Day20:业务分析_学员考勤主题
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day20:业务分析_学员考勤主题相关的知识,希望对你有一定的参考价值。
知识点01:回顾
-
拉链表是什么?如何构建拉链表?
- 拉链表:通过时间来标记变化数据的不同状态
- startTime:状态开始时间
- endTime:状态结束时间,最新状态:9999-12-31
- 步骤
- step1:增量采集到更新表:ODS
- step2:更新表与拉链表合并临时表:TMP
- 修改原有拉链表中的数据:数据发生更新的,并且之前是拉链表最新的状态的数据,endTime修改为当前最新的startTime-1
- step3:将最新的拉链数据覆盖到拉链表:DW
- 拉链表:通过时间来标记变化数据的不同状态
-
报名业务的需求有哪些维度与指标?
-
指标:报名人数
-
维度:时间、线上线下、来源渠道、校区、学科、部门
-
-
报名数仓的设计分为几层,每层的功能是什么?
-
ODS:存储原始事务事实表
- customer_relationship
-
DIM:维度数据层
- itcast_clazz:班级信息表
- 校区、学科
- employee和scrm_deparment
- 部门
- itcast_clazz:班级信息表
-
DWD:ETL
- step1:过滤过期的数据,过滤报名数据
- step2:维度退化,支付时间退化年、月、天、小时
-
DWM:实现了事务事实表与所有维度表的关联
- 实现4张表的关联
-
DWS:基于小时维度实现各种组合维度的聚合
-
APP:基于更大时间维度对小时维度的结果直接聚合
-
-
Hive是否支持索引?如何实现的?有什么问题?
-
支持索引机制:0.7 ~ 3.0
-
通过MapReduce将索引数据存储在一张索引表中
- 列的值与文件、在文件中的偏移量映射关系
-
问题:Hive中索引不会自动根据原表的数据进行更新,必须强制手动更新
-
-
ORC文件索引分为几种,各自的应用和特点是什么?
-
row group index:范围匹配、存储列的最大值和最小值
-
bloom filter index:等值匹配、存储列的值
-
-
Hive中小文件如何处理?有哪些特殊的属性优化?
- 小文件处理
- 避免小文件产生:将结果进行小文件合并
- 如果处理小文件:提前对小文件进行聚合再处理
- 特殊属性优化
- 矢量化查询
- 零拷贝
- 关联优化器
- 小文件处理
知识点02:目标
- 学员考勤管理
- 业务需求
- 为什么要做考勤管理的分析?
- 指标与维度分别是什么?
- 数据来源
- 有哪些表,哪些字段?
- 数据仓库设计
- 如何对原始的数据进行处理,得到可以使用的的数据
- 对转换后的数据再进行聚合
- 数据仓库实现
- 业务需求
- Hive中的优化器的选择
- RBO
- CBO
- 练习:有效线索主题
- 基于不同维度统计有效线索的个数
知识点03:学员考勤业务需求
-
目标:掌握学员考勤业务需求
-
路径
- step1:需求
- step2:指标与维度
- step3:数据来源
-
实施
- 需求
- 通过学员的考勤数据来实现基于时间或者班级校区等不同维度下的考勤指标统计
- 发现教学管理中的问题,提升学员学习质量
- 指标与维度
- 指标
- 出勤
- 出勤人数:上课的人数
- 出勤率:上课人数 / 总人数
- 迟到:迟到人数、迟到率
- 请假:请假人数、请假率
- 旷课:旷课人数、旷课率
- 出勤
- 维度
- 时间、班级、校区、学科
- 指标
- 数据来源
- 学员管理系统
- 分析需要的数据
- 打卡数据表:班级id、学员id、打卡时间
- 正常出勤和迟到出勤
- 请假数据表:班级id、学员id、请假开始时间、请假结束时间
- 班级总人数表
- 判断是否是一个有效的出勤或者请假状态:
- 今天不上课
- 打卡时间不是上课时间
- 请假没有被批准
- ……
- 打卡数据表:班级id、学员id、打卡时间
- 需求
-
小结
- 掌握学员考勤业务需求
知识点04:学员考勤管理数据
4.1 学生打卡信息表
- tbh_student_signin_record:学员打卡信息表
- class_id:班级id
- student_id:学员id
- signin_time:打卡时间
- signin_date:打卡日期
- 判断:是否是一个有效打卡,如果是有效的,出勤状态是什么?
- time_table_id:作息时间的id,关联作息时间表
- share_state:共屏状态
- 作用:构建每个学生的出勤状态:正常出勤、迟到出勤
| COLUMN_NAME | COLUMN_COMMENT |
|---|---|
| id | 主键id |
| normal_class_flag | 是否正课 1 正课 2 自习 |
| time_table_id | 作息时间id 关联 tbh_school_time_table 或者 tbh_class_time_table |
| class_id | 班级id |
| student_id | 学员id |
| signin_time | 签到时间 |
| signin_date | 签到日期 |
| inner_flag | 内外网标志 0 外网 1 内网 |
| signin_type | 签到类型 1 心跳打卡 2 老师补卡 |
| share_state | 共享屏幕状态 0 否 1是,在上午或下午段有共屏记录,则该段所有记录该字段为1,内网默认为1 外网默认为0 |
| inner_ip | 内网ip地址 |
4.2 班级作息时间表
- tbh_class_time_table:班级作息时间表
- 每个班级每天上午、下午、晚上的上课时间和下课时间
- 作用:判断学员的打卡是否是一个有效的打卡
| COLUMN_NAME | COLUMN_COMMENT |
|---|---|
| id | 主键id |
| class_id | 班级id |
| morning_template_id | 上午出勤模板id |
| morning_begin_time | 上午开始时间 |
| morning_end_time | 上午结束时间 |
| afternoon_template_id | 下午出勤模板id |
| afternoon_begin_time | 下午开始时间 |
| afternoon_end_time | 下午结束时间 |
| evening_template_id | 晚上出勤模板id |
| evening_begin_time | 晚上开始时间 |
| evening_end_time | 晚上结束时间 |
| use_begin_date | 使用开始日期 |
| use_end_date | 使用结束日期 |
| create_time | 创建时间 |
| create_person | 创建人 |
| remark | 备注 |
4.3 班级课表
-
course_table_upload_detail:班级排课信息表
-
class_id:班级id
-
class_date:班级上课的日期
-
content:班级上课的内容
- 如果内容为null,或者今天上课的内容是开班典礼
-
作用:用于判断当前的打卡是否是一个有效的打卡、或者一个请假是否是一个有效的请假
-
| COLUMN_NAME | COLUMN_COMMENT |
|---|---|
| id | id |
| base_id | 课程主表id |
| class_id | 班级id |
| class_date | 上课日期 |
| content | 课程内容 |
| teacher_id | 老师id |
| teacher_name | 老师名字 |
| job_number | 工号 |
| classroom_id | 教室id |
| classroom_name | 教室名称 |
| is_outline | 是否大纲 0 否 1 是 |
| class_mode | 上课模式 0 传统全天 1 AB上午 2 AB下午 3 线上直播 |
| is_stage_exam | 是否阶段考试(0:否 1:是) |
| is_pay | 代课费(0:无 1:有) |
| tutor_teacher_id | 晚自习辅导老师id |
| tutor_teacher_name | 辅导老师姓名 |
| tutor_job_number | 晚自习辅导老师工号 |
| is_subsidy | 晚自习补贴(0:无 1:有) |
| answer_teacher_id | 答疑老师id |
| answer_teacher_name | 答疑老师姓名 |
| answer_job_number | 答疑老师工号 |
| remark | 备注 |
| create_time | 创建时间 |
4.4 在读学员人数信息表
- class_studying_student_count:班级学员人数表
- 记录每个班级的总人数
- class_id:班级id
- studying_student_count:班级的总人数
| COLUMN_NAME | COLUMN_COMMENT |
|---|---|
| id | |
| school_id | 校区id |
| subject_id | 学科id |
| class_id | 班级id |
| studying_student_count | 在读班级人数 |
| studying_date | 在读日期 |
4.5 学生请假申请表
-
student_leave_apply:学员请假信息表
-
class_id:班级id
-
student_id:学员id
-
audit_state:是否批准
-
begin_time:请假开始时间
-
end_time:请假结束时间
-
作用:用于统计每个班级的请假人数
- 对请假的合法性做判断
-
| COLUMN_NAME | COLUMN_COMMENT |
|---|---|
| id | 序列id |
| class_id | 班级id |
| student_id | 学员id |
| audit_state | 审核状态 0 待审核 1 通过 2 不通过 |
| audit_person | 审核人 |
| audit_time | 审核时间 |
| audit_remark | 审核备注 |
| leave_type | 请假类型 1 请假 2 销假 |
| leave_reason | 请假原因 1 事假 2 病假 |
| begin_time | 请假开始时间 |
| begin_time_type | 1:上午 2:下午 |
| end_time | 请假结束时间 |
| end_time_type | 1:上午 2:下午 |
| days | 请假/已休天数 |
| cancel_state | 撤销状态 0 未撤销 1 已撤销 |
| cancel_time | 撤销时间 |
| old_leave_id | 原请假id,只有leave_type =2 销假的时候才有 |
| leave_remark | 请假/销假说明 |
| valid_state | 是否有效(0:无效 1:有效) |
| create_time | 创建时间 |
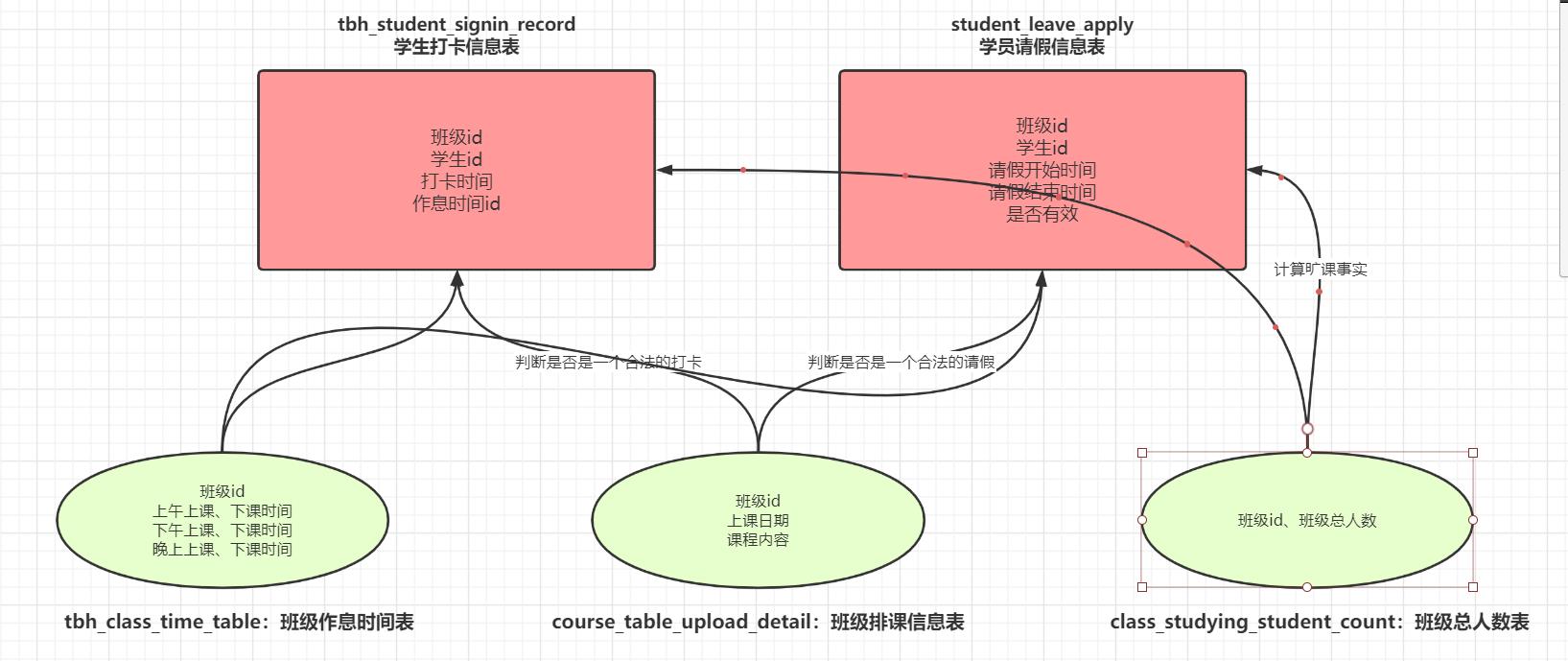
知识点05:数仓设计:ODS与DIM层
-
目标:了解考勤管理数仓中ODS与DIM层的设计
-
实施
-
ODS:事务事实表
- 学员打卡信息表:记录了所有打卡信息,用于描述出勤事实
- 正常出勤、迟到出勤
- 出勤人数:正常出勤 + 迟到出勤
- 迟到人数
- 学员请假信息表:记录所有请假信息,用于描述请假事实
- 请假人数
- 学员打卡信息表:记录了所有打卡信息,用于描述出勤事实
-
DIM:维度信息表
-
班级作息时间表:判断打卡或者请假是否合法的
-
班级排课信息表:判断打卡或者请假是否合法的
-
班级人数信息表:记录每个班级的总人数
-
用于计算旷课人数
-
用于计算出勤状态的比例
-
-
-
-
小结
- 了解考勤管理数仓中ODS与DIM层的设计
知识点06:数仓设计:DWD与DWM层
-
目标:了解考勤管理数仓中DWD与DWM层的设计
-
实施
-
DWD:明细数据层
- 无具体ETL需求,不做DWD处理
-
DWM:中间数据层
- 最终目标
-
时间 班级 上午出勤 上午出勤率 上午迟到人数 上午迟到率 上午请假人数 上午请假率 上午旷课人数 上午旷课率
5-14 001 98 98% 10 10% 2 2% 0
时间 班级 上午出勤人数 上午迟到人数 上午请假人数 上午旷课人数
5-14 001 98 10 2 0
- 打卡信息表
- 请假信息表
|
- 班级出勤状态表
时间 班级 上午出勤人数 上午迟到人数
5-14 001 98 10
- 班级请假状态表
时间 班级 上午请假人数
5-14 001 2
-
班级旷课状态表
- 总人数表 - 出勤状态表 - 请假状态表 时间 班级 上午旷课人数 5-14 001 0-
目标:构建班级出勤状态表、班级请假状态表、班级旷课状态表
-
班级出勤状态表
时间 班级id 上午出勤 上午迟到 下午出勤 下午迟到 晚上出勤 晚上迟到- 班级请假状态表
时间 班级id 上午请假 下午请假 晚上请假 ``` - 班级旷课状态表 ``` 时间 班级id 上午旷课 下午旷课 晚上旷课 ```
-
班级出勤状态表分析
-
数据:学员打卡信息表
班级id 学员id 打卡时间 001 1 2020-01-01 12:30:00 001 1 2020-01-01 15:30:00 001 1 2020-01-01 19:00:00 -
目标:班级出勤状态表
时间 班级id 上午出勤 上午迟到 下午出勤 下午迟到 晚上出勤 晚上迟到 2020-01-01 001 30 10 30 2 30 1 -
步骤
-
step1:先将学员打卡信息转换为学员出勤状态信息
班级id 学员id date 上午 下午 晚上 001 1 正常 迟到 未出勤 001 2 迟到 正常 正常
-
-
-
select
case 打卡时间 when 上课前40分钟到下课之间 then 出勤
when 上课后10分钟到下课之间 then 迟到
else 其他
from ods_student_signin
-
出勤:上课前40分钟到下课之间
-
迟到:上课后10分钟到下课之间
-
step2:基于学员出勤状态信息统计班级出勤人数表
时间 班级id 上午出勤 上午迟到 下午出勤 下午迟到 晚上出勤 晚上迟到 2020-01-01 001 30 10 30 2 30 1select count(case when 上午状态 = 正常 or 迟到 then 学员id else null end) as 上午出勤人数 count(case when 上午状态 = 迟到 then 学员id else null end) as 上午迟到人数 …… from table group by class_id ,date
-
-
班级请假状态表分析
-
ODS:学员请假信息表
班级id 学员id 请假开始时间 请假结束时间 是否合法 001 1 12:00:00 18:00:00 0 001 2 12:00:00 18:00:00 1 -
DWM:班级请假人数报表
时间 班级id 上午请假人数 下午请假人数 晚上请假人数 2020-01-01 001 3 2 4 -
实现
select class_id, date, count(disintct 学员id) as 上午请假人数 from table where 请假时间 < 上午上课时间 and 请假时间 > 上午下课时间 group by class_id,date; join select class_id, date, count(disintct 学员id) as 下午请假人数 from table where 请假时间 < 下午上课时间 and 请假时间 > 下午下课时间 group by class_id,date; join select class_id, date, count(disintct 学员id) as 晚上请假人数 from table where 请假时间 < 晚上上课时间 and 请假时间 > 晚上下课时间 group by class_id,date; on classId and date -
-
班级旷课状态表分析
-
DWM
-
班级出勤状态表
时间 班级id 上午出勤 上午迟到 下午出勤 下午迟到 晚上出勤 晚上迟到 2020-01-01 001 25 5 25 2 25 4 -
班级请假人数表
时间 班级id 上午请假人数 下午请假人数 晚上请假人数 2020-01-01 001 3 2 4 -
DIM:班级总人数表
班级id 总人数 001 30
-
-
DWM:班级旷课信息表
时间 班级 上午旷课人数 下午旷课人数 晚上旷课人数 2020-01-01 001 2 3 1
-
-
-
小结
- 了解考勤管理数仓中DWD与DWM层的设计
知识点07:数仓设计:DWS与APP层
-
目标:了解考勤管理数仓中DWS与APP层的设计
-
实施
-
DWM
- 出勤状态
时间 班级 出勤人数 迟到人数- 请假状态
时间 班级 请假人数- 旷课装填
时间 班级 旷课人数 -
DWS:汇总数据层
-
关联
时间 班级 出勤人数 迟到人数 请假人数 旷课人数 -
按照天维度做基础聚合,得到天维度下的结果
时间【天】 班级 上午指标…… 下午指标…… 晚上指标……
-
-
APP:应用数据层
-
最终得到每个时间维度下对应每个班级的汇总指标
时间【天、月、年】 班级 上午指标…… 下午指标…… 晚上指标……
-
-
-
小结
- 了解考勤管理数仓中DWS与APP层的设计
知识点08:Hive分析优化器与CBO引擎
-
目标:掌握Hive分析优化器与CBO引擎的使用
-
路径
- step1:优化器
- step2:CBO
- step3:分析优化器Analyze
-
实施
-
优化器
-
问题:关于底层优化器的选择的问题
-
RBO:基于规则的优化引擎,几乎所有数据库工具默认的优化引擎
- 按照规定的规则,源码中定义所有的规则,只要符合条件,就按照固定的规则来处理
-
CBO:基于代价的优化引擎
- 按照代价的判断的性能来具体选择一种代价最小的方式来处理数据
-
举个栗子
select * from table where age = 20- 条件:age这一列有索引,整张表有100条数据,age=20的数据有90条
- 结果:返回这90条数据内容
- RBO:按照固定的规则,来实现处理,走了索引,通过索引查询到这90条数据对应的位置,再去读这90条数据
- CBO:根据代价实现判断,发现全表扫描比走索引更快,所以CBO引擎会选择走全表扫描来得到这90条数据
-
-
-
CBO
-
功能:基于各种方式所要付出的代价来衡量,使用代价相对较小的方式来实现底层的计算
-
要求:要想用CBO,必须提前准备这些数据的一些元数据信息,列的元数据信息【哪些列,每种列的值有多少个】
-
属性
set hive.cbo.enable=true; set hive.compute.query.using.stats=true; set hive.stats.fetch.column.stats=true; set hive.stats.fetch.partition.stats=true;
-
-
分析优化器Analyze
-
功能:通过底层执行一个MapReduce,提前构建这张表中的列、分区等数据的元数据,搭配CBO引擎来使用
-
使用
ANALYZE TABLE tablename [PARTITION(partcol1[=val1], partcol2[=val2], ...)] COMPUTE STATISTICS [noscan]; ANALYZE TABLE tablename [PARTITION(partcol1[=val1], partcol2[=val2], ...)] COMPUTE STATISTICS FOR COLUMNS ( columns name1, columns name2...) [noscan];- noscan:不读取文件,如果不读取文件,只能获取到一些基本的信息
-
-
-
小结
- 什么是CBO?如何使用CBO?
- CBO:基于代价的优化器引擎,根据所有方案需要付出的代价选择最小的代价的方案来实现执行
- 使用
- step1:先通过分析优化器anlayze构建元数据
- step2:开启属性
- 什么是CBO?如何使用CBO?
知识点09:数仓实现:ODS层与DIM层
-
目标:实现ODS层与DIM层的构建
-
实施
-
ODS
-
分析
- 学员打卡信息表:出勤和迟到事实
- 学员请假信息表:请假事实
-
实现
-
学生打卡记录表
drop table itcast_ods.student_signin_ods; CREATE TABLE IF NOT EXISTS itcast_ods.student_signin_ods ( id int, normal_class_flag int comment '是否正课 1 正课 2 自习 3 休息', time_table_id int comment '作息时间id normal_class_flag=2 关联tbh_school_time_table 或者 normal_class_flag=1 关联 tbh_class_time_table', class_id int comment '班级id', student_id int comment '学员id', signin_time String comment '签到时间', signin_date String comment '签到日期', inner_flag int comment '内外网标志 0 外网 1 内网', signin_type int comment '签到类型 1 心跳打卡 2 老师补卡 3 直播打卡', share_state int comment '共享屏幕状态 0 否 1是 在上午或下午段有共屏记录,则该段所有记录该字段为1,内网默认为1 外网默认为0 (暂不用)', inner_ip String comment '内网ip地址', create_time String comment '创建时间') comment '学生打卡记录表' PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' stored as orc location '/user/hive/warehouse/itcast_ods.db/student_signin_ods' TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='time_table_id,class_id,signin_date,share_state');sqoop import \\ --connect jdbc:mysql://node3:3306/teach \\ --username root \\ --password 123456 \\ --driver com.mysql.jdbc.Driver \\ --query 'select *, FROM_UNIXTIME(unix_timestamp(),"%Y-%m-%d") as dt from tbh_student_signin_record where $CONDITIONS' \\ --hcatalog-database itcast_ods \\ --hcatalog-table student_signin_ods \\ --hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \\ -m 1 -
学生请假记录表
drop table itcast_ods.student_leave_apply_ods; CREATE TABLE IF NOT EXISTS itcast_ods.student_leave_apply_ods ( id int, class_id int comment '班级id', student_id int comment '学员id', audit_state int comment '审核状态 0 待审核 1 通过 2 不通过', audit_person int comment '审核人', audit_time String comment '审核时间', audit_remark String comment '审核备注', leave_type int comment '请假类型 1 请假 2 销假 (查询是否请假不用过滤此类型,通过有效状态来判断)', leave_reason int comment '请假原因 1 事假 2 病假', begin_time String comment '请假开始时间', begin_time_type int comment '1:上午 2:下午 3:晚自习', end_time String comment '请假结束时间', end_time_type int comment '1:上午 2:下午 3:晚自习', days float comment '请假/已休天数', cancel_state int comment '撤销状态 0 未撤销 1 已撤销', cancel_time String comment '撤销时间', old_leave_id int comment '原请假id,只有leave_type =2 销假的时候才有', leave_remark String comment '请假/销假说明', valid_state int comment '是否有效(0:无效 1:有效)', create_time String comment '创建时间') comment '学生请假申请表' PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' stored as orc location '/user/hive/warehouse/itcast_ods.db/student_leave_apply_ods' TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='class_id,audit_state,cancel_state,valid_state');sqoop import \\ --connect jdbc:mysql://node3:3306/teach \\ --username root \\ --password 123456 \\ --driver com.mysql.jdbc.Driver \\ --query 'select *, FROM_UNIXTIME(unix_timestamp(),"%Y-%m-%d") as dt from student_leave_apply where $CONDITIONS' \\ --hcatalog-database itcast_ods \\ --hcatalog-table student_leave_apply_ods \\ --hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \\ -m 1
-
-
-
DIM
-
分析
- 班级作息时间表
-
班级排课信息表
-
-
班级总人数表
-
实现
-
在读学员人数表
set hive.exec.orc.compression.strategy=COMPRESSION; drop table itcast_dimen.class_studying_student_count_dimen; CREATE TABLE IF NOT EXISTS itcast_dimen.class_studying_student_count_dimen ( id int, school_id int comment '校区id', subject_id int comment '学科id', class_id int comment '班级id', studying_student_count int comment '在读班级人数', studying_date STRING comment '在读日期') comment '在读班级的每天在读学员人数' PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
stored as orc
location ‘/user/hive/warehouse/itcast_dimen.db/class_studying_student_count_dimen’
TBLPROPERTIES (‘orc.compress’=‘SNAPPY’,‘orc.bloom.filter.columns’=‘studying_student_count,studying_date’);```shell sqoop import \\ --connect jdbc:mysql://node3:3306/teach \\ --username root \\ --password 123456 \\ --driver com.mysql.jdbc.Driver \\ --query 'select id, school_id, subject_id, class_id, ifnull(studying_student_count,0) studying_student_count, studying_date, FROM_UNIXTIME(unix_timestamp(),"%Y-%m-%d") as dt from class_studying_student_count where $CONDITIONS' \\ --hcatalog-database itcast_dimen \\ --hcatalog-table class_studying_student_count_dimen \\ --hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \\ -m 1-
班级排课表
drop table itcast_dimen.course_table_upload_detail_dimen; CREATE TABLE IF NOT EXISTS itcast_dimen.course_table_upload_detail_dimen ( id int comment 'id', base_id int comment '课程主表id', class_id int comment '班级id', class_date STRING comment '上课日期', content STRING comment '课程内容', teacher_id int comment '老师id', teacher_name STRING comment '老师名字', job_number STRING comment '工号', classroom_id int comment '教室id', classroom_name STRING comment '教室名称', is_outline int comment '是否大纲 0 否 1 是', class_mode int comment '上课模式 0 传统全天 1 AB上午 2 AB下午 3 线上直播', is_stage_exam int comment '是否阶段考试(0:否 1:是)', is_pay int comment '代课费(0:无 1:有)', tutor_teacher_id int comment '晚自习辅导老师id', tutor_teacher_name STRING comment '辅导老师姓名', tutor_job_number STRING comment '晚自习辅导老师工号', is_subsidy int comment '晚自习补贴(0:无 1:有)', answer_teacher_id int comment '答疑老师id', answer_teacher_name STRING comment '答疑老师姓名', answer_job_number STRING comment '答疑老师工号', remark STRING comment '备注', create_time STRING comment '创建时间') comment '班级课表明细表' PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
stored as orc
location ‘/user/hive/warehouse/itcast_dimen.db/course_table_upload_detail_dimen’
TBLPROPERTIES (‘orc.compress’=‘SNAPPY’,‘orc.bloom.filter.columns’=‘class_id,class_date’);```shell sqoop import \\ --connect jdbc:mysql://node3:3306/teach \\ --username root \\ --password 123456 \\ --driver com.mysql.jdbc.Driver \\ --query 'select id, base_id, class_id, class_date, content, teacher_id, teacher_name, job_number, classroom_id, classroom_name, is_outline, class_mode, is_stage_exam, is_pay, tutor_teacher_id, tutor_teacher_name, tutor_job_number, is_subsidy, answer_teacher_id, answer_teacher_name, answer_job_number, remark, create_time, FROM_UNIXTIME(unix_timestamp(),"%Y-%m-%d") as dt from course_table_upload_detail where $CONDITIONS' \\ --hcatalog-database itcast_dimen \\ --hcatalog-table course_table_upload_detail_dimen \\ --hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \\ -m 1- 班级作息时间表
-
-
-
drop table itcast_dimen.class_time_dimen;
CREATE TABLE IF NOT EXISTS itcast_dimen.class_time_dimen (
id int,
class_id int comment '班级id',
morning_template_id int comment '上午出勤模板id',
morning_begin_time STRING comment '上午开始时间',
morning_end_time STRING comment '上午结束时间',
afternoon_template_id int comment '下午出勤模板id',
afternoon_begin_time STRING comment '下午开始时间',
afternoon_end_time STRING comment '下午结束时间',
evening_template_id int comment '晚上出勤模板id',
evening_begin_time STRING comment '晚上开始时间',
evening_end_time STRING comment '晚上结束时间',
use_begin_date STRING comment '使用开始日期',
use_end_date STRING comment '使用结束日期',
create_time STRING comment '创建时间',
create_person int comment '创建人',
remark STRING comment '备注')
comment '班级作息时间表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\\t'
stored as orc
location '/user/hive/warehouse/itcast_dimen.db/class_time_dimen'
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='id,class_id');
sqoop import \\
--connect jdbc:mysql://node3:3306/teach \\
--username root \\
--password 123456 \\
--driver com.mysql.jdbc.Driver \\
--query 'select *, FROM_UNIXTIME(unix_timestamp(),"%Y-%m-%d") as dt from tbh_class_time_table where $CONDITIONS' \\
--hcatalog-database itcast_dimen \\
--hcatalog-table class_time_dimen \\
--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \\
-m 1
-
小结
- 实现ODS层与DIM层的构建
知识点10:数仓实现:DWM层出勤
-
目标:实现DWM层出勤状态表的构建
-
实施
-
分析
-
ODS:学员打卡信息表
班级id 学员id 打卡时间 打卡日期 001 1 2020-01-01 12:30:00 2020-01-01 -
DWM
-
step1:先将学员打卡信息转换为学员出勤状态信息
班级id 学员id 上午 下午 晚上 001 1 正常 迟到 未出勤 001 2 迟到 正常 正常 -
step2:基于学员出勤状态信息统计班级出勤人数表
时间 班级id 上午出勤 上午迟到 下午出勤 下午迟到 晚上出勤 晚上迟到 2020-01-01 001 30 10 30 2 30 1
-
-
SQL实现:判断:0.正常出勤、1.迟到、2.其他
- 判断打卡时间是否在上课时间范围内
- 出勤时间范围:上课前40分钟 ~ 下课时间
- 迟到时间范围:上课十分钟后 ~ 下课时间
- 关联班级作息时间表
- 出勤时间范围:上课前40分钟 ~ 下课时间
- 判断打卡是否是一个合法的打卡
- 今天是否是正课
- 关联班级排课表
- 判断打卡时间是否在上课时间范围内
-
-
实现学员出勤状态表
-
建表:学员出勤状态表
drop table itcast_dwm.student_attendance_dwm; CREATE TABLE IF NOT EXISTS itcast_dwm.student_attendance_dwm ( dateinfo String comment '日期', class_id int comment '班级id', student_id int comment '学员id', morning_att String comment '上午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)', afternoon_att String comment '下午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)', evening_att String comment '晚自习出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)') comment '学生出勤(正常出勤和迟到)数据' PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' stored as orc location '/user/hive/warehouse/itcast_dwm.db/student_attendance_dwm'; --内存不足,执行以下语句 drop table itcast_dwm.student_attendance_dwm; CREATE TABLE IF NOT EXISTS itcast_dwm.student_attendance_dwm ( dateinfo String comment '日期', class_id int comment '班级id', student_id int comment '学员id', morning_att String comment '上午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)', afternoon_att String comment '下午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)', evening_att String comment '晚自习出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)') comment '学生出勤(正常出勤和迟到)数据' PARTITIONED BY
-
-