Spring Boot - 构建数据访问层
Posted 小小工匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Boot - 构建数据访问层相关的知识,希望对你有一定的参考价值。
文章目录

基础规范: JDBC 关系型数据库访问规范
我们将进入 Spring Boot 另一个核心技术体系的讨论,即数据访问技术体系。无论是互联网应用还是传统软件,对于任何一个系统而言,数据的存储和访问都是不可缺少的。
数据访问层的构建可能会涉及多种不同形式的数据存储媒介,这里关注的是最基础也是最常用的数据存储媒介,即关系型数据库,针对关系型数据库,Java 中应用最广泛的就是 JDBC 规范,今天我们将对这个经典规范展开讨论。
JDBC 是 Java Database Connectivity 的全称,它的设计初衷是提供一套能够应用于各种数据库的统一标准,这套标准需要不同数据库厂家之间共同遵守,并提供各自的实现方案供 JDBC 应用程序调用。
作为一套统一标准,JDBC 规范具备完整的架构体系,如下图所示:
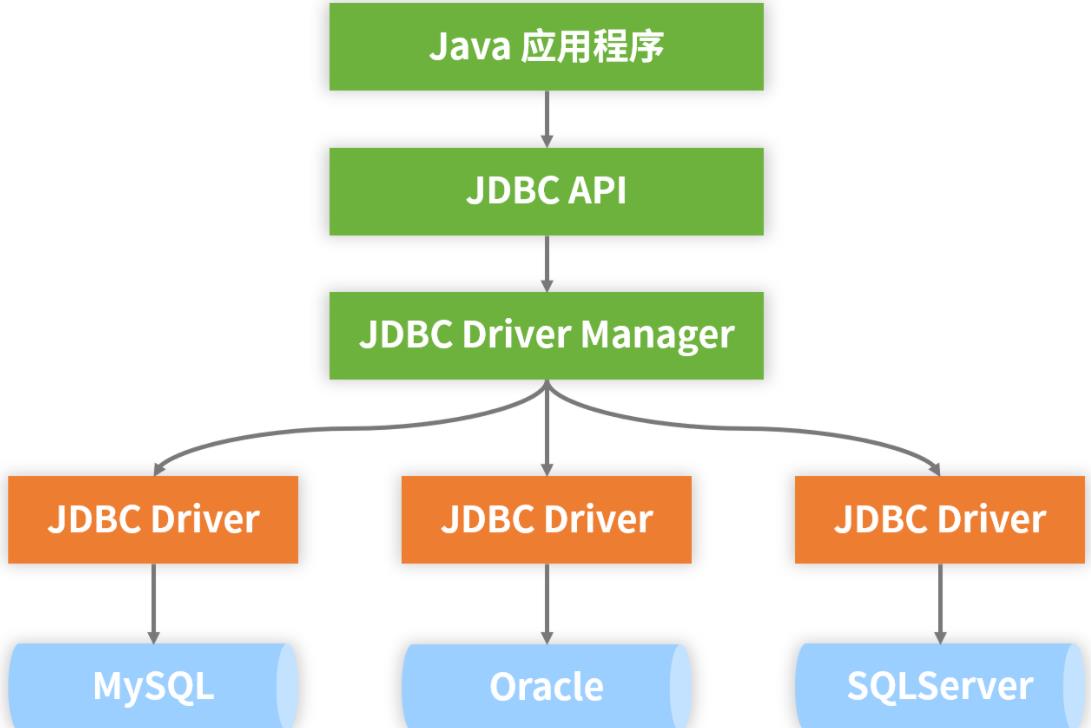
可以看到,Java 应用程序通过 JDBC 所提供的 API 进行数据访问,而这些 API 中包含了开发人员所需要掌握的各个核心编程对象
JDBC 规范中的核心编程对象
对于日常开发而言,JDBC 规范中的核心编程对象包括 DriverManger、DataSource、Connection、Statement,及 ResultSet。
DriverManager
JDBC 中的 DriverManager 主要负责加载各种不同的驱动程序(Driver),并根据不同的请求向应用程序返回相应的数据库连接(Connection),应用程序再通过调用 JDBC API 实现对数据库的操作。
JDBC 中的 Driver 定义如下,其中最重要的是第一个获取 Connection 的 connect 方法:
public interface Driver {
//获取数据库连接
Connection connect(String url, java.util.Properties info)
throws SQLException;
boolean acceptsURL(String url) throws SQLException;
DriverPropertyInfo[] getPropertyInfo(String url, java.util.Properties info)
throws SQLException;
int getMajorVersion();
int getMinorVersion();
boolean jdbcCompliant();
public Logger getParentLogger() throws SQLFeatureNotSupportedException;
}
针对 Driver 接口,不同的数据库供应商分别提供了自身的实现方案。例如,mysql 中的 Driver 实现类如下代码所示:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
// 通过 DriverManager 注册 Driver
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
…
}
这里就使用用了 DriverManager,而 DriverManager 除提供了上述用于注册 Driver 的 registerDriver 方法之外,还提供了 getConnection 方法用于针对具体的 Driver 获取 Connection 对象。
DataSource
我们知道在 JDBC 规范中可直接通过 DriverManager 获取 Connection,我们也知道获取 Connection 的过程需要建立与数据库之间的连接,而这个过程会产生较大的系统开销。
为了提高性能,通常我们首先会建立一个中间层将 DriverManager 生成的 Connection 存放到连接池中,再从池中获取 Connection。
而我们可以认为 DataSource 就是这样一个中间层,它作为 DriverManager 的替代品而推出,是获取数据库连接的首选方法。
DataSource 在 JDBC 规范中代表的是一种数据源,核心作用是获取数据库连接对象 Connection。在日常开发过程中,我们通常会基于 DataSource 获取 Connection。DataSource 接口的定义如下代码所示:
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password) throws SQLException;
}
从上面我们可以看到,DataSource 接口提供了两个获取 Connection 的重载方法,并继承了 CommonDataSource 接口。CommonDataSource 是 JDBC 中关于数据源定义的根接口,除了 DataSource 接口之外,它还有另外两个子接口,如下图所示:
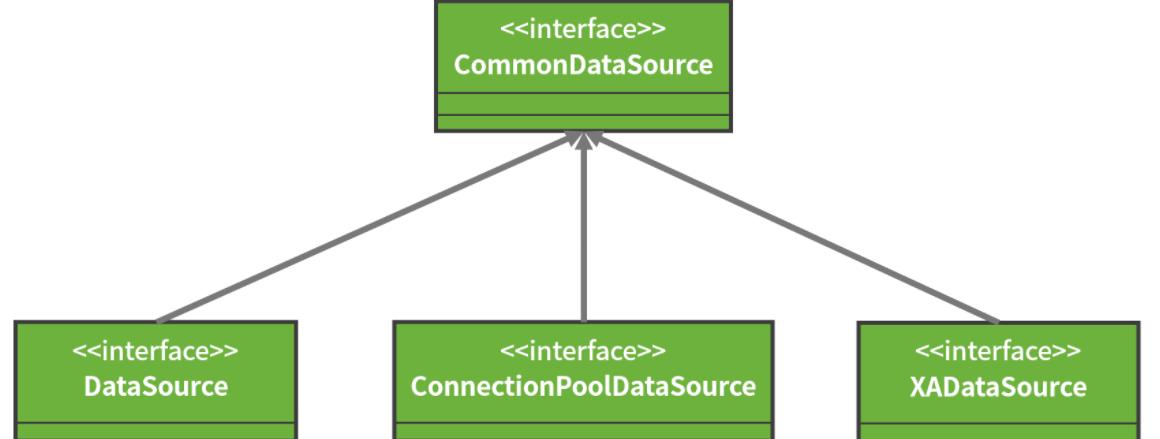
其中,DataSource 是官方定义的获取 Connection 的基础接口,XADataSource 用来在分布式事务环境下实现 Connection 的获取,而 ConnectionPoolDataSource 是从连接池 ConnectionPool 中获取 Connection 的接口。
所谓的 ConnectionPool 相当于预先生成一批 Connection 并存放在池中,从而提升 Connection 获取的效率。
请注意 DataSource 接口同时还继承了一个 Wrapper 接口。从接口的命名上看,我们可以判断该接口起到一种包装器的作用。事实上,因为很多数据库供应商提供了超越标准 JDBC API 的扩展功能,所以 Wrapper 接口可以把一个由第三方供应商提供的、非 JDBC 标准的接口包装成标准接口。
以 DataSource 接口为例,如果我们想自己实现一个定制化的数据源类 MyDataSource,就可以提供一个实现了 Wrapper 接口的 MyDataSourceWrapper 类来完成包装和适配,如下图所示:
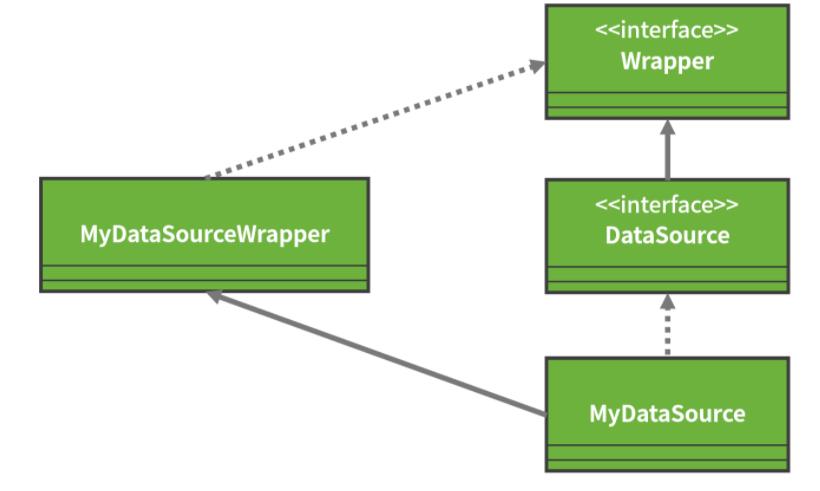
在 JDBC 规范中,除了 DataSource 之外,Connection、Statement、ResultSet 等核心对象也都继承了这个 Wrapper 接口。
作为一种基础组件,它同样不需要开发人员自己实现 DataSource,因为业界已经存在了很多优秀的实现方案,如 DBCP、C3P0 和 Druid 等。
例如 Druid 提供了 DruidDataSource,它不仅提供了连接池的功能,还提供了诸如监控等其他功能,它的类层结构如下图所示: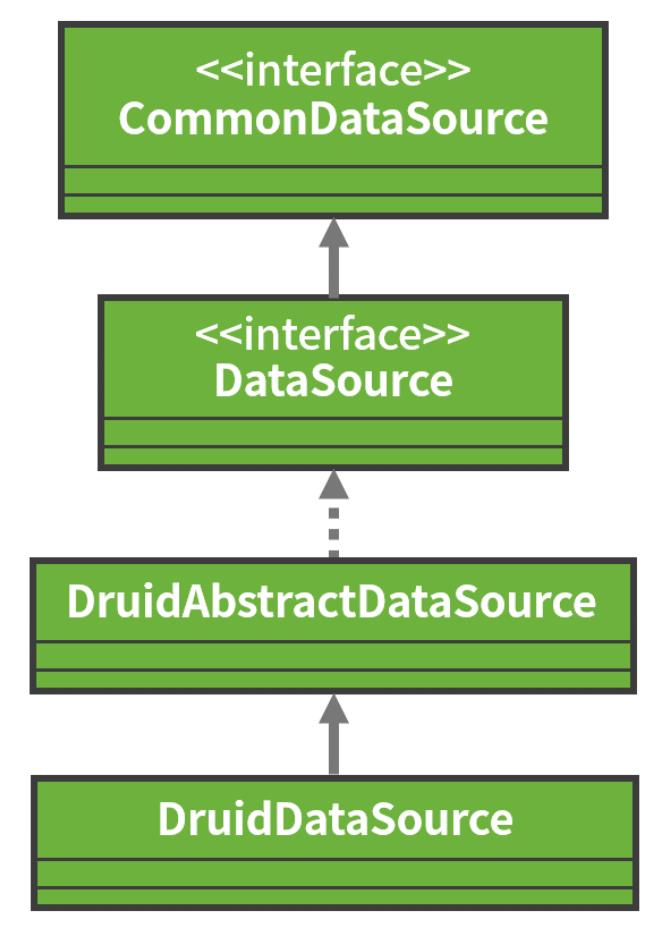
Connection
DataSource 的目的是获取 Connection 对象。我们可以把 Connection 理解为一种会话(Session)机制,Connection 代表一个数据库连接,负责完成与数据库之间的通信。
所有 SQL 的执行都是在某个特定 Connection 环境中进行的,同时它还提供了一组重载方法分别用于创建 Statement 和 PreparedStatement。另一方面,Connection 也涉及事务相关的操作。
Connection 接口中定义的方法很丰富,其中最核心的几个方法如下代码所示:
public interface Connection extends Wrapper, AutoCloseable {
//创建 Statement
Statement createStatement() throws SQLException;
//创建 PreparedStatement
PreparedStatement prepareStatement(String sql) throws SQLException;
//提交
void commit() throws SQLException;
//回滚
void rollback() throws SQLException;
//关闭连接
void close() throws SQLException;
}
这里涉及具体负责执行 SQL 语句的 Statement 和 PreparedStatement 对象,我们接着往下看。
Statement/PreparedStatement
JDBC 规范中的 Statement 存在两种类型,一种是普通的 Statement,一种是支持预编译的 PreparedStatement。
所谓预编译,是指数据库的编译器会对 SQL 语句提前编译,然后将预编译的结果缓存到数据库中,下次执行时就可以通过替换参数并直接使用编译过的语句,从而大大提高 SQL 的执行效率。
当然,这种预编译也需要一定成本,因此在日常开发中,如果对数据库只执行一次性读写操作时,用 Statement 对象进行处理会比较合适;而涉及 SQL 语句的多次执行时,我们可以使用 PreparedStatement。
如果需要查询数据库中的数据,我们只需要调用 Statement 或 PreparedStatement 对象的 executeQuery 方法即可。
这个方法以 SQL 语句作为参数,执行完后返回一个 JDBC 的 ResultSet 对象。当然,Statement 或 PreparedStatement 还提供了一大批执行 SQL 更新和查询的重载方法,我们无意一一展开。
以 Statement 为例,它的核心方法如下代码所示:
public interface Statement extends Wrapper, AutoCloseable {
//执行查询语句
ResultSet executeQuery(String sql) throws SQLException;
//执行更新语句
int executeUpdate(String sql) throws SQLException;
//执行 SQL 语句
boolean execute(String sql) throws SQLException;
//执行批处理
int[] executeBatch() throws SQLException;
}
这里我们同样引出了 JDBC 规范中最后一个核心编程对象,即代表执行结果的 ResultSet。
ResultSet
一旦我们通过 Statement 或 PreparedStatement 执行了 SQL 语句并获得了 ResultSet 对象,就可以使用该对象中定义的一大批用于获取 SQL 执行结果值的工具方法,如下代码所示:
public interface ResultSet extends Wrapper, AutoCloseable {
//获取下一个结果
boolean next() throws SQLException;
//获取某一个类型的结果值
Value getXXX(int columnIndex) throws SQLException;
…
}
如何使用 JDBC 规范访问数据库
对于开发人员而言,JDBC API 是我们访问数据库的主要途径,如果我们使用 JDBC 开发一个访问数据库的执行流程,常见的代码风格如下所示(省略了异常处理):
// 创建池化的数据源
PooledDataSource dataSource = new PooledDataSource ();
// 设置 MySQL Driver
dataSource.setDriver ("com.mysql.jdbc.Driver");
// 设置数据库 URL、用户名和密码
dataSource.setUrl ("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root");
// 获取连接
Connection connection = dataSource.getConnection();
// 执行查询
PreparedStatement statement = connection.prepareStatement ("select * from user");
// 获取查询结果进行处理
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
…
}
// 关闭资源
statement.close();
resultSet.close();
connection.close();
这段代码中完成了对基于前面介绍的 JDBC API 中的各个核心编程对象的数据访问。上述代码主要面向查询场景,而针对用于插入数据的处理场景,我们只需要在上述代码中替换几行代码,即将“执行查询”和“获取查询结果进行处理”部分的查询操作代码替换为插入操作代码就行。
最后,我们梳理一下基于 JDBC 规范进行数据库访问的整个开发流程,如下图所示: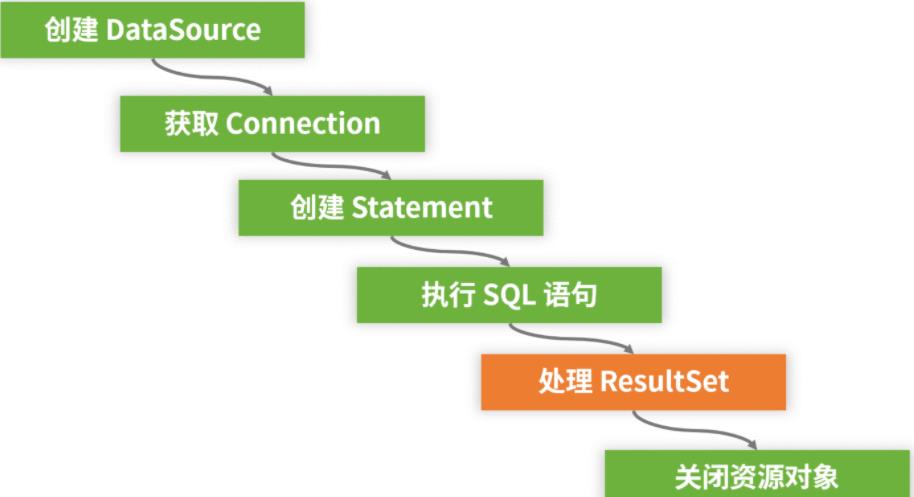
我们明确地将基于 JDBC 规范访问关系型数据库的操作分成两大部分:一部分是准备和释放资源以及执行 SQL 语句,另一部分则是处理 SQL 执行结果。
而对于任何数据访问而言,前者实际上都是重复的。在上图所示的整个开发流程中,事实上只有“处理 ResultSet ”部分的代码需要开发人员根据具体的业务对象进行定制化处理。这种抽象为整个执行过程提供了优化空间。诸如 Spring 框架中 JdbcTemplate 这样的模板工具类就应运而生了
数据访问: JdbcTemplate 访问关系型数据库
JDBC 规范是 Java 领域中使用最广泛的数据访问标准,目前市面上主流的数据访问框架都是构建在 JDBC 规范之上。
因为 JDBC 是偏底层的操作规范,所以关于如何使用 JDBC 规范进行关系型数据访问的实现方式有很多(区别在于对 JDBC 规范的封装程度不同),而在 Spring 中,同样提供了 JdbcTemplate 模板工具类实现数据访问,它简化了 JDBC 规范的使用方法,jiex我们将围绕这个模板类展开讨论。
数据模型和 Repository 层设计
我们知道一个订单中往往涉及一个或多个商品, 我们主要通过一对多的关系来展示数据库设计和实现方面的技巧。而为了使描述更简单,我们把具体的业务字段做了简化。Order 类的定义如下代码所示:
Domain设计
public class Order{
private Long id; //订单Id
private String orderNumber; //订单编号
private String deliveryAddress; //物流地址
private List<Goods> goodsList; //商品列表
//省略了 getter/setter
}
其中代表商品的 Goods 类定义如下:
public class Goods {
private Long id; //商品Id
private String goodsCode; //商品编号
private String goodsName; //商品名称
private Double price; //商品价格
//省略了 getter/setter
}
数据模型
从以上代码,我们不难看出一个订单可以包含多个商品,因此设计关系型数据库表时,我们首先会构建一个中间表来保存 Order 和 Goods 这层一对多关系。
DROP TABLE IF EXISTS `order`;
DROP TABLE IF EXISTS `goods`;
DROP TABLE IF EXISTS `order_goods`;
create table `order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`order_number` varchar(50) not null,
`delivery_address` varchar(100) not null,
`create_time` timestamp not null DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);
create table `goods` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`goods_code` varchar(50) not null,
`goods_name` varchar(50) not null,
`goods_price` double not null,
`create_time` timestamp not null DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);
create table `order_goods` (
`order_id` bigint(20) not null,
`goods_id` bigint(20) not null,
foreign key(`order_id`) references `order`(`id`),
foreign key(`goods_id`) references `goods`(`id`)
);
抽象数据库访问的入口
基于以上数据模型,我们将完成 order-server 中的 Repository 层组件的设计和实现。首先,我们需要设计一个 OrderRepository 接口,用来抽象数据库访问的入口,如下代码所示:
public interface OrderRepository {
Order addOrder(Order order);
Order getOrderById(Long orderId);
Order getOrderDetailByOrderNumber(String orderNumber);
}
这个接口非常简单,方法都是自解释的。不过请注意,这里的 OrderRepository 并没有继承任何父接口,完全是一个自定义的、独立的 Repository。
针对上述 OrderRepository 中的接口定义,我们将构建一系列的实现类。
-
OrderRawJdbcRepository:使用原生 JDBC 进行数据库访问
-
OrderJdbcRepository:使用 JdbcTemplate 进行数据库访问
-
OrderJpaRepository:使用 Spring Data JPA 进行数据库访问
原生的实现
OrderRawJdbcRepository 类中实现方法如下代码所示:
@Repository("orderRawJdbcRepository")
public class OrderRawJdbcRepository implements OrderRepository {
@Autowired
private DataSource dataSource;
@Override
public Order getOrderById(Long orderId) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
connection = dataSource.getConnection();
statement = connection.prepareStatement("select id, order_number, delivery_address from `order` where id=?");
statement.setLong(1, orderId);
resultSet = statement.executeQuery();
Order order = null;
if (resultSet.next()) {
order = new Order(resultSet.getLong("id"), resultSet.getString("order_number"),
resultSet.getString("delivery_address"));
}
return order;
} catch (SQLException e) {
System.out.print(e);
} finally {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
}
}
}
return null;
}
//省略其他 OrderRepository 接口方法实现
}
这里,值得注意的是,我们首先需要在类定义上添加 @Repository 注解,标明这是能够被 Spring 容器自动扫描的 Javabean,再在 @Repository 注解中指定这个 Javabean 的名称为"orderRawJdbcRepository",方便 Service 层中根据该名称注入 OrderRawJdbcRepository 类。
可以看到,上述代码使用了 JDBC 原生 DataSource、Connection、PreparedStatement、ResultSet 等核心编程对象完成针对“order”表的一次查询。代码流程看起来比较简单,其实也比较烦琐,学到这里,我们可以结合上一课时的内容理解上述代码。
请注意,如果我们想运行这些代码,千万别忘了在 Spring Boot 的配置文件中添加对 DataSource 的定义,如下代码所示:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/appointment
username: root
password: root
使用 JdbcTemplate 操作数据库
要想在应用程序中使用 JdbcTemplate,首先我们需要引入对它的依赖,如下代码所示:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
JdbcTemplate 提供了一系列的 query、update、execute 重载方法应对数据的 CRUD 操作。
使用 JdbcTemplate 实现查询
我们先来讨论一下最简单的查询操作,并对 OrderRawJdbcRepository 中的 getOrderById 方法进行重构。为此,我们构建了一个新的 OrderJdbcRepository 类并同样实现了 OrderRepository 接口,如下代码所示:
@Repository("orderJdbcRepository")
public class OrderJdbcRepository implements OrderRepository {
private JdbcTemplate jdbcTemplate;
@Autowired
public OrderJdbcRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
}
可以看到,这里通过构造函数注入了 JdbcTemplate 模板类。
而 OrderJdbcRepository 的 getOrderById 方法实现过程如下代码所示:
@Override
public Order getOrderById(Long orderId) {
Order order = jdbcTemplate.queryForObject("select id, order_number, delivery_address from `order` where id=?",
this::mapRowToOrder, orderId);
return order;
}
显然,这里使用了 JdbcTemplate 的 queryForObject 方法执行查询操作,该方法传入目标 SQL、参数以及一个 RowMapper 对象。其中 RowMapper 定义如下:
public interface RowMapper<T> {
T mapRow(ResultSet rs, int rowNum) throws SQLException;
}
从 mapRow 方法定义中,我们不难看出 RowMapper 的作用就是处理来自 ResultSet 中的每一行数据,并将来自数据库中的数据映射成领域对象。例如,使用 getOrderById 中用到的 mapRowToOrder 方法完成对 Order 对象的映射,如下代码所示:
private Order mapRowToOrder(ResultSet rs, int rowNum) throws SQLException {
return new Order(rs.getLong("id"), rs.getString("order_number"), rs.getString("delivery_address"));
}
讲到这里,你可能注意到 getOrderById 方法实际上只是获取了 Order 对象中的订单部分信息,并不包含商品数据。
接下来,我们再来设计一个 getOrderDetailByOrderNumber 方法,根据订单编号获取订单以及订单中所包含的所有商品信息,如下代码所示:
@Override
public Order getOrderDetailByOrderNumber(String orderNumber) {
//获取 Order 基础信息
Order order = jdbcTemplate.queryForObject(
"select id, order_number, delivery_address from `order` where order_number=?", this::mapRowToOrder,
orderNumber);
if (order == null)
return order;
//获取 Order 与 Goods 之间的关联关系,找到给 Order 中的所有 GoodsId
Long orderId = order.getId();
List<Long> goodsIds = jdbcTemplate.query("select order_id, goods_id from order_goods where order_id=?",
new ResultSetExtractor<List<Long>>() {
public List<Long> extractData(ResultSet rs) throws SQLException, DataAccessException {
List<Long> list = new ArrayList<Long>();
while (rs.next()) {
list.add(rs.getLong("goods_id"));
}
return list;
}
}, orderId);
//根据 GoodsId 分别获取 Goods 信息并填充到 Order 对象中
for (Long goodsId : goodsIds) {
Goods goods = getGoodsById(goodsId);
order.addGoods(goods);
}
return order;
}
首先,我们获取 Order 基础信息,并通过 Order 中的 Id 编号从中间表中获取所有 Goods 的 Id 列表,通过遍历这个 Id 列表再分别获取 Goods 信息,最后将 Goods 信息填充到 Order 中,从而构建一个完整的 Order 对象。
这里通过 Id 获取 Goods 数据的实现方法也与 getOrderById 方法的实现过程一样,如下代码所示
private Goods getGoodsById(Long goodsId) {
return jdbcTemplate.queryForObject("select id, goods_code, goods_name, price from goods where id=?",
this::mapRowToGoods, goodsId);
}
private Goods mapRowToGoods(ResultSet rs, int rowNum) throws SQLException {
return new Goods(rs.getLong("id"), rs.getString("goods_code"), rs.getString("goods_name"),
rs.getDouble("price"));
}
使用 JdbcTemplate 实现插入
在 JdbcTemplate 中,我们可以通过 update 方法实现数据的插入和更新。针对 Order 和 Goods 中的关联关系,插入一个 Order 对象需要同时完成两张表的更新,即 order 表和 order_goods 表,因此插入 Order 的实现过程也分成两个阶段,如下代码所示的 addOrderWithJdbcTemplate 方法展示了这一过程:
private Order addOrderDetailWithJdbcTemplate(Order order) {
//插入 Order 基础信息
Long orderId = saveOrderWithJdbcTemplate(order);
order.setId(orderId);
//插入 Order 与 Goods 的对应关系
List<Goods> goodsList = order.getGoods();
for (Goods goods : goodsList) {
saveGoodsToOrderWithJdbcTemplate(goods, orderId);
}
return order;
}
可以看到,这里同样先是插入 Order 的基础信息,然后再遍历 Order 中的 Goods 列表并逐条进行插入。其中的 saveOrderWithJdbcTemplate 方法如下代码所示:
private Long saveOrderWithJdbcTemplate(Order order) {
PreparedStatementCreator psc = new 以上是关于Spring Boot - 构建数据访问层的主要内容,如果未能解决你的问题,请参考以下文章