子树的最右节点。
为什么左子树最大值可以呢?
因为覆盖删除节点的值无非满足两个条件,第一,小于右孩子,第二,大于左孩子。
从左子树挑选,不会出现大于右孩子的(有就不是二叉搜索树了)肯定是小于右孩子的,满足条件1。
但是还要大于左孩子,就需要挑选左子树的最大值即最右节点,才能保证替换后的值大于左子树中的所有值。找到了最右节点,不管是不是叶子节点,他一定是一个右为空的节点(假如右边还有,那他就不是最右了)。
怎么找出右子树的最小值?
由于其子树也满足二叉搜索树的性质,所以就是右子树的最左节点。
为什么右子树的最小值可以呢?
两个条件,第一,小于右孩子,第二,大于左孩子。
从右子树选,一定大于左孩子,而且选的是最小值,所以一定小于右孩子。
同时选定的一定是一个左为空的节点。
示例1
删除6,以找右子树最小值(右子树的最左)为例。
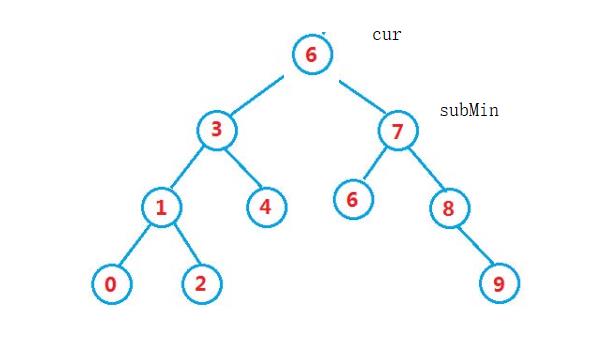
当subMin->left为空停止
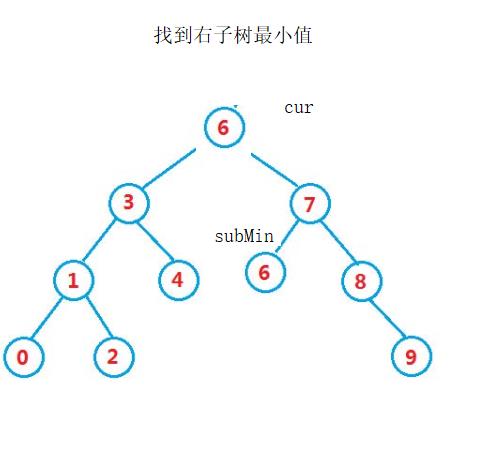
把subMin->_key赋值给cur->_key。
由于要删除,所以需要一个smParent,在他每次循环下去,判断其左是否为空时,保存他的上一个
这种情况下,smParent初始值为null没有问题,因为循环下去就会被重新赋值。
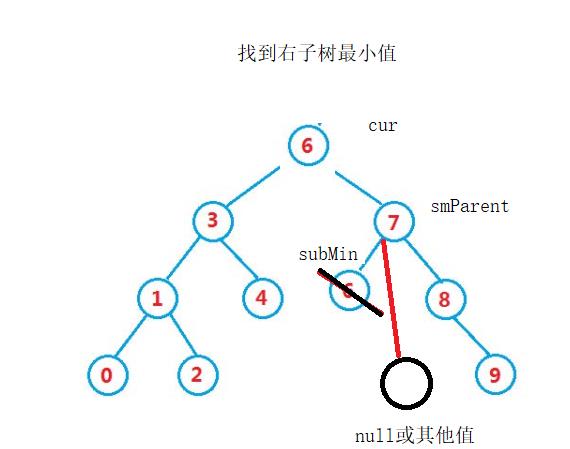
删除掉subMin,subMin左边一定为空,右边不一定,由于subMin是smParent的左,所以需要smParent的左连接subMin的右。
示例2
还有隐藏的一个问题,父亲节点不能声明为nullptr,在这种情况下
删除7,找7的右子树最小值。
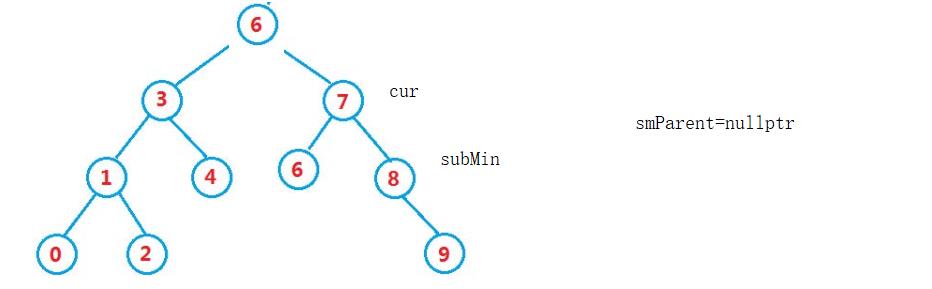

由于一开始,subMin->left就等于nullptr,所以没有循环进入赋值。后面if语句里还对smParent进行了操作,空指针异常,所以smParent要声明为cur。
3 K模型与KV模型
搜索树,真正的作用是排序。它分为两种模型。
K搜索模型对应STL中的Set,他只有一个值
K-value搜索模型对应STL的map,它存储两个值。
3.1 K模型
K搜索模型,他用来查找“在不在”的问题,例如门禁,在刷卡期间,门禁机器识别你的学号,他就去查找存储结构中你的信息,从而判断。
而且还被用来做排序和去重,当中序的时候天然有序,重复的数据直接不插入
3.2 K模型搜索树实现代码
#include<iostream>
using namespace std;
#pragma once
//K,键值
template<class K>
struct BSTreeNode
{
K _key;
struct BSTreeNode<K>* _left;
struct BSTreeNode<K>* _right;
BSTreeNode(const K& k)
:_key(k)
,_left(nullptr)
,_right(nullptr)
{}
};
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
//插入
bool Insert(const K& val)
{
if (_root == nullptr)
{
_root = new Node(val);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (val > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if(val < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
//走到这,说明cur为空,parent为他的上一个节点。
//确定了他的位置,开始和父亲比较,看放左边还是右边
Node* newNode = new Node(val);
if (val > parent->_key)
{
parent->_right = newNode;
}
else//不存在等于情况,等于的话在前面肯定返回false了
{
parent->_left = newNode;
}
return true;
}
//查找(K不允许修改)
const Node* Find(const K& key)
{
Node* cur = root;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key == cur->_key)
{
return cur;
}
else
{
cur = cur->_left;
}
}
return nullptr;
}
//删除
bool Erase(const K& val)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (val > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (val<cur->_key)
{
parent = cur;
cur = cur->_left;
}
else//找到了,准备删除逻辑
{
//删除节点左边为空(只有右孩子)
if (cur->_left == nullptr)
{
//假如要删头,而且头的左边为空(上面的条件),就成右单支了
if (cur == _root)
{
_root = cur->_right;
}
else
{
//先看他自己在哪,父亲的左还是右
//他在父亲的左边,要把他的孩子放左边
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
//他在父亲的右边要把他的孩子放右边
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
//删除节点右边为空(只有左节点)
else if (cur->_right==nullptr)
{
if (cur == _root)
{
cur->_left = _root;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
//两边都有节点
//右子树最小值(最左)为例
else
{
Node* cur = _root;
Node* subMin = cur->_right;
Node* smParent = cur;
while (subMin->_left)
{
smParent = subMin;
subMin = subMin->_left;
}
//覆盖
cur->_key = subMin->_key;
//子树的最左节点,父亲根据subMin在哪一边,连接他的右
if (subMin == smParent->_left)
{
//subMin可以看做左为空
//连上他的右
smParent->_left = subMin->_right;
}
else
{
smParent->_right = subMin->_right;
}
delete subMin;
}
return true;
}
}
return false;
}
//用来递归的子结构
void _Inorder(Node* root)
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key<<" ";
_Inorder(root->_right);
}
//封装起来让外面可以调用
void Inorder()
{
_Inorder(_root);
cout << endl;
}
private:
Node* _root = nullptr;
};
#include"BSTree.hpp"
#include"BSTree.hpp"
int main()
{
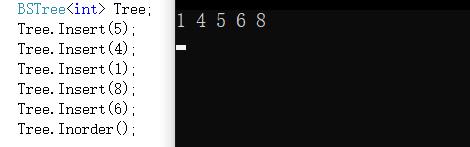
BSTree<int> Tree;
Tree.Insert(5);
Tree.Insert(4);
Tree.Insert(1);
Tree.Insert(8);
Tree.Insert(6);
Tree.Inorder();
Tree.Erase(4);
Tree.Inorder();
Tree.Erase(5);
Tree.Inorder();
Tree.Erase(8);
Tree.Inorder();
return 0;
}
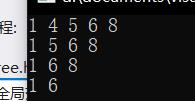
3.3 KV模型
K-value,字典模型,输入英文查找中文。
当你插入一个英文(K)的时候,对应的中文(val)也被插入。
相比于K模型,代码逻辑不变,还是以K为依据。将Find中的const去掉,因为Value是可以改变的。然后K值不变,声明的时候加上const。
他依旧可以,1. 查找在不在,2. 排序+去重。
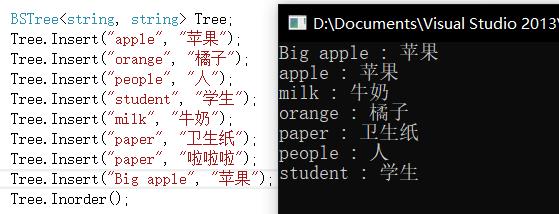
3. 最关键的是他具有字典的特征:
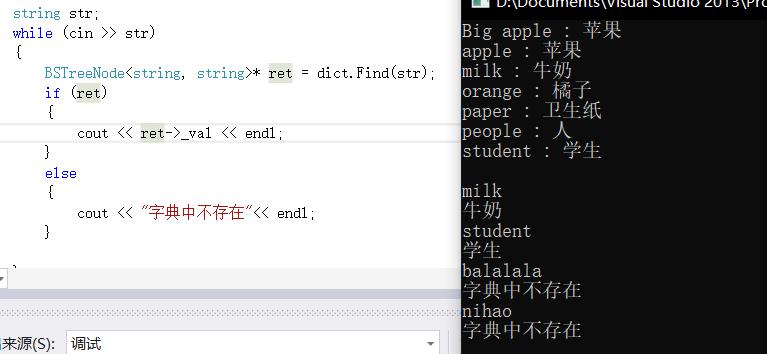
4.统计出现次数
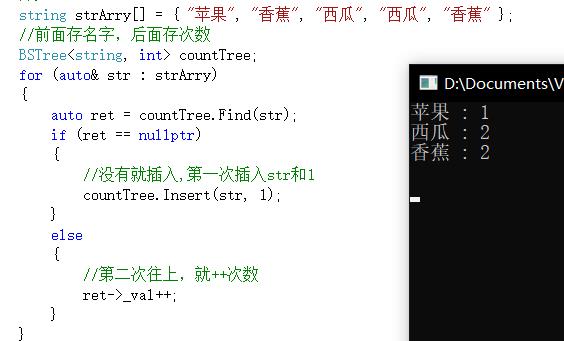
3.4 KV模型搜索树实现代码
#include<iostream>
using namespace std;
#pragma once
//K,键值
template<class K,class V>
struct BSTreeNode
{
const K _key;
V _val;
struct BSTreeNode<K,V>* _left;
struct BSTreeNode<K,V>* _right;
BSTreeNode(const K& k,const V& v)
:_key(k)
, _val(v)
,_left(nullptr)
,_right(nullptr)
{}
};
template<class K,class V>
class BSTree
{
typedef BSTreeNode<K,V> Node;
public:
bool Insert(const K& key,const V& val)
{
if (_root == nullptr)
{
_root = new Node(key,val);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if(key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
//走到这,说明cur为空,parent为他的上一个节点。
//确定了他的位置,开始和父亲比较,看放左边还是右边
Node* newNode = new Node(key,val);
if (key > parent->_key)
{
parent->_right = newNode;
}
else//不存在等于情况,等于的话在前面肯定返回false了
{
parent->_left = newNode;
}
return true;
}
//不允许改
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key == cur->_key)
{
return cur;
}
else
{
cur = cur->_left;
}
}
return nullptr;
}
//用来递归的子结构
void _Inorder(Node* root)
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key<<" : "<<root->_val;
cout << endl;
_Inorder(root->_right);
}
//封装起来让外面可以调用
void Inorder()
{
_Inorder(_root);
cout << endl;
}
private:
Node* _root = nullptr;
};
#include"BSTree.hpp"
#include<string>
int main()
{
/*BSTree<string, string> dict;
dict.Insert("apple", "苹果");
dict.Insert("orange", "橘子");
dict.Insert("people", "人");
dict.Insert("student", "学生");
dict.Insert("milk", "牛奶");
dict.Insert("paper", "卫生纸");
dict.Insert("paper", "啦啦啦");
dict.Insert("Big apple", "苹果");
dict.Inorder();*/
//string str;
//while (cin >> str)
//{
// BSTreeNode<string, string>* ret = dict.Find(str);
// if (ret)
// {
// cout << ret->_val << endl;
// }
// else
// {
// cout << "字典中不存在"<< endl;
// }
//
//}
string strArry[] = { "苹果", "香蕉", "西瓜", "西瓜", "香蕉" };
//前面存名字,后面存次数
BSTree<string, int> countTree;
for (auto& str : strArry)
{
auto ret = countTree.Find(str);
if (ret == nullptr)
{
//没有就插入,第一次插入str和1
countTree.Insert(str, 1);
}
else
{
//第二次往上,就++次数
ret->_val++;
}
}
countTree.Inorder();
return 0;
}
以上是关于二叉搜索树(KV模型,二叉搜索树删除节点)的主要内容,如果未能解决你的问题,请参考以下文章