Go | string与UTF8编码
Posted Lindbergh_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go | string与UTF8编码相关的知识,希望对你有一定的参考价值。
字符表示
使用字符编号对照表,即收录很多字符,然后给他们一一编号。
字符集促进了字符与二进制的合作
ASCII字符集(1967年)只收录了128个字符,扩展字符集也就只有256个
英文字符、阿拉伯数字、西文符、控制字符
GB2312(1980年)添加了简体中文、拉丁字母、日文假名
BIG5(1984年) 添加了繁体字,但是依旧有很多字符没有被收录
GB13000.1(1993年) 添加了中日韩
GBK(1995年) 不支持韩文
GB18030(2000) 更多兼容
与其不断退出更多字符的字符集,莫不如本着全球化统一标准的目的,制作一个通用字符集。这个字符集就是Unicode
Unicode(1990-1994)实现了跨区语言跨平台的文本转换与处理
如何划分字符边界
- 直接照搬Unicode字符集进行拼凑,显然行不通,无法区分字符边界
定长编码
不管编号多大多小,统一按最长的来,位数不够高位补零。
虽然字符边界解决了,但是有些浪费内存。而且字符集收录的越多,字符跨度越大,定长编码造成的浪费就越显著
变长编码(UTF-8)
Go 语言默认的编码方式
小编号少占字节,大编号多占字节
那如何划分边界呢?
| 编号 | 编码模板 | – |
|---|---|---|
| [0,127] | 0??? | 占一字节,且最高位标识为0 |
| [128,2047] | 110??? 10??? | 占用两个字节,且有固定标识位110和10 |
| [2048,65535] | 1110??? 10??? 10??? | 占用三字节,且有固定标识位1110和10 |
| [65536,…] | 11110??? 10??? … | 三个以上字节也遵循这样的规则 |
除了固定标识位,其他的就是该字符的二进制编号
字符串类型的变量结构
源码包src/runtime/string.go:stringStruct定义了string的数据结构:
type stringStruct struct {
str unsafe.Pointer
len int
}
string 数据结构存放两个东西
- stringStruct.str:字符串的首地址
- stringStruct.len:字符串的长度
字符串的存储要用“字符集”配合“编码”才行
字符串构建过程是先根据字符串构建stringStruct,再转换成string。转换的源码如下:
func gostringnocopy(str *byte) string { // 根据字符串地址构建string
ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)} // 先构造stringStruct
s := *(*string)(unsafe.Pointer(&ss)) // 再将stringStruct转换成string
return s
}
string在runtime包中就是stringStruct,对外呈现叫做string。
为什么字符串不允许修改?
字符串不能够被修改,所以这样定义的字符串内容被分配到只读内存段,而不是堆或栈上
字符串变量是可以共享底层字符串内容的,如果对字符串修改,那么后果是无法估计的
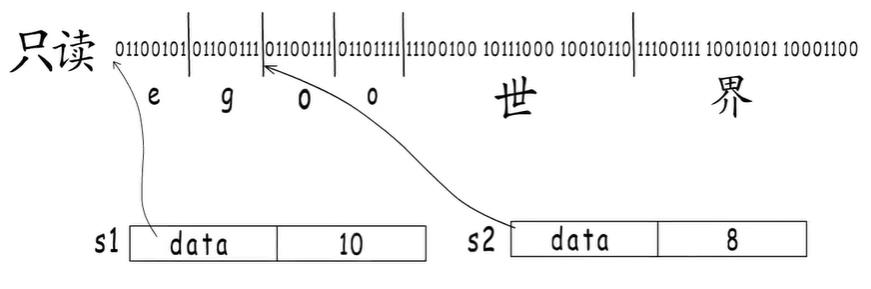
内存中这些读、写、执行等权限,是为了保护程序的正常运行
如果非要修改
- str = “hello” 使str重新分配内存,便不会修改原内存
- bs := ([]byte)(str) bs[2] = ‘o’ 可以把变量强制类型转换成字节slice,这样会为slice变量重新分配一段内存,并且会拷贝原来字符串的内容
注:了解slice的结构并且学会使用unsafe包,就可以让slice依然使用原来字符串指向的这段内存,这样虽然转换了内存,但是依然不能修改这段只读内存的内容
以上是关于Go | string与UTF8编码的主要内容,如果未能解决你的问题,请参考以下文章