学习笔记之——非线性优化的解读
Posted gwpscut
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记之——非线性优化的解读相关的知识,希望对你有一定的参考价值。
SLAM问题中,非线性优化是非常重要的,本博文是本人复习非线性优化时做的学习记录,博客部分内容来自网络,仅仅供本人学习记录用,不作任何商业用途~
目录
g2o(General graph optimization )
首先给出SLAM十四讲中关于非线性优化这一章的视频~
【高翔】视觉SLAM十四讲
优化算法
对于SLAM问题,可以看成一个最大似然估计:“在什么样的状态下,最可能产生现在观测到的数据”。而换句话说,当前状态估计与观测的数据的误差最小化,那么也可以将SLAM优化问题,变成一个最小二乘问题。
迭代求解
对于一个最小二乘问题,可以如下公式表述
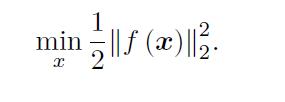
如果f 是个数学形式上很简单的函数,那问题也许可以用解析形式来求。令目标函数的导数为零,然后求解x 的最优值,就和一个求二元函数的极值一样:
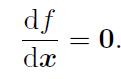
解此方程,就得到了导数为零处的极值。它们可能是极大、极小或鞍点处的值,只要挨个儿比较它们的函数值大小即可。但是,这个方程是否容易求解呢?这取决于f 导函数的形式。在SLAM 中,我们使用李代数来表示机器人的旋转和位移。但这不代表我们就能够顺利求解上式这样一个复杂的非线性方程。而对于不方便直接求解的最小二乘问题,我们可以用迭代的方式,从一个初始值出发,不断地更新当前的优化变量,使目标函数下降。具体步骤可列写如下:

这让求解导函数为零的问题,变成了一个不断寻找梯度并下降的过程。直到某个时刻增量非常小,无法再使函数下降。此时算法收敛,目标达到了一个极小,我们完成了寻找极小值的过程。在这个过程中,我们只要找到迭代点的梯度方向即可,而无需寻找全局导函数为零的情况。接下来的问题是,增量Δxk 如何确定?
不同的优化算法的不同主要体现在增量的更新方式上。如果采用不合适的更新方式,其实很容易陷入局部最小值。这里给出一个关于局部最小值和全局最小值的直观的理解。如下图所示:
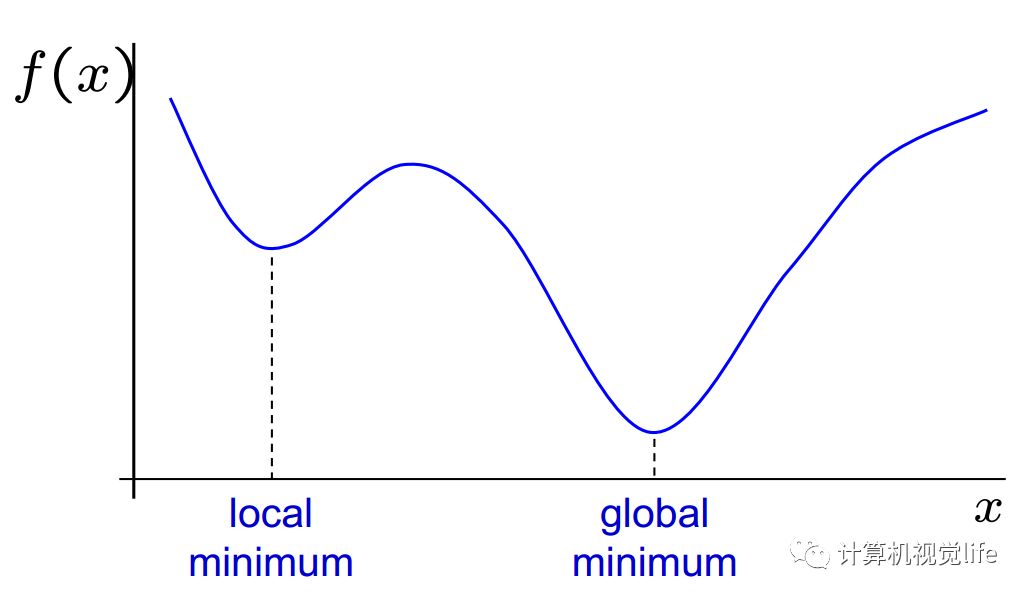
通常我们希望迭代得到的是全局最小值(只有一个)而不是局部最小值(可能有多个)。下图表示的是不同初始值对迭代结果的影响。如果我们初值设的是红色的θ0,最后找到的极小值位于 θ∞,在这个例子中它是全局最小值。但是如果我们初值设的是蓝色的 θ'0,最后我们找到的极小值位于 θ'∞,显然只是局部最小值,不是全局最小值。
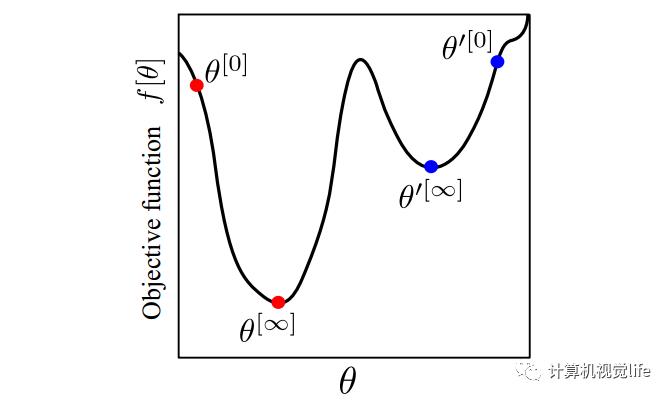
故此,对于优化问题,我们希望对目标函数有一定的限制。如果我们的目标函数是凸函数,那么可以保证最终找到的极小值就是最小值。
凸函数的概念
凸函数(convex function)定义如下:
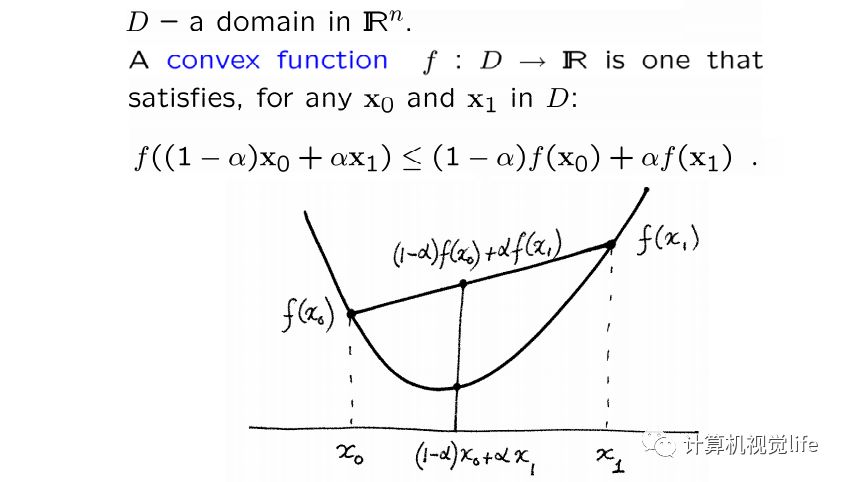
简单来说~凸函数其实就是一个「碗」状曲线,碗口向上。对于一元二次可微函数,如果它的二阶导数是正的,那么该函数就是严格凸函数。对于多元二次可微函数,当它的Hessian矩阵是正定的时候,就是严格凸函数。
1、如果一个函数是凸函数,那么它有且只有一个极值点,且这个极值点是最值点。
2、几个非负凸函数的和仍然是凸函数。
3、如果一个函数不是凸函数,那么它可能只有一个极值点,也可能有多个极值点(局部极值点和全局极值点)
对于优化问题,在优化函数是凸函数的前提下,初值也很重要。在做最优化计算时,都需要提供变量的初始值,而在SLAM问题中,一般会通过PnP或者ICP之类提供优化初始值。关于PnP问题,可以参考之前的博客《学习笔记之——P3P与ICP位姿估计算法及实验》,后面的博客《学习笔记之——视觉里程计》也会介绍一下ICP。
接下来对各种优化算法做一个简单的介绍~优化算法的发展顺序是:梯度下降、牛顿法、高斯牛顿法、LM法。
梯度下降(Gradient Descent)法
梯度下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的。梯度下降法,其本质是一阶优化算法,有时候也称为最速下降法(Steepest Descent)。与其对应的是梯度上升法(Gradient ascent),用来求函数的极大值,两种方法原理一样,只是计算的过程中正负号不同而已。
在微积分里,对函数求导数(如果是多元函数则求偏导)得到的就是梯度。具体来说,对于函数 f(x,y), 在点 (x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0),它的方向是 f(x,y) 增加最快的方向。或者说,沿着梯度向量的方向,更加容易找到函数的极大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0) 的方向,梯度减少最快,也就是更加容易找到函数的极小值。
以一元函数为例,假设目标函数为F(x),梯度的符号为∇,那么在梯度下降中,自变量x每次按照如下方式迭代更新:
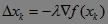
其中 λ 称为步长或者学习率。按照上述方式迭代更新自变量,直到满足迭代终止条件,此时认为自变量更新到函数最小值点。下图是梯度下降法的示意图。
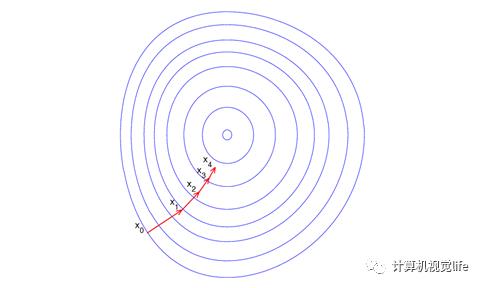
总结一下梯度下降法:
1、实际使用中使用梯度下降法找到的通常是局部极小值,而不是全局最小值。
2、具体找到的是哪个极小值和初始点位置有很大关系。
3、如果函数是凸函数,那么梯度下降法可以保证收敛到全局最优解(最小值)
4、梯度下降法收敛速度通常比较慢
5、梯度下降法中搜索步长 λ 很关键,步长太长会导致找不到极值点甚至震荡发散,步长太小收敛非常慢。
牛顿法
梯度下降法在山谷中容易出现锯齿状的迭代,如下图所示。是二维函数优化的一个例子,不同颜色表示不同高度。我们初始值在蓝色的加号位置,最小值位于绿色的加号位置。图中展示了从不同的初始值开始迭代所需要的迭代次数,可以看到不同初始值会产生非常大的差异。(a) 图只经过5次迭代就收敛了, (b) 图经过了22次迭代才收敛。
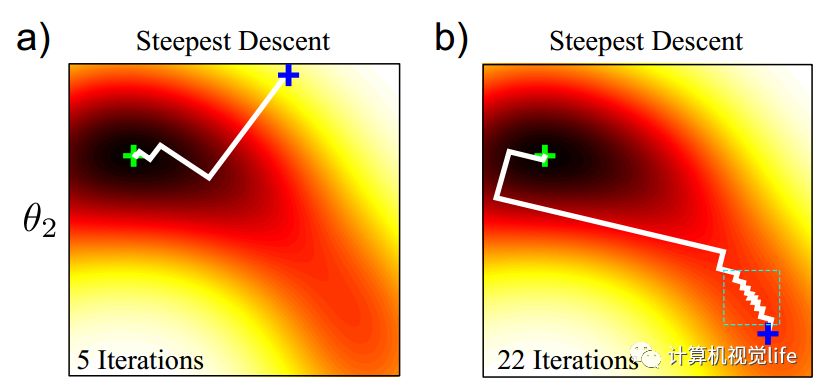
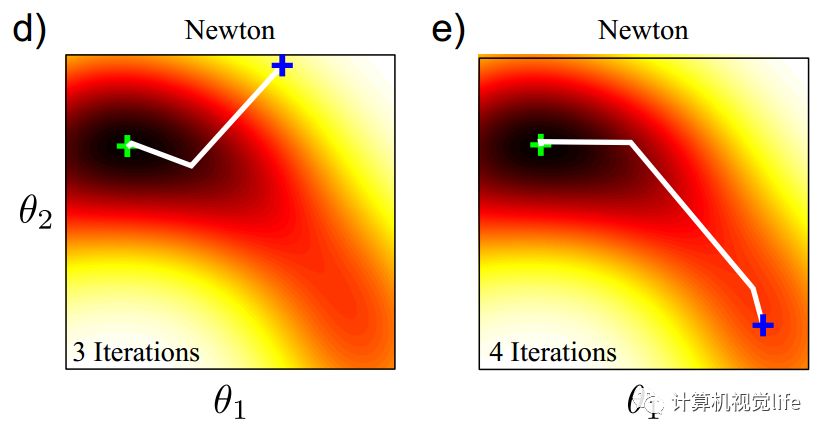
这种锯齿状的迭代,可以通过牛顿法来避免。对于同样的目标函数,使用牛顿法在不同的初始值位置(下图中蓝色十字),只需要3、4次迭代即可找到最小值(下图中绿色十字)。
对于泰勒展开式有:
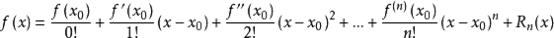
待优化的目标函数和前面一样:
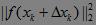
将目标函数在x处进行二阶泰勒展开。对照上述通式,目标函数泰勒展开如下:
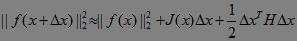
其中 J(x) 是 ||f(x)||2 关于x的Jacobian矩阵(一阶导数),H(x)则是Hessian矩阵(二阶导数)。
Jacobian矩阵
假设函数 f = {f1(x1,...,xn), .., fm((x1,...,xn))} 有m维空间组成,对应n个自变量。那么函数 f 的一阶偏导数(如果存在)可以组成一个m行n列的矩阵,称为Jacobian(译为雅克比)矩阵
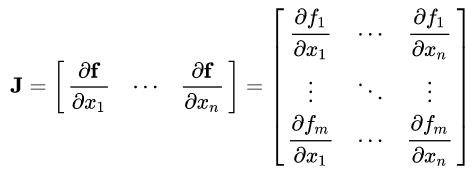
Hessian矩阵
假设有一个实数函数 f(x1,...,xn), 如果函数 f 的所有二阶偏导数存在,那么称如下矩阵为Hessian矩阵,它是一个n x n 的方阵。

而梯度下降法可以认为是泰勒展开式中只取到了一阶项,二阶项后面的部分丢弃。而在牛顿法中,泰勒展开中取到二阶导数,我们的目标函数变为:
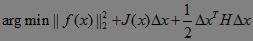
对其关于△x求导,并令其为0,可以得到步长
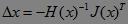
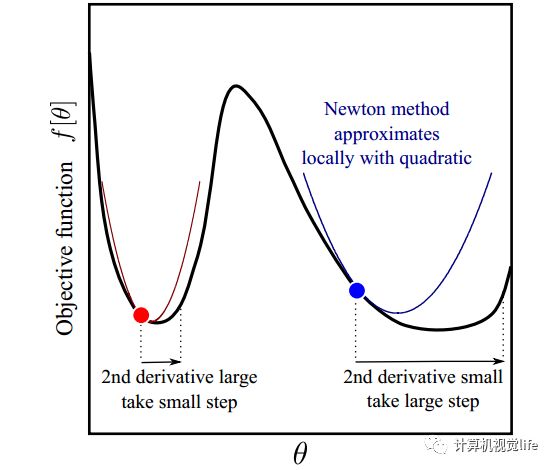
类似于梯度下降法,我们用上述步长来迭代优化,最终收敛到极值点。这个过程就称为牛顿法。牛顿法与梯度下降法的直观比较理解如下图所示。红点和蓝点的梯度(一阶导数)是一样的,但是红点出的二阶导数比蓝点大,也就是说在红点处梯度变化比蓝点处更快,那么最小值可能就在附近,因此步长就应该变小;而蓝点处梯度变化比较缓慢,也就是说这里相对平坦,多走一点也没事,那么可以大踏步往前,因此步长可以变大一些。所以我们看到牛顿法迭代优化时既利用了梯度,又利用了梯度变化的速度(二阶导数)的信息。
高斯牛顿法(Gauss-Newton)
然而牛顿法中包含了Hessian 矩阵的计算。而在高维度下计算Hessian 矩阵需要消耗很大的计算量,很多时候甚至无法计算。而高斯牛顿(Gauss-Newton)法是对牛顿法的一种改进,它用雅克比矩阵的乘积近似代替牛顿法中的二阶Hessian 矩阵,从而省略了求二阶Hessian 矩阵的计算。牛顿法中我们是将目标函数 f(x+△x)^2 进行泰勒展开,而在高斯牛顿法中,我们对 f(x+△x) 进行一阶泰勒展开,如下:
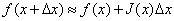
前面我们说过,我们要确定一个步长,使得目标函数
达到最小,将一阶泰勒展开代入,问题转化为如下最小二乘问题:
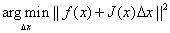
展开后可得:
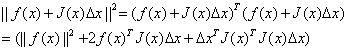
对△x求导并令导数为0,可得:
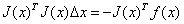
则有:
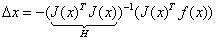
其中我们把J^TJ作为牛顿法中Hessian矩阵的近似,从而用求一阶雅克比矩阵代替了直接求二阶Hessian矩阵的过程。
Levenberg-Marquardt(LM)法
Levenberg-Marquardt(LM)法在一定程度上修正了高斯牛顿法的缺点,因此它比高斯牛顿法更加鲁棒,不过这是以牺牲一定的收敛速度为代价的--它的收敛速度比高斯牛顿法慢。LM算法中定义的步长为:
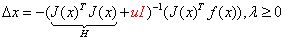
其中I是单位矩阵,u是一个非负数。如果 u 取值较大时,uI 占主要地位,此时的LM算法更接近一阶梯度下降法,说明此时距离最终解还比较远,用一阶近似更合适。反之,如果 u 取值较小时,H 占主要地位,说明此时距离最终解距离较近,用二阶近似模型比较合适,可以避免梯度下降的“震荡”,容易快速收敛到极值点。因此参数 u 不仅影响到迭代的方向还影响到迭代步长的大小。设x初值为x0,根据经验可以设置u的初值u0为:
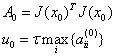
其中,τ可以自己指定,aii表示矩阵A对角线元素。LM采用的搜索方法是信赖域(Trust Region)方法,和梯度下降、牛顿法、高斯牛顿法采用的线性搜索(Line Search)方法不同。
g2o(General graph optimization )
(官网:https://github.com/RainerKuemmerle/g2o)
ceres与g20都是最小二乘求解器。从带噪声的数据中拟合参数模型。g2o以图模型表达一个最小二乘问题。个人感觉,了解g2o就好了哈~
SLAM的后端一般分为两种处理方法,一种是以扩展卡尔曼滤波(EKF)为代表的滤波方法,一种是以图优化为代表的非线性优化方法。不过,目前SLAM研究的主流热点几乎都是基于图优化的。
在计算资源受限、待估计量比较简单的情况下,EKF为代表的滤波方法比较有效,经常用在激光SLAM中。但它的一个大缺点就是存储量和状态量是平方增长关系,因为存储的是协方差矩阵,因此不适合大型场景。而现在基于视觉的SLAM方案,路标点(特征点)数据很大,滤波方法根本吃不消,所以此时滤波的方法效率非常低。
而在大家还是用滤波算法的年代,在图优化里,Bundle Adjustment(后面简称BA)起到了核心作用。但是那会SLAM的研究者们发现包含大量特征点和相机位姿的BA计算量其实很大,根本没办法实时。后来SLAM研究者们发现了其实在视觉SLAM中,虽然包含大量特征点和相机位姿,但其实BA是稀疏的,稀疏的就好办了,就可以加速了啊!比较代表性的就是2009年,《SBA:A software package for generic sparse bundle adjustment》,而且计算机硬件发展也很快,因此基于图优化的视觉SLAM也可以实时了。
g2o用来做优化的~图优化(graph optimization )。而到底什么是图优化呢?图优化里的图就是数据结构里的图,一个图由若干个顶点(vertex),以及连接这些顶点的边(edge)组成,举个例子:比如一个机器人在房屋里移动,它在某个时刻 t 的位姿(pose)就是一个顶点,这个也是待优化的变量。而位姿之间的关系就构成了一个边,比如时刻 t 和时刻 t+1 之间的相对位姿变换矩阵就是边,边通常表示误差项。进而,用顶点表示优化变量,用边表示误差项。如下图所示。是一个简单的图优化例子。我们用三角形表示相机位姿节点,用圆形表示路标点,它们构成了图优化的顶点;同时,蓝色线表示相机的运动模型,红色虚线表示观测模型,它们构成了图优化的边。此时,虽然整个问题的数学形式仍是一个基本的最小二乘问题(![]() ),但现在我们可以直观地看到问题的结构了。
),但现在我们可以直观地看到问题的结构了。

在SLAM里,图优化一般分解为两个任务:
1、构建图。机器人位姿作为顶点,位姿间关系作为边。
2、优化图。调整机器人的位姿(顶点)来尽量满足边的约束,使得误差最小。
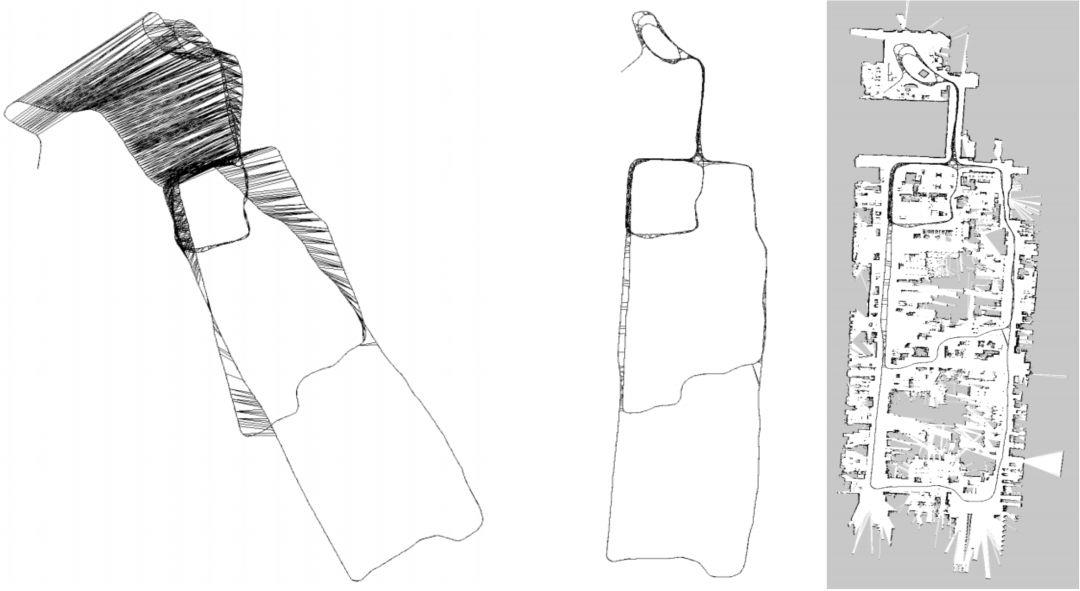
下面就是一个直观的例子。我们根据机器人位姿来作为图的顶点,这个位姿可以来自机器人的编码器,也可以是ICP匹配得到的,图的边就是位姿之间的关系。由于误差的存在,实际上机器人建立的地图是不准的,如下图左。我们通过设置边的约束,使得图优化向着满足边约束的方向优化,最后得到了一个优化后的地图(如下图中所示),它和真正的地图(下图右)非常接近。
在SLAM领域,基于图优化的一个用的非常广泛的库就是g2o,它是General Graphic Optimization 的简称,是一个用来优化非线性误差函数的c++框架。g2o的基本框架结构如下图所示。
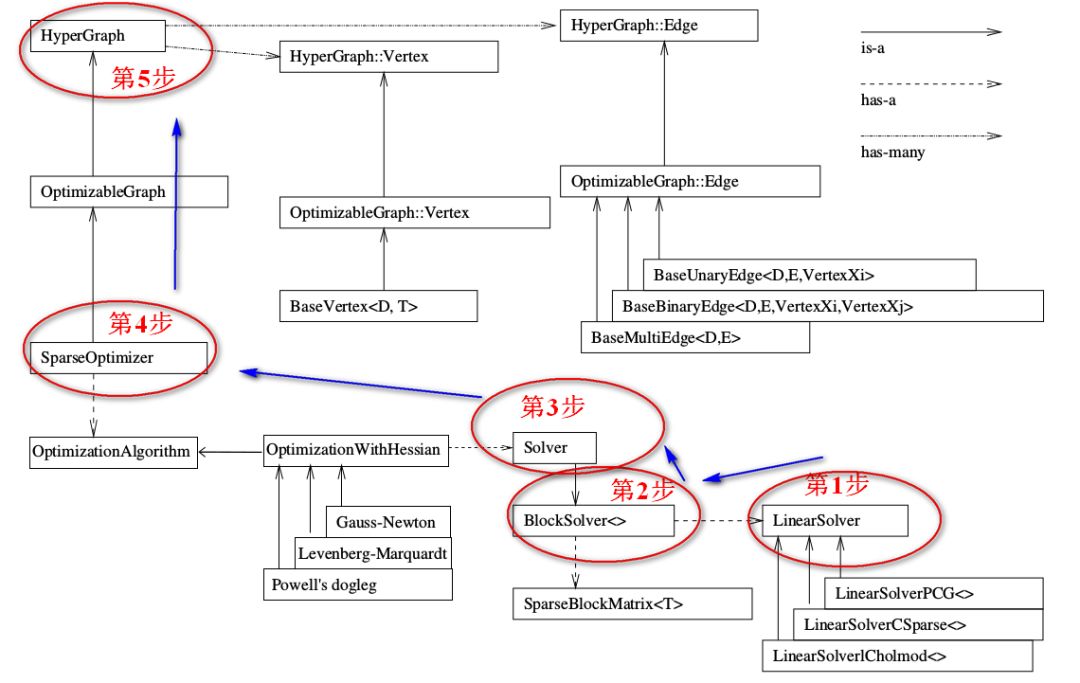
g2o帮助我们实现了很多内部的算法,只是在进行构造的时候,需要遵循一些规则(后面实战敲代码的时候再多看多记一些关键点吧,这里就单纯列一些)
SparseOptimizer是整个图的核心,注意右上角的 is-a 实心箭头,这个SparseOptimizer它是一个Optimizable Graph,从而也是一个超图(HyperGraph)。注意看 has-many 箭头,这个超图包含了许多顶点(HyperGraph::Vertex)和边(HyperGraph::Edge)。而这些顶点顶点继承自 Base Vertex,也就是OptimizableGraph::Vertex,而边可以继承自 BaseUnaryEdge(单边), BaseBinaryEdge(双边)或BaseMultiEdge(多边),它们都叫做OptimizableGraph::Edge。
下面看看配置SparseOptimizer的优化算法和求解器。整个图的核心SparseOptimizer 包含一个优化算法(OptimizationAlgorithm)的对象。OptimizationAlgorithm是通过OptimizationWithHessian 来实现的。其中迭代策略可以从Gauss-Newton(高斯牛顿法,简称GN), Levernberg-Marquardt(简称LM法), Powell's dogleg 三者中间选择一个(我们常用的是GN和LM,上面已经介绍了哈~)。
g2o的整个框架就是按照上图中标的顺序来写的。详细的过程可参考:https://mp.weixin.qq.com/s/j9h9lT14jCu-VvEPHQhtBw
1、创建一个线性求解器LinearSolver
2、创建BlockSolver。并用上面定义的线性求解器初始化。
3、创建总求解器solver。并从GN, LM, DogLeg 中选一个,再用上述块求解器BlockSolver初始化
4、创建终极大boss 稀疏优化器(SparseOptimizer),并用已定义求解器作为求解方法。
5、定义图的顶点和边。并添加到SparseOptimizer中。
6、设置优化参数,开始执行优化。
Bundle Adjustmen
参考资料
《SLAM十四讲》
https://mp.weixin.qq.com/s/j9h9lT14jCu-VvEPHQhtBw
以上是关于学习笔记之——非线性优化的解读的主要内容,如果未能解决你的问题,请参考以下文章