今天清华大佬教你用Python爬虫,爬取腾讯视频评论,机会难得还不点击进来看看
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了今天清华大佬教你用Python爬虫,爬取腾讯视频评论,机会难得还不点击进来看看相关的知识,希望对你有一定的参考价值。
前提条件
我们就采用第二种方法,去js里面找。复制其中一个url为:
url = https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6460163812968870071&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1576567187273
去浏览器里面打开,在里面搜索一下此url的下一个url的cursor=?的值。我们发现一个惊喜!
如下:
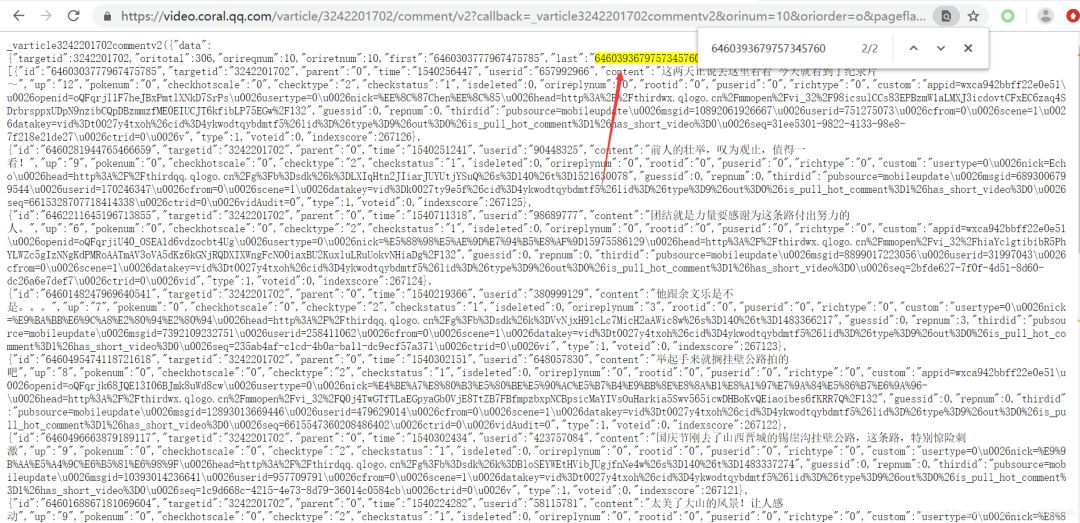
一般情况下,我们还要多试几次,确定我们的想法是正确的。
至此,我们发现了评论的url之间的规律:
三、代码编写

-
安装了Fiddler了(用于抓包分析)
-
谷歌或火狐浏览器
-
如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器
-
有Python的编译环境,一般选择Python3.0及以上
一丶分析思路
1、分析评论页面
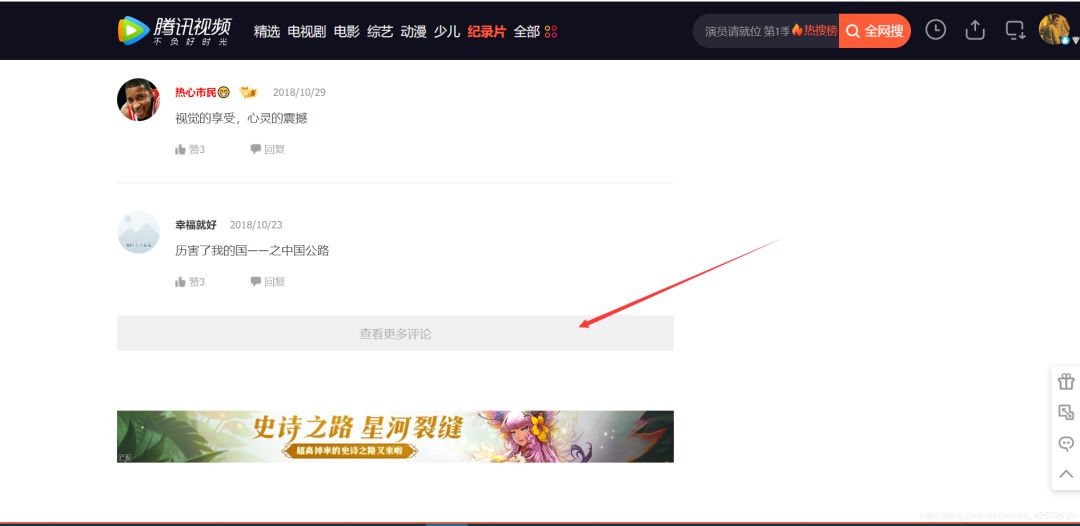
根据上图,我们可以知道:评论使用了Ajax异步刷新技术。这样就不能使用以前分析当前页面找出规律的手段了。因为展示的页面只有部分评论,还有大量的评论没有被刷新出来。
这时,我们应该想到使用抓包来分析评论页面刷新的规律。以后大部分爬虫,都会先使用抓包技术,分析出规律!
使用Fiddler进行抓包分析——得出评论网址规律
fiddler如何抓包,这个知识点,需要读者自行去学习,不在本博客讨论范围。
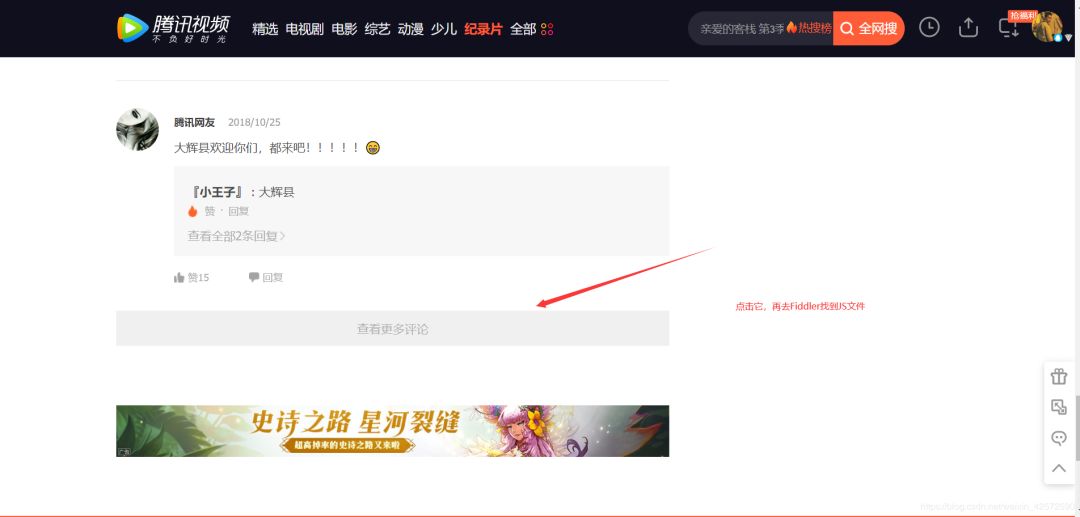
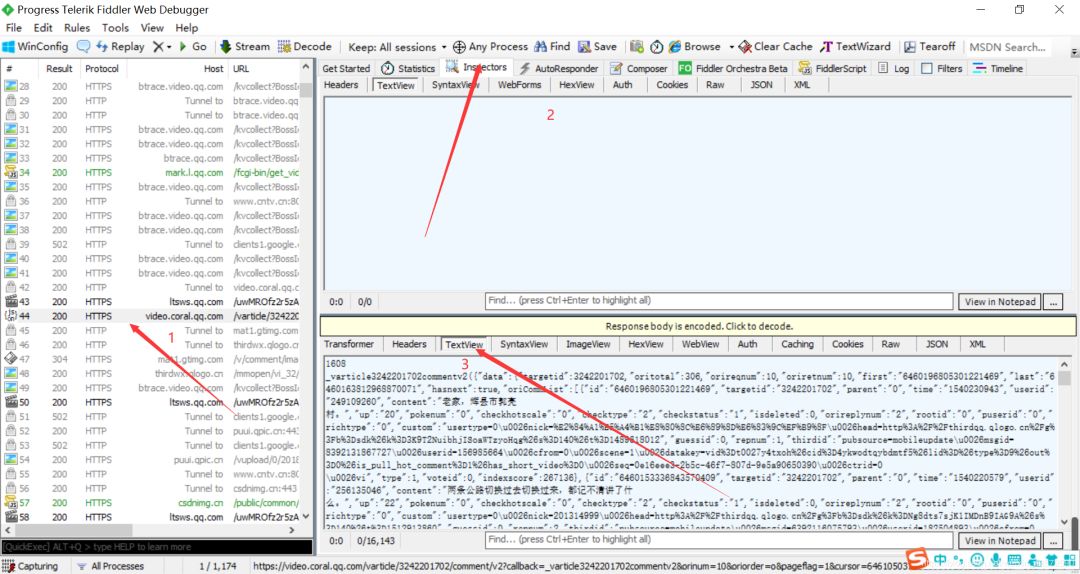
把上面两张图里面的内容对比一下,可以知道这个JS就是评论存放页面。(这需要大家一个一个找,一般Ajax都是在JS里面,所以这也找JS进行对比即可)
我们复制这个JS的url:右击 > copy > Just Url
大家可以重复操作几次,多找几个JS的url,从url得出规律。下图是我刷新了4次得到的JS的url:
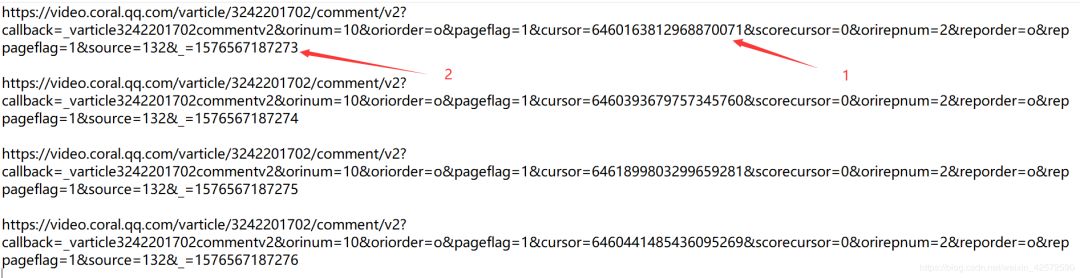
根据上图,我们发现url不同的地方有两处:一是cursor=?;二是_=?。
我们很快就能发现 _=?的规律,它是从1576567187273加1。而cursor=?的规律看不出来。这个时候如何去找到它的规律呢?
-
百度一下,看前人有没有爬取过这种类型的网站,根据他们的规律和方法,去找出规律;
-
羊毛出在羊身上。我们需要有的大胆想法——会不会这个cursor=?可以根据上一个JS页面得到呢?这只是很多大胆想法中的一个,我们就一个想法一个想法的试试。
-
_=?从1576567187273加1
-
cursor=?的值存在上面一个JS中。
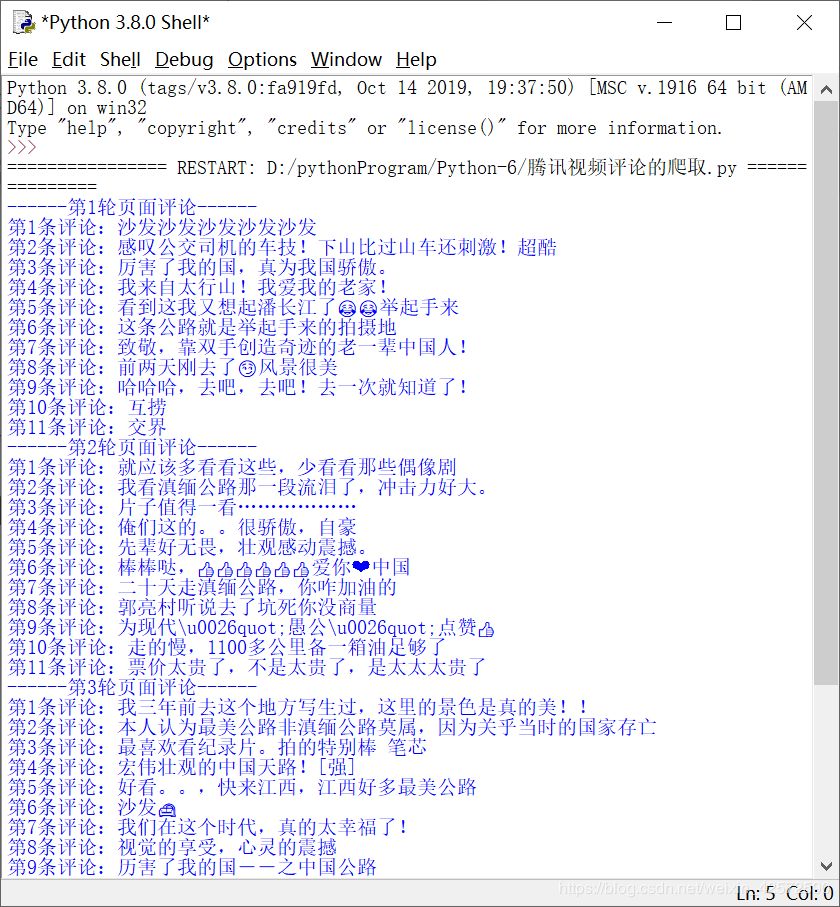
结果展示
若需要相关python爬虫资料的可以扫一扫备注【爬虫】

以上是关于今天清华大佬教你用Python爬虫,爬取腾讯视频评论,机会难得还不点击进来看看的主要内容,如果未能解决你的问题,请参考以下文章