机器学习40讲 学习笔记13 线性降维
Posted bohu83
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习40讲 学习笔记13 线性降维相关的知识,希望对你有一定的参考价值。
一 序
本文属于极客时间机器学习40讲学习笔记系列。
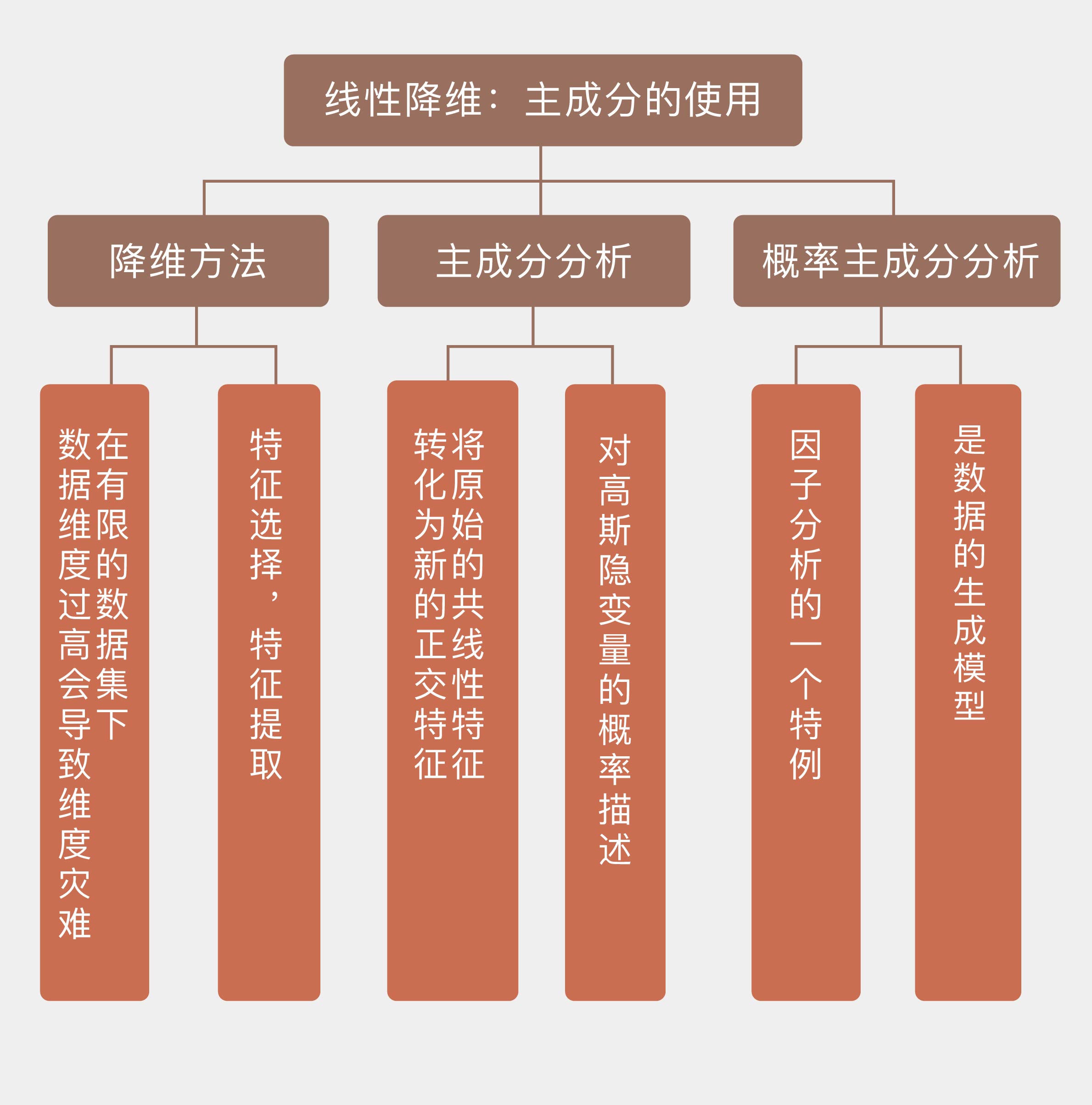
13 线性降维:主成分的使用
在前一篇文章中,老师以岭回归和 LASSO 为例介绍了线性回归的正则化处理。这两种方法都属于收缩方法(shrinkage method),它们能够使线性回归的系数连续变化。但和岭回归不同的是,LASSO 可以将一部分属性的系数收缩为 0,事实上起到了筛选属性的作用。换个说法就是降维(dimensionality reduction),也就是直接降低输入属性的数目来削减数据的维度。
维数灾难深层次的原因在于数据样本的有限,化繁为简的降维是必经之路。直接砍掉鸡肋属性,这种“简单粗暴”的做法就是特征选择(feature selection)。另一种更加稳妥的办法是破旧立新,将所有原始属性的信息一点儿不浪费地整合到脱胎换骨的新属性中,这就是特征提取(feature extraction)的方法。
中间关于矩阵分解的推导没看懂,略过去了。
岭回归收缩系数的对象并非每个单独的属性,而是由属性的线性组合计算出来的互不相关的主成分,主成分上数据的方差越小,其系数收缩地就越明显。
数据在一个主成分上波动较大意味着主成分的取值对数据有较高的区分度,也就是上一季中提到的“最大方差原理”。反之,数据在另一个主成分上方差较小就说明不同数据的取值较为集中,而聚成一团的数据显然是不容易区分的。岭回归正是通过削弱方差较小的主成分、保留方差较大的主成分来简化模型,实现正则化的。

不同方差的主成分示意图,2 点钟方向的主成分方差较大,11 点钟方向的主成分方差较小
既然主成分都已经算出来了,与其用岭回归兜一个圈子,莫不如直接使用它们作为自变量来计算线性回归的系数,这种思路得到的就是主成分回归。主成分回归以每个主成分
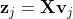 作为输入计算回归参数。由于不同的主成分是两两正交的,因此这个看似多元线性回归的问题实质上是多个独立的简单线性回归的组合。就是下图的
作为输入计算回归参数。由于不同的主成分是两两正交的,因此这个看似多元线性回归的问题实质上是多个独立的简单线性回归的组合。就是下图的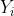 之间相互无关.
之间相互无关.

还有个特征:让样本的方差尽量的大,在实际的情况下就是在主成分中,使得方差最大的几个主成分得以保留,而方差很小的主成分进行抛弃。
前面对主成分分析的解释都是从降维的角度出发的。换个角度,主成分分析可以看成对高斯隐变量的概率描述。概率主成分分析(probabilistic principal component analysis)体现的就是高斯型观测结果和高斯隐变量之间线性的相关关系,它是因子分析(factor analysis)的一个特例。数学推导比较复杂,没看懂。插一句,对于数学机器好的,没啥区别。但是在贪心NLP上,文哲老师会给出数学推导的背景知识讲解。降低学习门槛。这个不懂就得自己啃资料了。
在实际问题中,使用的主成分数目是个超参数,需要通过模型选择确定,而概率主成分分析对测试数据的处理就可以完成模型选择的任务。从重构误差的角度出发,经典主成分分析一般会让被选中的主成分的特征值之和占所有特征值之和的 95% 以上
同其他隐变量模型一样,概率主成分分析也是个生成模型,其生成机制如下图所示。首先从服从一维正态分布的隐变量z中得到采样值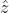 ,以
,以 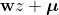 为均值的单位方差二维正态分布就是数据
为均值的单位方差二维正态分布就是数据  的似然分布,将先验分布与似然分布相乘,得到的就是最右侧的二维分布
的似然分布,将先验分布与似然分布相乘,得到的就是最右侧的二维分布 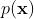 了。
了。
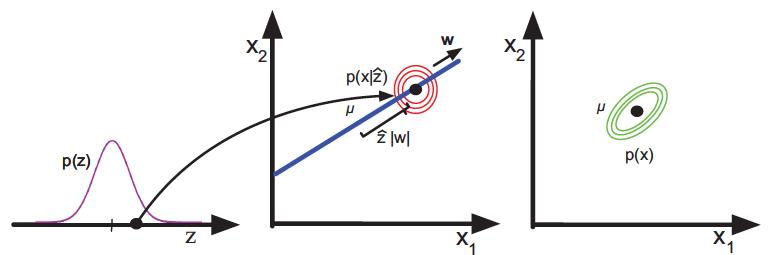
概率主成分分析表示的数据生成机制
在 Scikit-learn 中,主成分分析对应的类是 PCA,它在 decomposition 的模块中。
以上是关于机器学习40讲 学习笔记13 线性降维的主要内容,如果未能解决你的问题,请参考以下文章