Day19:业务分析_意向与报名主题
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day19:业务分析_意向与报名主题相关的知识,希望对你有一定的参考价值。
- 知识点01:回顾
- 知识点02:目标
- 知识点03:意向数仓构建:DWS
- 知识点04:意向数仓构建:APP
- 知识点05:拉链表:设计
- 知识点06:拉链表:流程
- 知识点07:拉链表:实现
- 知识点7.5:模拟拉链表的实现
- 知识点08:报名业务需求
- 知识点09:报名数据来源
- 知识点10:报名数仓设计:ODS与DIM
- 知识点11:报名数仓设计:DWD与DWM
- 知识点12:报名数仓设计:DWS与APP
- 知识点13:Hive优化:Hive索引
- 知识点14:Hive优化:ORC索引
- 知识点15:Hive优化:小文件处理
- 知识点16:Hive优化:其他属性优化
- 知识点17:报名数仓实现:ODS与DIM
- 知识点18:报名数仓实现:DWD
- 知识点19:报名数仓实现:DWM
- 知识点20:报名数仓实现:DWS
- 知识点21:报名数仓实现:APP
- 知识点22:报名数仓实现:导出
- 知识点22:报名数仓实现:导出
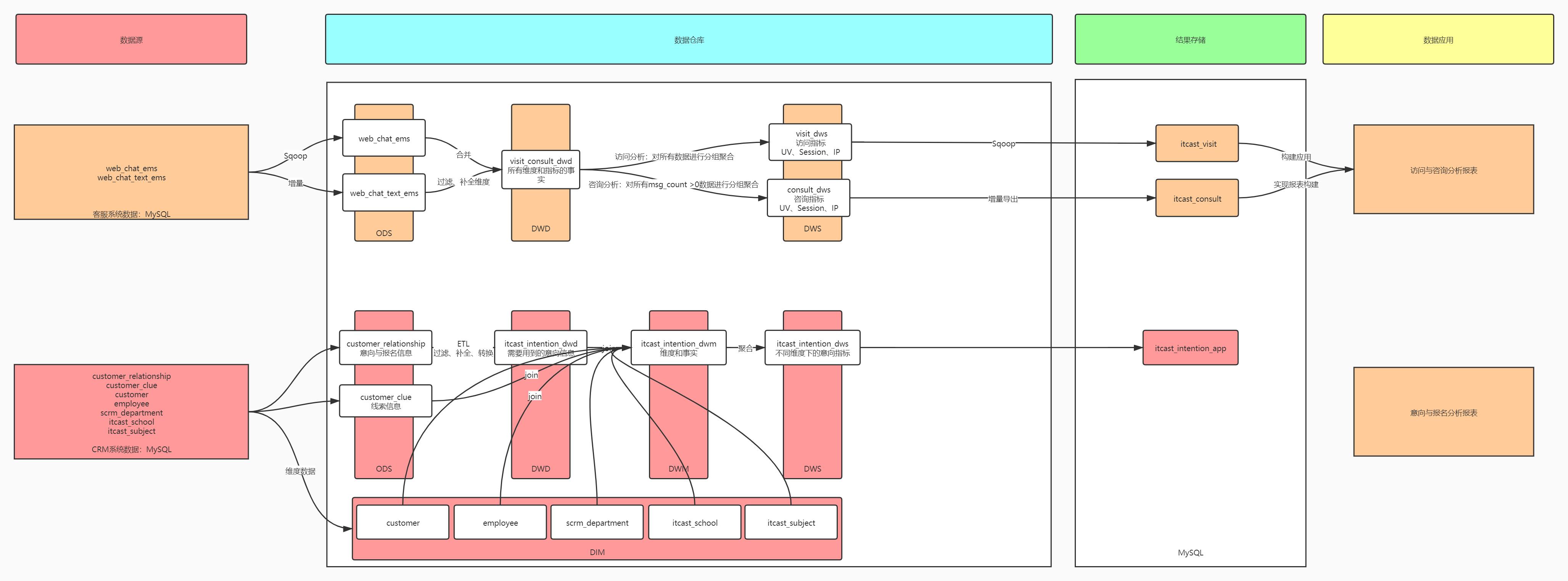
知识点01:回顾
-
意向与报名业务需求中有哪些指标与维度?
- 指标:意向人数、报名人数、报名率
- 维度:时间、线上线下、新老学员、地区、来源渠道、校区、学科、咨询中心
-
意向与报名的数据的数据来源是什么?有哪些表与核心的字段?
- 数据来源:CRM系统、mysql数据库
- 表和字段
- customer_relationship:意向信息表
- id:意向id
- customer_id:学员id
- create_date_time:时间维度
- orgin_type:线上线下
- origin_channel:来源渠道
- itcast_school_id:校区id
- itcast_subject_id:学科id
- creator:销售的id
- customer:学员信息表
- id:学员id
- area:地区维度
- itcast_school:校区信息表
- id:校区id
- name:校区名称
- itcast_subject:学科信息表
- id:学科id
- name:学科名称
- employee:员工信息表
- 通过员工表获取员工所在的部门id
- id:员工id
- tdepart_id:部门id
- scrm_deparment:部门信息表
- id:部门id
- name:部门名称
- customer_clue:线索信息表
- customer_relationship_id:意向id
- clue_stat:新老学员维度
- customer_relationship:意向信息表
-
意向与报名的数据仓库如何分层及每一层实现的功能是什么?
- ODS:存储原始事务事实表
- customer_relationship
- custom_clue
- DIM:存储维度信息表
- DWD:实现对ODS的数据ETL
- step1:过滤
- step2:补全
- step3:转换
- DWM:将所有维度与事实合并到一张表中
- 所有表的join过程
- DWS:实现基于各个维度的分组聚合得到指标
- ODS:存储原始事务事实表
-
分桶的功能是什么?如何实现分桶采样与分桶Join?
- 功能
- 分桶Join:本质就是多个Reduce将数据划分到多个文件中
- 分桶采样:tablesample(bucket x out of y )
- x:桶的编号
- y:分桶因子
- Bucket Join
- 分类
- 普通的Bucket Join:custered by col into N bucket
- SMB Join :custered by col sorted by col into N bucket
- 要求
- Hive会根据参数属性自动判断是否满足分桶Join的条件
- 自己必须维护两张表为桶表
- 分桶字段必须为关联字段、SMB必须为排序字段
- 桶的个数必须成倍数
- 应用
- 适合于多次的大表join大表的场景
- 分类
- 功能
知识点02:目标
- 意向分析的DWS构建
- DWS分组聚合
- APP层导出
- 拉链表的构建【重点】
- 场景
- 流程
- 实现
- 为什么要构建拉链表?怎么构建拉链表?
- 报名业务分析及实现
- 数据来源
- 数仓设计
- 数仓实现
- Hive优化
- 索引优化:Hive本身的索引、ORC文件
- 小文件处理
- 其他属性:零拷贝机制、矢量化查询
知识点03:意向数仓构建:DWS
-
目标:实现意向数据仓库DWS层的构建(聚合dwm层的结果即可)
-
实施
-
分析
-
DWM
时间 地区 来源渠道 线上线下 新老学员 校区 学科 部门 学员id -
DWS
时间 地区 来源渠道 线上线下 新老学员 校区 学科 部门 学员个数 groupType timeType- 维度
- 基本维度:时间 + 线上线下 + 新老学员
- 组合维度:其他维度
- 维度
-
-
建表
- 别用这张表,用下面的那张表
drop Table if exists itcast_dws.itcast_intention_dws; CREATE TABLE IF NOT EXISTS itcast_dws.itcast_intention_dws ( `customer_total` INT COMMENT '聚合意向客户数', `area` STRING COMMENT '区域信息', `itcast_school_id` STRING COMMENT '校区id', `itcast_school_name` STRING COMMENT '校区名称', `origin_type` STRING COMMENT '来源渠道', `itcast_subject_id` STRING COMMENT '学科id', `itcast_subject_name` STRING COMMENT '学科名称', `hourinfo` STRING COMMENT '小时信息', `origin_type_stat` STRING COMMENT '数据来源:0.线下;1.线上', `clue_state_stat` STRING COMMENT '客户属性:0.老客户;1.新客户', `tdepart_id` STRING COMMENT '创建者部门id', `tdepart_name` STRING COMMENT '咨询中心名称', `time_str` STRING COMMENT '时间明细', `groupType` STRING COMMENT '产品属性类别:1.总意向量;2.区域信息;3.校区 4.学科;5.来源渠道;6.贡献中心;', `time_type` STRING COMMENT '时间维度:1、按小时聚合;2、按天聚合;3、按周聚合;4、按月聚合;5、按年聚合;' ) comment '客户意向dws表' PARTITIONED BY(yearinfo STRING,monthinfo STRING,dayinfo STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' stored as orc location '/user/hive/warehouse/itcast_dws.db/itcast_intention_dws'; TBLPROPERTIES ('orc.compress'='SNAPPY');drop Table if exists itcast_dws.itcast_intention_dws; CREATE TABLE IF NOT EXISTS itcast_dws.itcast_intention_dws ( `customer_total` INT COMMENT '聚合意向客户数', `area` STRING COMMENT '区域信息', `itcast_school_id` STRING COMMENT '校区id', `itcast_school_name` STRING COMMENT '校区名称', `origin_type` STRING COMMENT '来源渠道', `itcast_subject_id` STRING COMMENT '学科id', `itcast_subject_name` STRING COMMENT '学科名称', `hourinfo` STRING COMMENT '小时信息', `origin_type_stat` STRING COMMENT '数据来源:0.线下;1.线上', `clue_state_stat` STRING COMMENT '客户属性:0.老客户;1.新客户', `tdepart_id` STRING COMMENT '创建者部门id', `tdepart_name` STRING COMMENT '咨询中心名称', `time_str` STRING COMMENT '时间明细', `groupType` STRING COMMENT '产品属性类别:1.总意向量;2.区域信息;3.校区 4.学科;5.来源渠道;6.贡献中心;', `time_type` STRING COMMENT '时间维度:1、按小时聚合;2、按天聚合;3、按周聚合;4、按月聚合;5、按年聚合;' ) comment '客户意向dws表' PARTITIONED BY(yearinfo STRING,monthinfo STRING,dayinfo STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'; -
实现
-
时间
-
小时
--内存检查 set yarn.nodemanager.pmem-check-enabled=false; set yarn.nodemanager.vmem-check-enabled=false; set yarn.nodemanager.vmem-pmem-ratio=4; --分区 SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions.pernode=10000; set hive.exec.max.dynamic.partitions=100000; set hive.exec.max.created.files=150000; --hive压缩 set hive.exec.compress.intermediate=true; set hive.exec.compress.output=true; --写入时压缩生效 set hive.exec.orc.compression.strategy=COMPRESSION; --分桶 set hive.enforce.bucketing=true; set hive.enforce.sorting=true; set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, hourinfo, origin_type_stat, clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str, '1' as grouptype, '1' as time_type, yearinfo, monthinfo, dayinfo from itcast_dwm.itcast_intention_dwm dwm group by yearinfo, monthinfo, dayinfo, hourinfo, origin_type_stat, clue_state_stat; -
天
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, origin_type_stat, clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str, '1' as grouptype, '2' as time_type, yearinfo, monthinfo, dayinfo from itcast_dwm.itcast_intention_dwm dwm group by yearinfo, monthinfo, dayinfo, origin_type_stat, clue_state_stat; -
月
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, origin_type_stat, clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo,'-',monthinfo) as time_str, '1' as grouptype, '4' as time_type, yearinfo, monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by yearinfo, monthinfo, origin_type_stat, clue_state_stat; -
年
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, origin_type_stat, clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo) as time_str, '1' as grouptype, '5' as time_type, yearinfo, '-1' as monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by yearinfo, origin_type_stat, clue_state_stat;
-
-
时间+校区
-
年
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, itcast_school_id, itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, '-1' as origin_type_stat, '-1' as clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo) as time_str, '3' as grouptype, '5' as time_type, yearinfo, '-1' as monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by itcast_school_id, itcast_school_name, yearinfo;
-
-
时间+学科
-
年
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' as itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, itcast_subject_id, itcast_subject_name, '-1' as hourinfo, '-1' as origin_type_stat, '-1' as clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo) as time_str, '4' as grouptype, '5' as time_type, yearinfo, '-1' as monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by itcast_subject_id, itcast_subject_name, yearinfo;
-
-
时间+渠道
-
年
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' as itcast_school_id, '-1' as itcast_school_name, origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, '-1' as origin_type_stat, '-1' as clue_state_stat, '-1' as tdepart_id, '-1' as tdepart_name, concat(yearinfo) as time_str, '5' as grouptype, '5' as time_type, yearinfo, '-1' as monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by origin_type, yearinfo;
-
-
时间+咨询中心
-
年
insert into itcast_dws.itcast_intention_dws partition (yearinfo, monthinfo, dayinfo) select count(distinct customer_id) as customer_total, '-1' as area, '-1' as itcast_school_id, '-1' as itcast_school_name, '-1' as origin_type, '-1' as itcast_subject_id, '-1' as itcast_subject_name, '-1' as hourinfo, '-1' as origin_type_stat, '-1' as clue_state_stat, tdepart_id, tdepart_name, concat(yearinfo) as time_str, '6' as grouptype, '5' as time_type, yearinfo, '-1' as monthinfo, '-1' as dayinfo from itcast_dwm.itcast_intention_dwm dwm group by tdepart_id,tdepart_name, yearinfo;
-
-
-
-
小结
- 实现意向数据仓库DWS层的构建
知识点04:意向数仓构建:APP
-
目标:实现意向数据仓库APP层的构建
-
实施
-
分析
- 实现将分析的结果,导出到MySQL中
-
建表
use scrm_bi; drop table if exists itcast_intention_app; CREATE TABLE itcast_intention_app ( `customer_total` int(11) COMMENT '聚合意向客户数', `area` varchar(32) COMMENT '区域信息', `itcast_school_id` varchar(32) COMMENT '校区id', `itcast_school_name` varchar(32) COMMENT '校区名称', `origin_type` varchar(32) COMMENT '来源渠道', `itcast_subject_id` varchar(32) COMMENT '学科id', `itcast_subject_name` varchar(32) COMMENT '学科名称', `hourinfo` varchar(32) COMMENT '小时信息', `origin_type_stat` varchar(32) COMMENT '数据来源:0.线下;1.线上', `clue_state_stat` varchar(32) COMMENT '客户属性:0.老客户;1.新客户', `tdepart_id` varchar(32) COMMENT '创建者', `tdepart_name` varchar(32) COMMENT '咨询中心名称', `time_str` varchar(32) COMMENT '时间明细', `groupType` varchar(32) COMMENT '产品属性类别:1.总意向量;2.区域信息;3.校区 4.学科;5.来源渠道;6.贡献中心', `time_type` varchar(32) COMMENT '聚合时间类型:1、按小时聚合;2、按天聚合;3、按周聚合;4、按月聚合;5、按年聚合;', `dayinfo` varchar(32) COMMENT '日信息', `monthinfo` varchar(32) COMMENT '月信息', `yearinfo` varchar(32) COMMENT '年信息' )ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; -
实现
sqoop export \\ --connect "jdbc:mysql://node3:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \\ --username root \\ --password '123456' \\ --driver com.mysql.jdbc.Driver \\ --table itcast_intention_app \\ --hcatalog-database itcast_dws \\ --hcatalog-table itcast_intention_dws \\ -m 1
-
-
小结
- 实现意向数据仓库APP层的构建
知识点05:拉链表:设计
-
目标:掌握拉链表的设计
-
实施
-
问题:如果我们已经采集的事务事实的数据维度状态发生了变化,如何解决数据存储的问题?
-
举例
-
2020-01-01
-
MySQL
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已支付 o003 u003 2020-01-01 已支付 -
Hive:空的,第一次搭建数仓平台
-
-
2020-01-02
-
Hive:2020-01-01
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已支付 o003 u003 2020-01-01 已支付
-
-
MySQL
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已发货 o003 u003 2020-01-01 已支付 o004 u004 2020-01-02 已支付- 新增了一条数据:o004
- 更新了一条数据:o002
-
2020-01-03
-
Hive:2020-01-02
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已支付 o003 u003 2020-01-01 已支付
-
-
问题:3号采集2号的数据放入Hive中,2号的数据有新增的数据和更新的数据
-
新增的数据:直接添加表中即可
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已支付 o003 u003 2020-01-01 已支付 o004 u004 2020-01-02 已支付 -
更新的数据:怎么处理?
o002 u002 2020-01-01 已发货
-
-
三种方案
-
SCD1:直接用的状态覆盖老的状态,老的状态的记录就没有了,不选用
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已发货 o003 u003 2020-01-01 已支付 o004 u004 2020-01-02 已支付 -
SCD2:通过时间来标记数据的每个状态,都保存下来
订单id 用户id 创建时间 状态 startTime endTime o001 u001 2020-01-01 已支付 2020-01-01 9999-12-31 o002 u002 2020-01-01 已支付 2020-01-01 2020-01-01 o002 u002 2020-01-02 已发货 2020-01-02 2020-01-02 o002 u002 2020-01-02 已收货 2020-01-03 9999-12-31 o003 u003 2020-01-01 已支付 2020-01-01 9999-12-31 o004 u004 2020-01-02 已支付 2020-01-01 9999-12-31
- 通过时间来标记每个状态的存活周期 - startTime:这个状态的开始时间 - endTime:这个状态的结束时间 - 最新状态的标记:将endTime设置为9999-12-31 23:59:59来标记当前最新状态 -
-
根据时间来获取对应时间范围的状态
- 查询所有数据的最新状态select * from table where endTime = '9999-12-31'
-
SCD3:通过增加列的方式来标记每个状态,一般不选用,用于状态变化时固定的
订单id 用户id 创建时间 状态 历史状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已发货 已支付 o003 u003 2020-01-01 已支付 o004 u004 2020-01-02 已支付
-
-
-
-
小结
- 什么是拉链表?
- 本质:存储所有数据的状态,通过时间来标记数据的不同状态,可以通过时间来获取任意的状态数据
- 什么是拉链表?
知识点06:拉链表:流程
-
目标:掌握拉链表的实现流程
-
实施
-
需求:通过SCD2来解决增量数据更新问题,在Hive中的体现就是拉链表
-
step1:先增量采集,将新增的数据和更新的数据采集保存到一张更新表中
-
update表:存储当前最新的一些数据,要写入数据仓库的更新的数据【新增的数据和更新的数据】
-
举例:
-
MySQL
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已发货 o003 u003 2020-01-01 已支付 o004 u004 2020-01-02 已支付 -
Hive:2020-01-02
订单id 用户id 创建时间 状态 o001 u001 2020-01-01 已支付 o002 u002 2020-01-01 已支付 o003 u003 2020-01-01 已支付 -
Update表中的数据
o002 u002 2020-01-01 已发货 o004 u004 2020-01-02 已支付
-
-
-
step2:将数据仓库中的表与Update表进行合并,得到最新的拉链表,存放在一个临时表:Tmp表
-
TMP表:存储当前数仓中的数据合并完最新的数据生成的最新结果表
订单id 用户id 创建时间 状态 starttime endtime o001 u001 2020-01-01 已支付 2020-01-01 9999-12-31 o002 u002 2020-01-01 已支付 2020-01-01 2020-01-01 o002 u002 2020-01-01 已发货 2020-01-02 9999-12-31 o003 u003 2020-01-01 已支付 2020-01-01 9999-12-31 o004 u004 2020-01-02 已支付 2020-01-02 9999-12-31订单id 用户id 创建时间 状态 startTime endTime o001 u001 2020-01-01 已支付 2020-01-01 9999-12-31 o002 u002 2020-01-01 已支付 2020-01-01 2020-01-01 o002 u002 2020-01-02 已发货 2020-01-02 9999-12-31 o003 u003 2020-01-01 已支付 20以上是关于Day19:业务分析_意向与报名主题的主要内容,如果未能解决你的问题,请参考以下文章
-
-