MySql存储引擎和索引原理
Posted xc技术天堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql存储引擎和索引原理相关的知识,希望对你有一定的参考价值。
一.MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此mysql数据库支持多种索引类型,如BTree索引,B+Tree索引,哈希索引,全文索引等等
1.InnoDB存储引擎(mysql主要用这个引擎):
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
特点:支持自动增长列,支持外键约束
2.MyISAM存储引擎:
不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
3.MERGE存储引擎:
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,
对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
4.MEMORY存储引擎:
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的
表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
二.建立索引需要注意:
1.索引需要占用磁盘空间,因此在创建索引时要考虑到磁盘空间是否足够
2.创建索引时需要对表加锁,因此实际操作中需要在业务空闲期间进行
三.常见的不使用的索引的情况:
1..Like的参数以通配符开头时 like '%你好%'
2.在进行条件查询只有对所有索引列使用!= 或 <> 操作符时
3.在进行条件查询只有对所有索引列使用is not null
4.索引列和没有建立索引的列使用or来连接条件
5.CBO计算走索引花费过大的情况
可使用关键字FORCE INDEX来强制使用某个索引
四.索引类型和索引实现方法及其原理:
1.索引类型: 聚集索引(主键索引)
InnoDB存储引擎表是索引组织表,即数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点存放的是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。索引聚集索引可以在B+树索引的叶子节点上直接找到数据。由于定义了数据的逻辑顺序,聚集索引能够特别快的访问针对范围值的查询。
2.索引类型: 辅助索引(唯一索引、普通索引、前缀索引,联合索引等)
对于辅助索引,叶子节点并不包含的是行记录的全部数据。叶子节点除了包含键值之外,每个叶子结点的索引行中还包含了一个书签。这个书签就是相对应行数据的聚集索引键。
辅助索引的存在不会影响数据在聚集索引中的组织,因此每张表可以有多个辅助索引。
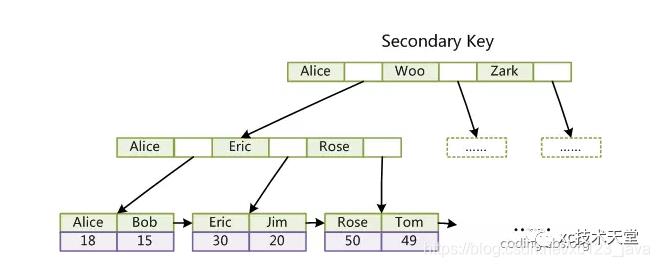
唯一索引: 允许记录为null,记录在表中是唯一的
前缀索引:即只取字符串的前n位来作为节点创建索引,实际上,在按字典序来建立索引结构的时候,通过前面几个字符大概就能确定其位置范围了,然后Mysql会在这个小的范围内遍历出要匹配的条件
联合索引: 就是由多列组成的的索引。遵循最左前缀规则
3.索引类型:全文索引:
仅用于MyISAM和InnoDB,用于大文本字段搜索
针对较大的数据,生成全文索引非常消耗时间和控件,对于文本的大对象,如果使用普通索引,那么匹配文本前几个字符还是可行的,但是要匹配文本中间的几个单词,就要使用like,这样会需要很长的时间来执行
(由于前面是模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫描)
这个时候就需要使用全文索引,再生成全文索引时候,会为文本生成一份单词的清单,在索引时候根据这个单词的清单来索引
全文索引的查询也有自己特殊的语法: select * from test where match(字段名) against('xxx');
4.索引方法: BTree索引
InnoDB引擎主要用这个索引
叶子节点就是没有子节点的节点,非叶子节点就是有子节点的节点
B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B书允许每个节点有更多的子节点。
B树的特点:
①所有键值分布在整个树中
②任何关键字出现且只出现在一个节点中
③搜索有可能在非叶子节点结束
④在关键字全集内做一次查找,性能逼近二分查找算法
为了提升效率,要尽量减少磁盘IO的次数.实际过程中,磁盘并不是每次严格按需读取,而是每次都会预读.磁盘读取完需要的数据后,会按顺序再多读一部分数据到内存中
这样做的理论依据是计算机科学中注明的局部性原理:
①由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
②MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。linux 默认页大小为4K。
所以BTree索引借助计算机磁盘预读机制:每次新建节点的时候,都是申请一个页的空间,所以没查找一个节点只需要一次I/O;因为实际应用当中,节点深度会很少,所以查找效率很高.
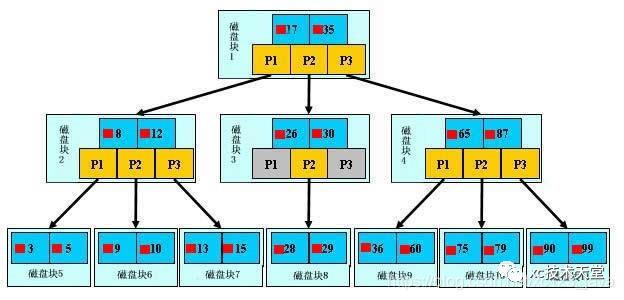
查找数字29的过程:
①B-树示意图如下:
②.B+Tree索引:
从图中也可以看到,B+树与B树的不同在于:
①所有关键字存储在叶子节点,非叶子节点不存储真正的data
②为所有叶子节点增加了一个链指针
为什么mysql的索引使用B+树而不是B树呢?
①B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
②mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。
5.索引方法: 哈希索引:
只有memory(内存)存储引擎支持
哈希索引用索引列的计算该值的hashCode,然后在hashCode相应的位置存执
该值所在行数据的物理位置,因为使用散列算法,所以访问速度非常快,但是一个值只能对应一个hashCode,而且是散列的分布方式,因次哈希索引不支持范围查找和排序的功能
以上是关于MySql存储引擎和索引原理的主要内容,如果未能解决你的问题,请参考以下文章