小白也能上手的Python数据分析案例
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白也能上手的Python数据分析案例相关的知识,希望对你有一定的参考价值。
学习python的同学都会遇到这样一个困境:我已经看了无数的书籍,也练习过非常多的项目,但在面临一个新的数据分析问题时还是无从下手。
只有真正将输入的知识转化为输出,才算是真正掌握这项技能。
本文通过【泰坦尼克数据集】来做示例,通过对这个数据集的处理,手把手教你python数据分析,相信你在学完之后能够快速上手。
- python 安装 -
如果你还没有安装 Python 环境,那么推荐你安装 Anaconda,对于上手 Python 来说更加简单,不容易出差错。
Anaconda 的安装教程网上很多,进入Anaconda下载网址(https://www.anaconda.com/products/individual) ,找到对应版本客户端安装即可。安装好后,即可上手。
- 上手准备 -
开始python的第一步,一定是导入相关的库:
import pandas as pd
import numpy as np
读取前五行数据,分析数据特点:
file='titanic.csv'
df=pd.DataFrame(pd.read_csv(file))
df.head()
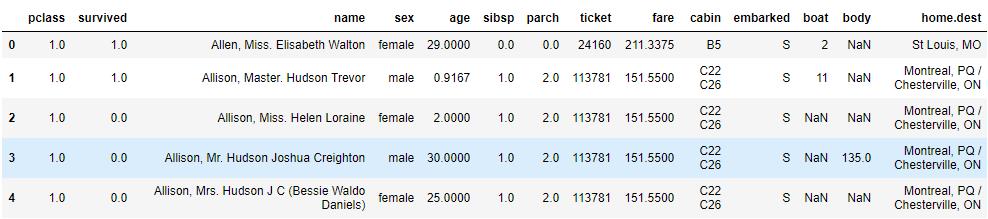
数据情况如下:
·survival - 是否幸存(0=幸存,1=遇难)
·pclass - 船票类型(1=一等票,2=二等票,3=三等票)
·sex - 性别
·age - 年龄
·sibsp - 泰坦尼克号上该人员兄弟姐妹的数量
·parch - 泰坦尼克号上该人员父母或者子女的数量
·ticket - 船票编号
·fare - 乘客票价
·cabin - 客舱号码
·embarked - 起航运港(C = Cherbourg, Q = Queenstown, S = Southampton)
·boat - 救生艇的编号(如果幸存)
·body - 人体编号(如果遇难并且尸体被找到)
·home.dest - 出发地到目的地
- 数据处理 -
数据查看
01 查看数据维度
df.shape
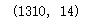
这是一个1310*14的数据集。
02 查看数据的整体分布
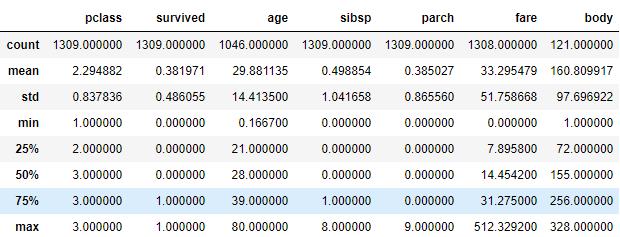
df.describe()
03 查看数据集的空值,或者说是缺失值
df.isnull().sum()
Age列有264个空值,Cabin有1015,Embarked有3个,boat有824个,body有1189个,home.dest有565个。

数据处理
如果不习惯英文,我们可以将标签替换为中文:
df.rename(columns={'survived':'是否获救','sex':'性别','name':'姓名','pclass':'船舱等级','sex':'性别','age':'年龄','sibsp':'兄弟姐妹数','parch':'父母小孩数','ticket':'船票','fare':'船票费','cabin':'客舱号码','embarked':'起航运港','boat':'救生艇编号','body':'人体编号','home.dest':'出发地到目的地'})
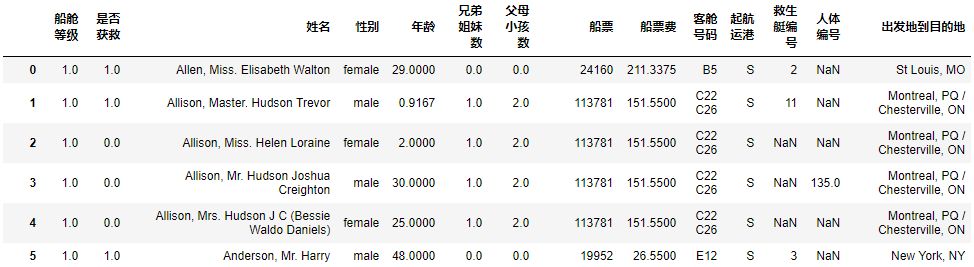
01 数据提取
(1)按照索引提取:
df.loc[666] #提取索引值为666的那一行

(2)指定位置提取:
df.iloc[6:9,:3]#取第六,七八行的前3列

(3)按照条件提取:
df[(df['age']<=30)&(df['sex']=='female')]#年龄小于30岁以下的女性
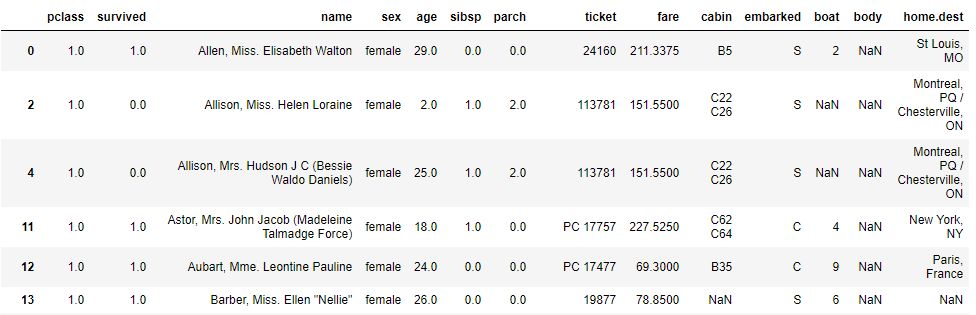
(4)巧用不等于:
df[(df['survived']==1)&(df['pclass']!=3)].head()#提取非3等仓并且获救乘客的信息

(5)query函数:
df.query('pclass==[1,2]').head() #船舱等级不等于1和2的
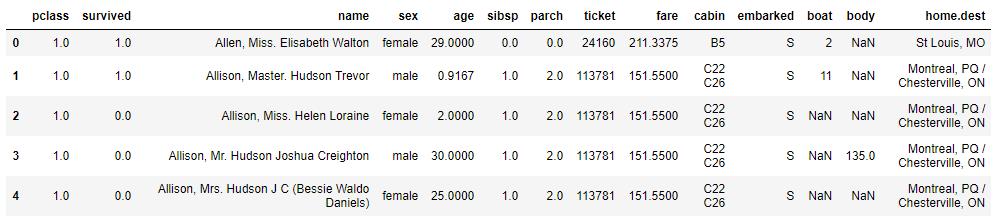
02 数据清洗
(1)处理空值,用dropna删除空值
df.dropna(how='any') #发现Age中的空值会全部删掉
df.fillna(value=0) #用数据0来填充空值
df['age'].fillna(df['age'].mean()) #用数据集里面的年龄均值来填充空值
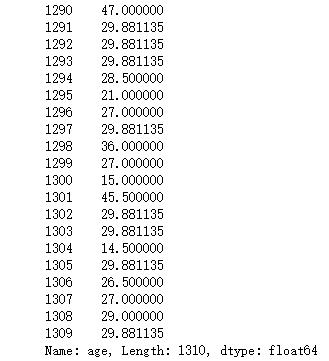
(2)去除重复值
通过drop_duplicates可以快速的去掉重复值
df['embarked'].drop_duplicates()#登船类别
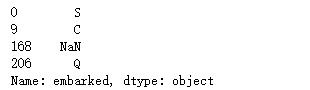
(3)值的替换
# 将survived列中1全部替换成3
df['survived'].replace(1, 3).head()

03 数据排序
(1)按索引排序
# 默认axis=0,按行索引对行进行排序;ascending=True,升序排序
df.sort_index().head()
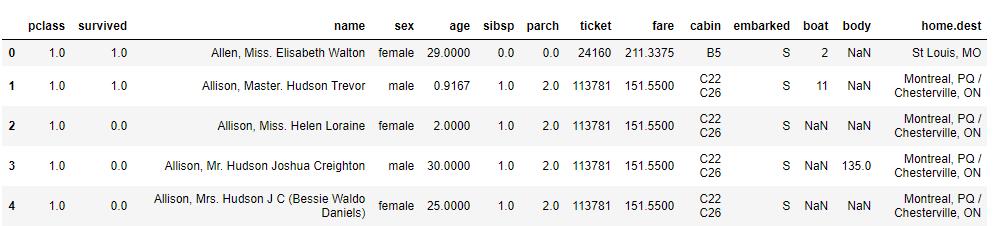
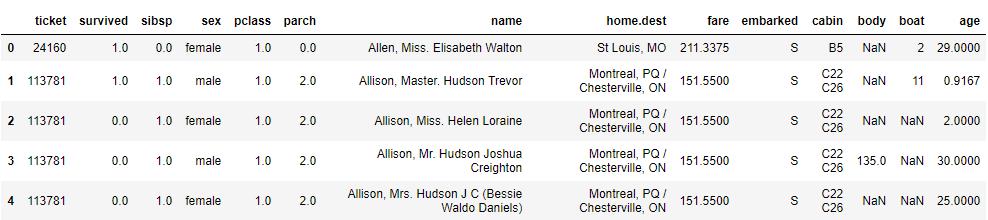
# 按列名对列进行排序,ascending=False 降序
df.sort_index(axis=1, ascending=False).head()
(2)按照年龄进行降序排列
df.sort_values(by=['age'],ascending=False).head(5)

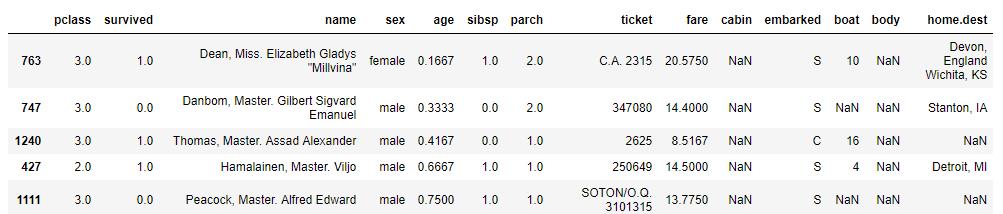
(3)按照年龄升序排列
df.sort_values(by=['age'],ascending=True).head(5)
04 数据分类与统计
(1)groupby函数
df.groupby('sex')['survived'].count() #性别获救统计
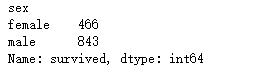
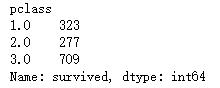
dfgroupby('pclass')['survived'].count() #船舱等级获救统计
(2)where函数
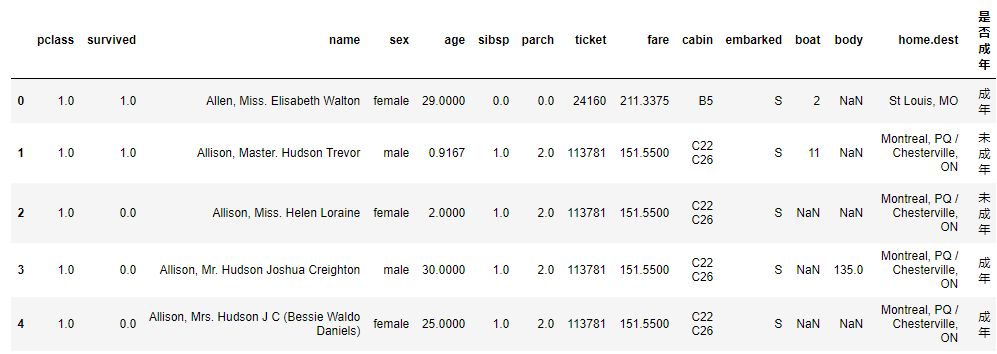
df['是否成年']=np.where(df['age']>=18,'成年','未成年')
df.head(5)
(3)切片分析
比如我们希望对是非获救和船舱等级这个两个轴进行深入切片分析,这样的伎俩在R语言里面也经常用到,这里pandas给我们提供了非常方便的agg函数
df.groupby(['survived','pclass'])['age'].agg(['size','max','min','mean'])
(4)数据聚合
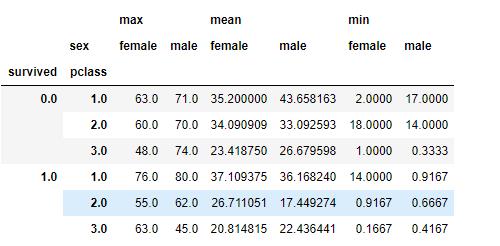
df.pivot_table(columns=['sex'],index=['survived','pclass'],values='age',aggfunc={'age':[np.mean,min,max]})
- 数据分析与可视化 -
01 总体生还率分析
df['survived'].mean()
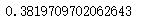
可以看到,约有38.2%的乘客生还。
02 按乘客年纪和性别进行分析
对性别进行分析:
import matplotlib.pyplot as plt
class_sex_grouping = df.groupby(['pclass','sex']).mean()
class_sex_grouping
class_sex_grouping['survived'].plot.bar(figsize=(12, 7), fontsize=12)
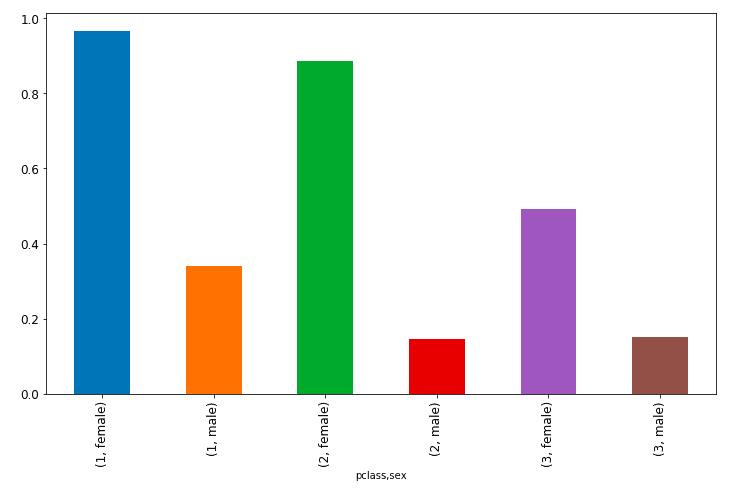
从上面的分析中可以看出来,在惨剧发生的时候大家倾向于首先疏散女性。在所有的阶层中,女性都比男性更有可能生存下来。
对年纪进行分析:
group_by_age = pd.cut(df["age"], np.arange(0, 90, 10))
age_grouping = df.groupby(group_by_age).mean()
age_grouping['survived'].plot.bar(figsize=(12, 7), fontsize=12)
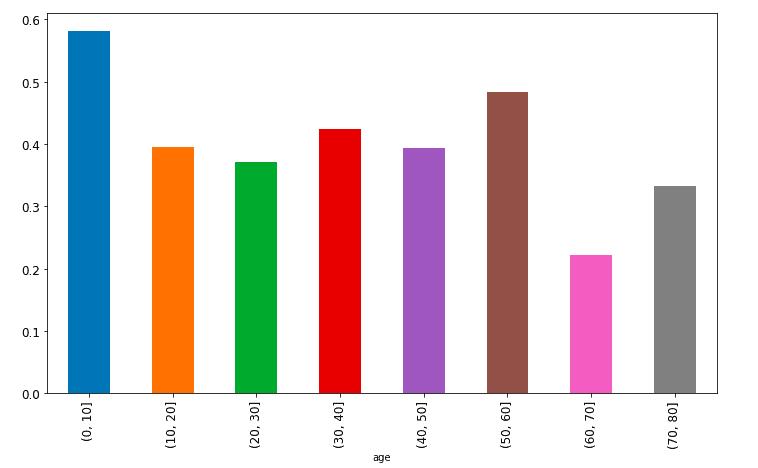
显然,儿童的生还比例是最高的,在本次灾难中儿童也得到了充分的优先照顾。
03 按乘客阶级地位进行分析
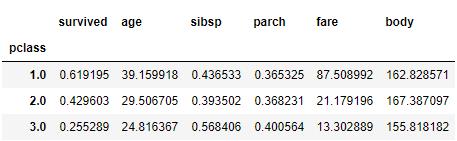
df.groupby('pclass').mean()
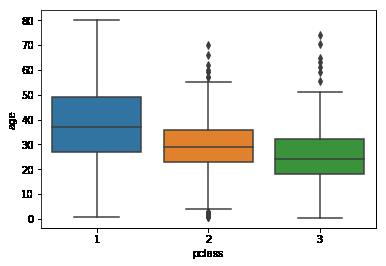
船舱等级和年龄:
titanic=sns.load_dataset('titanic')
sns.boxplot(x='pclass',y='age',data=titanic)
年龄、船舱等级与是否生还:
sns.violinplot(x='pclass',y='age',hue='survived',data=titanic,split=True)
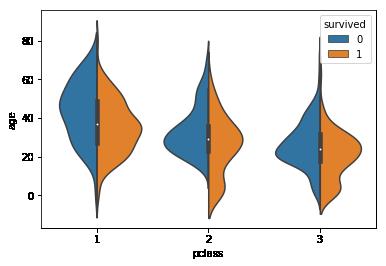
我们可以看出来,头等舱的乘客有62%的生还几率。相比之下,三等舱的乘客只有25.5%的生还概率。此外客舱越豪华,乘客的年纪也就越大。
关于python数据分析上手到这里就差不多了,从基本的数据处理到数据分析和可视化,走完这一套流程下来你可以看到利用python做数据分析其实很简单。
当然,这只是最基础的数据分析步骤,更深层更高级的数据分析还需要你去探索。
以上是关于小白也能上手的Python数据分析案例的主要内容,如果未能解决你的问题,请参考以下文章
火遍全网!98页Python自动化办公教程,小白也能快速上手
火遍全网!98页Python自动化办公教程,小白也能快速上手