机器学习算法之SVM原理
Posted 狂奔的CD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法之SVM原理相关的知识,希望对你有一定的参考价值。
前言
很多知识并不是看一遍就能懂得,特别是对于搞算法的,数学问题博大精深,需要重复不断的学习,理解,实验。比如这个SVM,支持向量机,我很难看懂里面的数学原理,到目前为止理解都是泛泛的。
正文
svm的理解
05.14
之所以再次提到SVM,主要是因为项目中需要做个多分类,目前感觉svm或者用深度学习CNN都可以处理。
SVM入门之一至三
参考系列文章 http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html
文章内容梳理:
1)与深度学习模型一样,SVM也是训练出一个模型逼近问题的真实模型,它也是一个分类器
2)训练得到的模型与真实模型会存在误差,误差的累积称之为风险。真实风险应该由两部分内容刻画,一是经验风险,代表了分类器在给定样本上的误差;二是置信风险,代表了我们在多大程度上可以信任分类器在未知文本上分类的结果。第二部分是没有办法精确计算的,因此只能给出一个估计的区间,也使得整个误差只能计算上界,而无法计算准确的值(所以叫做泛化误差界,而不叫泛化误差)。
置信风险与两个量有关,一是样本数量,显然给定的样本数量越大,我们的学习结果越有可能正确,此时置信风险越小;二是分类函数的VC维,显然VC维越大,推广能力越差,置信风险会变大
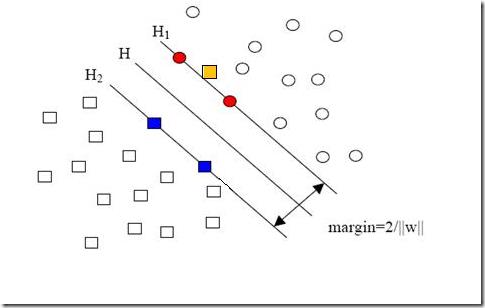
3)几何间隔的理解
H是分类面,而H1和H2是平行于H,且过离H最近的两类样本的直线,H1与H,H2与H之间的距离就是几何间隔。


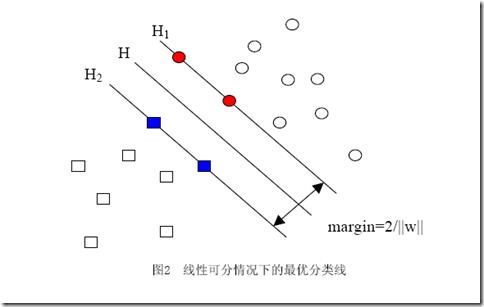
4)误分次数
其中的δ是样本集合到分类面的间隔,R=max ||xi|| i=1,…,n,即R是所有样本中(xi是以向量表示的第i个样本)向量长度最长的值(也就是说代表样本的分布有多么广)。先不必追究误分次数的具体定义和推导过程,只要记得这个误分次数一定程度上代表分类器的误差。而从上式可以看出,误分次数的上界由几何间隔决定!(当然,是样本已知的时候)

几何间隔越大的解,它的误差上界越小。因此最大化几何间隔成了我们训练阶段的目标
SVM入门(四)线性分类器的求解——问题的描述Part1
参考 http://www.blogjava.net/zhenandaci/archive/2009/02/13/254578.html
1)几何间隔最大,则需要找到最小的||w||
2)实际上对于这个目标,我们常常使用另一个完全等价的目标函数来代替,
很容易看出当||w||=0的时候就得到了目标函数的最小值。但是你也会发现,无论你给什么样的数据,都是这个解.反映在图中,就是H1与H2两条直线间的距离无限大,这个时候,所有的样本点(无论正样本还是负样本)都跑到了H1和H2中间。而我们原本的意图是,H1右侧的被分为正类,H2 左侧的被分为负类,位于两类中间的样本则拒绝分类

3)需要添加新的约束:样本点必须在H1或H2的某一侧(或者至少在H1和H2上),所有样本点中间隔最小的那一点的间隔定为1,表达式如下:
yi[(w·xi)+b]-1≥0 (i=1,2,…,l) (l是总的样本数)

SVM入门(五)线性分类器的求解——问题的描述Part2
参考:http://www.blogjava.net/zhenandaci/archive/2009/02/14/254630.html
1)凸集是指有这么一个点的集合,其中任取两个点连一条直线,这条线上的点仍然在这个集合内部。
2)在这个问题中,自变量就是w,而目标函数是w的二次函数,所有的约束条件都是w的线性函数(哎,千万不要把xi当成变量,它代表样本,是已知的),这种规划问题有个很有名气的称呼——二次规划(Quadratic Programming,QP),而且可以更进一步的说,由于它的可行域是一个凸集,因此它是一个凸二次规划。凸二次规划让人喜欢的地方就在于,它有解。
3)我们可以轻松的解一个不带任何约束的优化问题(实际上就是当年背得烂熟的函数求极值嘛,求导再找0点呗,谁不会啊?笑),我们甚至还会解一个只带等式约束的优化问题,也是背得烂熟的,求条件极值,记得么,通过添加拉格朗日乘子,构造拉格朗日函数,来把这个问题转化为无约束的优化问题云云(如果你一时没想通,我提醒一下,构造出的拉格朗日函数就是转化之后的问题形式,它显然没有带任何条件)。
4)解题关键:把带不等式约束的问题向只带等式约束的问题转化
SVM入门(六)线性分类器的求解——问题的转化,直观角度
参考:http://www.blogjava.net/zhenandaci/archive/2009/03/01/257237.html
1)样本确定了w,用数学的语言描述,就是w可以表示为样本的某种组合:
w=α1x1+α2x2+…+αnxn
2)而用<x1,x2>表示向量x1,x2的内积(也叫点积,注意与向量叉积的区别)。因此g(x)的表达式严格的形式应该是:
g(x)=<w,x>+b
3)w不仅跟样本点的位置有关,还跟样本的类别有关(也就是和样本的“标签”有关)。因此用下面这个式子表示才算完整:
w=α1y1x1+α2y2x2+…+αnynxn (式1)
注意式子中x才是变量,也就是你要分类哪篇文档,就把该文档的向量表示代入到 x的位置,而所有的xi统统都是已知的样本。还注意到式子中只有xi和x是向量,因此一部分可以从内积符号中拿出来,得到g(x)的式子为
以这样的形式描述问题以后,我们的优化问题少了很大一部分不等式约束(记得这是我们解不了极值问题的万恶之源



SVM入门(七)为何需要核函数
参考:http://www.blogjava.net/zhenandaci/archive/2009/03/06/258288.html
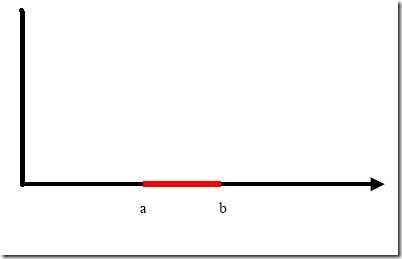
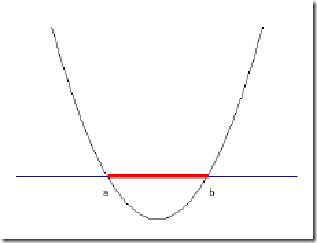
1)问题:把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?
不能,显然找不到符合条件的直线。但我们可以找到一条曲线。
负类的点函数值一定比0大,而正类的一定比0小。它的函数表达式可以写为:
也可以转化为向量形式
这样g(x)就可以转化为f(y)=<a,y>
原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。
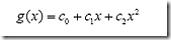

2)高维度的函数表示为
f(x’)=<w’,x’>+b
它是由低维度的x转换过来了,这种映射关系很难找,是否能有这样一种函数K(w,x),他接受低维空间的输入值,却能算出高维空间的内积值<w’,x’>?
这样的K(w,x)确实存在,它被称作核函数(核,kernel),而且还不止一个,事实上,只要是满足了Mercer条件的函数,都可以作为核函数。
3)问题需要求一个线性分类器,它的形式应该是:
这个就是高维空间里的线性函数,可以用一个低维空间里的函数来代替,这个低维空间里的函数就不再是线性的


SVM入门(八-九)松弛变量
参考 http://www.blogjava.net/zhenandaci/archive/2009/03/15/259786.html
1)当线性不可分问题向高维转化时还是线性不可分的时候,可以继续向上转化。但是如果因为极少数错误的样本,采取这样的办法可能效果不会更好。这时引入了松弛变量,忽略掉极少数不协调的样本,(下图中黄色的方块)
加入松弛变量后的表达式,其中C为惩罚因子:
2)没有任何规定说必须对所有的松弛变量都使用同一个惩罚因子C,我们完全可以给每一个离群点都使用不同的C,这时就意味着你对每个样本的重视程度都不一样。
当出现数据集偏斜(unbalanced),正样本:负样本=100:1 。如果采取同样的C,可能会导致数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
解决办法可以是使用不同的惩罚因子
先假定说C+是5这么大,C-就可以定为500这么大。
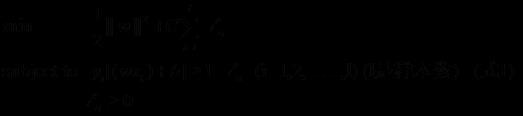
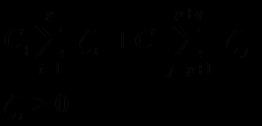
以上是关于机器学习算法之SVM原理的主要内容,如果未能解决你的问题,请参考以下文章