打怪升级之小白的大数据之旅(四十九)<MapReduce框架原理一:MapReduce工作流程&InputFormat>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(四十九)<MapReduce框架原理一:MapReduce工作流程&InputFormat>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(四十九)
MapReduce框架原理一:MapReduce工作流程&InputFormat
上次回顾
- 上一章我们整体的认识了一下MapReduce,通过案例来认识MapReduce的核心思想,本章开始,我会对MapReduce的框架中的各个模块进行详细的讲解,里面也会有一些相关的源码,大家不要慌,看源码是学习大数据必不可少的内容,我会循序渐进的带大家来认识MapReduce框架、认识大数据
MapReduce框架整体认知
首先看图:
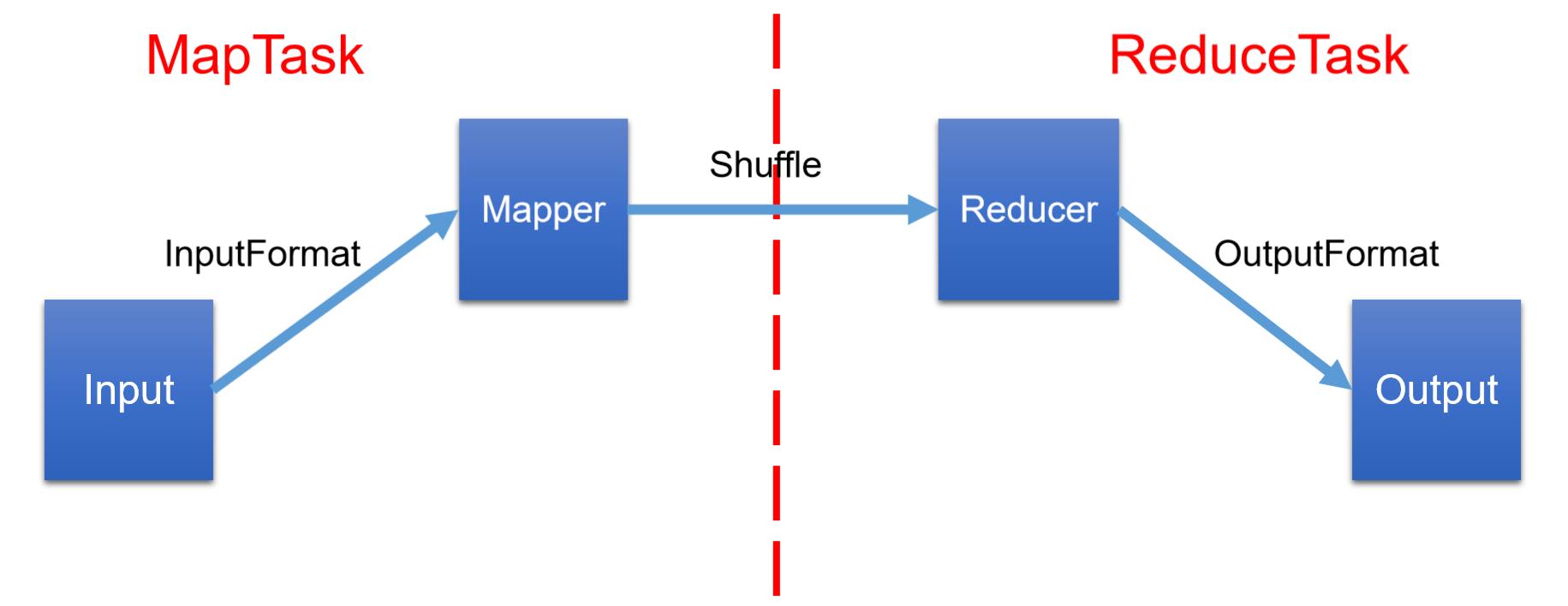
图例讲解:
- MapReduce的数据输入输出都是依靠IO流的方式进行的,所以我们需要了解InputFormat数据输入的原理以及OutputFormat数据输出的原理
- 在上一章的案例中,我们对数据的处理分为两步:一个是map阶段,一个是reduce阶段,map阶段用于数据的运算逻辑,reduce阶段用于对运算的结果进行汇总
- 中间的shuffle我会单独来将
接下来,从以下几个维度来介绍MapReduce
1.从流的角度:
Input ---> InputFormat ---> Mapper ---> Shuffle ---> Reducer --->OutputFormat --->Ouput
2.从不同阶段的角度:
Map ---> Shuffle(Map阶段的后半部分+Reduce阶段的前半部分) ---> Reduce
3.从源码的角度:map ---> sort ---> copy ---> sort ---> reduce
Map阶段:map ---> sort
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
Reduce阶段:copy ---> sort ---> reduce
copyPhase = getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase = getProgress().addPhase("reduce");
MapReduce工作流程
下面的两个图就是MapReduce完整的工作流程,我先大概介绍一下,具体的流程我会挨个进行介绍
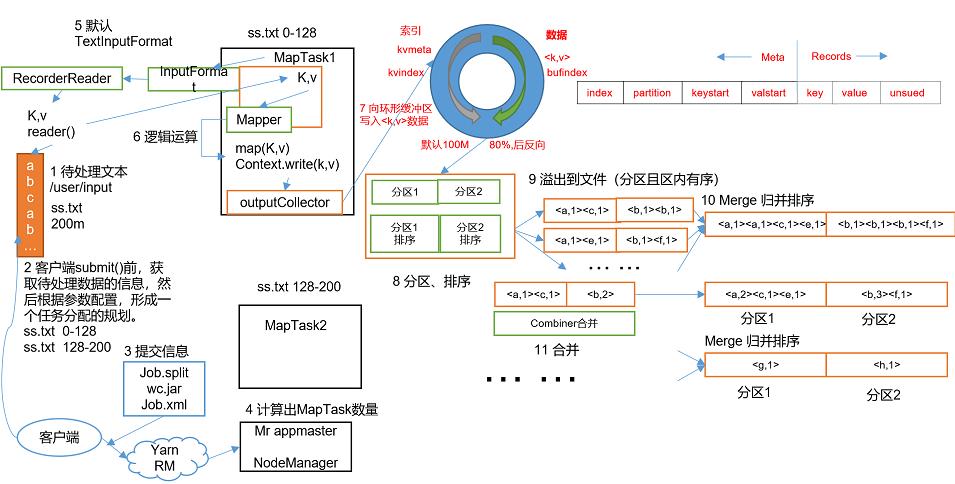
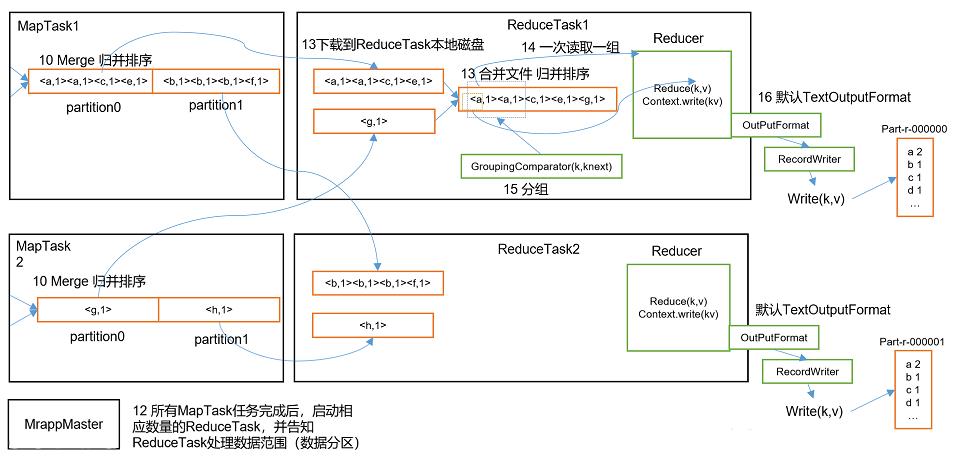
MapReduce整体的工作流程
- 待处理文本,此时,利用InputFormat对我们需要操作的文件进行读取
- 配置信息,在我们前面的案例 Driver类中配置的信息进行的就是这个工作,它的作用就是形成一个任务分配的规划
- 这一步就是Driver类中最后一步,提交任务,将我们的任务交给Hadoop进行运行,它提交的任务(job)里面包含了三个部分:job.split、xx.jar、job.xml,后面我会详细讲解
- 计算出mapTask数量,mapTask就是将这个任务分配给谁来做
- MapReduce默认使用TextInputFormat中的LineRecoderReder类进行数据的读取
- 读取到的数据交给Mapper类中的map方法进行运算
- 然后将运算后的k,v交给环形缓冲区并分配分区号用于进行分区
- 环形缓冲区进行分区排序
- 将排序后溢出的数据写入到磁盘中
- 每个分区中的MapTask对数据进行归并排序(Merage)
- 所有的MapTask任务完成后,启动相应数量的ReduceTask,并告诉需要处理的数据范围
- 此时将数据写入到磁盘中
- ReduceTask对所有分区中的数据进行合并,并再次进行归并排序
- 最后利用OutputFormat流输出到output文件夹中
InputFormat
切片与MapTask并行度机制
聊这个话题前,我们先要知道下面两个小知识点:
- 数据块:Block是HDFS物理上把数据分成一块一块
- 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储
在分芝麻那个案例中,我们将分芝麻的任务交给悟空等人(MapTask)完成,大大提高了分芝麻的效率,但并不是MapTask越多越好
举个栗子,1G的数据,启动了8个MapTask,1K的数据也启动了8个MapTask,我们知道启动MapTask时需要耗费资源,所以MapTask并不是越多越好
切片的原理
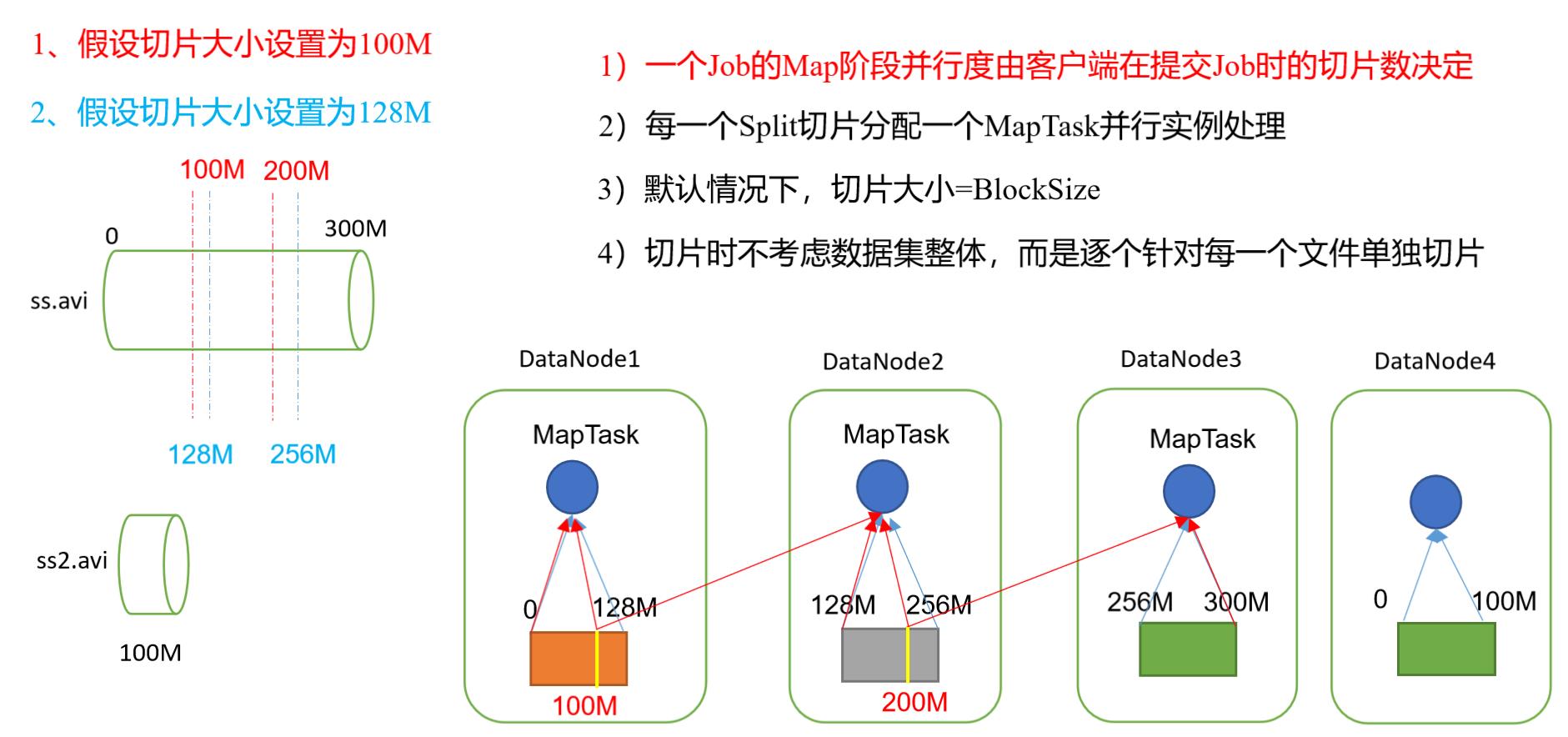
- 切片就是将我们的文件进行逻辑的切割,然后按每一片就是一个MapTask
- 默认切片大小等于文件的块大小,如果切片大小与块大小不一样就会造成跨节点访问,我们知道块的大小是128mb,假设我们切片大小是100mb,MapTask任务时需要进行数据的读取,那么当它创建第一个MapTask任务时,它读取了第一个块128mb数据中的100mb
- 第二个MapTask任务启动时就会读取上一个块中剩余的数据28mb数据,然后再读第二块的数据
- 第三个MapTask同样的需要先访问第二块中的剩余数据再读取第三块的数据
InputFormat继承关系
InputFormat的继承树
|----InputFormat(抽象类)
|-----FileInputFormat(抽象类)
|-----TextInputFormat(默认用来读取数据的类)
|-----CombineFileInputFormat(抽象类)
|-----CombineTextInputFormat(可以将多个小文件合并成一片进行处理)
- InputFormat的源码
InputFormat是一个抽象类,它有生成切片和创建读取对象createRecordReader两个方法
//获取切片信息
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
//获取RecordReader对象 ---该对象是真正用来读取数据的对象。
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
-
FileInputFormat(抽象类)
重写了getSplits方法,该方法用来生成切片信息 -
TextInputFormat(默认用来读取数据的类)
- 重写了createRecordReader方法,该方法返回了LineRecordReader
- LineRecordReader是RecordReader的子类。
- LineRecordReader是一行一行的读取数据的。
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
return new LineRecordReader(recordDelimiterBytes);
}
job提交流程源码
Job提交流程:
1.生成切片信息–并写到stag路径
2.生成配置信息–并写到stag路径
3.上传jar包 – 向集群提交job会向stag路径上传
源码如下:
/*
Job提交流程:
1.生成切片信息--并写到stag路径
2.生成配置信息--并写到stag路径
3.上传jar包 -- 向集群提交job会向stag路径上传
*/
//1.提交Job
job.waitForCompletion()
//1.1开始提交
submit();
//1.1.1设置使用新的API---考虑的是兼容性问题
setUseNewAPI();
//1.1.2建立连接---会创建一个根据不同场景(本地or集群)下提交Job的对象
connect();
// 1.1.2.1创建提交Job的代理
new Cluster(getConfiguration());
// 1.1.2.1.1判断是本地还是集群(如果是本地创建LocalJobRunner对象,如果是集群创建YarnRunner对象)
initialize(jobTrackAddr, conf);
//1.1.3提交job
submitter.submitJobInternal(Job.this, cluster)
//1.1.3.1创建给集群提交数据的Stag路径(如果是本地就在项目的的盘符中,
如果是集群就在HDFS上)
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//1.1.3.2获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
//根据jobStagingArea和jobId拼接起来的路径
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
//1.1.3.3拷贝jar包到集群(只要向集群提交那么会向HDFS上传jar包)
copyAndConfigureFiles(job, submitJobDir);
//1.1.3.3.1上传jar包
rUploader.uploadFiles(job, jobSubmitDir);
//1.1.4 计算切片,生成切片规划文件写到submitJobDir路径中
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 1.1.5 向submitJobFile路径写XML配置文件
writeConf(conf, submitJobFile);
//写配置文件
conf.writeXml(out);
// 1.1.6提交Job,返回提交状态(如果是本地submitClient就是LocalJobRunner,如果是集群submitClient是YarnRunner)
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
切片源码
切片流程:
1.获取文件路径、大小等参数
2.判断文件是否可切片(目录不可切)
3.获取块大小
4.计算切片大小
4.1 进行第一片的切割,并修改剩余大小
4.2 进行第二片的切割,并修改剩余大小...
4.3 最后一片的切割,将剩余的数据当成一片
源码如下:
/*
getFormatMinSplitSize() : 返回值为1
getMinSplitSize(job) : 如果对mapreduce.input.fileinputformat.split.minsize进行了设置
就返回设置的数值,如果没有设置就返回1
注意:如果想要修改minSize : 对mapreduce.input.fileinputformat.split.minsize设置即可
*/
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
/*
getMaxSplitSize(job) :如果设置了mapreduce.input.fileinputformat.split.maxsize
那么就获取设置的值,如果没有设置就返因Long.MAX_VALUE
注意:如果需要修改maxSize只需要设置mapreduce.input.fileinputformat.split.maxsize
*/
long maxSize = getMaxSplitSize(job);
//获取文件路径
Path path = file.getPath();
//获取文件大小
long length = file.getLen();
//判断文件是否可切
if (isSplitable(job, path)) {
//获取文件的块大小
long blockSize = file.getBlockSize();
//获取切片大小
/*
计算切片大小
默认 : 片大小 = 块大小
需求:
片大小 > 块大小 : 需要修改minSize的值即可
片大小 < 块大小 :需要修改maxSize的值即可
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
*/
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;//剩余文件大小
/*
(double) bytesRemaining)/splitSize > 1.1
目的 : 是让最后一片不会太小,如果最后一片太小会浪费资源
好处 :不会浪费MapTask资源
缺点 :会造成跨节点读数据(只会对最后一个MapTask造成跨节点读数据)
*/
//计算剩余文件是否可以切片
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//块的索引
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//生成切片信息
/*
splits :是集合用来装切片信息
makeSplit :该方法用来生成切片信息
参数1-path : 文件路径
参数2-length-bytesRemaining :片的起始位置
参数3-splitSize :切片大小(偏移量)
*/
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//重新计算剩余文件大小
bytesRemaining -= splitSize;
}
//将剩余的文件切成一片
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
}
CombineTextInputFormat切片机制
- 框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下,所以当我们有许多的小文件时,可以使用CombineTextInputFormat来完成我们的数据运算任务
- 我以4m大小为虚拟存储切片的最大值举例
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m

虚拟存储过程:
- 将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较
- 如果不大于设置的最大值,逻辑上划分一个块
- 如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块
- 当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片
- 例如:setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
切片过程:
-
判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
-
如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
-
测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M) -
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
TextInputFormat的KV
- MapReduce默认使用的是TextInputFormat,它是FileInputFormat的实现类,它的读取规则是按行进行读取
- TextInputFormat的键(key)默认是存储该行在整个文件中起始字节的偏移量,它是LongWritable类型
- TextInputFormat的值是这行的内容,不包括任何行终止符(例如换行符和回车符),默认是Text类型
总结
本章介绍了MapReduce的工作流程、InputFormat中切片的原理以及切片源码和Job的源码,看源码是为了辅助我们更加清晰地学习框架,了解框架运行的原理,从而更好让我们使用好框架,好了,本章内容就到这里,下一章我会为大家带来Shuffle机制
以上是关于打怪升级之小白的大数据之旅(四十九)<MapReduce框架原理一:MapReduce工作流程&InputFormat>的主要内容,如果未能解决你的问题,请参考以下文章