java问题,byte a=1,b=1;byte c=a+b;为啥错
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java问题,byte a=1,b=1;byte c=a+b;为啥错相关的知识,希望对你有一定的参考价值。
我之前总结的有两种1,错误提示是int转换为byte可能会丢失精度,可能是+号会提升两边的数据类型为int,大数据类型转小数据类型需要强转,并不能隐转,换句话说int以上所有数据类型支持这种写法,
例如double a=1;
double b=1;
double c=a+b;
解决这个问题可以这样bety c=(byte)(a+b);
2是byte 不支持这种写法,这个说法很牵强,我试过short也不能这样用 参考技术A byte的值的范围只有0和1(只是一位二进制数字),1+1=2,范围超出而出现溢出错误。 参考技术B byte a='1',b='1';byte c=a+b;
Java学习之InputStream中read()与read(byte[] b)
Java学习之InputStream中read()与read(byte[] b)
这两个方法在抽象类InputStream中都是作为抽象方法存在的,
JDK API中是这样描述两者的:
read() : 从输入流中读取数据的下一个字节,返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回-1。在输入数据可用、检测到流末尾或者抛出异常前,此方法一直阻塞。
read(byte[] b) : 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。在输入数据可用、检测到文件末尾或者抛出异常前,此方法一直阻塞。
如果 b 的长度为 0,则不读取任何字节并返回 0;否则,尝试读取至少一个字节。如果因为流位于文件末尾而没有可用的字节,则返回值 -1;否则,至少读取一个字节并将其存储在 b 中。
将读取的第一个字节存储在元素 b[0] 中,下一个存储在 b[1] 中,依次类推。读取的字节数最多等于b 的长度。设 k 为实际读取的字节数;这些字节将存储在 b[0] 到 b[k-1] 的元素中,不影响 b[k] 到b[b.length-1] 的元素。
由帮助文档中的解释可知,read()方法每次只能读取一个字节,所以也只能读取由ASCII码范围内的一些字符。这些字符主要用于显示现代英语和其他西欧语言。而对于汉字等unicode中的字符则不能正常读取。只能以乱码的形式显示。
对于read()方法的上述缺点,在read(byte[] b)中则得到了解决,就拿汉字来举例,一个汉字占有两个字节,则可以把参数数组b定义为大小为2的数组即可正常读取汉字了。当然b也可以定义为更大,比如如果b=new byte[4]的话,则每次可以读取两个汉字字符了,但是需要注意的是,如果此处定义b 的大小为3或7等奇数,则对于全是汉字的一篇文档则不能全部正常读写了。
下面用实例来演示一下二者的用法:
实例说明:类InputStreamTest.java 来演示read()方法的使用。类InputStreamTest1.java来演示read(byte[] b)的使用。两个类的主要任务都是通过文件输入流FileInputStream来读取文本文档yhw.txt中的内容,并且输出到控制台上显示。
先看一下yhw.txt文档的内容:
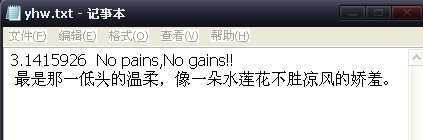
InputStreamTest.java代码如下:
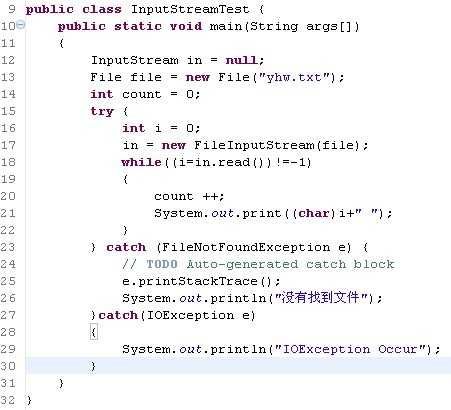
运行结果:3.1415926 No pains,No gains!!(乱码乱码)
InputStreamTest1.java代码如下:
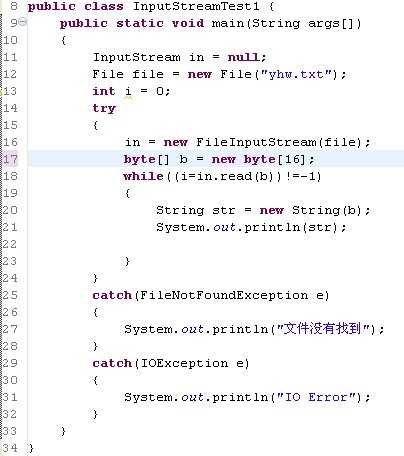
运行结果:
3.1415926 No pains,No gains!! 最是那一低头的温柔,像一朵水莲花不胜凉风的娇羞。
InputStream的三个read的区别
1.read
这个方法是对这个流一个一个字节的读,返回的int就是这个字节的int表示方式
以下是代码片段,经过测试当eclipse的编码为gbk时,转化出的字符串不需经过重新编码,如果eclipse的编码为utf-8时则由byte转成字符串需重新编成utf-8的
InputStream in = Test.class.getResourceAsStream("/tt.txt");
byte[]tt=new byte[15];//测试用的事前知道有15个字节码
while(in.available()!=0){
for(int i=0;i<15;i++){
tt[i]=(byte)in.read();
}
}
String ttttt=new String(tt,"utf-8");
System.out.println(ttttt);
in.close();
2.read(byte[] b)
这个方法是先规定一个数组长度,将这个流中的字节缓冲到数组b中,返回的这个数组中的字节个数,这个缓冲区没有满的话,则返回真实的字节个数,到未尾时都返回-1
in = Test.class.getResourceAsStream("/tt.txt");
byte [] tt=new byte[1024];
int b;
while((b=in.read(tt))!=-1){
System.out.println(b);
String tzt=new String(tt,"utf-8");
System.out.println(tzt);
3.read(byte[] b, int off, int len)
此方法其实就是多次调用了read()方法
InputStream in = Test.class.getResourceAsStream("/tt.txt");
//System.out.println(in.available());//此方法是返回这个流中有多少个字节数,可以把数组长度定为这个
byte[]tt=new byte[in.available()];
int z;
while((z=in.read(tt, 0, tt.length))!=-1){
System.out.println(new String(tt,"utf-8"));
}
以上是关于java问题,byte a=1,b=1;byte c=a+b;为啥错的主要内容,如果未能解决你的问题,请参考以下文章