面试官:单表数据量大一定要分库分表吗?我用6个字和10张图回答
Posted java构架师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:单表数据量大一定要分库分表吗?我用6个字和10张图回答相关的知识,希望对你有一定的参考价值。
一、 文章概述
在业务发展初期单表完全可以满足业务需求,在阿里巴巴开发手册也建议:单表行数超过500万行或者单表容量超过2GB才推荐进行分库分表,如果预计三年后数据量根本达不到这个级别,请不要在创建表时就分库分表。
但是随着业务的发展和深入,单表数据量不断增加,逐渐成为业务系统的瓶颈。这是为什么呢?
从宏观层面分析任何物体都必然有其物理极限。1965年英特尔创始人摩尔预测:集成电路上可容纳的元器件的数目,约每隔24个月增加一倍,性能提升一倍,即计算机性能每两年翻一番。
但是摩尔定律会有终点吗?有些科学家认为摩尔定律是有终点的:半导体芯片单位面积可集成的元件数量是有极限的,因为半导体芯片制程工艺的物理极限为2到3纳米。当然也有科学家不支持这种说法,但是我们可以从中看出物理极限是很难突破的,当单表数据量达到一定规模时必然也达到极限。
从细节层面分析我们将数据保存在数据库,实际上是保存在磁盘中,一次磁盘IO操作需要经历寻道、旋转延时、数据传输三个步骤,那么一次磁盘IO耗时公式如下:
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间
总体来说上述操作都较为耗时,速度和内存相比有着数量级的差距,当数据量过大磁盘这一瓶颈更加明显。那么应该怎么办?处理单表数据量过大有以下六字口诀:删、换、分、拆、异、热。

删是指删除历史数据并进行归档。换是指不要只使用数据库资源,有些数据可以存储至其它替代资源。分是指读写分离,增加多个读实例应对读多写少的互联网场景。拆是指分库分表,将数据分散至不同的库表中减轻压力。异指数据异构,将一份数据根据不同业务需求保存多份。热是指热点数据,这是一个非常值得注意的问题。
二、删
我们分析这样一个场景:消费者会经常查询一年之前的订单记录吗?答案是一般不会,或者说这种查询需求量很小。根据上述分析那么一年前的数据我们就没有必要放在单表这张业务主表,可以将一年前的数据迁移到历史归档表。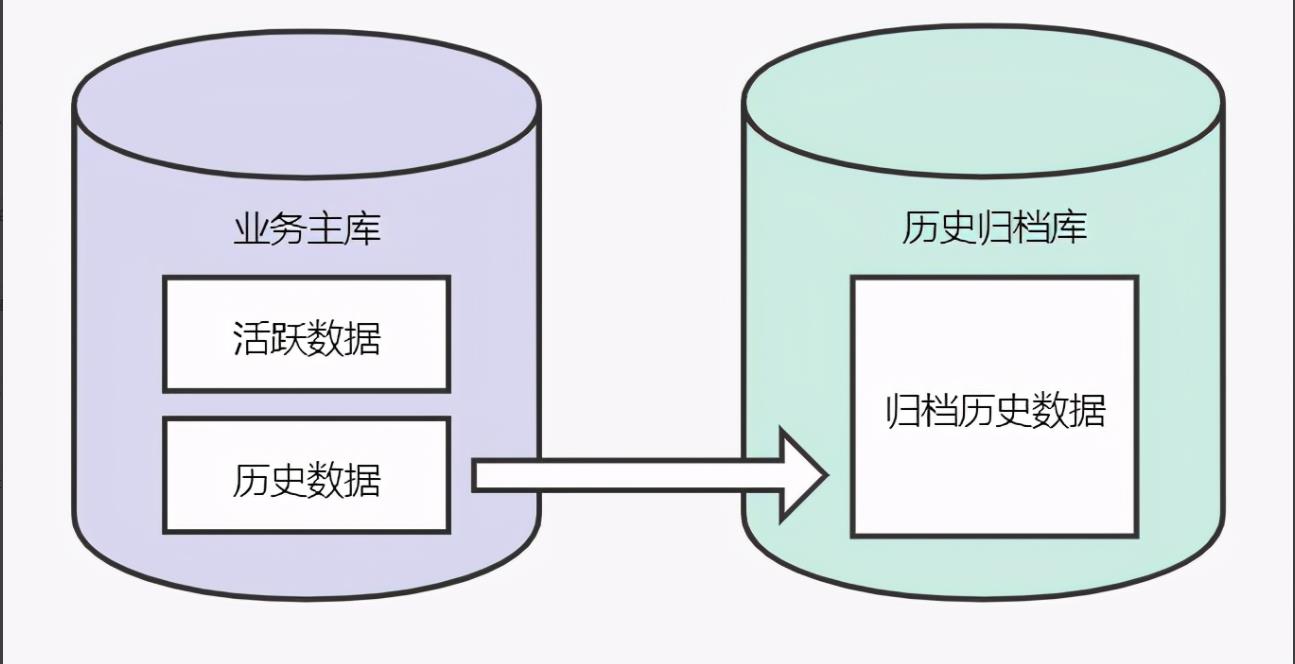
在查询历史数据表时,可以限制查询条件如必须选择日期范围,日期范围不能超过X个月等等从而减轻查询压力。
处理历史存量数据比较简单,因为存量数据一般是静态的,此时状态已经不再改变了。数据处理一般分为以下两个步骤:
(1) 迁移一年前数据至历史归档表
(2) 根据主键分批删除主表数据
不能一次性删除所有数据,因为数据量太大可能会引发超时,而是应该根据ID分批删除,例如每次删除500条数据。
第一步查询一年前主键最大值和最小值,这是我们需要删除的数据范围:
SELECT
MIN(id) AS minId,
MAX(id) AS maxId
FROM biz_table
WHERE create_time < DATE_SUB(now(),INTERVAL 1 YEAR)
第二步删除数据时不能一次性全部删掉,因为很可能会超时,我们可以通过代码动态更新endId进行批量删除:
DELETE FROM biz_table
WHERE id >= #{minId}
AND id <= #{maxId}
AND id <= #{endId}
LIMIT 500
三、换
换是指换一个存储介质,当然并不是说完全替换,而是用其它存储介质对数据库做一个补充。例如海量流水记录,这类数据量级是巨量的,根本不适合存储在mysql数据库中,那么这些数据可以存在哪里呢?
现在互联网公司一般都具备与之规模相对应的大数据服务或者平台,那么作为业务开发者要善于应用公司大数据能力,减轻业务数据库压力。
3.1 消息队列
这些海量数据可以存储至Kafka,因为其本质上就是分布式的流数据存储系统。使用Kafka有如下优点:
第一个优点是Kafka社区活跃功能强大,已经成为了一种事实上的工业标准。大数据很多组件都提供了Kafka接入组件,经过生产验证并且对接成本较小,可以为下游业务提供更多选择。
第二个优点是Kafka具有消息队列本身的优点例如解耦、异步和削峰。
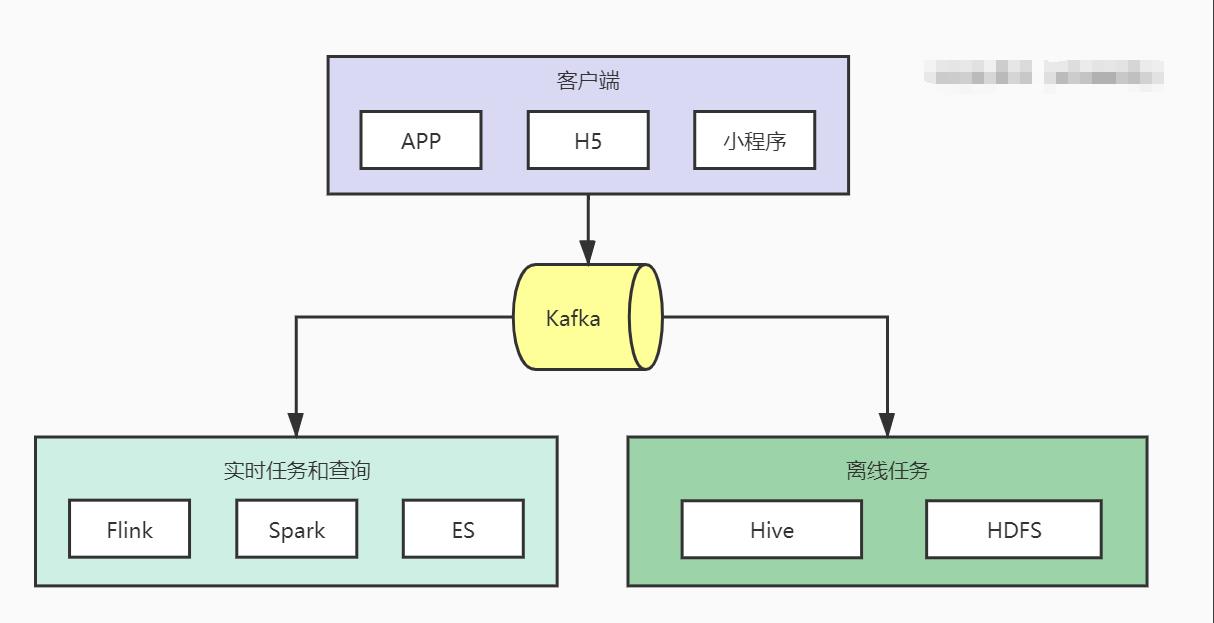
假设这些海量数据都已经存储在Kafka,现在我们希望这些数据可以产生业务价值,这涉及到两种数据分析任务:离线任务和实时任务。
离线任务对实时性要求不高,例如每天、每周、每月的数据报表统计分析,我们可以使用基于MapReduce数据仓库工具Hive进行报表统计。
实时任务对实时性要求高,例如根据用户相关行为推荐用户感兴趣的商品,提高用户购买体验和效率,可以使用Flink进行流处理分析。例如运营后台查询分析,可以将数据同步至ES进行检索。
还有一种分类方式是将任务分为批处理任务和流处理任务,我们可以这么理解:离线任务一般使用批处理技术,实时任务一般使用流处理技术。
3.2 API
上一个章节我们使用了Kafka进行海量数据存储,由于其强大兼容性和集成度,可以作为数据中介将数据进行中转和解耦。
当然我们并不是必须使用Kafka进行中转,例如我们直接可以使用相关Java API将数据存入Hive、ES、HBASE等。
但是我并不推荐这种做法,因为将保存流水这样操作耦合进业务代码并不合适,违反了高内聚低耦合的原则,尽量不要使用。
3.3 缓存
从广义上理解换这个字,我们还可以引入Redis远程缓存,把Redis放在MySQL前面,拦下一些高频读请求,但是要注意缓存穿透和击穿问题。
缓存穿透和击穿从最终结果上来说都是流量绕过缓存打到了数据库,可能会导致数据库挂掉或者系统雪崩,但是仔细区分还是有一些不同,我们分析一张业务读取缓存一般流程图。
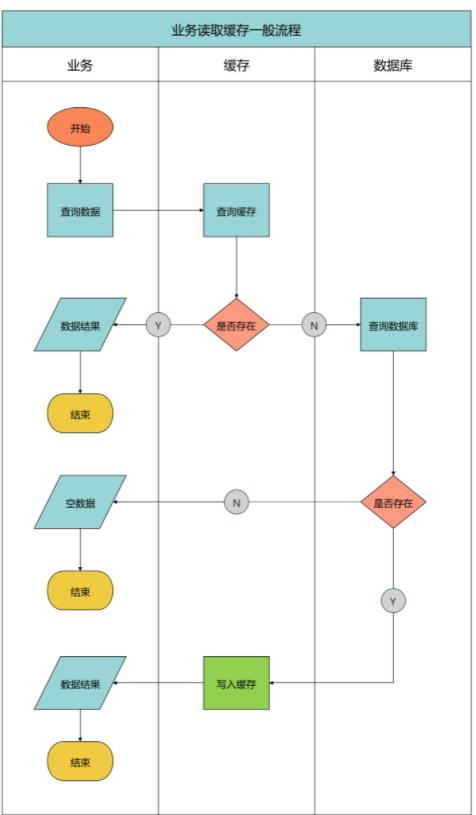
我们用文字简要描述这张图:
(1) 业务查询数据时首先查询缓存,如果缓存存在数据则返回,流程结束
(2) 如果缓存不存在数据则查询数据库,如果数据库不存在数据则返回空数据,流程结束
(3) 如果数据库存在数据则将数据写入缓存并返回数据给业务,流程结束
假设业务方要查询A数据,缓存穿透是指数据库根本不存在A数据,所以根本没有数据可以写入缓存,导致缓存层失去意义,大量请求会频繁访问数据库。
缓存击穿是指请求在查询数据库前,首先查缓存看看是否存在,这是没有问题的。但是并发量太大,导致第一个请求还没有来得及将数据写入缓存,后续大量请求已经开始访问缓存,这是数据在缓存中还是不存在的,所以瞬时大量请求会打到数据库。
我们可以使用分布式锁加上自旋解决这个问题,本文给出一段示例代码:
/**
* 业务回调
*
* @author 今日头条号「JAVA前线」
*
*/
public interface RedisBizCall {
/**
* 业务回调方法
*
* @return 序列化后数据值
*/
String call();
}
/**
* 安全缓存管理器
*
* @author 今天头条号「JAVA前线」
*
*/
@Service
public class SafeRedisManager {
@Resource
private RedisClient RedisClient;
@Resource
private RedisLockManager redisLockManager;
public String getDataSafe(String key, int lockExpireSeconds, int dataExpireSeconds, RedisBizCall bizCall, boolean alwaysRetry) {
boolean getLockSuccess = false;
try {
while(true) {
String value = redisClient.get(key);
if (StringUtils.isNotEmpty(value)) {
return value;
}
/** 竞争分布式锁 **/
if (getLockSuccess = redisLockManager.tryLock(key, lockExpireSeconds)) {
value = redisClient.get(key);
if (StringUtils.isNotEmpty(value)) {
return value;
}
/** 查询数据库 **/
value = bizCall.call();
/** 数据库无数据则返回**/
if (StringUtils.isEmpty(value)) {
return null;
}
/** 数据存入缓存 **/
redisClient.setex(key, dataExpireSeconds, value);
return value;
} else {
if (!alwaysRetry) {
logger.warn("竞争分布式锁失败,key={}", key);
return null;
}
Thread.sleep(100L);
logger.warn("尝试重新获取数据,key={}", key);
}
}
} catch (Exception ex) {
logger.error("getDistributeSafeError", ex);
return null;
} finally {
if (getLockSuccess) {
redisLockManager.unLock(key);
}
}
}
}
四、 分
我们首先看一个概念:读写比。互联网场景中一般是读多写少,例如浏览20次订单列表信息才会进行1次确认收货,此时读写比例就是20:1。面对读多写少这种情况我们可以做什么呢?
我们可以部署多台MySQL读库专门用来接收读请求,主库接收写请求并通过binlog实时同步的方式将数据同步至读库。MySQL官方即提供这种能力,进行简单配置即可。
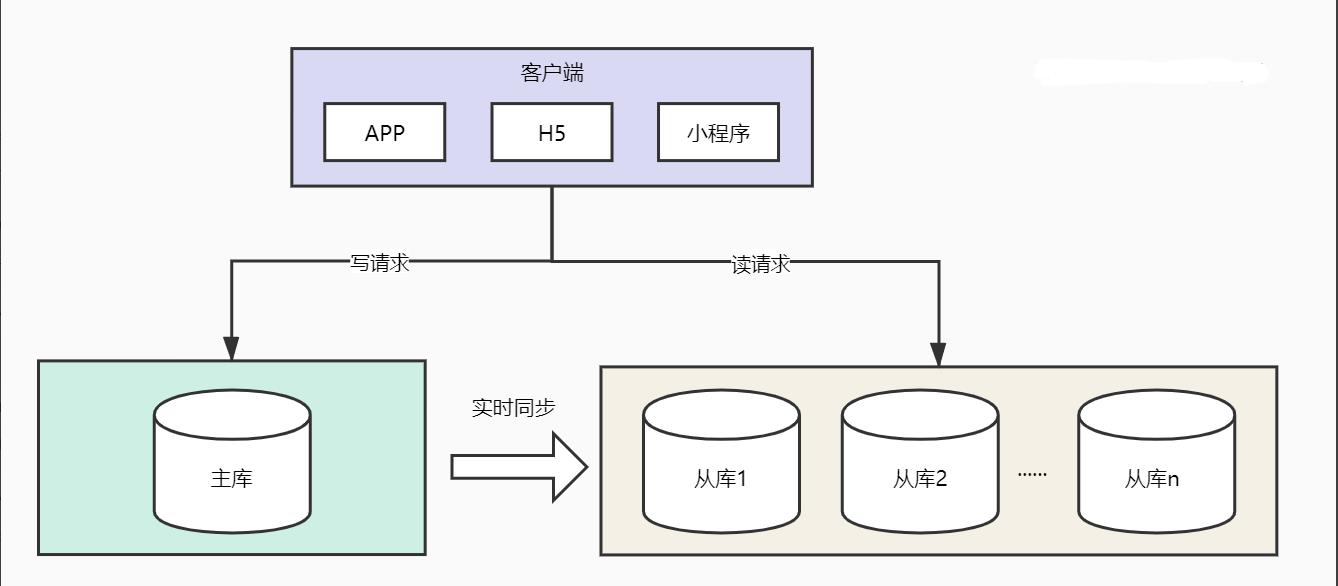
那么客户端怎么知道访问读库还是写库呢?推荐使用ShardingSphere组件,通过配置将读写请求分别路由至读库或者写库。
五、拆
如果删除了历史数据并采用了其它存储介质,也用了读写分离,但是单表压力还是太大怎么办?这时我们只能拆分数据表,即把单库单表数据迁移到多库多张表中。
假设有一个电商数据库存放订单、商品、支付三张业务表。随着业务量越来越大,这三张业务数据表也越来越大,我们就以这个例子进行分析。
5.1 垂直拆分
垂直拆分就是按照业务拆分,我们将电商数据库拆分成三个库,订单库、商品库。支付库,订单表在订单库,商品表在商品库,支付表在支付库。这样每个库只需要存储本业务数据,物理隔离不会互相影响。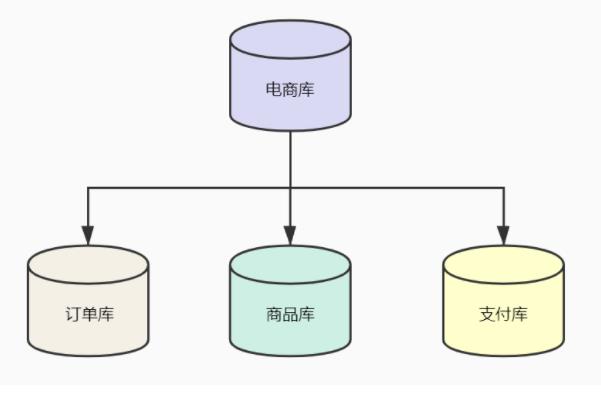
5.2 水平拆分
按照垂直拆分方案,现在我们已经有三个库了,平稳运行了一段时间。但是随着业务增长,每个单库单表的数据量也越来越大,逐渐到达瓶颈。
这时我们就要对数据表进行水平拆分,所谓水平拆分就是根据某种规则将单库单表数据分散到多库多表,从而减小单库单表的压力。
水平拆分策略有很多方案,最重要的一点是选好ShardingKey,也就是按照哪一列进行拆分,怎么分取决于我们访问数据的方式。
5.2.1 范围分片
现在我们要对订单库进行水平拆分,我们选择的ShardingKey是订单创建时间,拆分策略如下:
(1) 拆分为四个数据库,分别存储每个季度的数据
(2) 每个库三张表,分别存储每个月的数据
上述方法优点是对范围查询比较友好,例如我们需要统计第一季度的相关数据,查询条件直接输入时间范围即可。
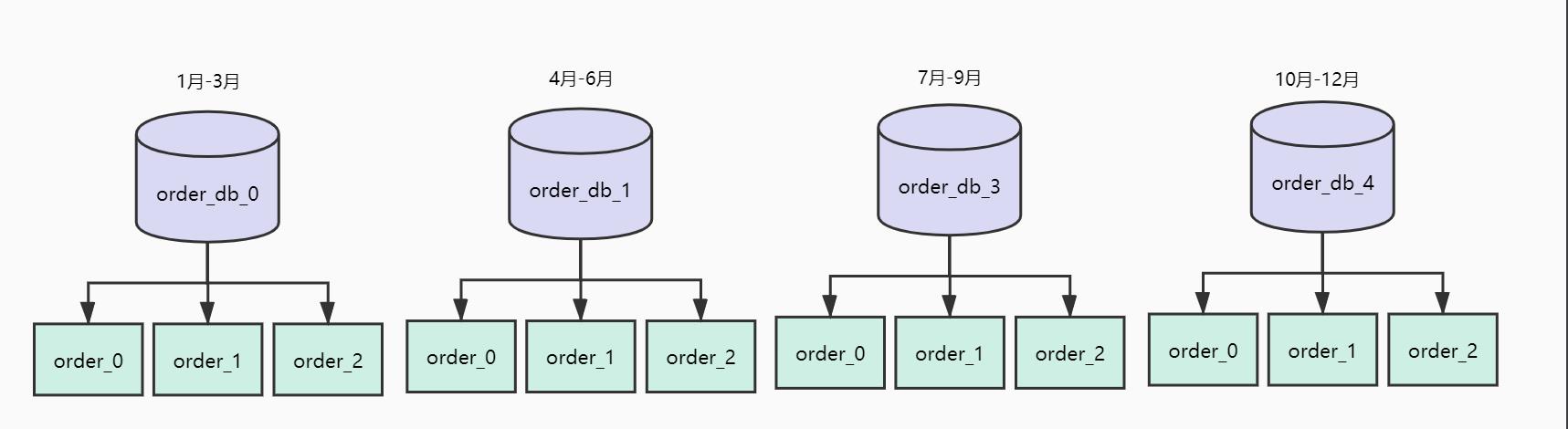
但是这个方案问题是容易产生热点数据。例如双11当天下单量特别大,就会导致11月这张表数据量特别大从而造成访问压力。
5.2.2 查表分片
查表法是根据一张路由表决定ShardingKey路由到哪一张表,每次路由时首先到路由表里查到分片信息,再到这个分片去取数据。
我们分析一个查表法实际案例。Redis官方在3.0版本之后提供了集群方案Redis Cluster,其中引入了哈希槽(slot)这个概念。
一个集群固定有16384个槽,在集群初始化时这些槽会平均分配到Redis集群节点上。每个key请求最终落到哪个槽计算公式是固定的:
SLOT = CRC16(key) mod 16384
那么问题来了:一个key请求过来怎么知道去哪台Redis节点获取数据?这就要用到查表法思想。
(1) 客户端连接任意一台Redis节点,假设随机访问到为节点A
(2) 节点A根据key计算出slot值
(3) 每个节点都维护着slot和节点映射关系表
(4) 如果节点A查表发现该slot在本节点则直接返回数据给客户端
(5) 如果节点A查表发现该slot不在本节点则返回给客户端一个重定向命令,告诉客户端应该去哪个节点上请求这个key的数据
(6) 客户端再向正确节点发起连接请求
查表法优点是可以灵活制定路由策略,如果我们发现有的分片已经成为热点则修改路由策略。缺点是多一次查询路由表操作增加耗时,而且路由表如果是单点也可能会有单点问题。
5.2.3 哈希分片
现在比较流行的分片方法是哈希分片,相较于范围分片,哈希分片可以较为均匀将数据分散在数据库中。
我们现在将订单库拆分为4个库编号为[0,3],每个库4张表编号为[0,3],如下图如所示:
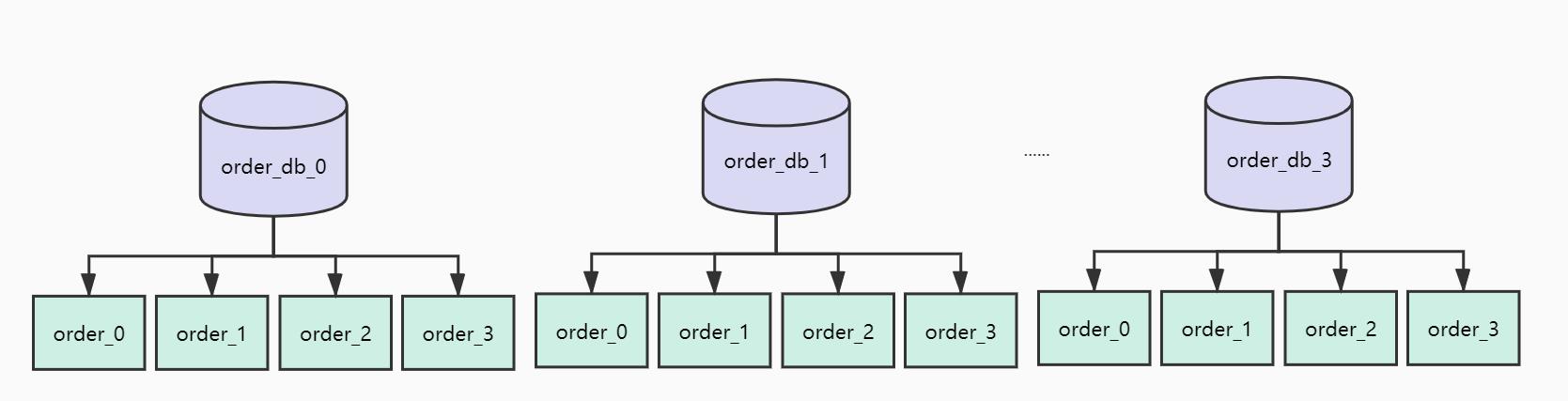
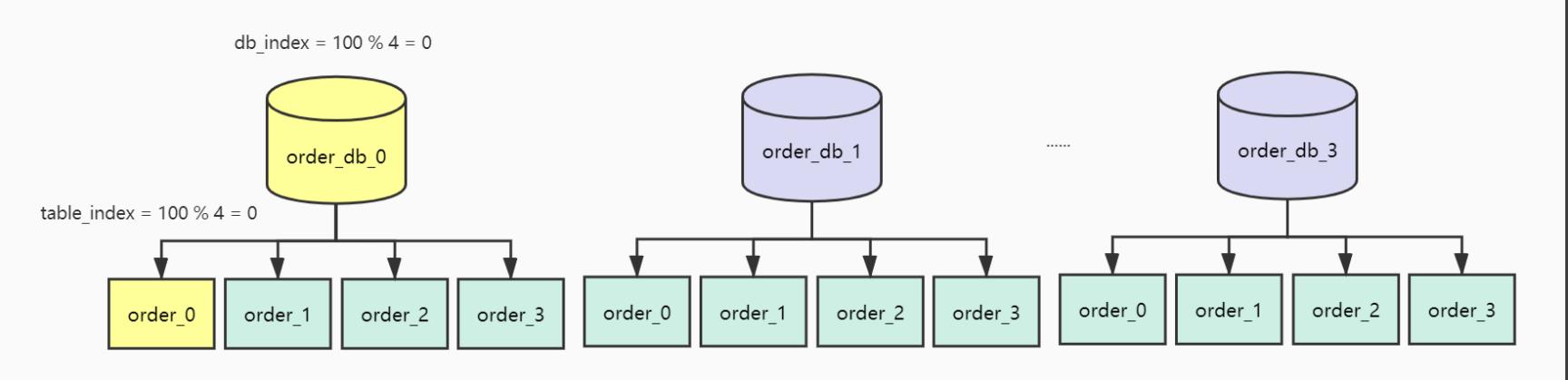
现在使用orderId作为ShardingKey,那么orderId=100的订单会保存在哪张表?我们来计算一下:由于是分库分表,首先确定路由到哪一个库,取模计算得到序号为0表示路由到db[0]
db_index = 100 % 4 = 0
库确定了接着在db[0]进行取模表路由
table_index = 100 % 4 = 0
最终这条数据应该路由至下表
db[0]_table[0]
最终计算结果如下图所示:
在实际开发中最终路由到哪张表,并不需要我们自己算,因为有许多开源框架就可以完成路由功能,例如ShardingSphere、TDDL等等。
六、异
现在数据已经使用哈希分片方法完成了水平拆分,我们选择的ShardingKey是orderId。这时客户端需要查询orderId=111的数据,查询语句很简单如下:
SELECT * FROM order WHERE orderId = 111
这个语句没有问题,因为查询条件包含orderId,可以路由到具体的数据表。
现在如果业务想要查询用户维度的数据,希望查询userId=222的数据,现在问题来了:以下这个语句可以查出数据吗?
SELECT * FROM order WHERE userId = 222
答案是可以,但是需要扫描所有库的所有表,因为无法根据userId路由到具体某一张表,这样时间成本会非常高,这种场景怎么办呢?
这就要用到数据异构的思想。数据异构核心是用空间换时间,简单一句话就是一份数据按照不同业务需求保存多份,这样做是因为存储硬件成本不是很高,而互联网场景对响应速度要求很高。
对于上述需要使用userId进行查询的场景,我们完全可以新建库和表,数量和结构与订单库表完全一致,唯一不同点是ShardingKey改用userId,这样就可以使用userId查询了。
现在又引出一个新问题,业务不可能每次都将数据写入多个数据源,这样会带来性能问题和数据一致行为。怎么解决老库和新库数据同步问题?我们可以使用阿里开源的canal组件解决这个问题,看一张官网介绍canal架构图: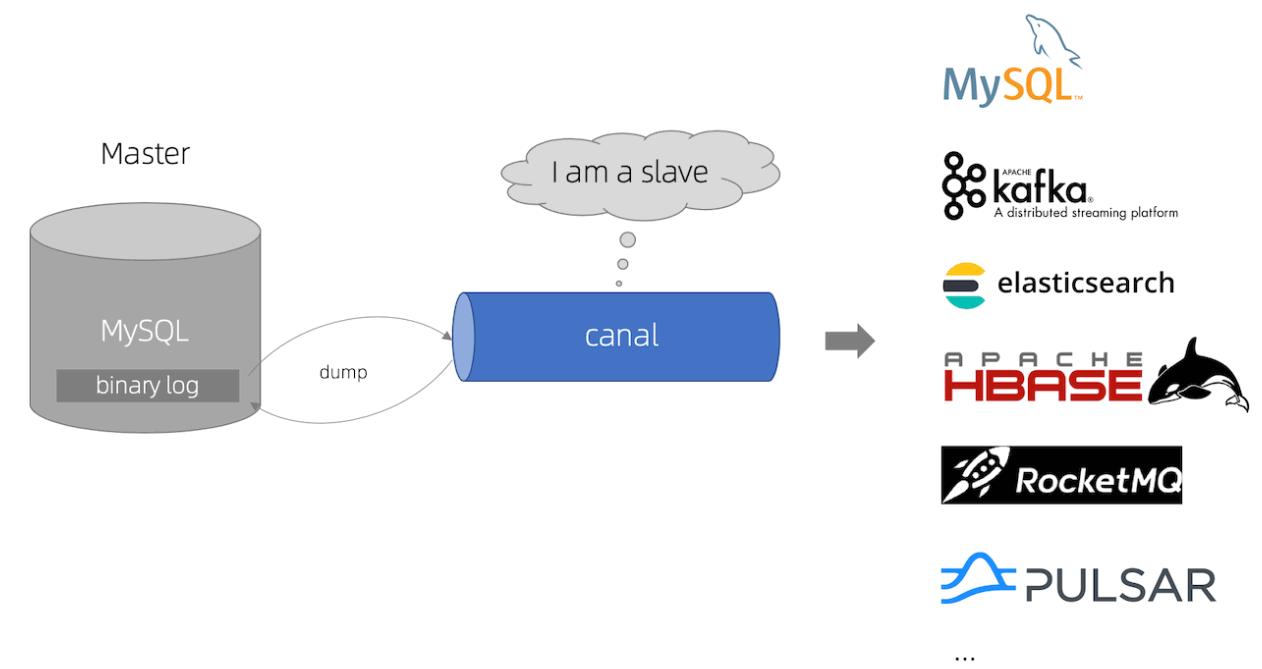
canal组件的主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费服务,工作原理如下:
(1) canal伪装成为MySQL slave模拟交互协议向master发送dump协议
(2) master收到canal发送的dump请求,开始推送binlog给canal
(3) canal解析binlog并发送到存储目的地,例如MySQL、Kafka、Elasticsearch
canal组件下游可以对接很多其它数据源,这样给业务提供了更多选择。我们可以像上述实例中新建用户维度订单表,也可以将数据存在ES中提供运营检索能力等等。
七、热
我们来分析这样一个场景:社交业务有一张用户关系表,主要记录谁关注了谁。其中有一个明星粉丝特别多,如果以userId作为分片,那么其所在分片数据量就会特别大。
不仅分片数据量特别大,而且可以预见这个分片访问频率也会非常高。此时数据量大并且访问频繁,很有可能造成系统压力。
7.1 热点概念
我们将访问行为称为热点行为,将访问对应的数据称为热点数据。我们通过实例来分析。
在电商双11活动中百分之八十的访问量会集中在百分之二十的商品上。用户刷新、添加购物车、下单被称为热点行为,相应商品数据就被称为热点数据。
在微博场景中大V发布一条消息会获得大量访问。用户对这条消息的浏览、点赞、转发、评论被称为热点行为,这条消息数据被称为热点数据。
在秒杀场景中参与秒杀的商品会获得极大的瞬时访问量。用户对这个商品的频繁刷新、点击、下单被称为热点行为,参与秒杀的商品数据被称为热点数据。
我们必须将热点数据进行一些处理,使得热点访问更加流畅,更是为了保护系统免于崩溃。我们从发现热点数据、处理热点数据来展开分析。
7.2 发现热点数据
我们把发现热点数据分为两种方式:静态发现和动态发现。
静态发现:在开始秒杀活动之前,参与商家一定知道哪些商品参与秒杀,那么他们可以提前将这些商品报备告知平台。
在微博场景中,具有影响力的大V一般都很知名,网站运营同学可以提前知道。技术同学还可以通过分析历史数据找出TOP N数据。对于这些可以提前预判的数据,完全可以通过后台系统上报,这样系统可以提前做出预处理。
动态发现:有些商品可能并没有上报为热点商品,但是在实际销售中却非常抢手。在微博场景中,有些话题热度突然升温。这些数据成为事实上的热点数据。对于这些无法提前预判的数据,需要动态进行判断。
我们需要一个热点发现系统去主动发现热点数据。大体思路是首先异步收集访问日志,再统计单位时间内访问频次,当超过一定阈值时可以判断为热点数据。
7.3 处理热点问题
(1) 热点行为
热点行为可以采取高频检测方式,如果发现频率过高则进行限制。或者采用内存队列实现的生产者与消费者这种异步化方式,消费者根据能力处理请求。
(2) 热点数据
处理热点数据核心主要是根据业务形态来进行处理,我一般采用以下方案配合执行:
(1) 选择合适ShardingKey进行分库分表
(2) 异构数据至其它适合检索的数据源例如ES
(3) 在MySQL之前设置缓存层
(4) 尽量不在MySQL进行耗时操作(例如聚合)
8 文章总结
本文我们详细介绍处理单表数据量过大的六字口诀:删、换、分、拆、异、热。这并不是意味这每次遇到单表数据量过大情况六种方案全部都要使用,例如拆分数据表成本确实比较高,会带来分布式事务、数据难以聚合等问题,如果不分表可以解决那么就不要分表,核心还是根据自身业务情况选择合适的方案。
以上内容希望可以对大家有所帮助,觉得文章不错的话就一键三连支持一下吧。
以上是关于面试官:单表数据量大一定要分库分表吗?我用6个字和10张图回答的主要内容,如果未能解决你的问题,请参考以下文章