[Python图像处理] 四十.全网首发Python图像分割万字详解(阈值分割边缘分割纹理分割分水岭算法K-Means分割漫水填充分割区域定位)
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python图像处理] 四十.全网首发Python图像分割万字详解(阈值分割边缘分割纹理分割分水岭算法K-Means分割漫水填充分割区域定位)相关的知识,希望对你有一定的参考价值。
该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。希望文章对您有所帮助,如果有不足之处,还请海涵~
前面一篇文章介绍了图像分类知识,包括常见的图像分类算法,并介绍Python环境下的贝叶斯图像分类算法、基于KNN算法的图像分类和基于神经网络算法的图像分类等案例。这篇文章将详细讲解图像分割知识,包括阈值分割、边缘分割、纹理分割、分水岭算法、K-Means分割、漫水填充分割、区域定位等。万字长文整理,希望对您有所帮助。 同时,该部分知识均为作者查阅资料撰写总结,并且开设成了收费专栏,为小宝赚点奶粉钱,感谢您的抬爱。当然如果您是在读学生或经济拮据,可以私聊我给你每篇文章开白名单,或者转发原文给你,更希望您能进步,一起加油喔~
代码下载地址(如果喜欢记得star,一定喔):
文章目录
前文参考:
- [Python图像处理] 一.图像处理基础知识及OpenCV入门函数
- [Python图像处理] 二.OpenCV+Numpy库读取与修改像素
- [Python图像处理] 三.获取图像属性、兴趣ROI区域及通道处理
- [Python图像处理] 四.图像平滑之均值滤波、方框滤波、高斯滤波及中值滤波
- [Python图像处理] 五.图像融合、加法运算及图像类型转换
- [Python图像处理] 六.图像缩放、图像旋转、图像翻转与图像平移
- [Python图像处理] 七.图像阈值化处理及算法对比
- [Python图像处理] 八.图像腐蚀与图像膨胀
- [Python图像处理] 九.形态学之图像开运算、闭运算、梯度运算
- [Python图像处理] 十.形态学之图像顶帽运算和黑帽运算
- [Python图像处理] 十一.灰度直方图概念及OpenCV绘制直方图
- [Python图像处理] 十二.图像几何变换之图像仿射变换、图像透视变换和图像校正
- [Python图像处理] 十三.基于灰度三维图的图像顶帽运算和黑帽运算
- [Python图像处理] 十四.基于OpenCV和像素处理的图像灰度化处理
- [Python图像处理] 十五.图像的灰度线性变换
- [Python图像处理] 十六.图像的灰度非线性变换之对数变换、伽马变换
- [Python图像处理] 十七.图像锐化与边缘检测之Roberts算子、Prewitt算子、Sobel算子和Laplacian算子
- [Python图像处理] 十八.图像锐化与边缘检测之Scharr算子、Canny算子和LOG算子
- [Python图像处理] 十九.图像分割之基于K-Means聚类的区域分割
- [Python图像处理] 二十.图像量化处理和采样处理及局部马赛克特效
- [Python图像处理] 二十一.图像金字塔之图像向下取样和向上取样
- [Python图像处理] 二十二.Python图像傅里叶变换原理及实现
- [Python图像处理] 二十三.傅里叶变换之高通滤波和低通滤波
- [Python图像处理] 二十四.图像特效处理之毛玻璃、浮雕和油漆特效
- [Python图像处理] 二十五.图像特效处理之素描、怀旧、光照、流年以及滤镜特效
- [Python图像处理] 二十六.图像分类原理及基于KNN、朴素贝叶斯算法的图像分类案例
- [Python图像处理] 二十七.OpenGL入门及绘制基本图形(一)
- [Python图像处理] 二十八.OpenCV快速实现人脸检测及视频中的人脸
- [Python图像处理] 二十九.MoviePy视频编辑库实现抖音短视频剪切合并操作
- [Python图像处理] 三十.图像量化及采样处理万字详细总结(推荐)
- [Python图像处理] 三十一.图像点运算处理两万字详细总结(灰度化处理、阈值化处理)
- [Python图像处理] 三十二.傅里叶变换(图像去噪)与霍夫变换(特征识别)万字详细总结
- [Python图像处理] 三十三.图像各种特效处理及原理万字详解(毛玻璃、浮雕、素描、怀旧、流年、滤镜等)
- [Python图像处理] 三十四.数字图像处理基础与几何图形绘制万字详解(推荐)
- [Python图像处理] 三十五.OpenCV图像处理入门、算数逻辑运算与图像融合(推荐)
- [Python图像处理] 三十六.OpenCV图像几何变换万字详解(平移缩放旋转、镜像仿射透视)
- [Python图像处理] 三十七.OpenCV和Matplotlib绘制直方图万字详解(掩膜直方图、H-S直方图、黑夜白天判断)
- [Python图像处理] 三十八.OpenCV图像增强万字详解(直方图均衡化、局部直方图均衡化、自动色彩均衡化)
- [Python图像处理] 三十九.Python图像分类万字详解(贝叶斯图像分类、KNN图像分类、DNN图像分类)
- [[Python图像处理] 四十.全网首发Python图像分割万字详解(阈值分割、边缘分割、纹理分割、分水岭算法、K-Means分割、漫水填充分割、区域定位)]
图像分割是将图像分成若干具有独特性质的区域并提取感兴趣目标的技术和过程,它是图像处理和图像分析的关键步骤。主要分为基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法和基于特定理论的分割方法。本章节将重点围绕图像处理实例,详细讲解各种图像分割的方法。
一.图像分割概述
图像分割(Image Segmentation)技术是计算机视觉领域的重要研究方向,是图像语义理解和图像识别的重要一环。它是指将图像分割成若干具有相似性质的区域的过程,研究方法包括基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法和基于特定理论的分割方法(含图论、聚类、深度语义等)。该技术广泛应用于场景物体分割、人体背景分割、三维重建、车牌识别、人脸识别、无人驾驶、增强现实等行业。如图1所示,它将鲜花颜色划分为四个层级。

图像分割的目标是根据图像中的物体将图像的像素分类,并提取感兴趣的目标。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像索赋予相同的编号。
图像分割是图像识别和计算机视觉至关重要的预处理,没有正确的分割就不可能有正确的识别。图像分割主要依据图像中像素的亮度及颜色,但计算机在自动处理分割时,会遇到各种困难,如光照不均匀、噪声影响、图像中存在不清晰的部分以及阴影等,常常发生图像分割错误。同时,随着深度学习和神经网络的发展,基于深度学习和神经网络的图像分割技术有效提高了分割的准确率,能够较好地解决图像中噪声和不均匀问题。
二.基于阈值的图像分割
最常用的图像分割方法是将图像灰度分为不同的等级,然后用设置灰度门限的方法确定有意义的区域或欲分割的物体边界。图像阈值化(Binarization)旨在剔除掉图像中一些低于或高于一定值的像素,从而提取图像中的物体,将图像的背景和噪声区分开来。图像阈值化可以理解为一个简单的图像分割操作,阈值又称为临界值,它的目的是确定出一个范围,然后这个范围内的像素点使用同一种方法处理,而阈值之外的部分则使用另一种处理方法或保持原样。
阈值化处理可以将图像中的像素划分为两类颜色,常见的阈值化算法如公式(1)所示。
- 当某个像素点的灰度Gray(i,j)小于阈值T时,其像素设置为0,表示黑色;
- 当灰度Gray(i,j)大于或等于阈值T时,其像素值为255,表示白色。
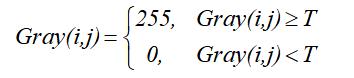
在Python的OpenCV库中,提供了固定阈值化函数threshold()和自适应阈值化函数adaptiveThreshold(),将一幅图像进行阈值化处理,前文7.5小节详细介绍了图像阈值化处理方法,下面代码对比了不同阈值化算法的图像分割结果。
# -*- coding: utf-8 -*-
# 2021-05-17 Eastmount CSDN
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图像
img=cv2.imread('scenery.png')
grayImage=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#阈值化处理
ret,thresh1=cv2.threshold(grayImage,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(grayImage,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(grayImage,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(grayImage,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(grayImage,127,255,cv2.THRESH_TOZERO_INV)
#显示结果
titles = ['Gray Image','BINARY','BINARY_INV','TRUNC',
'TOZERO','TOZERO_INV']
images = [grayImage, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
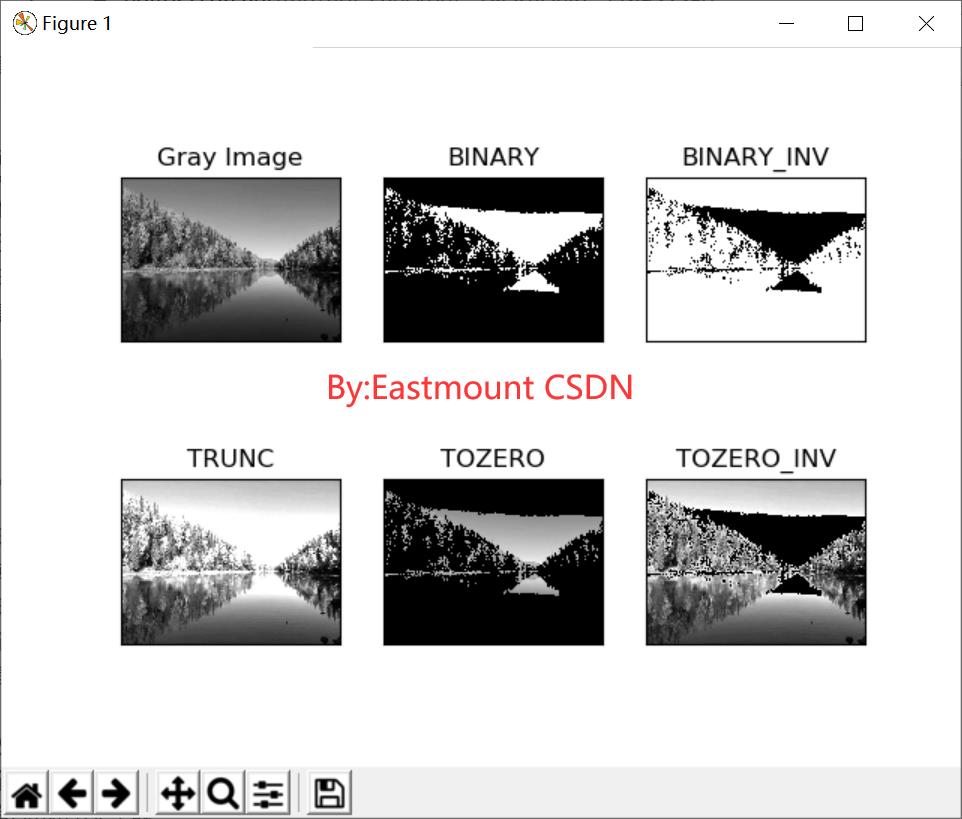
输出结果如图2所示,它将彩色风景图像转换成五种对应的阈值处理效果,包括二进制阈值化(BINARY)、反二进制阈值化(BINARY_INV)、截断阈值化(THRESH_TRUNC)、阈值化为0(THRESH_TOZERO)、反阈值化为0(THRESH_TOZERO_INV)。
三.基于边缘检测的图像分割
图像中相邻区域之间的像素集合共同构成了图像的边缘。基于边缘检测的图像分割方法是通过确定图像中的边缘轮廓像素,然后将这些像素连接起来构建区域边界的过程。由于沿着图像边缘走向的像素值变化比较平缓,而沿着垂直于边缘走向的像素值变化比较大,根据该特点,通常会采用一阶导数和二阶导数来描述和检测边缘。
在下一篇文章中,我们将详细讲解了Python边缘检测的方法,下面的代码先对比常用的微分算子,如Roberts、Prewitt、Sobel、Laplacian、Scharr、Canny、LOG等算子。
# -*- coding: utf-8 -*-
# 2021-05-17 Eastmount CSDN
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图像
img = cv2.imread('scenery.png')
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#灰度化处理图像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#阈值处理
ret, binary = cv2.threshold(grayImage, 127, 255, cv2.THRESH_BINARY)
#Roberts算子
kernelx = np.array([[-1,0],[0,1]], dtype=int)
kernely = np.array([[0,-1],[1,0]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Roberts = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Prewitt算子
kernelx = np.array([[1,1,1],[0,0,0],[-1,-1,-1]], dtype=int)
kernely = np.array([[-1,0,1],[-1,0,1],[-1,0,1]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(absX,0.5,absY,0.5,0)
#Sobel算子
x = cv2.Sobel(binary, cv2.CV_16S, 1, 0)
y = cv2.Sobel(binary, cv2.CV_16S, 0, 1)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#拉普拉斯算法
dst = cv2.Laplacian(binary, cv2.CV_16S, ksize = 3)
Laplacian = cv2.convertScaleAbs(dst)
# Scharr算子
x = cv2.Scharr(binary, cv2.CV_32F, 1, 0) #X方向
y = cv2.Scharr(binary, cv2.CV_32F, 0, 1) #Y方向
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Scharr = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Canny算子
gaussianBlur = cv2.GaussianBlur(binary, (3,3), 0) #高斯滤波
Canny = cv2.Canny(gaussianBlur , 50, 150)
#LOG算子
gaussianBlur = cv2.GaussianBlur(binary, (3,3), 0) #高斯滤波
dst = cv2.Laplacian(gaussianBlur, cv2.CV_16S, ksize = 3)
LOG = cv2.convertScaleAbs(dst)
#效果图
titles = ['Source Image', 'Binary Image', 'Roberts Image',
'Prewitt Image','Sobel Image', 'Laplacian Image',
'Scharr Image', 'Canny Image', 'LOG Image']
images = [rgb_img, binary, Roberts, Prewitt,
Sobel, Laplacian, Scharr, Canny, LOG]
for i in np.arange(9):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
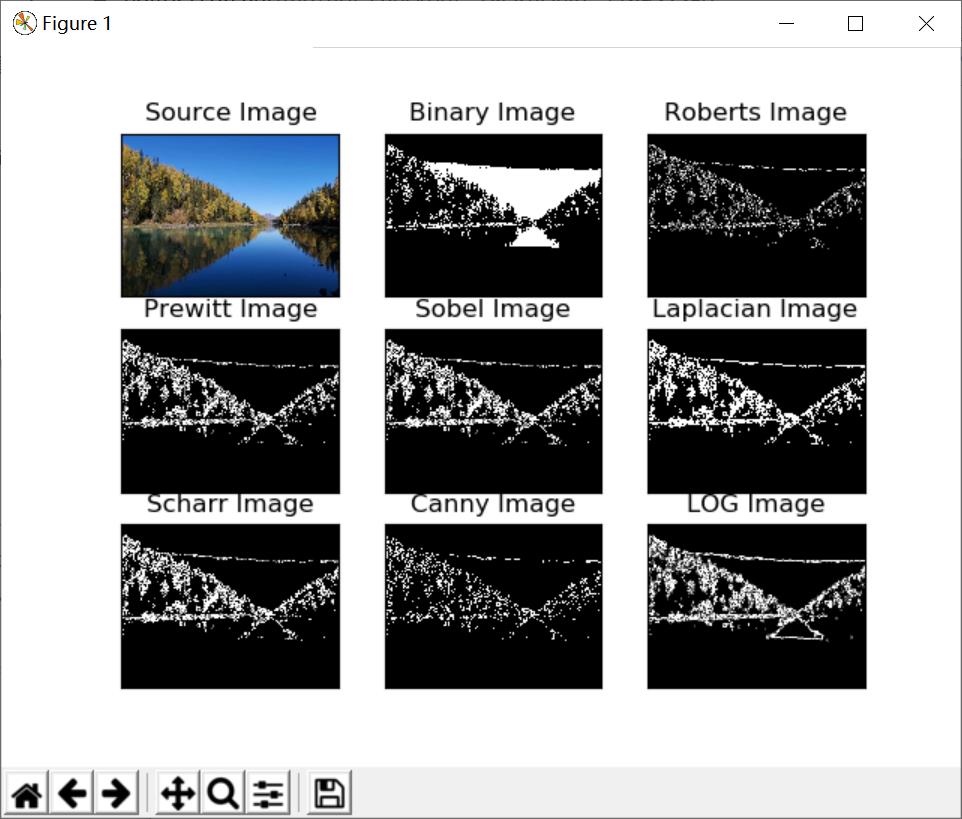
输出结果如图3所示,它依次为原始图像、二值化图像、Roberts算子分割图、Prewitt算子分割图、Sobel算子分割图、Laplacian算子分割图、Scharr算子分割图、Canny算子分割图和LOG算子分割图。
下面讲解另一种边缘检测的方法。在OpenCV中,可以通过cv2.findContours()函数从二值图像中寻找轮廓,其函数原型如下所示:
- image, contours, hierarchy = findContours(image, mode, method[, contours[, hierarchy[, offset]]])
– image表示输入图像,即用于寻找轮廓的图像,为8位单通道
– contours表示检测到的轮廓,其函数运行后的结果存在该变量中,每个轮廓存储为一个点向量
– hierarchy表示输出变量,包含图像的拓扑信息,作为轮廓数量的表示,它包含了许多元素,每个轮廓contours[i]对应4个hierarchy元素hierarchy[i][0]至hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号
– mode表示轮廓检索模式。cv2.RETR_EXTERNAL表示只检测外轮廓;cv2.RETR_LIST表示提取所有轮廓,且检测的轮廓不建立等级关系;cv2.RETR_CCOMP提取所有轮廓,并建立两个等级的轮廓,上面的一层为外边界,里面一层为内孔的边界信;cv2.RETR_TREE表示提取所有轮廓,并且建立一个等级树或网状结构的轮廓
– method表示轮廓的近似方法。cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2), abs(y1-y2))=1;cv2.CHAIN_APPROX_SIMPLE压缩水平方向、垂直方向、对角线方向的元素,只保留该方向的终点坐标,例如一个矩阵轮廓只需4个点来保存轮廓信息; cv2.CHAIN_APPROX_TC89_L1和cv2.CHAIN_APPROX_TC89_KCOS使用Teh-Chinl Chain近似算法
– offset表示每个轮廓点的可选偏移量
在使用findContours()函数检测图像边缘轮廓后,通常需要和drawContours()函数联合使用,接着绘制检测到的轮廓,drawContours()函数的原型如下:
- image = drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]])
– image表示目标图像,即所要绘制轮廓的背景图片
– contours表示所有的输入轮廓,每个轮廓存储为一个点向量
– contourldx表示轮廓绘制的指示变量,如果为负数表示绘制所有轮廓
– color表示绘制轮廓的颜色
– thickness表里绘制轮廓线条的粗细程度,默认值为1
– lineType表示线条类型,默认值为8,可选线包括8(8连通线型)、4(4连通线型)、CV_AA(抗锯齿线型)
– hierarchy表示可选的层次结构信息
– maxLevel表示用于绘制轮廓的最大等级,默认值为INT_MAX
– offset表示每个轮廓点的可选偏移量
下面的代码是使用cv2.findContours()检测图像轮廓,并调用cv2.drawContours()函数绘制出轮廓线条。
# -*- coding: utf-8 -*-
# 2021-05-17 Eastmount CSDN
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图像
img = cv2.imread('scenery.png')
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#灰度化处理图像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#阈值化处理
ret, binary = cv2.threshold(grayImage, 0, 255,
cv2.THRESH_BINARY+cv2.THRESH_OTSU)
#边缘检测
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)
#轮廓绘制
cv2.drawContours(img, contours, -1, (0, 255, 0), 1)
#显示图像5
cv2.imshow('gray', binary)
cv2.imshow('res', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
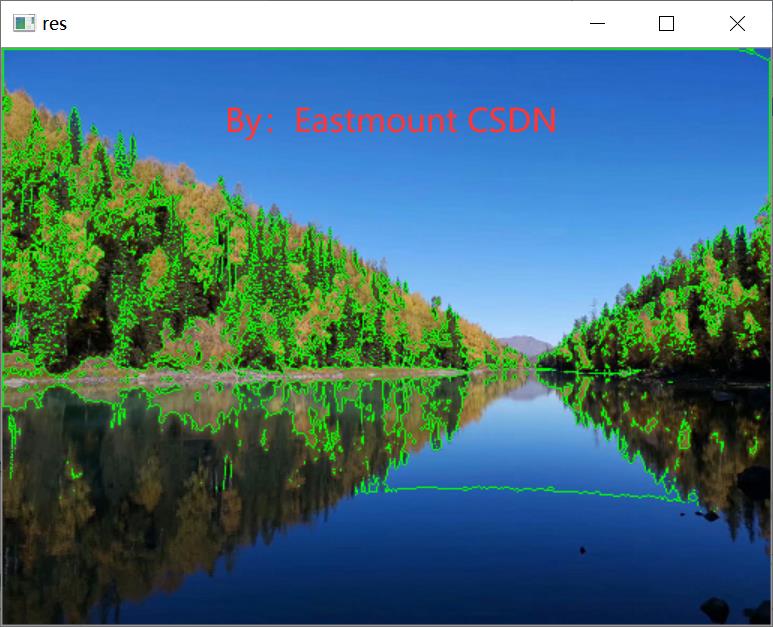
图4为图像阈值化处理效果图。

图5为最终提取的风景图的边缘线条。
四.基于纹理背景的图像分割
该小节主要讲解基于图像纹理信息(颜色)、边界信息(反差)和背景信息的图像分割算法。在OpenCV中,GrabCut算法能够有效地利用纹理信息和边界信息分割背景,提取图像目标物体。该算法是微软研究院基于图像分割和抠图的课题,它能有效地将目标图像分割提取,如图6所示。

GrabCut算法原型如下所示:
- mask, bgdModel, fgdModel = grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode])
– image表示输入图像,为8位三通道图像
– mask表示蒙板图像,输入/输出的8位单通道掩码,确定前景区域、背景区域、不确定区域。当模式设置为GC_INIT_WITH_RECT时,该掩码由函数初始化
– rect表示前景对象的矩形坐标,其基本格式为(x, y, w, h),分别为左上角坐标和宽度、高度
– bdgModel表示后台模型使用的数组,通常设置为大小为(1, 65)np.float64的数组
– fgdModel表示前台模型使用的数组,通常设置为大小为(1, 65)np.float64的数组
– iterCount表示算法运行的迭代次数
– mode是cv::GrabCutModes操作模式之一,cv2.GC_INIT_WITH_RECT 或 cv2.GC_INIT_WITH_MASK表示使用矩阵模式或蒙板模式
下面是Python的实现代码,通过调用np.zeros()函数创建掩码、fgbModel和bgModel,接着定义rect矩形范围,调用函数grabCut()实现图像分割。由于该方法会修改掩码,像素会被标记为不同的标志来指明它们是背景或前景。接着将所有的0像素和2像素点赋值为0(背景),而所有的1像素和3像素点赋值为1(前景),完整代码如下所示。
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
#读取图像
img = cv2.imread('nv.png')
#灰度化处理图像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#设置掩码、fgbModel、bgModel
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1,65), np.float64)
fgdModel = np.zeros((1,65), np.float64)
#矩形坐标
rect = (100, 100, 500, 800)
#图像分割
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5,
cv2.GC_INIT_WITH_RECT)
#设置新掩码:0和2做背景
mask2 = np.where((mask==2)|(mask==0), 0, 1).astype('uint8')
#设置字体
matplotlib.rcParams['font.sans-serif']=['SimHei']
#显示原图
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.subplot(1,2,1)
plt.imshow(img)
plt.title(u'(a)原始图像')
plt.xticks([]), plt.yticks([])
#使用蒙板来获取前景区域
img = img*mask2[:, :, np.newaxis]
plt.subplot(1,2,2)
plt.imshow(img)
plt.title(u'(b)目标图像')
plt.colorbar()
plt.xticks([]), plt.yticks([])
plt.show()
输出图像如图7所示,图7(a)为原始图像,图7(b)为图像分割后提取的目标人物,但人物右部分的背景仍然存在。如何移除这些背景呢?这里需要使用自定义的掩码进行提取,读取一张灰色背景轮廓图,从而分离背景与前景,希望读者下来实现该功能。
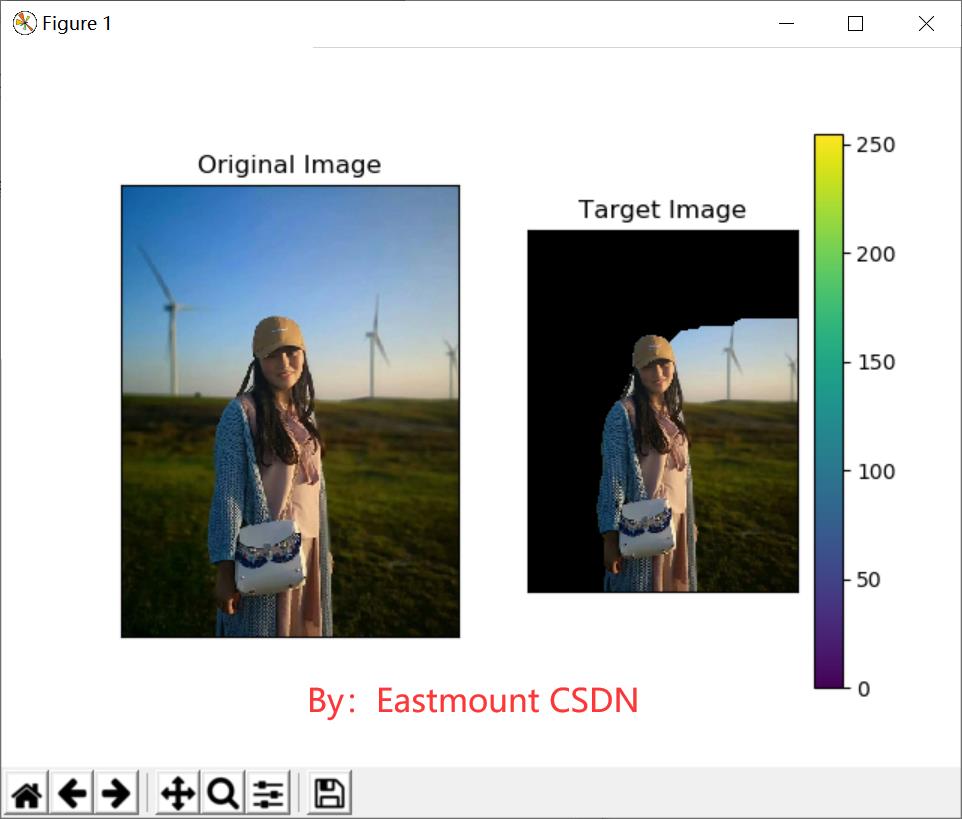
五.基于K-Means聚类的区域分割
K-Means聚类是最常用的聚类算法,最初起源于信号处理,其目标是将数据点划分为K个类簇,找到每个簇的中心并使其度量最小化。该算法的最大优点是简单、便于理解,运算速度较快,缺点是只能应用于连续型数据,并且要在聚类前指定聚集的类簇数。
下面是K-Means聚类算法的分析流程,步骤如下:
- 第一步,确定K值,即将数据集聚集成K个类簇或小组;
- 第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心;
- 第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心;
- 第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心;
- 第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止;
- 第六步,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。
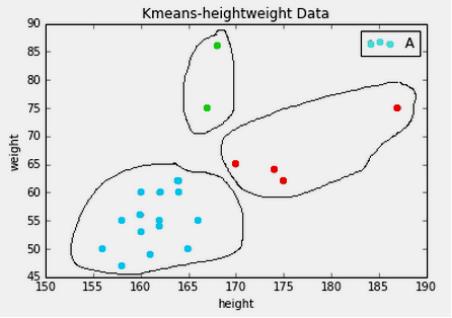
图8是对身高和体重进行聚类的算法,将数据集的人群聚集成三类。
在图像处理中,通过K-Means聚类算法可以实现图像分割、图像聚类、图像识别等操作,本小节主要用来进行图像颜色分割。假设存在一张100×100像素的灰度图像,它由10000个RGB灰度级组成,我们通过K-Means可以将这些像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有的像素点,这样就能实现在不改变分辨率的情况下量化压缩图像颜色,实现图像颜色层级分割。
在OpenCV中,Kmeans()函数原型如下所示:
- retval, bestLabels, centers = kmeans(data, K, bestLabels, criteria, attempts, flags[, centers])
– data表示聚类数据,最好是np.flloat32类型的N维点集
– K表示聚类类簇数
– bestLabels表示输出的整数数组,用于存储每个样本的聚类标签索引
– criteria表示算法终止条件,即最大迭代次数或所需精度。在某些迭代中,一旦每个簇中心的移动小于criteria.epsilon,算法就会停止
– attempts表示重复试验kmeans算法的次数,算法返回产生最佳紧凑性的标签
– flags表示初始中心的选择,两种方法是cv2.KMEANS_PP_CENTERS ;和cv2.KMEANS_RANDOM_CENTERS
– centers表示集群中心的输出矩阵,每个集群中心为一行数据
下面使用该方法对灰度图像颜色进行分割处理,需要注意,在进行K-Means聚类操作之前,需要将RGB像素点转换为一维的数组,再将各形式的颜色聚集在一起,形成最终的颜色分割。
# coding: utf-8
# 2021-05-17 Eastmount CSDN
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像灰度颜色
img = cv2.imread('scenery.png', 0)
print(img.shape)
#获取图像高度、宽度和深度
rows, cols = img.shape[:]
#图像二维像素转换为一维
data = img.reshape((rows * cols, 1))
data = np.float32(data)
#定义中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_C以上是关于[Python图像处理] 四十.全网首发Python图像分割万字详解(阈值分割边缘分割纹理分割分水岭算法K-Means分割漫水填充分割区域定位)的主要内容,如果未能解决你的问题,请参考以下文章