shell 命令 之 sortuniqtrcuteval 与 正则表达式
Posted 我一个月改一次名
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell 命令 之 sortuniqtrcuteval 与 正则表达式相关的知识,希望对你有一定的参考价值。
目录
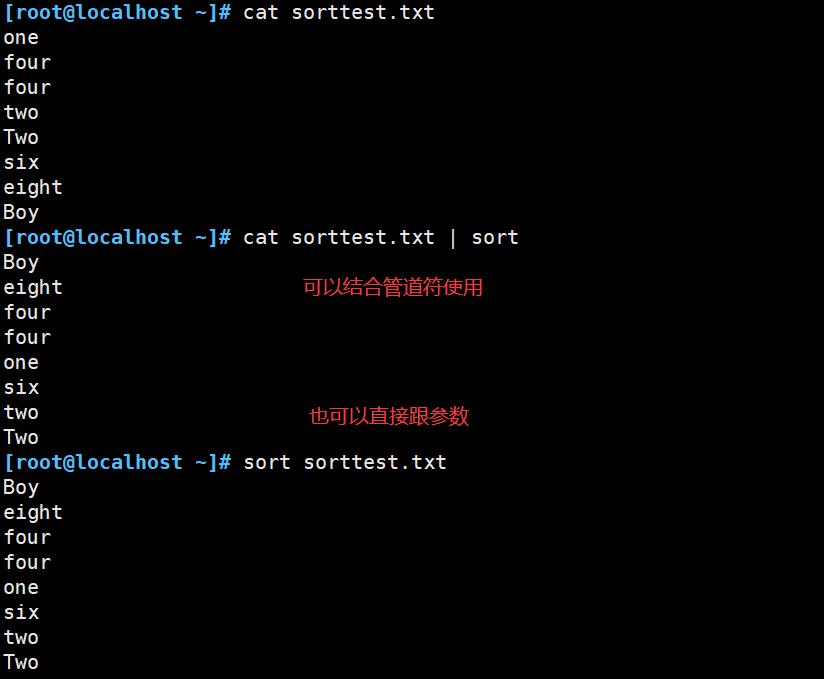
一、sort 命令
- sort :以行为单位对文件内容进行排序,默认按首字母大小进行升序排序;也可以根据不同的数据类型来排序。
语法格式:
sort [选项] 参数
cat filename | sort [选项]
常用选项:
| 常用选项 | 功能 |
|---|---|
| -f | 忽略大小写(默认小写在前面,-f 后大写在上面) |
| -b | 忽略每行前面的空格 |
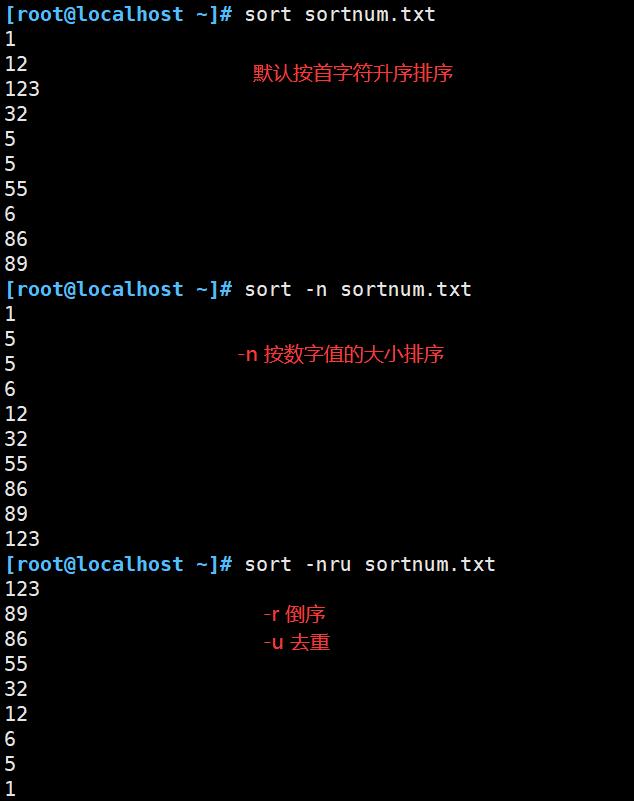
| -n | 按照数字大小进行排序 |
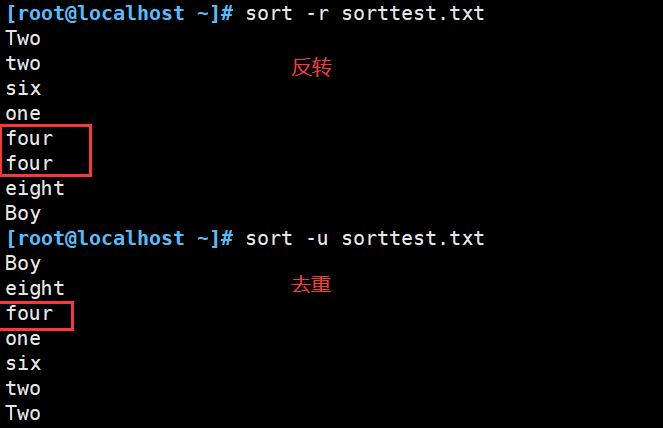
| -r | 反向排序(降序排序,默认升序排序) |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o <输出文件> | 将排序后的结果转存至指定文件 |
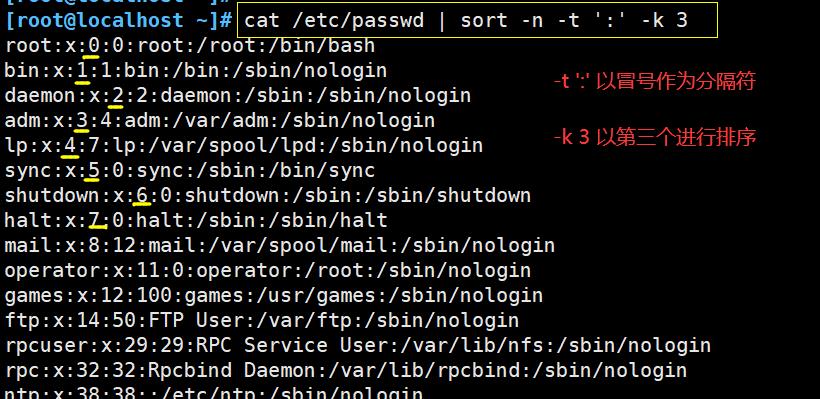
#-t -k 选项使用
#以: 进行分割,指定第三个字段进行排序
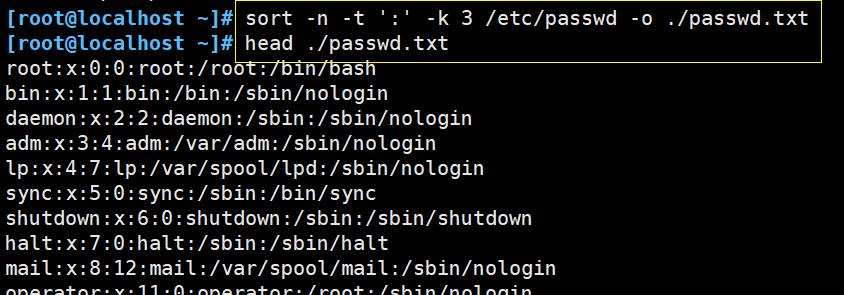
cat /etc/passwd | sort -n -t ':' -k 3
将分割排序后的结果输出到 ./passwd.txt 文件中
sort -n -t ':' -k 3 /etc/passwd -o ./passwd.txt
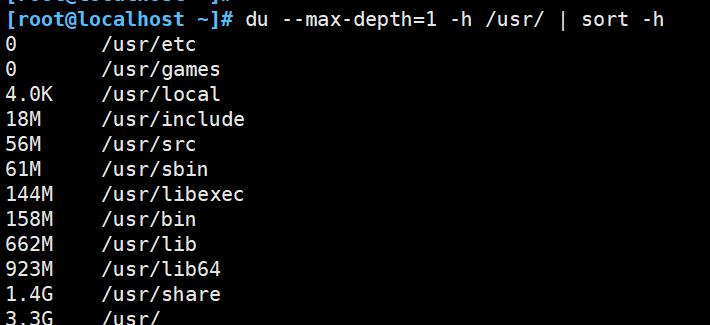
再如:统计 /usr 目录下,第一层的文件大小,并按照大小进行排序
二、uniq 命令
- uniq 用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
- 注意:只能去除连续重复的行
常用选项:
| 选项 | 说明 |
|---|---|
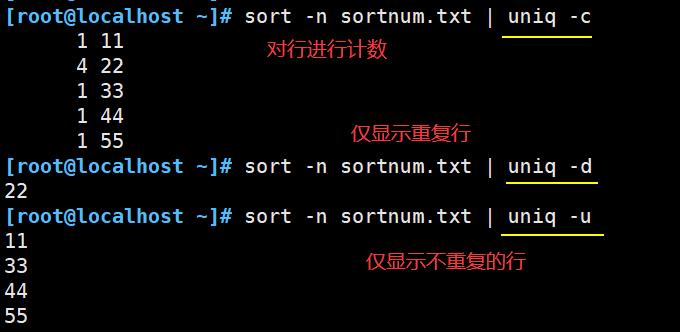
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示重复行 |
| -u | 仅显示出现一次的行 |
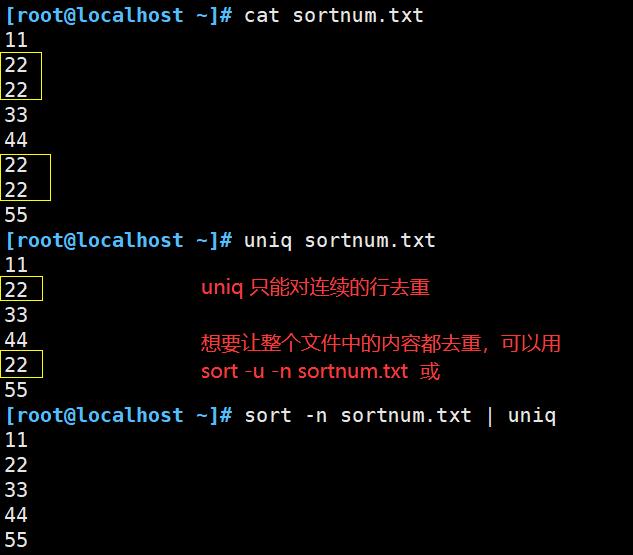
多会与sort命令配合使用,先 sort 再 uniq
三、tr 命令
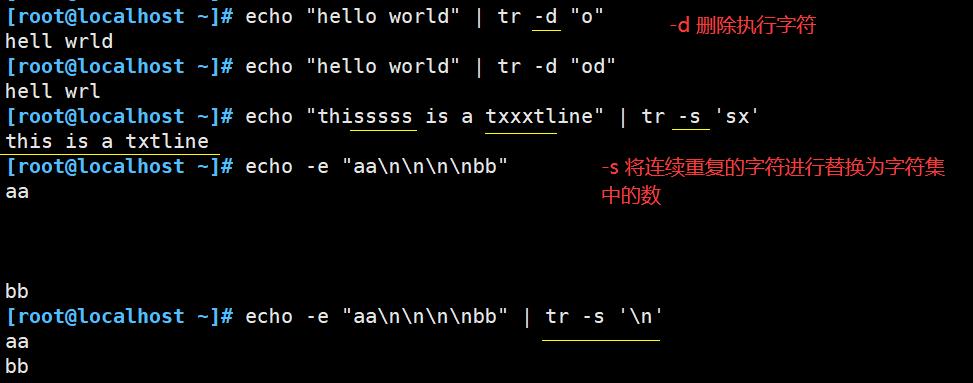
- 常用来对来自标准输入的字符进行 替换、压缩和删除
语法格式:tr [选项] [参数]
常用选项:
| 选项 | 作用 |
|---|---|
| -c | 只保留字符集1的字符,其他的字符用(包括换行符 \\n)字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选就是默认该选项。 |
参数:
- 字符集1:指定需要转换或删除的原字符集。
当执行转换操作时,必须使用参数 “字符集2” 指定转换的目标字符集。
但执行删除操作时,不需要参数 “字符集2” ; - 字符集2:指定要转换成的目标字符集。
3.1 基本用法
比如把一个字符中的小写字母替换成大写字母:


去掉空行 cat aa.txt | tr -s '\\n'
补充: 查看文件中非空行:cat testfile | grep -v "^$"
3.2 扩展用法
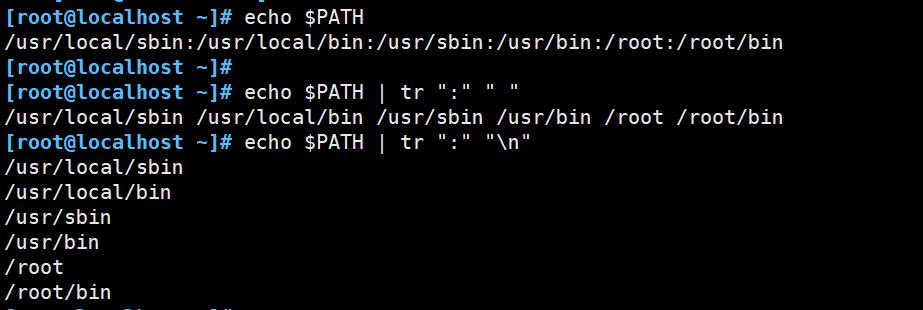
for 循环默认识别 空格 /t退格 和 换行符,
我们之前用 IFS=$IFS: 来遍历 $PATH 中定义的路径,
现在我们可以用 tr 来操作后,把结果放到一个文件中,再去遍历这个文件即可。
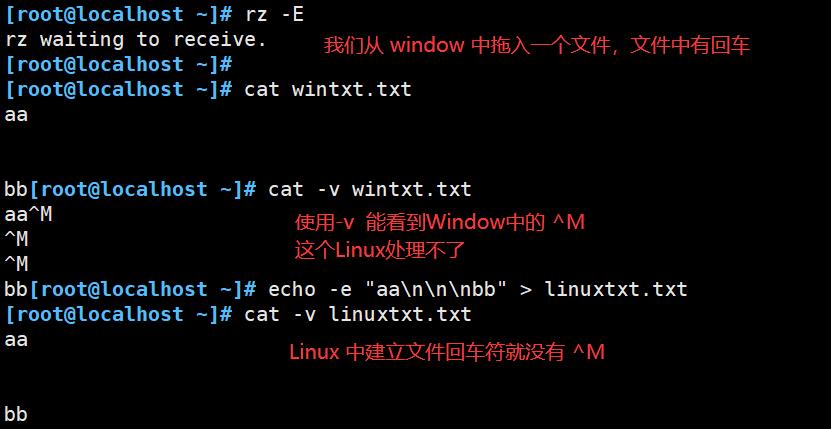
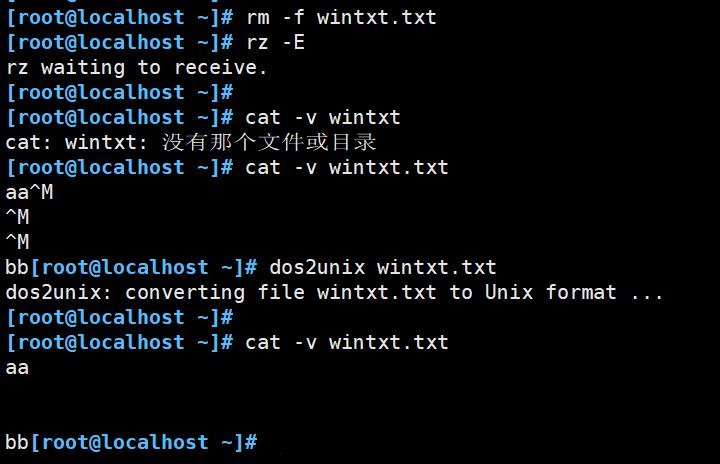
3.3 删除^M字符
前提:当我们从Windows 文件中拖进来一个文件后,如果原文件中有回车符,name在Linux中查看这个文件,回车会被识别成 ^M,Linux 中不识别这个字符,所以需要替换。
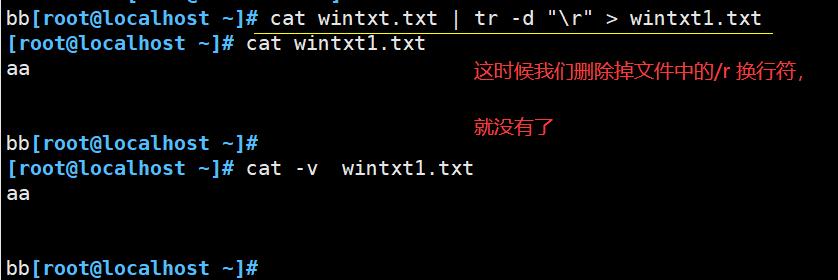
或者使用工具 dos2unix 自动帮我们转换不识别的字符:
yum install -y dos2unix
dos2unix 文件名
3.4 数组排序小实验

或者在脚本里写:
#!/bin/bash
arr=(40 10 30 50 20)
echo ${arr[@]} | tr " " "\\n" | sort -n > list
j=0
for i in `cat list` #list 是个文件
do
arr[$j]=$i
let j++
done
echo ${arr[@]}
四、cut 命令
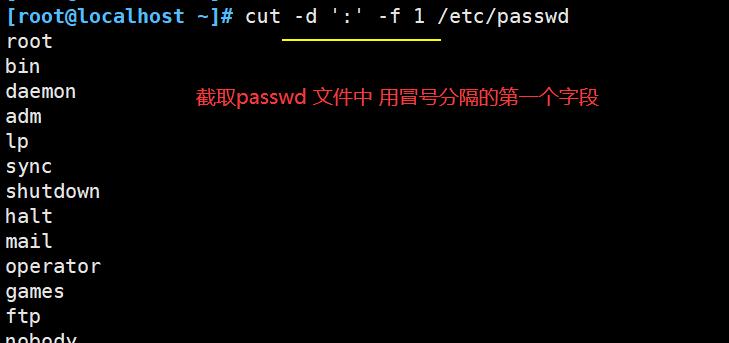
- cut命令用来 显示行中的指定部分,删除文件中指定字段
语法格式:
cut 选项 参数
cat file l cut 选项
常用选项:
| 选项 | 参数 |
|---|---|
| -f | 通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符 |
| -d | "TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符 |
--complement | 此选项用于排除所指定的字段 |
--output-delimiter | 更改输出内容的分隔符 |


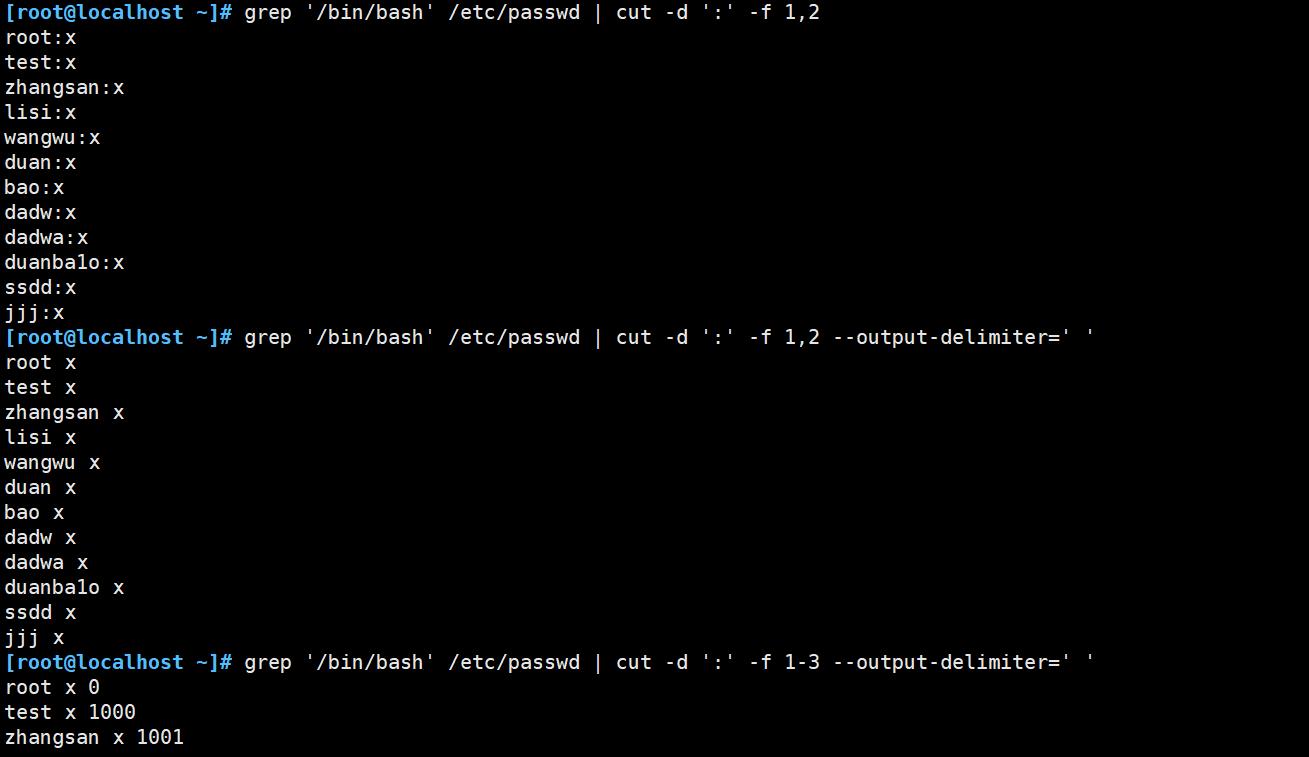
过滤多个字段
grep '/bin/bash' /etc/passwd | cut -d ':' -f 1-4,6,7
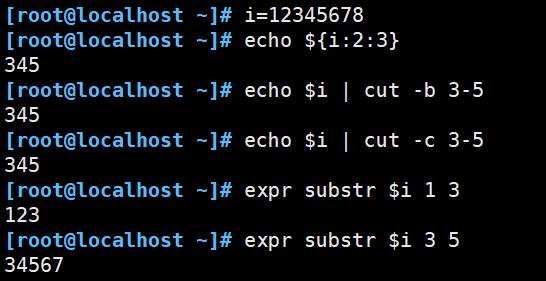
截取字符串的几种方法
五、正则表达式
正则表达式通常用于判断语句中,用来检查某一字符串是否满足某一格式。
- 正则表达式是由 普通字符 与 元字符 组成
- 普通字符包括大小写字母、数字、标点符号及一些其他符号
- 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
5.1 基础正则表达式元字符
支持的工具命令:grep、egrep、sed、awk
基础正则表达式常见元字符:
\\ :转义字符,用于取消特殊符号的含义,例:\\!、\\n、\\$、\\{、\\}等
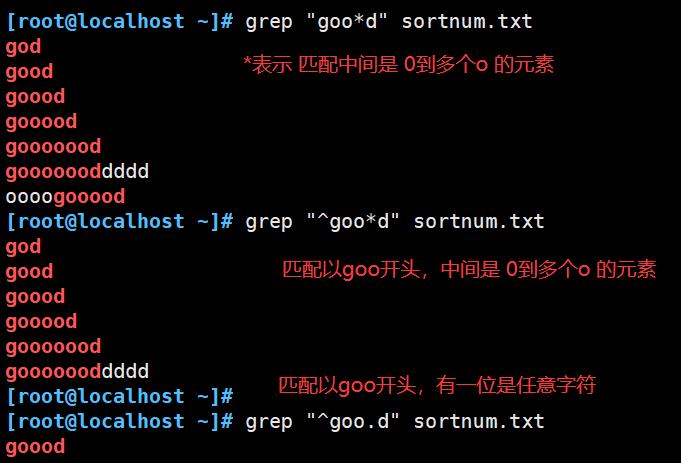
^ :匹配字符串开始的位置,例:^a、^the、^#、^[a-z]
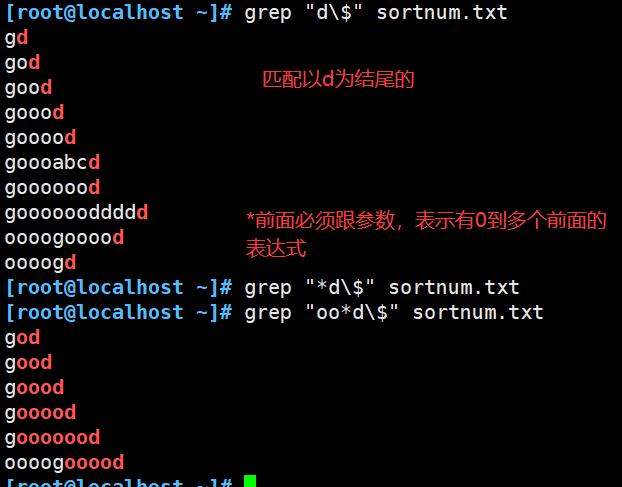
$ :匹配字符串结束的位置,例:word$、^$匹配空行
. :匹配除\\n之外的任意的一个字符,例:go.d、g..d
* :匹配前面子表达式0次或者多次,例:goo*d、go.*d
[list] :匹配list列表中的一个字符,例:go[ola]d,[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字
[^list] :匹配任意非list列表中的一个字符,例:[^0-9]、[^A-Z0-9]、[^a-z]匹配任意一位非小写字母
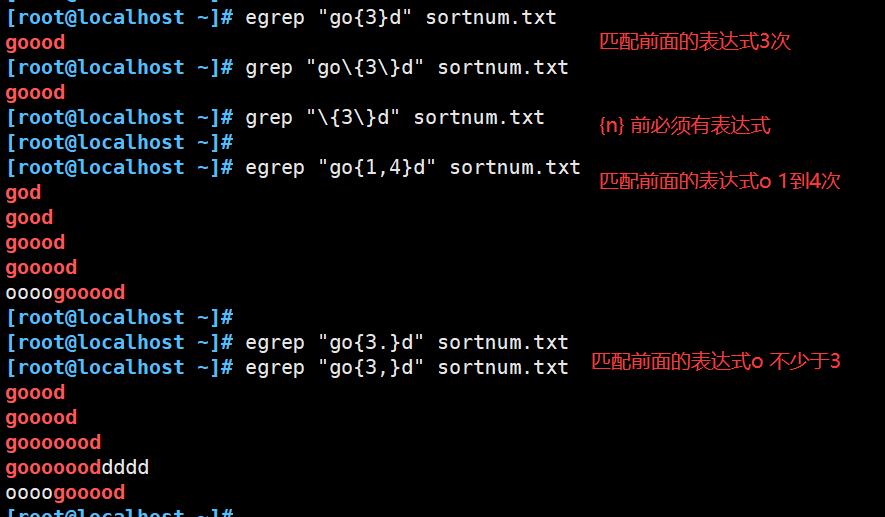
\\{n\\} :匹配前面的子表达式n次,例:go\\{2\\}d、'[0-9]\\{2\\}'匹配两位数字
\\{n,\\} :匹配前面的子表达式不少于n次,例:go\\{2,\\}d、'[0-9]\\{2,\\}'匹配两位及两位以上数字
\\{n,m\\} :匹配前面的子表达式n到m次,例:go\\{2,3\\}d、'[0-9]\\{2,3\\}'匹配两位到三位数字
注:egrep、awk使用{n}、{n,}、{n,m}匹配时“{}”前不用加“\\”
5.2 扩展正则表达式
支持的工具命令:egrep(grep -E)、awk
扩展正则表达式元字符:
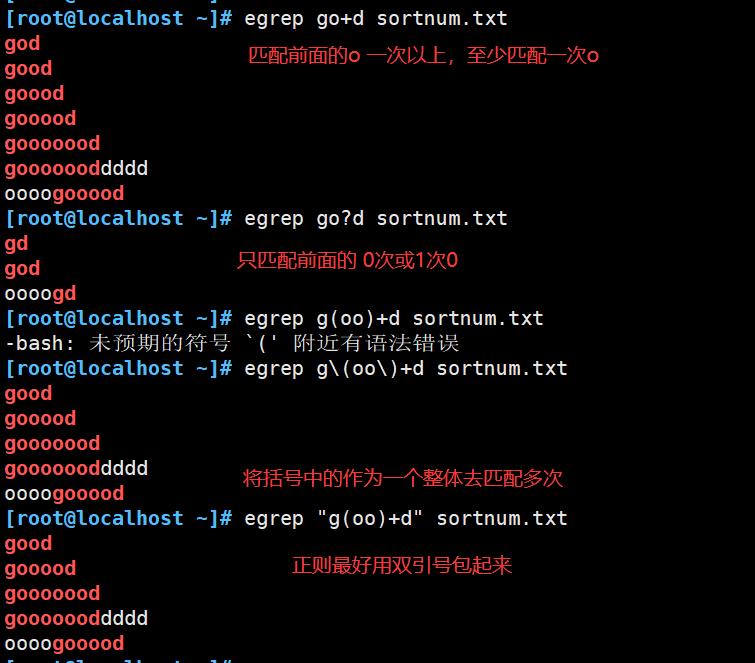
+ :匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、goood等
? :匹配前面子表达式0次或者1次,例:go?d,将匹配gd或god
() :将括号中的字符串作为一个整体,例1:g(oo)+d,将匹配oo整体1次以上,如good、gooood等
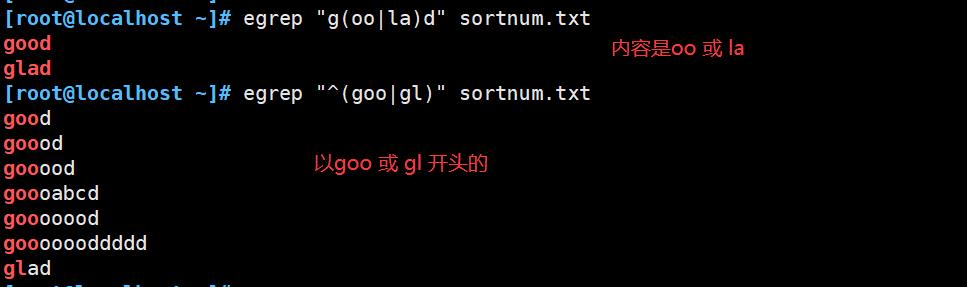
| :以或的方式匹配字条串,例:g(oo|la)d,将匹配good或者glad
测试
5.3 实验一 匹配电话号码
匹配文件中的内容:phonenum.txt
要求:
以025 或 (025) 开头
号码长度为8位
号码只能以5或8开头
区号025与号码之间可以用 空格 -
02588888888
025-5555555555
025-12345678
(025) 88551234
025 54321678
025ABC88888
01012345678
0125 12345678
方法一:
不使用扩展正则表达式元字符 ?、+、()、| 等
grep "^(*025)*[ -]*[58][0-9]\\{7\\}\\$" phonenum.txt
解释:
^(*025)* #(*、)* 表示匹配前面(或) 0 次或多次,即以025、(025)、((025))d 等开头的行
[ -]* #[ -]表示 匹配空格和-任意一个字符,后面跟上*,表示可以出现0次或多次
[58] #表示匹配5或8任意一个字符
[0-9]\\{7\\}\\$ #表示有七位由0-9组成的数,且以0-9中一个数为结尾

方法二
使用扩展正则表达式元字符,必须结合 egrep 或 awk 使用,用 grep 命令无效,也可以使用 grep -E 。
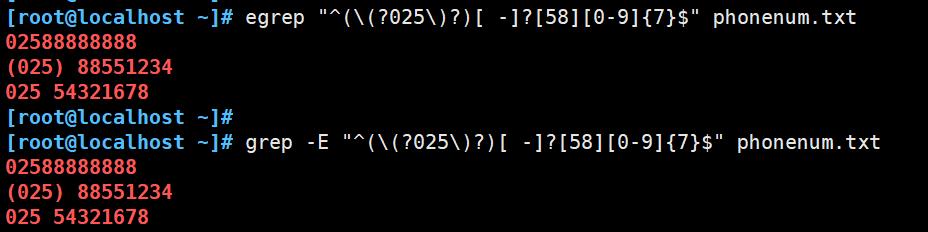
egrep "^(\\(?025\\)?)[ -]?[58][0-9]{7}$" phonenum.txt
因为连续用两个括号,里面的要用转义符\\(\\)
? 表示匹配前面表达式0次或者1次,比如ab?c,将匹配ac或abc
[ -]? 表示可能是 空格,可能是-,可能啥都没有
[0-9]{7} 表示[0-9]执行其七次
使用扩展 egrep 或 grep -E {、} 和 $ 不需要使用转义符
方法三:
或者用 awk 命令
awk '/^\\(?025\\)?[ -]?[58][0-9]{7}$/{print $0}' phonenum.txt
#需要前后各加一个 / /,代表过滤,即 /正则表达式/{print ${0}}

5.4 匹配邮箱号
邮箱的结构: 用户名@子域名.顶级域名
首先匹配用户名
^([a-zA-Z0-9_-\\.]{6,})@
用户名可以是【 大小写字母 数字 . - _ ! # 】
且用户名不小于6位
子域名
任意长度
[a-zA-Z0-9_-\\.]+
+ 表示前面可以出现一次及以上
顶级域名长度一般为2-5,.要加转义符
\\.([a-zA-Z]{2,5})$
操作:
[root@localhost ~]# cat emailname.txt
dawdawddawd
304350406@qq.com
4654654@@dddd
1876266@163.com
6576576qq.com
138355@sinacom
4_5.54A-D@google.com
66_.!#54A-D@google.com
duanbao@qq.com.cn
egrep "^([0-9a-zA-Z_-\\.\\#\\!]{6,})@([a-z0-9A-Z_-\\.]+)\\.([a-zA-Z]{2,5})$" emailname.txt
#用户名最少为6位,_下划线最好放在特殊字符的前面,不然会有问题
#用@隔开 用户名与子域
#顶级域为 2-5 个字符
#测试(.*)用的,表示任意位字符
egrep "^([0-9])(.*)@([a-z0-9A-Z\\.]+)\\.[a-zA-Z]{2,5}$" emailname.txt
#以0-9中一位开头的,到@之间任意字符的。。。。。。

六、eval 命令
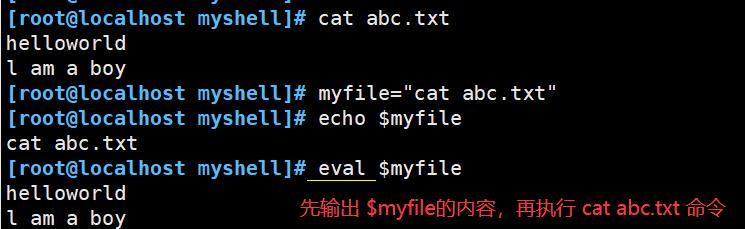
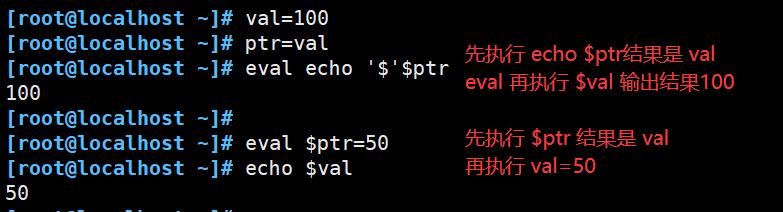
- eval 用于shell 在执行命令行之前 扫描两次;
- 用于重新运算求出参数的内容后进行输出
- 如下图会执行两次 echo命令
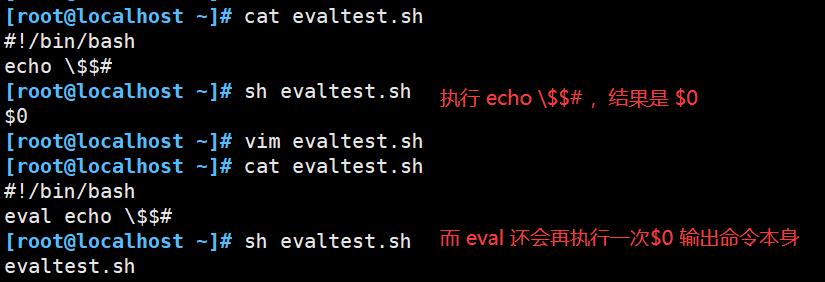
- 该命令适用于那些一次扫描无法实现其功能的变量。该命令可以对变量进行两次扫描。
- 命令前加上 eval 时,shell 就会在执行命令之前扫描它两次;eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。

也可以执行多次, 重新运算三次 echo 命令
eval echo "aaa";ls;ll
以上是关于shell 命令 之 sortuniqtrcuteval 与 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章