Redis基础
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis基础相关的知识,希望对你有一定的参考价值。
1.NoSql简介
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”, 泛指非关系型的数据库
Nosql这个技术门类,早期就有人提出,发展至2009年趋势越发高涨。
2.为什么会出现Nosql这个技术门类
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题。如图片,音频,视频的存储,传统的关系型数据库只能存储结构化数据,对于非结构化的数据支持不够完善,nosql这个技术门类的出现,更好的解决了这些问题,它 告诉了世界不仅仅是sql。
3.NoSQL数据库的四大分类 非关系型数据库
-
键值(Key-Value)存储数据库 key value
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
Key/value模型对于IT系统来说的优势在于简单、易部署。
但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。
举例如:Tokyo Cabinet/Tyrant, Redis (SSDB), Voldemort, Oracle BDB.
-
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。 键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。 如:Cassandra, **HBase**, Riak. -
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。 JSON----BSON {"id":1,name:"zhangsan",password:123456} 如:CouchDB, **MongoDb**. 国内也有文档型数据库SequoiaDB,已经开源。 -
图形(Graph)数据库 文件服务器 fastdfs (小文件(20-100MB)) 短视频
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。 NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。 如:Neo4J, **InfoGrid**, Infinite Graph.
4.Nosql的适应场景
1、数据模型比较简单
2、需要灵活性更强的IT系统
3、对数据库性能要求较高
4、不需要高度的数据一致性 nosql 弱化事务 redis
5、对于给定key,比较容易映射复杂值的环境(redis)。
5.什么是Redis
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.
Redis 是一个开源的,遵循BSD许可,基于内存的,键值对型的Nosql型数据库 持久化 磁盘
6.Redis的特点
Redis是一个高性能key/value内存型数据库
Redis支持丰富的数据类型如(String,list,set,zset,hash)
Redis支持持久化 内存中数据持久化到硬盘
Redis单线程,单进程 效率高 (不支持并发操作)
底层C语言写的
7.Redis与memcahed对比
- 共同点
无论是Memcahed还是Redis底层都是使用C语言编写,都是基于key-value(键值对存储) 内存存储
- 不同点
Memcahed支持的数据类型,比较简单(String,Object)
Redis支持的数据类型比较丰富(String,List,set,zset,hash)
Memcahed默认一个值的最大存储不能超过1M
Redis一个值的最大存储1G
Memcahed中存储的数据不能持久化,一旦断电,立即丢失
Redis中存储的数据可以持久化
Memcahed 多线程,支持并发访问 数据安全 锁
Redis 单线程,并发时串行执行,将单进程单线程效率发挥到最大
Memcahced自身不支持集群环境 (使用中间件)
Redis从3.0版本之后自身开始提供集群环境支持
8.Redis的安装
1. 通过wget指令在线下载 redis(4.0.1)
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
2. 解压
tar -zxvf redis-4.0.10.tar.gz
3. 由于redis底层为c语言编写 所以需要编译安装
a.安装gcc
b.进入源码目录执行 make 出现 致命错误:jemalloc/jemalloc.h
make MALLOC=libc
c.安装redis
make install PREFIX=/usr/redis
4. 启动redis的服务
./redis-server 启动redis后台服务
5. 启动redis的客户端
./redis-cli -p 6379 -h ip地址
9.redis的指令
1.key相关的指令
1.DEL
语法 : DEL key [key ...]
作用 : 删除给定的一个或多个key 。不存在的key 会被忽略。
可用版本: >= 1.0.0
时间复杂度:
O(N),N 为被删除的key 的数量。
删除单个字符串类型的key ,时间复杂度为O(1)。
删除单个列表、集合、有序集合或哈希表类型的key ,时间复杂度为O(M),M为以上数据结构内的元素数量。
返回值: 被删除key 的数量。
2.EXISTS
语法: EXISTS key
作用: 检查给定key 是否存在。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值: 若key 存在,返回1 ,否则返回0 。
3.EXPIRE
语法: EXPIRE key seconds
作用: 为给定key 设置生存时间,当key 过期时(生存时间为0 ),它会被自动删除。
在Redis 中,带有生存时间的key 被称为『易失的』(volatile)。生存时间可以通过使用DEL 命令来删除整个key 来移除,或者被SET 和GETSET 命令覆写(overwrite),
这意味着,如果一个命令只是修改(alter) 一个带生存时间的key 的值而不是用一个新的key 值来代替(replace) 它的话,那么生存时间不会被改变。
比如说,对一个key 执行INCR 命令,对一个列表进行LPUSH 命令,或者对一个哈希表执行HSET 命令,这类操作都不会修改key 本身的生存时间。
另一方面,如果使用RENAME 对一个key 进行改名,那么改名后的key 的生存时间和改名前一样。RENAME 命令的另一种可能是,尝试将一个带生存时间的key 改名成另一个带生存时间的another_key这时旧的another_key (以及它的生存时间) 会被删除,然后旧的key 会改名为another_key ,因此,新的another_key 的生存时间也和原本的key 一样。使用PERSIST 命令可以在不删除key 的情况下,移除key 的生存时间,让key 重新成为一个『持久的』(persistent) key 。更新生存时间可以对一个已经带有生存时间的key 执行EXPIRE 命令,新指定的生存时间会取代旧的生存时间。过期时间的精确度在Redis 2.4 版本中,过期时间的延迟在1 秒钟之内——也即是,就算key 已经过期,但它还是可能在过期之后一秒钟之内被访问到,而在新的Redis 2.6 版本中,延迟被降低到1 毫秒之内。Redis 2.1.3 之前的不同之处
在Redis 2.1.3 之前的版本中,修改一个带有生存时间的key 会导致整个key 被删除,这一行为是受当时复制(replication) 层的限制而作出的,现在这一限制已经被修复。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值:设置成功返回1 。
4.KEYS
语法 : KEYS pattern
作用 : 查找所有符合给定模式pattern 的key 。
KEYS * 匹配数据库中所有key 。
KEYS h?llo 匹配hello ,hallo 和hxllo 等。
KEYS h*llo 匹配hllo 和heeeeello 等。
KEYS h[ae]llo 匹配hello 和hallo ,但不匹配hillo 。
特殊符号用 \\ 隔开
注意: KEYS 的速度非常快,但在一个大的数据库中使用它仍然可能造成性能问题,如果你需要从一个数据集中查找特定的key ,你最好还是用Redis 的集合结构(set) 来代替。
可用版本: >= 1.0.0
时间复杂度: O(N),N 为数据库中key 的数量。
返回值: 符合给定模式的key 列表。
5.MOVE
语法 : MOVE key db
作用 : 将当前数据库的key 移动到给定的数据库db 当中。
如果当前数据库(源数据库) 和给定数据库(目标数据库) 有相同名字的给定key ,或者key 不存在于当前数据库,那么MOVE 没有任何效果。因此,也可以利用这一特性,将MOVE 当作锁(locking) 原语(primitive)。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值: 移动成功返回1 ,失败则返回0 。
注意:redis提供16个库 默认在0号库
切换库使用 select+库下标 指令
6.PEXPIRE
语法 : PEXPIRE key milliseconds
作用 : 这个命令和EXPIRE 命令的作用类似,但是它以毫秒为单位设置key 的生存时间,而不像EXPIRE 命令那样,以秒为单位。
可用版本: >= 2.6.0
时间复杂度: O(1)
返回值:设置成功,返回1 key 不存在或设置失败,返回0
7.PEXPIREAT
语法 : PEXPIREAT key milliseconds-timestamp
作用 : 这个命令和EXPIREAT 命令类似,但它以毫秒为单位设置key 的过期unix 时间戳,而不是像EXPIREAT那样,以秒为单位。
可用版本: >= 2.6.0
时间复杂度: O(1)
返回值:如果生存时间设置成功,返回1 。当key 不存在或没办法设置生存时间时,返回0 。(查看EXPIRE 命令获取更多信息)
8.TTL
语法 : TTL key
作用 : 以秒为单位,返回给定key 的剩余生存时间(TTL, time to live)。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值:
当key 不存在时,返回-2 。
当key 存在但没有设置剩余生存时间时,返回-1 。
否则,以秒为单位,返回key 的剩余生存时间。
Note : 在Redis 2.8 以前,当key 不存在,或者key 没有设置剩余生存时间时,命令都返回-1 。
9.PTTL
语法 : PTTL key
作用 : 这个命令类似于TTL 命令,但它以毫秒为单位返回key 的剩余生存时间,而不是像TTL 命令那样,以秒为单位。
可用版本: >= 2.6.0
复杂度: O(1)
返回值: 当key 不存在时,返回-2 。当key 存在但没有设置剩余生存时间时,返回-1 。
否则,以毫秒为单位,返回key 的剩余生存时间。
注意 : 在Redis 2.8 以前,当key 不存在,或者key 没有设置剩余生存时间时,命令都返回-1 。
10.RANDOMKEY
语法 : RANDOMKEY
作用 : 从当前数据库中随机返回(不删除) 一个key 。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值:当数据库不为空时,返回一个key 。当数据库为空时,返回nil 。
11.RENAME
语法 : RENAME key newkey
作用 : 将key 改名为newkey 。当key 和newkey 相同,或者key 不存在时,返回一个错误。当newkey 已经存在时,RENAME 命令将覆盖旧值。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值: 改名成功时提示OK ,失败时候返回一个错误。
12.TYPE
语法 : TYPE key
作用 : 返回key 所储存的值的类型。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值:
none (key 不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
2.value为string类型相关的指令
set 设置一个key/value
get 根据key获得对应的value
mset 一次设置多个key value
mget 一次获得多个key的value
getset 获得原始key的值,同时设置新值
strlen 获得对应key存储value的长度
append 为对应key的value追加内容
getrange 截取value的内容
setex 设置一个key存活的有效期(秒)
psetex 设置一个key存活的有效期(豪秒)
setnx 存在不做任何操作,不存在添加
msetnx 可以同时设置多个key,只有有一个存在都不保存
decr (不存在则创建) 进行数值类型的-1操作
Decrby (不存在则创建) 根据提供的数据进行减法操作
Incr (不存在则创建) 进行数值类型的+1操作
incrby (不存在则创建) 根据提供的数据进行加法操作
Incrbyfloat (保留17位) 根据提供的数据加入浮点数
3.value为list相关的指令

lpush 将某个值加入到一个key列表头部
lpushx 同lpush,但是必须要保证这个key存在
rpush 将某个值加入到一个key列表末尾
rpushx 同rpush,但是必须要保证这个key存在
lpop 返回和移除列表的第一个元素
rpop 返回和移除列表的第一个元素
lrange 获取某一个下标区间内的元素
llen 获取列表元素个数
lset 设置某一个指定索引的值(索引必须存在)
lindex 获取某一个指定索引位置的元素
lrem 删除重复元素
ltrim 保留列表中特定区间内的元素
linsert 在某一个元素之前,之后插入新元素
4.value为set类型的指令

sadd 为集合添加元素
smembers 显示集合中所有元素 无序
scard 返回集合中元素的个数
spop 随机返回一个元素
smove 从一个集合中向另一个集合移动元素
srem 从集合中删除一个元素
sismember 判断一个集合中是否含有这个元素
srandmember 随机返回元素
sdiff 去掉第一个集合中其它集合含有的相同元素
sinter 求交集
sunion 求和集
5.value为zset类型的指令

zadd 添加一个有序集合元素
zcard 返回集合的元素个数
zrange 返回一个范围内的元素
zrangebyscore 按照分数查找一个范围内的元素
zrank 返回排名
zrevrank 倒序排名
zscore 显示某一个元素的分数
zrem 移除某一个元素
zincrby 给某个特定元素加分
6.value为hash类型的指令

hset 设置一个key/value对
hget 获得一个key对应的value
hgetall 获得所有的key/value对
hdel 删除某一个key/value对
hexists 判断一个key是否存在
hkeys 获得所有的key
hvals 获得所有的value
hmset 设置多个key/value
hmget 获得多个key的value
//hsetnx 设置一个不存在的key的值 针对小key是否存在 如果存在则不添加
hincrby 为value进行加法运算
hincrbyfloat 为value加入浮点值
10.redis中的小细节
1.如何修改redis的端口号?
a.修改源码目录中的redis.conf中的端口 默认端口6379
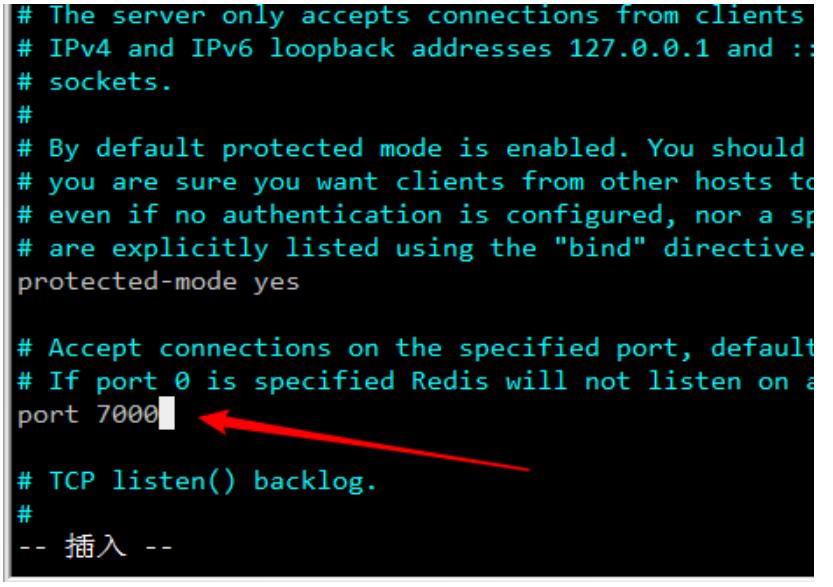
b.启动redis服务时加载修改后的配置文件
./redis-server /root/redis-4.0.10/redis.conf
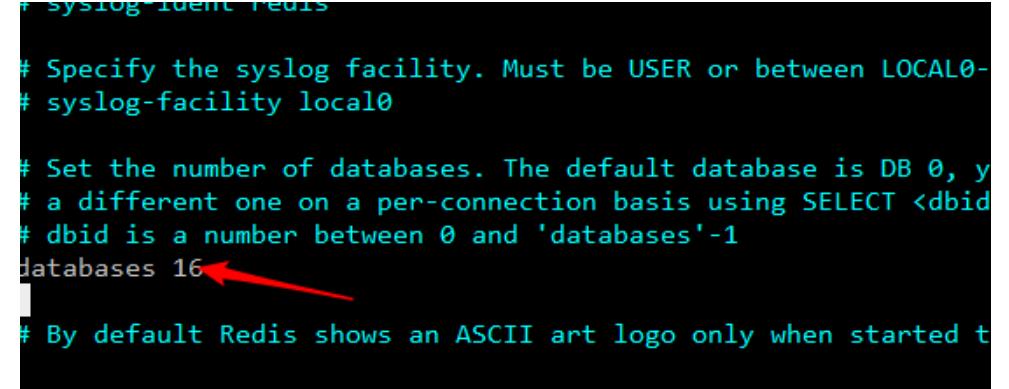
2.默认库的个数修改 默认在0号库 一共16个库 切库select 0
3.黑窗口中的中文展示
在连接redis数据库时 使用 ./redis-cli -p 7000 --raw
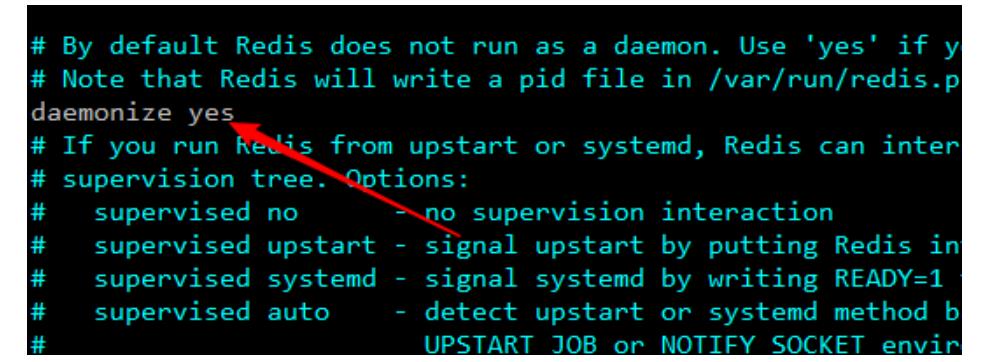
4.将redis服务设置为后台方式启动
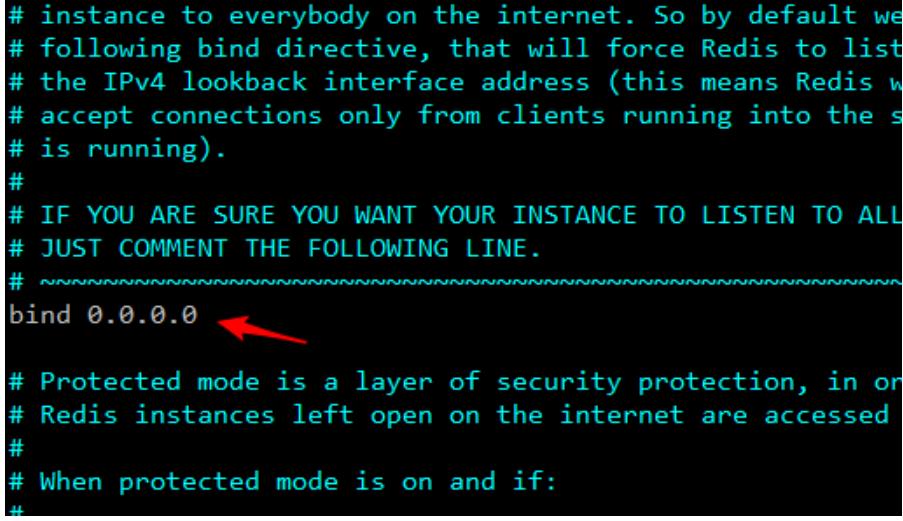
5.redis中的可视化工具
注意:redis默认没有开启远程的访问权限
11.redis中的两种持久化方式
1.快照(snapshotting)
这种方式可以将某一时刻的所有数据都写入硬盘中,当然这也是redis的默认持久化方式,保存的文件是以.rdb形式结尾的文件因此这种方式也称之为RDB方式
-
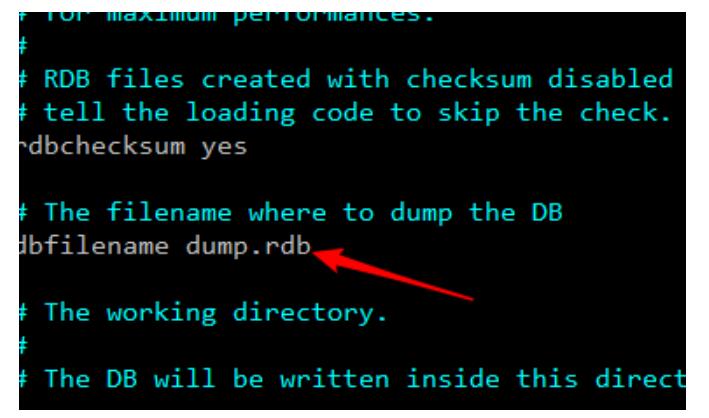
快照文件的名字 dump.rdb
-
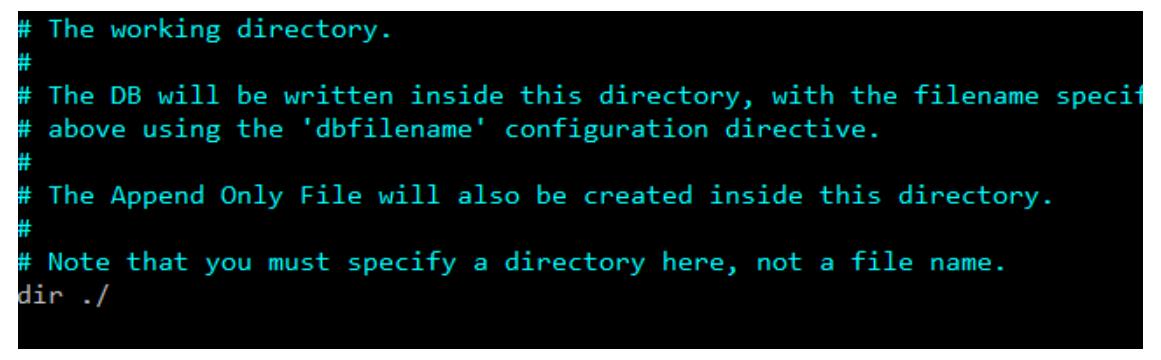
快照文件的默认存储位置 安装目录
- 快照的几种生成方式
1.客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork¹来创建一 个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求
注意:在执行bgsave指令时不会阻塞客户端请求
2.客户端还可以使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应任何其他的命令
注意:阻塞客户端请求
3.如果用户在redis.conf中设置了save配置选项,redis会在save选项条件满足之后自动触发一次BGSAVE命令,如果设置多个save配置选项,当任意一个save配置选项条件满足,redis也会触发一次BGSAVE命令
时间 秒 请求次数
save 900 1
save 300 10
save 60 10000
4.当redis通过shutdown指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有的客户端,不再执行客户端执行发送的任何命令,并且在save命令执行完毕之后关闭服务器
快照:丢失少量数据
2.AOF
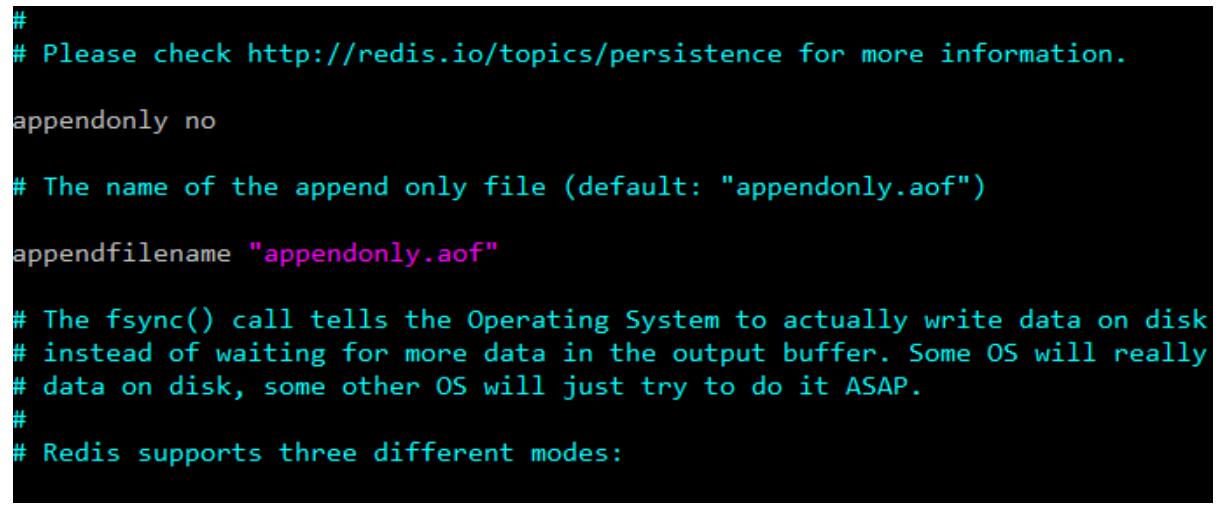
在redis的默认配置中AOF持久化机制 是没有开启的,AOF持久化会将被执行的写命令写到AOF的文件末尾,以此来记录数据发生的变化,因此只要redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集
- 开启aof以及文件名的设置
- aof生成的策略
可选项
| 选项 | 同步频率 |
|---|---|
| always | 每个redis写命令都要同步写入硬盘,严重降低redis速度 |
| everysec | 每秒执行一次同步显式的将多个写命令同步到磁盘 |
| no | 由操作系统决定何时同步 |
l 三种日志记录频率的详细分析 :
如果用户使用了always选项,那么每个redis写命令都会被写入硬盘,从而将发生系统崩溃时出现的数据丢失减到最少;遗憾的是,因为这种同步策略需要对硬盘进行大量的写入操作,所以redis处理命令的速度会受到硬盘性能的限制;
注意 : 转盘式硬盘在这种频率下200左右个命令/s ; 固态硬盘(SSD) 几百万个命令/s;
警告 : 使用SSD用户请谨慎使用always选项,这种模式不断写入少量数据的做法有可能会引发严重的写入放大问题,导致将固态硬盘的寿命从原来的几年降低为几个月
为了兼顾数据安全和写入性能,用户可以考虑使用everysec选项,让redis每秒一次的频率对AOF文件进行同步;redis每秒同步一次AOF文件时性能和不使用任何持久化特性时的性能相差无几,而通过每秒同步一次AOF文件,redis可以保证,即使系统崩溃,用户最多丢失一秒之内产生的数据(推荐使用这种方式)
最后使用no选项,将完全有操作系统决定什么时候同步AOF日志文件,这个选项不会对redis性能带来影响但是系统崩溃时,会丢失不定数量的数据,另外如果用户硬盘处理写入操作不够快的话,当缓冲区被等待写入硬盘数据填满时,redis会处于阻塞状态,并导致redis的处理命令请求的速度变慢(不推荐使用)
AOF文件的重写
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件Redis提供了AOF重写机制
1.重写 aof 文件的两种方式
- 执行BGREWRITEAOF命令
- 配置redis.conf中的auto-aof-rewrite-percentage选项
2.BGREWRITEAOF 方式
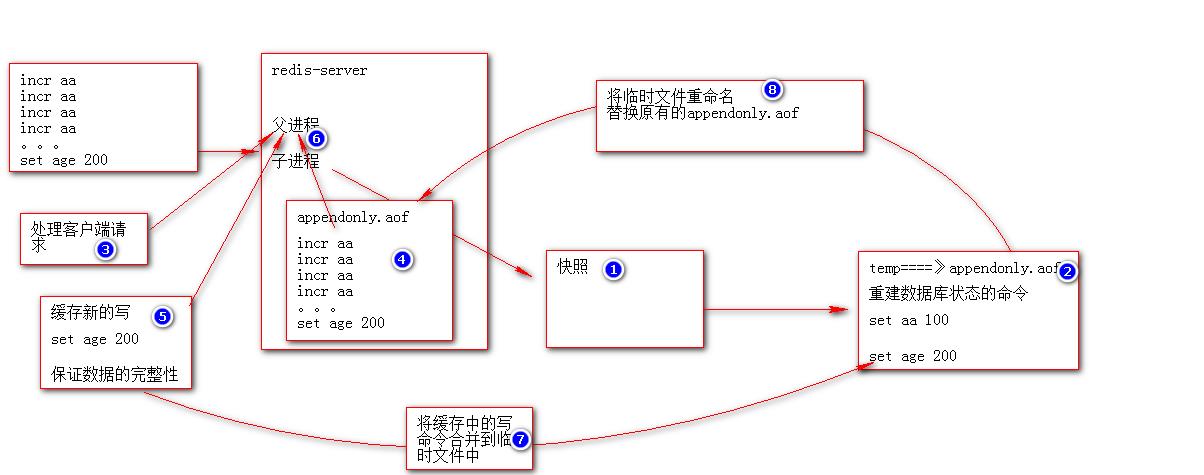
收到此命令redis将使用与快照类似的方式将内存中的数据 以命令的方式保存到临时文件中,最后替换原来的文件。具体过程如下
1. redis调用fork ,现在有父子两个进程 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
2. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
3. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
4. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
注意 : 重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,替换原有的文件这点和快照有点类似。(AOF重写过程完成后会删除旧的AOF文件,删除一个体积达几十GB大的旧的AOF文件可能会导致系统随时挂起 )
配置redis.conf中的auto-aof-rewrite-percentage选
AOF重写也可以使用auto-aof-rewrite-percentage 100
和auto-aof-rewrite-min-size 64mb来自动执行BGREWRITEAOF.
说明: 如果设置auto-aof-rewrite-percentage值为100和auto-aof-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64M,并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percentage设置为更大
12.springboot中操作redis
1.导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>1.5.8.RELEASE</version>
</dependency>
2.配置文件中配置redis
spring:
redis:
database: 0
host: 192.168.174.119
pool:
max-active: 8
max-wait: -1
port: 7000
3.使用springdata操作redis
RunWith(SpringRunner.class)
@SpringBootTest(classes = App.class)
public class TestRedis {
/*
*
* springdata提供模板RedisTemplate
*
*/
@Autowired
RedisTemplate redisTemplate;
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testRedis() {
redisTemplate.opsForValue().set("name", "zhangsan", 1, TimeUnit.HOURS);
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}
@Test
public void TestStringRedis() {
stringRedisTemplate.opsForValue().set("name", "zhangsan");
}
@Test
public void TestListRedis() {
//stringRedisTemplate.opsForList().leftPush("ages", "10");
List<String> ages = stringRedisTemplate.opsForList().range("ages", 0, -1);
for (String age : ages) {
System.out.println(age);
}
}
@Test
public void TestSetRedis() {
stringRedisTemplate.opsForSet().add("set","1","2","3","4");
Set<String> set = stringRedisTemplate.opsForSet().members("set");
for (String s : set) {
System.out.println(s);
}
}
@Test
public void TestMapRedis() {
// stringRedisTemplate.opsForZSet().add()
Map map=new HashMap();
map.put("id","1");
map.put("name","xiaohua1");
map.put("password","123456");
stringRedisTemplate.opsForHash().putAll("map",map);
}
@Test
public void TestBoundMapRedis() {
BoundHashOperations<String, Object, Object> boundHashOperations = stringRedisTemplate.boundHashOps("map");
Object id = boundHashOperations.get("id");
System.out.println(id);
}
}
13.缓存
1. 什么是缓存
内存中的一段数据
2. 缓存的作用是什么?
a.减轻数据库压力
b.提高查询效率,提高用户的体验
3. 怎么实现缓存
mybatis的缓存
一级缓存:缓存范围指一次sqlsession
二级缓存:二级缓存的作用范围是一个 namespace
<cache>
4. 现有架构下的缓存
mybtis缓存的缺陷 : 占用服务器资源,是服务器的处理速度降低
集群环境下缓存无法共享,同步
5. redis实现分布式缓存
1.分布式缓存的实现
1.准备redis环境
2.搭建springboot+mybatis的环境并且集成redis
1.实现mybatis提供的cache接口
public class RedisCache implements Cache {
private String id;
/*
* 必须准备一个构造方法 并且含有string类型的id
* 该id为mybatis的mapper文件的namespace
* */
public RedisCache(String id) {
this.id = id;
System.out.println(id);
}
/*
* 必须实现getId 将当前的namespace返回给mybatis
*
* */
@Override
public String getId() {
return id;
}
@Override //第一个参数 方法名 第二个参数 数据库里的值
public void putObject(Object o, Object o1) {
/*
* 将当前的键值对 加入到redis中
* */
System.out.println("当缓存为空时添加缓存---------2");
}
@Override
public Object getObject(Object o) {
System.out.println("获取缓存---------1");
return null;
}
@Override
public Object removeObject(Object o) {
return null;
}
@Override
public void clear() {
}
@Override
public int getSize() {
return 0;
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
}
2.在mapper文件中指定对应Cache实现
<!--修改mybatis的默认缓存实现-->
<cache type="com.baizhi.cache.RedisCache"></cache>
3.redis中存储缓存的数据结构
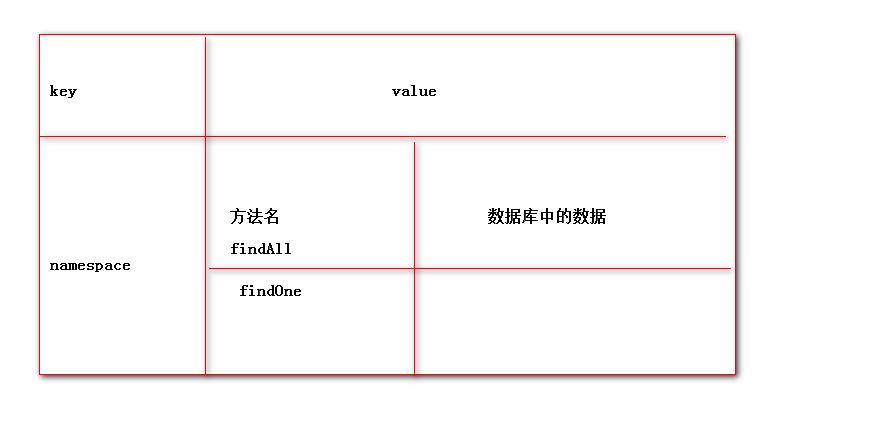
4.在redisCache使用工厂中的对象
/*
*
* 将感兴趣的对象传递过来
* */
@Component
public class SpringContextUtil implements ApplicationContextAware {
private static ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
/*在工厂加载完毕会被调用*/
context = applicationContext;
}
//获取整个工厂对象
public static ApplicationContext getContext(){
return context;
}
//根据名称获取指定bean
public static Object getBean(String name){
return context.getBean(name);
}
//根据类型获取指定bean
public static Object getBean(Class clazz){
return context.getBean(clazz);
}
//根据名称和类型获取
public static Object getBean(String name,Class clazz){
return context.getBean(name,clazz);
}
}
5.完善cache实现
实现添加缓存 获取缓存 清空缓存
public class RedisCache implements Cache {
/*获取springboot启动时创建的spring工厂*/
private String id;
/*
* 必须准备一个构造方法 并且含有string类型的id
* 该id为mybatis的mapper文件的namespace
* */
public RedisCache(String id) {
this.id = id;
}
/*
* 必须实现getId 将当前的namespace返回给mybatis
*
* */
@Override
public String getId() {
return id;
}
@Override //第一个参数 方法名 第二个参数 数据库里的值
public void putObject(Object o, Object o1) {
/*
* 将当前的键值对 加入到redis中
* */
// System.out.println("当缓存为空时添加缓存---------2");
// StringRedisTemplate stringRedisTemplate = (StringRedisTemplate)SpringContextUtil.getBean(StringRedisTemplate.class);
// String s = SerializeUtils.serialize(o1);
// stringRedisTemplate.opsForHash().put(id,o.toString(),s);
RedisTemplate redisTemplate = (RedisTemplate) SpringContextUtil.getBean("redisTemplate");
redisTemplate.opsForHash().put(id,o,o1);
}
@Override
public Object getObject(Object o) {
/* System.out.println("获取缓存---------1");
StringRedisTemplate stringRedisTemplate = (StringRedisTemplate) SpringContextUtil.getBean(StringRedisTemplate.class);
Object o1 = stringRedisTemplate.opsForHash().get(id, o.toString());
Object s =null;
if (o1!=null){
s = SerializeUtils.serializeToObject(o1.toString());
}
return s;*/
RedisTemplate redisTemplate = (RedisTemplate) SpringContextUtil.getBean("redisTemplate");
Object o1 = redisTemplate.opsForHash().get(id, o);
return o1;
}
@Override
public Object removeObject(Object o) {
System.out.println("------removeObject------");
return null;
}
@Override
public void clear() {
// System.out.println("------clear------");
// StringRedisTemplate stringRedisTemplate = (StringRedisTemplate) SpringContextUtil.getBean(StringRedisTemplate.class);
// stringRedisTemplate.delete(id);
RedisTemplate redisTemplate = (RedisTemplate) SpringContextUtil.getBean("redisTemplate");
redisTemplate.delete(id);
}
@Override
public int getSize() {
return 0;
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
}
14.集群搭建
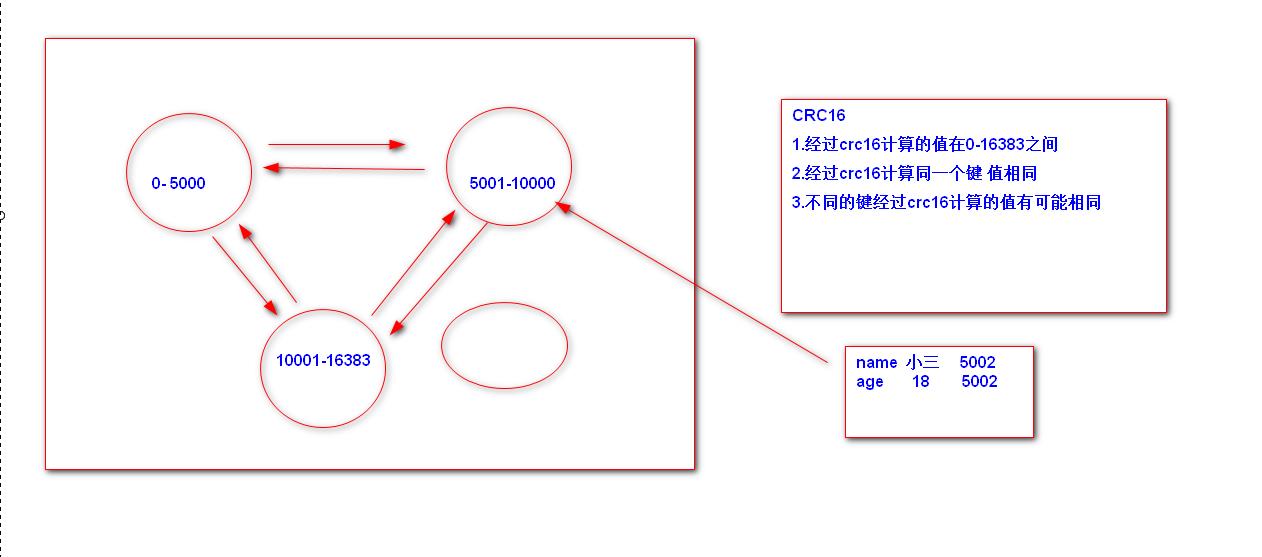
1.准备6个机器
准备一个机器 开启6个不同的端口号
2.分别创建6个配置文件
cluster-enabled yes //开启集群模式
cluster-config-file nodes-7000.conf //集群节点配置文件
cluster-node-timeout 5000 //集群节点超时时间
appendonly yes //开启AOF持久化
3.以此启动6个redis服务
4.在源码目录中 将redis-trib.rb 拷贝到 /usr/redis/bin 里
cp redis-trib.rb /usr/redis/bin/
5.redis-trib.rb脚本使用rube语言书写 所以需要安装ruby环境
yum install -y ruby
6.安装 redis-3.2.1.gem
gem install -y redis-3.2.1.gem
7.构建redis集群
a.创建集群
./redis-trib.rb create --replicas 1 192.168.68.128:7000 192.168.68.128:7001 192.168.68.128:7002 192.168.68.128:7003 192.168.68.128:7004 192.168.68.128:7005
b.查看集群状态
./redis-trib.rb check 192.168.174.119:7003
c.添加主节点
./redis-trib.rb add-node 192.168.65.11:7006 192.168.65.11:7001
d.节点的重新分片
./redis-trib.rb reshard 192.168.65.11:7001
e.添加从节点
./redis-trib.rb add-node --slave 192.168.174.119:7007 192.168.174.119:7001
f.为指定的主节点添加副本节点
a)./redis-trib.rb add-node
--slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7006 127.0.0.1:7000
g.删除副本节点
./redis-trib.rb del-node 127.0.0.1:7002 0ca3f102ecf0c888fc7a7ce43a13e9be9f6d3dd1
./redis-cli -c -p 7001
客户端连接
springboot操作redis集群
spring:
redis:
database: 0
pool:
max-active: 8
max-wait: -1
cluster:
nodes: