一篇文章搞懂京东面试真题解析,太牛了!
Posted Java范德萨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇文章搞懂京东面试真题解析,太牛了!相关的知识,希望对你有一定的参考价值。
前言
统一说明一下,楼主是研究生,一般的985毕业,之前在工作了6年,做过的大项目数不胜数,
比如再造淘宝项目落地实战,某滴网约车项目,多人在线即时对战网游服务器,和家云服务平台,前后端分离某喵微信商城,亿级流量多级缓存平台,亚马逊电商个性化推荐系统,IOT流云式平台,阿里巴巴中台实战,年初跳槽后去阿里面试6轮之后定级是P6。
缓存雪崩
缓存雪崩指的是Redis当中的大量缓存在同一时间全部失效,而假如恰巧这一段时间同时又有大量请求被发起,那么就会造成请求直接访问到数据库,可能会把数据库冲垮。
缓存雪崩一般形容的是缓存中没有而数据库中有的数据,而因为时间到期导致请求直达数据库。
解决方案
解决缓存雪崩的方法有很多:
-
1、加锁,保证单线程访问缓存。这样就不会有很多请求同时访问到数据库。
-
2、失效时间不要设置成一样。典型的就是初始化预热数据的时候,将数据存入缓存时可以采用随机时间来确保不会咋同一时间有大量缓存失效。
-
3、内存允许的情况下,可以将缓存设置为永不失效。
缓存击穿
缓存击穿和缓存雪崩很类似,区别就是缓存击穿一般指的是单个缓存失效,而同一时间又有很大的并发请求需要访问这个key,从而造成了数据库的压力。
解决方案
解决缓存击穿的方法和解决缓存雪崩的方法很类似:
-
1、加锁,保证单线程访问缓存。这样第一个请求到达数据库后就会重新写入缓存,后续的请求就可以直接读取缓存。
-
2、内存允许的情况下,可以将缓存设置为永不失效。
缓存穿透
缓存穿透和上面两种现象的本质区别就是这时候访问的数据其在数据库中也不存在,那么既然数据库不存在,所以缓存里面肯定也不会存在,这样如果并发过大就会造成数据源源不断的到达数据库,给数据库造成极大压力。
解决方案
对于缓存穿透问题,加锁并不能起到很好地效果,因为本身key就是不存在,所以即使控制了线程的访问数,但是请求还是会源源不断的到达数据库。
解决缓存穿透问题一般可以采用以下方案配合使用:
-
1、接口层进行校验,发现非法的key直接返回。比如数据库中采用的是自增id,那么如果来了一个非整型的id或者负数id可以直接返回,或者说如果采用的是32位uuid,那么发现id长度不等于32位也可以直接返回。
-
2、将不存在的数据也进行缓存,可以直接缓存一个空或者其他约定好的无效value。采用这种方案最好将key设置一个短期失效时间,否则大量不存在的key被存储到Redis中,也会占用大量内存。
布隆过滤器(Bloom Filter)
针对上面缓存穿透的解决方案,我们思考一下:假如一个key可以绕过第1种方法的校验,而此时有大量的不存在key被访问(如1亿个或者10亿个),那么这时候全部存储到缓存,会占用非常大的空间,会浪费大量服务器内存,导致内存不足。
那么有没有一种更好的解决方案呢?这就是我们接下来要介绍的布隆过滤器,布隆过滤器就可以最大程度的解决key值过多的这个问题。
什么是布隆过滤器
可能大部分人都知道有这么一个面试问题:如何在10亿的海量的无序的数据中快速判断一个元素是否存在?
要解决这个问题就需要用到布隆过滤器,否则大部分服务器的内存是无法存储这么大的数量级的数据的。
布隆过滤器(Bloom Filter)是由布隆在1970年提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率而且删除困难。
位图(Bitmap)
Redis当中有一种数据结构就是位图,布隆过滤器其中重要的实现就是位图的实现,也就是位数组,并且在这个数组中每一个位置只有0和1两种状态,每个位置只占用1个字节,其中0表示没有元素存在,1表示有元素存在。如下图所示就是一个简单的布隆过滤器示例(一个key值经过哈希运算和位运算就可以得出应该落在哪个位置):
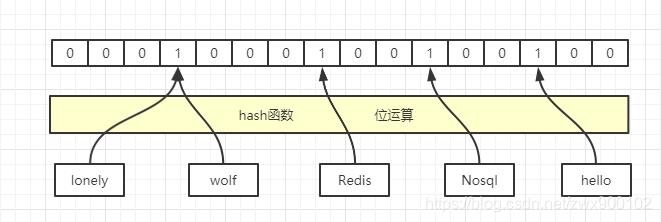
哈希碰撞
上面我们发现,lonely和wolf落在了同一个位置,这种不同的key值经过哈希运算后得到相同值的现象就称之为哈希碰撞。发生哈希碰撞之后再经过位运算,那么最后肯定会落在同一个位置。
如果发生过多的哈希碰撞,就会影响到判断的准确性,所以为了减少哈希碰撞,我们一般会综合考虑以下2个因素:
-
1、增大位图数组的大小(位图数组越大,占用的内存越大)。
-
2、增加哈希函数的次数(同一个key值经过1个函数相等了,那么经过2个或者更多个哈希函数的计算,都得到相等结果的概率就自然会降低了)。
上面两个方法我们需要综合考虑:比如增大位数组,那么就需要消耗更多的空间,而经过越多的哈希计算也会消耗cpu影响到最终的计算时间,所以位数组到底多大,哈希函数次数又到底需要计算多少次合适需要具体情况具体分析。
布隆过滤器的2大特点
下面这个就是一个经过了2次哈希函数得到的布隆过滤器,根据下图我们很容易看到,假如我们的Redis根本不存在,但是Redis经过2次哈希函数之后得到的两个位置已经是1了(一个是wolf通过f2得到,一个是Nosql通过f1得到)。
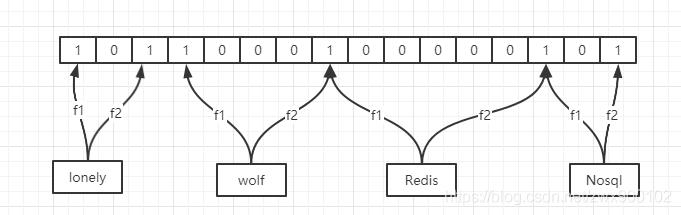
所以通过上面的现象,我们从布隆过滤器的角度可以得出布隆过滤器主要有2大特点:
-
1、如果布隆过滤器判断一个元素存在,那么这个元素可能存在。
-
2、如果布隆过滤器判断一个元素不存在,那么这个元素一定不存在。
而从元素的角度也可以得出2大特点:
-
1、如果元素实际存在,那么布隆过滤器一定会判断存在。
-
2、如果元素不存在,那么布隆过滤器可能会判断存在。
PS:需要注意的是,如果经过N次哈希函数,则需要得到的N个位置都是1才能判定存在,只要有一个是0,就可以判定为元素不存在布隆过滤器中。
fpp
因为布隆过滤器中总是会存在误判率,因为哈希碰撞是不可能百分百避免的。布隆过滤器对这种误判率称之为假阳性概率,即:False Positive Probability,简称为fpp。
在实践中使用布隆过滤器时可以自己定义一个fpp,然后就可以根据布隆过滤器的理论计算出需要多少个哈希函数和多大的位数组空间。需要注意的是这个fpp不能定义为100%,因为无法百分保证不发生哈希碰撞。
写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!有需要的朋友可以戳这里免费获取
Java经典面试问题(含答案解析)
阿里巴巴技术笔试心得

Java经典面试问题(含答案解析)
[外链图片转存中…(img-lYF6SaxW-1621315110549)]
阿里巴巴技术笔试心得
[外链图片转存中…(img-iSHu5Grm-1621315110552)]
以上是关于一篇文章搞懂京东面试真题解析,太牛了!的主要内容,如果未能解决你的问题,请参考以下文章