海量存储智能扩容,这款数据库架构为何深受用户喜爱?
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量存储智能扩容,这款数据库架构为何深受用户喜爱?相关的知识,希望对你有一定的参考价值。

导语 | 数据库正处在变革期,变革的动力同时来自于外因和内因,外因是用户需求的变化,内因是新技术的爆发。用户需求从强调物理上拥有数据到逻辑上拥有数据,因此云服务的形式被越来越广泛地接受;新技术的爆发体现在新的存储介质的产品化。腾讯云原生数据库就是这种变革的产物,腾讯云原生数据库以云服务的方式提供更好的数据库性能,可用性和可靠性。本文由腾讯云数据库技术总监 张青林在 Techo TVP开发者峰会「数据的冰与火之歌——从在线数据库技术,到海量数据分析技术」 的《腾讯云TDSQL-C架构探索和实践》演讲分享整理而成,为大家详尽介绍腾讯云原生数据库的架构、在核心指标上的突破以及探索。
点击可观看精彩演讲视频
一、腾讯云原生数据库的前世今生
我们今天的分享主要由三部分组成,第一部分是我们做TDSQL-C这款产品的背景,即为什么做TDSQL-C、它的架构和现状如何。第二部分主要介绍TDSQL-C有哪些突破性的创新,以及从用户视角来看我们主要做了哪些可以方便用户的事。第三部分是TDSQL-C未来的RoadMap,偏技术。
首先看第一点。我们之前是做CDB的产品运营研发相关工作,但在做的时候遇到了一些在传统数据库领域难以解决的问题:首先是存储容量问题,当单机磁盘容量达到一定程度时,就会对业务带来相应的麻烦。第二个是扩展性,熟悉数据库运维的朋友应该知道,典型的场景是在业务有活动的时候我们加机器,在业务活动结束之后要减机器,它的过程一般是经过备份、组件、实例,效率较差。第三是可用性,典型的就是灾备,从DBA的角度来看,灾备发生HA的时候,这个时间点是不可控的。第四是可靠性,因为单机传统的mysql架构,它的一主一备,并且存储是在本地存储,当我们本地磁盘损坏的时候,它的数据可靠性会有问题,传统的MySQL做数据备份以及数据恢复,如果出现了大数延迟或者DDL这种问题的时候,这个时候如果再发生HA,那么此时数据库服务实际上是不可用的。
基于在传统数据库领域运维遇到的问题,再结合业内的一些架构,我们自主研发了腾讯的一种存储和分离的数据库产品。
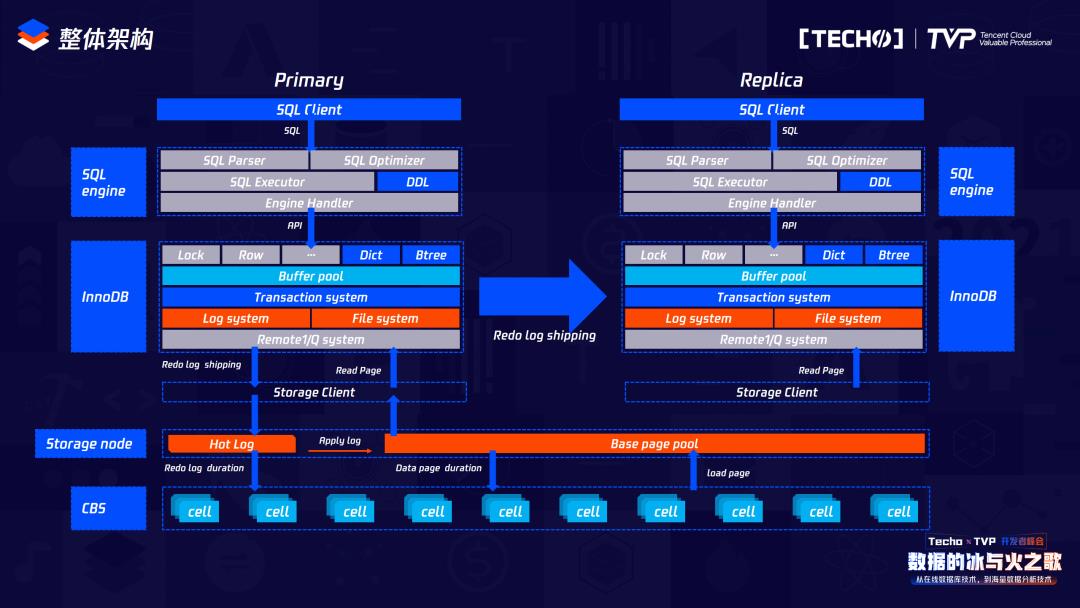
这是我们整体TDSQL-C的架构图,它和传统的MySQL类似,支持一个读写节点、多个备库节点,备库节点最多可以支持15个读节点。它分为计算和存储两部分,计算节点主要负责数据库的传统业务逻辑领域,包括像事务、锁以及常用的DML,传统数据库领域里所有在数据库的操作,除了两部分不在计算层以外,其他都在计算层,计算层不负责数据的持久化操作,数据的持久化操作会下发到存储层,存储层来负责数据的持久化操作。存储层是 HiStore (网络存储),本身最大支持的存储规模现在有1PB。而主备之间和原生MySQL不同的是它使用Redo log进行主备数据同步,Redo log发送到备库之后只负责同步备库之间的BP。
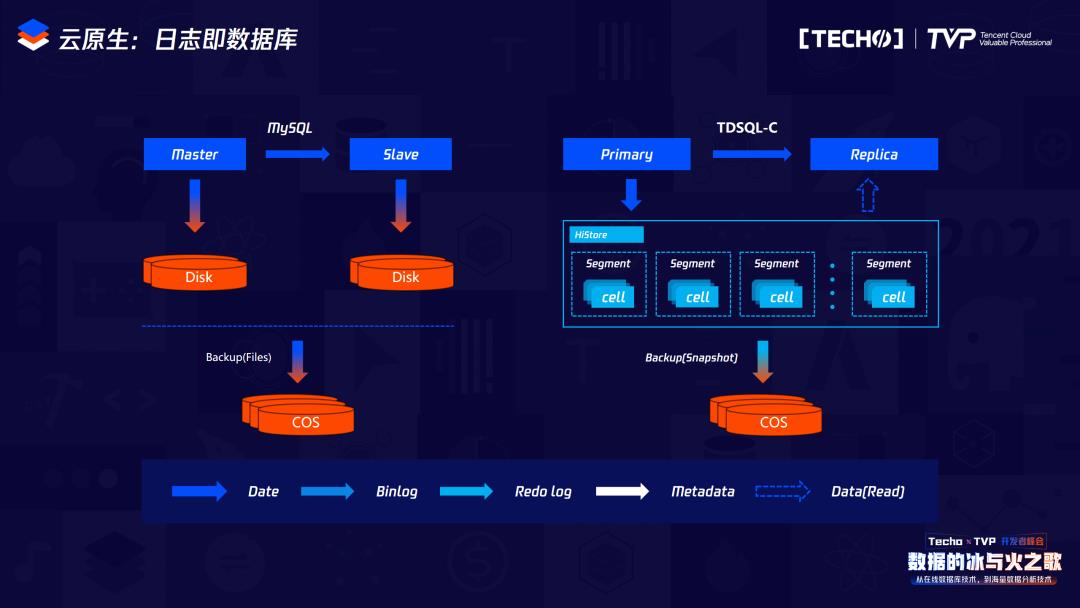
我们来看整体原生的MySQL一主一备的架构和现在TDSQL-C的架构。原生的MySQL里的存储是在本地进行的,依赖于本地的Dict存储,受限于本地的存储空间;TDSQL-C里的存储是网络云盘,它分为两级存储,上面是HiStore,负责存储数据,下面负责存储备份。
它的计算和存储分离,但是计算节点的主备节点会共享存储,就是下面这个HiStore。和传统MySQL架构不同,它是一个可计算存储,体现了两点:主节点的计算节点会把产生的Redo日志下发到存储层,存储层会依赖于它的Base page以及所产生的Redo log来负责数据的持久化操作,存储层在收到Redo log后才会向计算层反馈信息,说明Redo log已经持久化,证明现在的事务已经结束,可以让业务逻辑继续进行。业务逻辑在进行的同时,存储层会异步处理Redo log,计算中存储下来的Redo log共同生成新的,由这个新的持久化到HiStore里负责,从而将数据持久化操作。所以它和传统的CDB或传统的MySQL架构下面没有数据的持久化操作,也就不会有WAL带来的一些性能抖动问题。
在HiStore把数据持久化之后,会把之前Redo log所占的内存空间回收。而我们的存储也有以下特性:我们在把本地磁盘映射到网络存盘时,是根据它的物理地址映射到底下存储空间的某一个cell中,所以它的日志是按照页面来进行分发,每一个cell里都有相应的数据页和Redo log,因为子节点和主节点是共享存储数据的,所以要求我们的存储支持数据多版本,它的数据多版本是由我们的Base page加上从计算中传递下来的Redo log共同生成的一个具有指定版本的数据来进行的。
刚才介绍了我们本身的架构,而从整体上的架构来看,TDSQL-C有以下特性:第一是海量存储、智能扩容。存储由HiStore支持,网络存储最大可支持1PB,相对于现在单机容量几十T或者几T来说,不是一个级别的。第二是我们整体的QPS存储量可以达到百万级别,所以它的性能也得到了线性扩充。第三是兼容MySQL和PG,也没有分布式事务锁带来的一些问题,不进行数据分片,所以是天然支持分布式的。其次是扩展性,相对于传统的CDB架构或者传统RDS架构来说,它不依赖于本地的物理备份或者逻辑备份导数据来进行扩容,而是直接从文件系统做一个快照,快照加上Redo log来做扩容,所以整个扩容的时间基本在一分钟以内,可以说是秒级扩容。再次是和Serverless、备份以及故障切换相关的,我们下面一一来看。
二、腾讯云原生数据库在核心指标上的突破
1. 突破一
这是整体上TDSQL-C的一些架构和所支持的特性,也是我们的现状。在实现TDSQL-C这款计算和存储分离的分布式产品里,我们为解决用户实际问题而做的一些特性:
首先是Serverless场景。在支持Serverless之前,我们在做业务开发和运维时,会先购买一个计费的数据库实例,包括存储空间、网络存储空间和计算资源,都会从购买的这一刻起开始计费。但是在业务开发的时候肯定是属于低频使用时期,那么在我们整体的开发场景,使用数据库的场景较少,在Serverless场景下会根据你所使用的时间来进行计费,每5秒对这个实例打一个点,一分钟内会有12个点,一小时之内有720个点,真正在打点的时候使用时间才会作为真正的计费时间。在Serverless场景之下买一个实例时,你会有一个计算资源和一个存储空间,真正使用时是全部计费的,但你不使用时,它的计费空间只是存储空间,所以能降低我们的消费,并且用户利润可以达到最大化。
也不用关心什么时候启动和关闭Serverless,当对它没有访问的时候就自动关闭,当再一次发送请求时,我们会有中间的方式来自动界定它需要再次访问,那么它会迅速的把这个实例拉起来。所以它有两个特性,第一个是智能极致弹性:极速启停,第二个是真正的按使用计费。
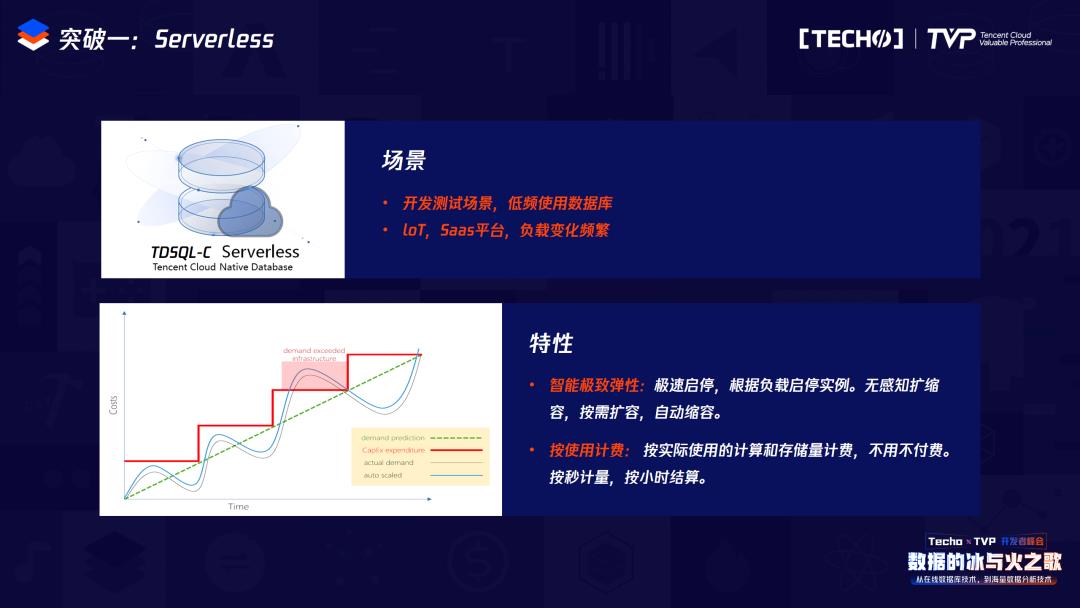
为了实现Serverless,我们做了以下事情。由于我们是本地网络,所以网络延迟会增加,为了实现极速启停,我们把BP独立在MySQL之外,在购买MySQL实例的或在创建BP的时候,实际上它是独立于MySQL进程之外的。
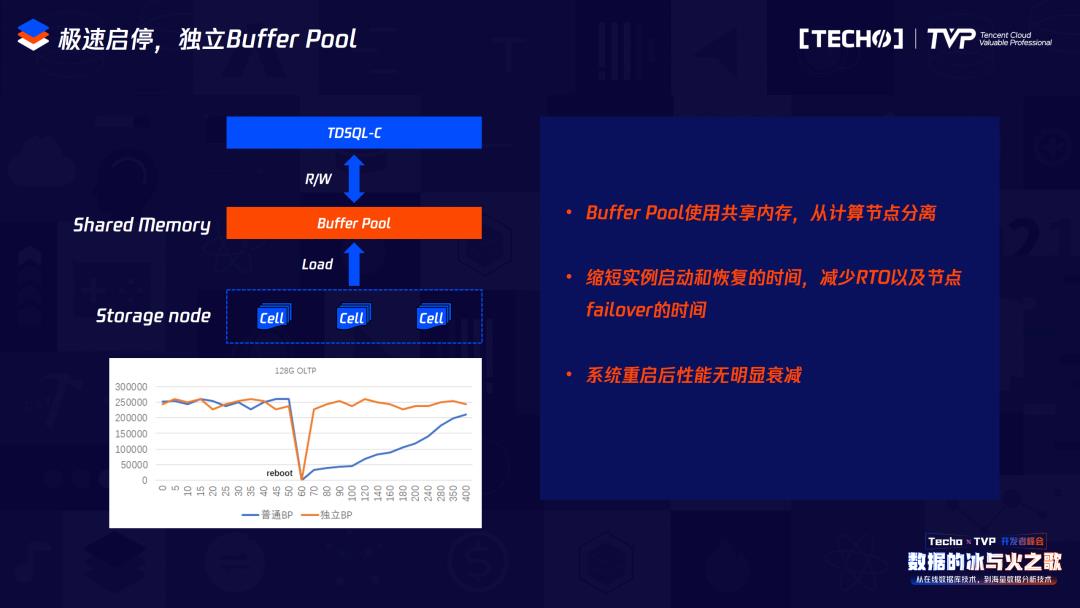
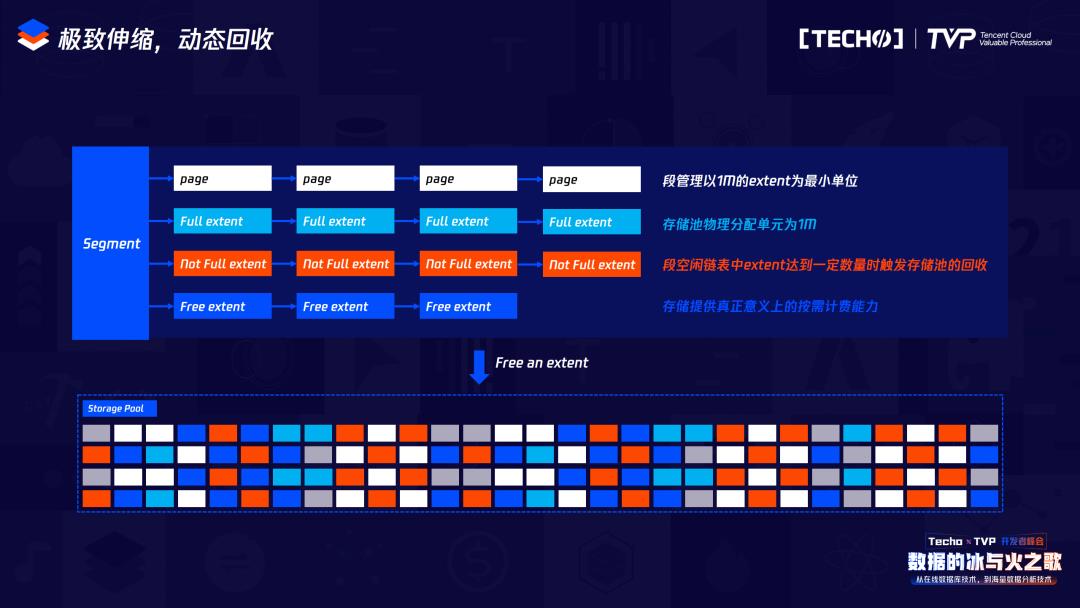
因为分析到整个MySQL启停过程中耗时间,我们也做了并行化处理,为了能够满足真正的“所用即所费”。因为在MySQL里创建一个表,这时会预先分配表的空间,无论用或不用,这些空间都会作为使用空间,我们在分配空间的时候是以exten或者1兆来进行分配的,如果你没有使用这1兆的话,那么这1兆就不会在你的计费空间以内,只有真正当你写数据在1兆空间的某一页时,才会真正灾容计费存储量。所以从用户的角度出发,把用户的计费存储量基本降到最低,后续我们还会继续优化,真正做到页级别的使用计费。
2. 突破二
我们单机容量可能在几G或几十G,这个时候它的内存是比较小的,比如只有几百个G的内存或者不到一个T,但是存储空间可能会有几百个T,这时属于典型的IO Bound类型,为了解决这个问题,我们把这种BP内存放到本地做二级缓存,在IO Bound场景之下,实际上并不是淘汰,而是把它淘汰到我们本地的SSD存储或者本地的AEP存储,下次用的时候,可以直接从本地读取,这样就可以最大限度降低网络IO的消耗。在我们的测试场景里,当命中率比较低,甚至在50%以下的时候,整体的性能是呈指数级性能提升的。
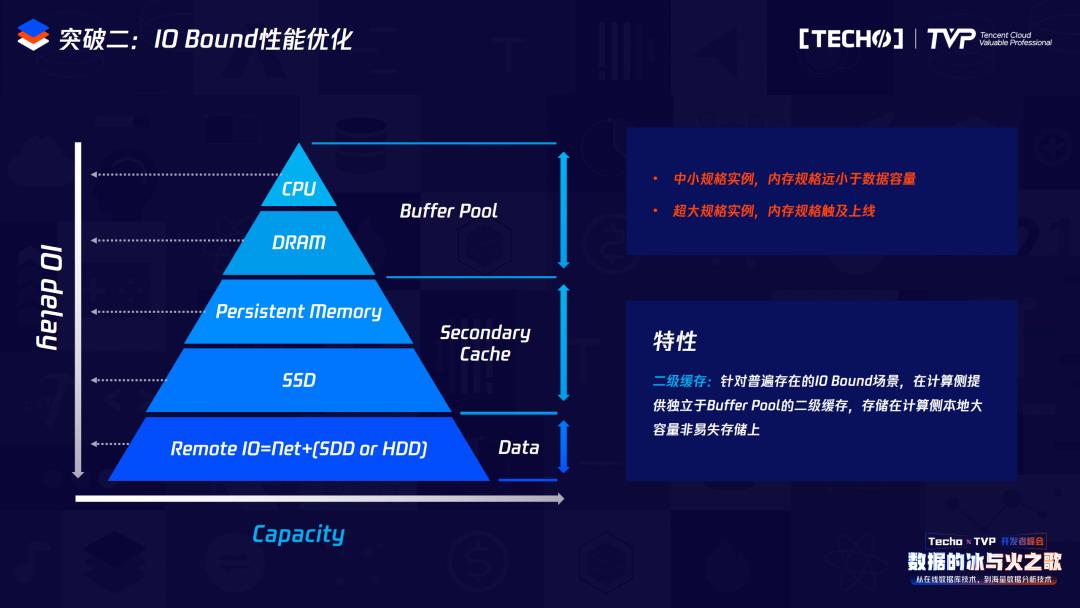
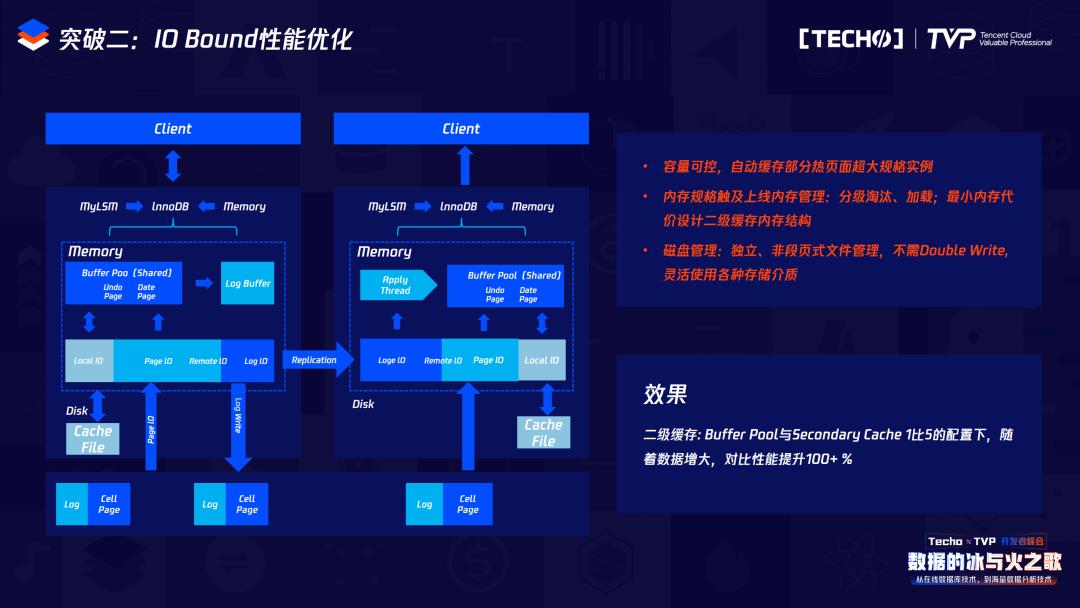
另外是我们越来越本地的磁盘空间做二级缓存的时候,首先是容量可控的,可以自动配置这一块占用多大的存储空间作为本地BP的二级缓存。内存规格以及内存管理也和BP的内存管理是类似的,淘汰的时候会首先淘汰本地的二级缓存,当本地文件不够大的时候,它也会遵循一系列淘汰算法来进行淘汰。磁盘管理独立于本地文件,所以它走的不是网络IO,那么用本地IO可以弥补整体网络IO的消耗,因此整体性能的收益比较明显。这张图就是我们本地二级缓存的架构图。
3. 突破三
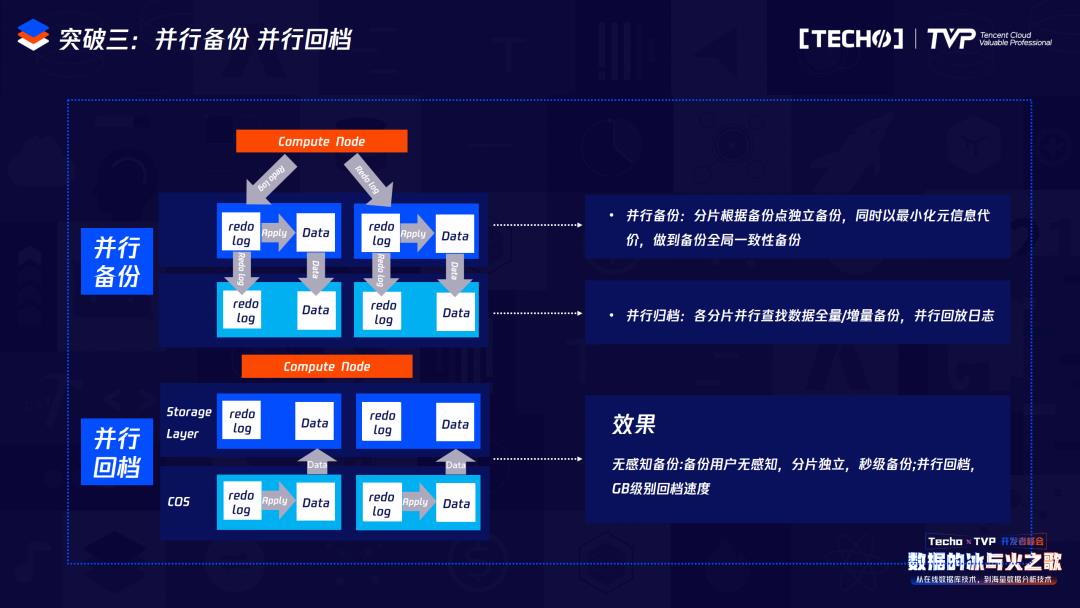
突破三是无感知备份。传统CDB架构或传统RDS架构,我们在做备份时一般都使用逻辑备份或者物理备份,这里面会有典型的两个问题,无论是逻辑备份还是物理备份,都涉及大量的IO操作,会极大占用集体资源。为了获取位点做之后的增量备份,会有一把大锁。
我们在备份中追求两个目标:第一是无感知备份,让用户没有察觉;第二是极速回档,因为在传统的备份恢复时,恢复是基于本地的,如果是逻辑备份,要导数据,如果是物理备份,要拷贝数据,再加上增量备份。所以我们的目标是无感知备份和极速回档,真正做到这两个才能实现秒级扩容。
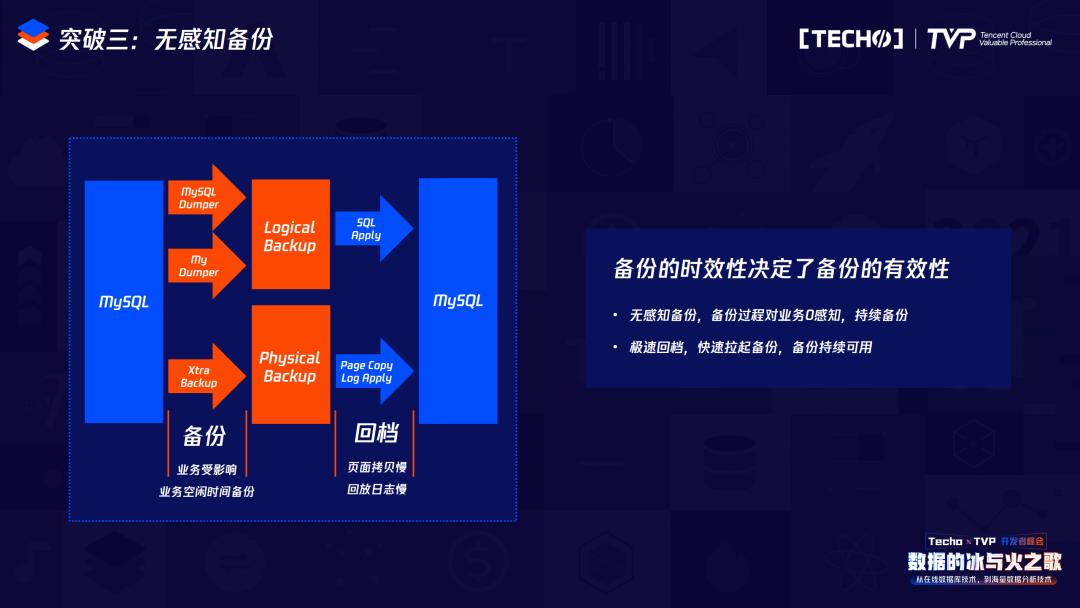
这就是在TDSQL-C里的备份和回档,备份实际上是依赖于HiStore做的文件系统的快照备份,相当于我如果发送一个备份命令,这时首先会对我之前的HiStore打一个快照,之前的写操作会写到新的数据存储的地方,那么在备份时就会直接拷贝我原先的数据,同时把它上传到COS里,因为我们底层的备份是分散到多个cell里,所以备份也是并行备份。在回档的时候也属于并行回档,它得把Redo log下发到cell里,那么这个cell包含原始数据以及Redo log,它在回档的时候每个cell会自行来应用这些Redo log。所以无论是备份还是回档,我们都是实现并行的,并且在回档的时候不是像Binlog的逻辑修改,而是直接定位到一些物理修改,回档速度也是GB级的。依赖于本地的可计算存储以及HiStore的一系列特性,我们可以实现自动的无感知备份以及秒级回档。
三、TDSQL-C的未来探索
基于我们现在所做的一系列事情,一方面是0-1,另一方面是结合在运维过程中遇到的问题,TDSQL-C后续的发展方向有两点:第一点是极简数据库运维。从运维的角度来鉴定之后的发展方向,首先是智能挑战,用过MySQL或CDB的人都应该会在MySQL的优化器上遇到一些问题,比如升级时发现它的执行计划走错,或者当数据量达到一定程度的时候执行计划也会走错,TDSQL-C的内核会在优化器里优化整体的统计信息,并且对它的执行计划进行判定,动态调优。比如在升级的时候,如果发现它的执行计划出错,可以自动对它进行纠正,并且发给运维。
因为在实现计算和存储分离产品的时候我们对内核的代码修改量较大,并且要增加存储量,在读写极致性能优化上我们也做了相应的修改,所以我们为了保证它的逻辑严谨性也会做相应的事,包括会引入业界相关的设施,从原理上进行把控对于内核的修改。从成本的角度来看,在Serverless场景下成本大部分是存储所带来的,所以要降低用户的成本。可以从两方面:一方面是用户真正用的才是他所需要付费的内容。这里有一个存储空间的概念,存储空间我们要真正做到页级别,另外一种现在是三副本,可以通过数据压缩存储、纠删码等技术降低存储空间,把本身的灾容数据存储空间降低在1/3左右,这也是我们后续的一个发力方向。
第三点是效率问题,因为做DDL,当我们单机单表容量达到上T级别的时候,在MySQL内部会首先扫描它的索引,来扫描所有这个索引相关的数据,每个进行排序,再做归并排序,再建立索引,这一系列的过程实际上是很费时的。针对这种操作,我们有两方面的优化思路:第一方面是instant DDL,对于每个字节所占用大小之间的改变,会支持更多的instant DDL。第二是通过它创建索引的这个过程,会把刚才所涉及到的像扫描B树、排序、建B+树这一系列过程全部并行化,如果能够走instant DDL的,可以实现秒级 ddl 操作,如果不能走instant DDL的操作,会进行parallel index 处理。

面向业务的Low Database开发,特别是在TDSQL-C这款产品里,数据存储规模会比较大,比如上几百个T或者类似于最大容量的P级别,那么这个时候数据分析能力就要提升,首先我们会提升它的最大存储量,通过优化器以及并行执行框架,最大限度地使用机器的资源来提升单机存储量。我们在存储方面会利用新的介质,比如AEP或者SSD,来极大提升本地的比如刚才所介绍的二级缓存,或者是把一系列可以在本地操作的做到最大加速。
从业务类型来看,比如金融或是政务容灾合规这类业务,我们会进行全链路审计,包括字段加密,同时也会就全球异地容灾、就近访问的原则优化 TDSQL-C 的产品能力。

最后是会在TDSQL-C产品里集成AP的能力,我们现在正在开发一款列存产品,内置到TDSQL-C里,在本地用列存来启动整个场景加速。
讲师简介

张青林
腾讯云数据库技术总监
腾讯云数据库CDB、TDSQL-C数据库内核研发负责人。腾讯云数据库技术总监,腾讯云布道师,MySQL架构师,现腾讯云架构平台部云原生数据库内核研发团队技术负责人,Mariadb 基金董事会 & Mariadb 社区版本开发成员,专注于MySQL内核开发和相关架构、产品化工作。
点击观看峰会的精彩总结视频????

以上是关于海量存储智能扩容,这款数据库架构为何深受用户喜爱?的主要内容,如果未能解决你的问题,请参考以下文章