特征工程集成算法浅谈
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征工程集成算法浅谈相关的知识,希望对你有一定的参考价值。
最近又在开始建模了,简单复习一下
1 特征工程
特征工程是指将原始数据转换为模型特征的技术,其目的在于获得更好的特
征变量,使构建的机器学习模型能够达到最优性能或接近最优性能

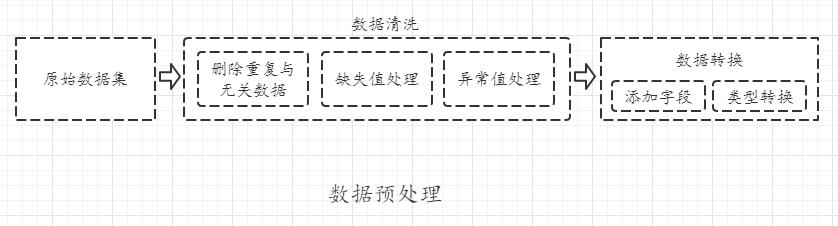
1.1 数据预处理
在解决实际问题时,所收集的数据通常往往是脏数据,可能存在数据噪声、数据冗余、数据缺失、数据集不均衡、数据异常等问题。
关于异常值的识别,常用方式有三种:
(1)通过描述性统计分析查看异常值;
(2)3σ原则,在数据服从正态分布时,认为样本距离平均值大于3σ的数据为异常值;
(3)通过绘制箱线图识别异常值。
关于异常值的处理,常用方法有四种:
(1)删除含有异常值的数据
(2)将异常值当作缺失值,使用缺失值填补方法填补
(3)根据业务实际情况,可能不需要处理异常值,具体情况进行具体分析。
关于类型转换
常见的数据类型包括数值型数据和非数值型数据,数值型数据分为连续和离散两种型,非数值型数据包括定序型、定类型和字符串型。
在机器学习算法中,模型只能识别数值变量,不能直接处理非数值型变量
引用:https://blog.csdn.net/weixin_44551646/article/details/115422314
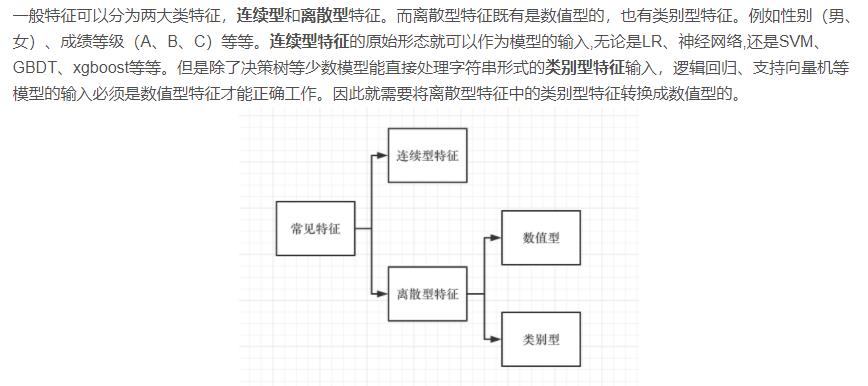
需要通过数据转换,得到机器学习能够使用的变量
eg:

关于转换处理,一般有标签编码与独热编码
(1)序号编码(Ordinal Encoding):通常用于处理类别间具有内在大小顺序关系的数据
(2)标签编码:LabelEncoder:主要用于处理有序类别变量,直接将类别转换成数字,可以保留类别变量的大小关系和原本的数据维度。Label Encoding是给某一列数据编码,而Ordinal Encoding常用于给数据集中的特征编码。
(3)独热编码(One-hot Encoding):如果类别变量是无序变量,那么标签编码不再适用,这时需要用到独热编码。通过独热编码,特征之间的距离更合理,有利于提升计算速度,适用于类别变量不太多的情况。
总结:
引用:https://blog.csdn.net/weixin_44551646/article/details/115422314

1.2 特征选择

2 集成算法
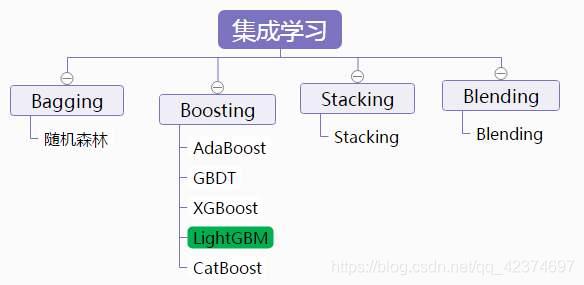
1)Bagging + 决策树 = 随机森林
2)Adaptive boosting(AdaBoost )+ 决策树 = 提升树(boosting tree)
3)Gradient Boosting + 决策树 = GBDT(梯度提升树)
提升树系列算法里面应用最广泛的是GBDT梯度提升树(Gradient Boosting Tree)
XGBoost的性能在GBDT上又有一步提升
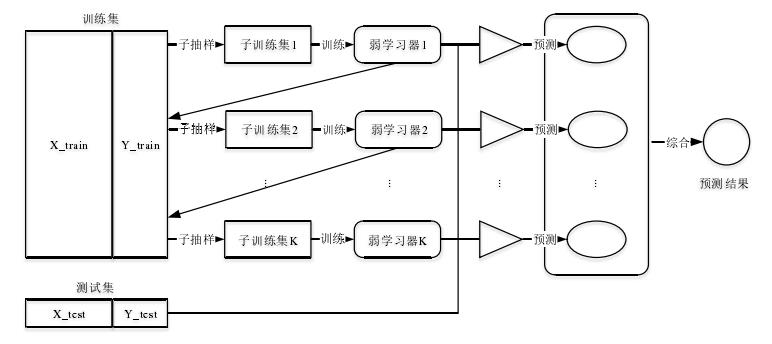
2.1 Bagging算法
装袋法,有放回的随机自助抽样,基模型之间相互独立
预测结果
- 对于分类来说是最高得票的结果
- 对于回归来说是所有弱学习器输出结果的均值
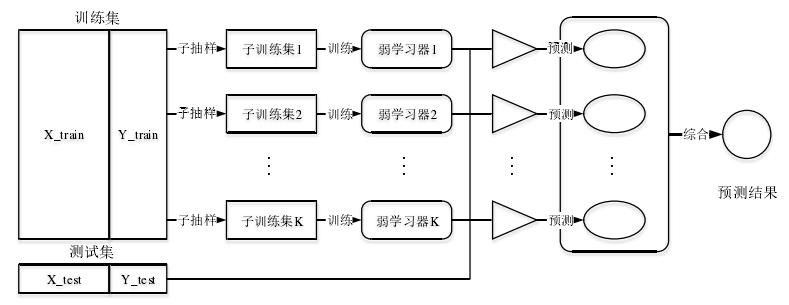
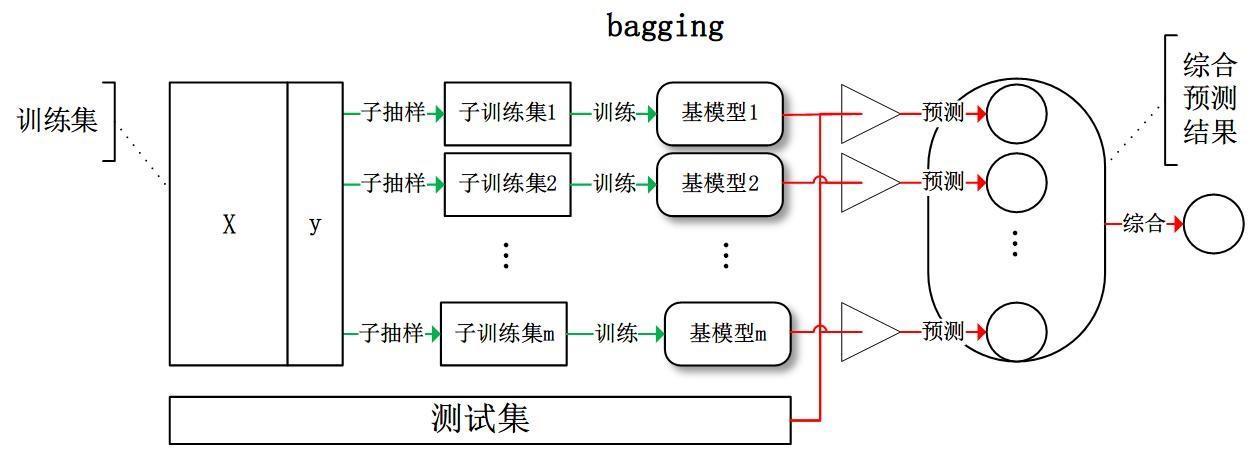
对于基学习器,可以是任何一种算法,
一般我们常说的集成学习的方法都是指的同质个体学习器。而同质个体学习器使用最多的模型是CART决策、神经网络、支持向量机。
2.1.1 随机森林
例
Bagging算法代表——随机森林,其基学习器为固定不变的决策树模型。通常决策树有一个明显的缺点,就是模型的泛化能力差,即在新数据上的表现差,通过集成后,随机森林模型通过集成决策树解决了泛化能力差的问题。
随机森林是以决策树作为元分类器的一种集成学习方法,其思想是通过bootstrap抽样方法从原始训练样本集N中有放回地随机抽取k个样本生成相互之间有差异的新的训练子集(抽取的样本不完全一样),再根据k个训练子集建立k个决策树,分类结果由k个决策树投票决定。因此,RF包括四个部分:①随机选择样本(放回抽样);②随机选择特征;③构建决策树;④随机森林投票(平均)。
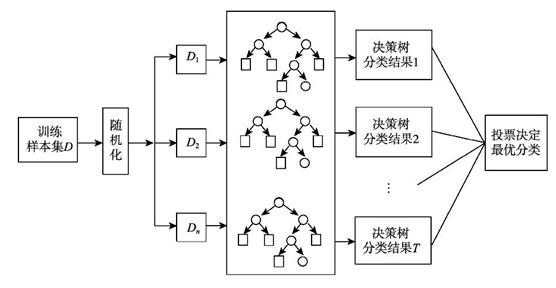
对于随机森林,其弱学习器不仅仅限于分类树,还可以是回归树,可以解决回归和分类两种问题。只是说在应用回归问题上的效果不如分类问题
其次,随机森林还有很多其他优点
(1)若数据集中存在缺失值,随机森林模型也可以保持很高的预测精度,对数据的要求较低。
(2)随机森林对变量共线性不作要求,因此可以将全部候选变量纳入模型。即随机森林模型可以处理高维数据。
2.2 Boosting算法
Boosting算法属于迭代算法,它通过不断地使用一个弱学习器弥补前一个弱学习器的“不足”的过程,来串行地构造一个较强的学习器,这个强学习器能够使目标函数值足够小。
引用:https://www.jiqizhixin.com/articles/2018-12-28-11
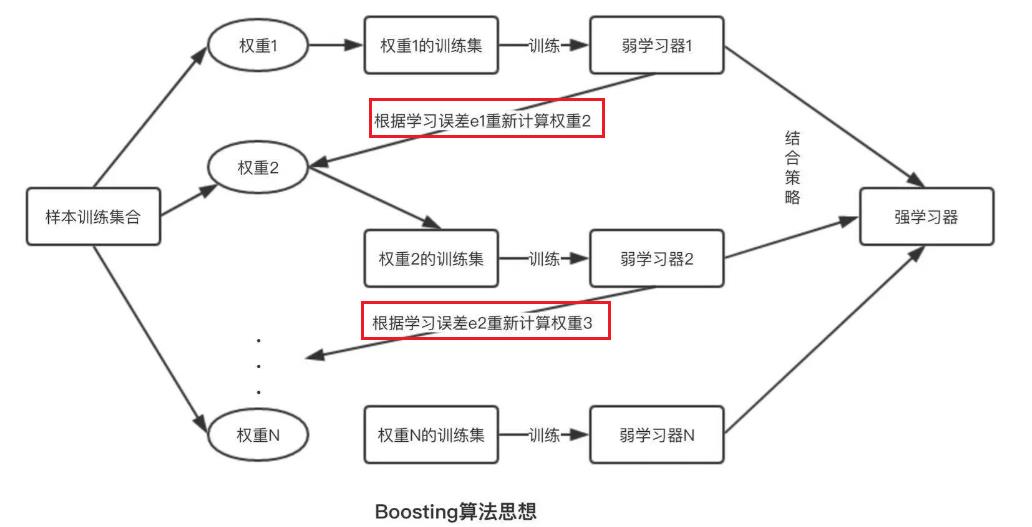
对提升方法来说,有两个问题需要回答:
(1)在每一轮如何改变训练数据的权值或概率分布;
(2)如何将弱分类器组合成一个强分类器。
2.2.1 AdaBoost
引用:https://www.cnblogs.com/YongSun/p/4767513.html
关于第1个问题,AdaBoost的做法是,先赋予每个训练样本相同的权重,然后进行T次迭代,每次迭代后,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。
至于第2个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
2.2.2 GBDT
GBDT(Gradient Boost Decision Tree)是一种常用的非线性模型,基于boosting算法的思想,每次迭代都在减少残差的梯度方向新建立一棵决策树,即是一种利用残差拟合弱学习器的Boosting算法,通过迭代不断提高预测的准确性。
由于GBDT能够发现多种有区分性的特征以及特征组合,决策树的路径可以直接作为其他模型的输入特征使用,省去了人工寻找特征、特征组合的步骤。.
注:GBDT的基模型一定是CART回归树,这是由于GBDT需要拟合的负梯度是连续数值。
GBDT的算法流程如下:
(1)初始化基模型,计算样本的残差,即负梯度;
(2)上一步计算的负梯度是这一轮的样本真实值,并将其当作下一轮的训练样本,构建回归树;
(3)经过反复训练,计算叶子节点的最优拟合值,不断迭代,最终得到强学习器。
2.2.3 XGBoost
XGBoost算法本质上还是GBDT算法,但对GBDT算法进行诸多改进
2.2.4 LightGBM
LightGBM算法由微软研发,是一种基于GBDT算法的改进模型。与XGBoost相比,LightGBM算法的计算复杂度更小。
以上是关于特征工程集成算法浅谈的主要内容,如果未能解决你的问题,请参考以下文章