超详细的 Python 方法函数总结
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细的 Python 方法函数总结相关的知识,希望对你有一定的参考价值。
目录
- 阅读前必读(不看会错过一个亿)
- 一、字符串操作
- 1.1 capitalize() 方法——字符串首字母转换为大写
- 1.2 casefold() 方法——所有大写字符转换为小写
- 1.3 center() 方法——字符串居中填充
- 1.4 count() 方法——统计字符串出现次数
- 1.5 encode() 方法——编码字符串
- 1.6 decode() 方法——解码字符串
- 1.7 endswith() 方法——是否以指定子字符串结尾、startswith() 方法
- 1.8 find() 方法——字符串首次出现的索引位置(rfind()、index()、rindex())
- 1.9 format() 方法——格式化字符串
- 1.10 f-string ——格式化字符串
- 1.11 字符串的判断方法 isalnum()、isalpha()、isdecimal()、isdigit()、isidentifier()、islower()、isnumeric()、isprintable()、isspace()、istitle()、isupper()
- 1.12 join() 方法——连接字符串、元组、列表和字典
- 1.13 len() 函数——计算字符串长度或元素个数
- 1.14 ljust() 方法——字符串左对齐填充、rjust()方法——字符串右对齐填充
- 1.15 大小写转换方法 lower()、swapcase()、title()、upper()
- 1.16 lstrip() 方法——截掉字符串左边的空格或指定的字符
- 1.17 partition()方法——分割字符串为元组
- 1.18 replace() 方法——替换字符串
- 1.19 split() 方法——分割字符串
- 1.20 strip() 方法——去除字符串头尾特殊字符
- 1.21 zfill() 方法——字符串前面填充
- 二、列表
- 2.1 [] --直接创建列表
- 2.2 append() 方法--添加列表元素
- 2.3 clear() 方法--删除列表中的所有元素
- 2.4 copy() 方法--复制列表中所有元素
- 2.5 count() 方法--获取指定元素出现的次数
- 2.6 enumerate() 函数--遍历列表
- 2.7 extend() 方法--将序列的全部元素添加到另一列表中
- 2.8 index() 方法--获取指定元素首次出现的索引
- 2.9 insert() 方法--向列表的指定位置插入元素
- 2.10 not in --查找列表元素是否不存在
- 2.11 pop()方法--删除列表中的元素
- 2.12 remove() 方法--删除列表中的指定元素
- 2.13 reverse() 方法--反转列表中的所有元素
- 2.14 sort() 方法--排序列表元素
- 2.15 sorted() 函数--排序列表元素
- 2.16 sum() 函数--统计数值列表的元素和
- 2.17 print() 函数--输出列表内容
- 2.18 list() 函数--创建列表
- 三、元组
- 四、字典
- 4.1 {} --直接创建字典
- 4.2 clear() 方法--删除字典中的全部元素
- 4.3 copy() 方法--浅复制一个字典
- 4.4 del 关键字--删除字典或字典中指定的键
- 4.5 dict() 函数--创建字典
- 4.6 fromkeys() 方法--创建一个新字典
- 4.7 get() 方法--获取字典中指定键的值
- 4.8 items() 方法--获取字典的所有"键值对"
- 4.9 key in dict --判断指定键是否存在于字典中
- 4.10 keys() 方法--获取字典的所有键
- 4.11 pop() 方法--删除字典中指定键对应的键值对并返回被删除的值
- 4.12 popitem() 方法 --返回并删除字典中的键值对
- 4.13 setdefault() 方法--获取字典中指定键的值
- 4.14 update() 方法--更新字典
- 4.15 values() 方法--获取字典的所有值
- 五、集合
阅读前必读(不看会错过一个亿)
一、字符串操作
Chapter Three : Python 序列之字符串操作详解
1.1 capitalize() 方法——字符串首字母转换为大写
capitalize() 方法用于将字符串的首字母转换为大写,其他字母为小写。capitalize() 方法的语法格式如下:
def capitalize(self, *args, **kwargs):
"""
Return a capitalized version of the string.
More specifically, make the first character have upper case and the rest lower case.
"""
pass
⇒ str.capitalize()
【示例1】将字符串的首字母转换为大写。

【示例2】字符串全是大写字母只保留首字母大写。
cn = '没什么是你能做却办不到的事。'
en = "THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE."
print(cn)
print('原字符串:', en)
# 字符串转换为小写后首字母大写
print('转换后:', en.lower().capitalize())
运行程序,输出结果为:
没什么是你能做却办不到的事。
原字符串: THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE.
转换后: There's nothing you can do that can't be done.
【示例3】对指定位置字符串的首字母大写。
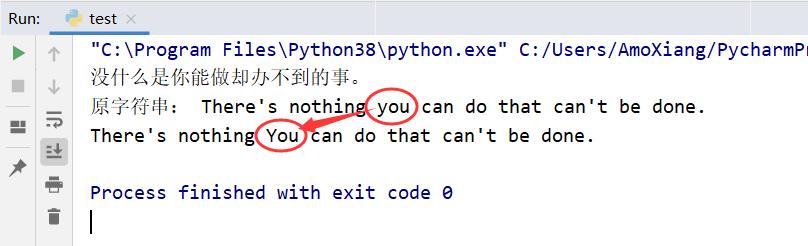
cn = '没什么是你能做却办不到的事。'
en = "There's nothing you can do that can't be done."
print(cn)
print('原字符串:', en)
# 对指定位置字符串转换为首字母大写
print(en[0:16] + en[16:].capitalize())
运行程序,输出结果为:
1.2 casefold() 方法——所有大写字符转换为小写
casefold() 方法是 Python3.3 版本之后引入的,其效果和 lower() 方法非常相似,都可以转换字符串中所有大写字符为小写。两者的区别是:lower() 方法只对 ASCII 编码,也就是 A-Z 有效,而 casefold() 方法对所有大写(包括非中英文的其他语言)都可以转换为小写。casefold() 方法的语法格式如下:
def casefold(self, *args, **kwargs): # real signature unknown
""" Return a version of the string suitable for caseless comparisons. """
pass
⇒ str.casefold()
⇒ 返回将字符串中所有大写字符转换为小写后生成的字符串。
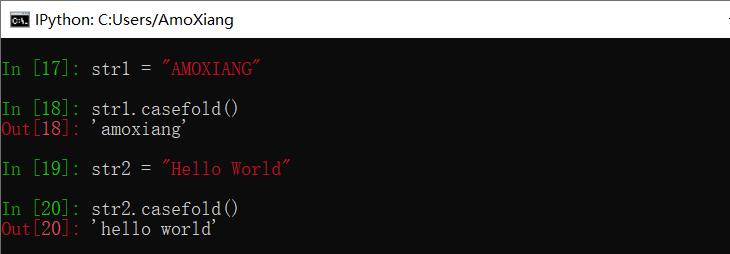
【示例1】将字符串中的大写字母转换为小写。
【示例2】对非中英文的其他语言字符串中的大写转换为小写。
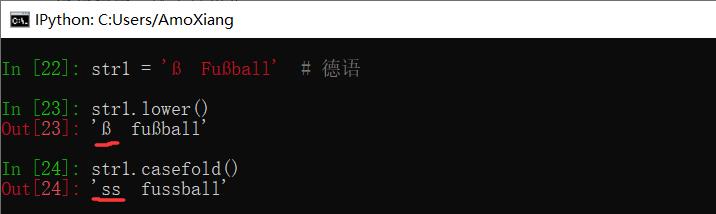
从以上结果看:lower() 方法没有进行转换,而 casefold() 方法将 ß 转换为小写字母 ss。因此,在对非中英文的其他语言字符串中的大写转换为小写时,应使用 casefold() 方法。
【示例3】判断英文短句是否为“回文”。首先科普下“回文”。在中文中,相同的词汇或句子调换位置或颠倒过来,产生首尾回环的情趣,叫做回文。例如,“客上天然居,居然天上客”;心清可品茶,茶品可清心。而在英语中,回文是一种英语修辞手法。英语中最著名的一个回文,是拿破仑被流放到Elba岛时说的一句话:Able was I ere I saw Elba(在我看到Elba岛之前,我曾所向无敌),这句话不论是从左向右看,还是从右向左看,内容都一样。下面我们就用Python来检测一下,首先需要将英文统一转换为小写,然后再进行判断,否则会影响判断结果。代码如下:
cn = '在我看到Elba岛之前,我曾所向无敌'
en = 'Able was I ere I saw Elba'
# 转换为小写
en = en.casefold()
# 反转字符串
rev_en = reversed(en)
print(cn)
print(en)
print(list(en))
print(list(reversed(en)))
# 判断字符串是否为“回文”
if list(en) == list(rev_en):
print('此句是回文!')
else:
print('此句不是回文!')
【示例4】判断小写字母在所在字符串中出现的次数。
import string
# 26个小写英文字母
chars = string.ascii_lowercase
print('26个小写英文字母:', chars)
test_str = 'AmoXiang is SO cool'
print('原字符串:', test_str)
test_str = test_str.casefold()
c = {}.fromkeys(chars, 0)
# 统计小写字母出现的次数
for char in test_str:
if char in c:
c[char] += 1
print(c)
1.3 center() 方法——字符串居中填充
字符串对象的 center() 方法用于将字符串填充至指定长度,并将原字符串居中输出。center() 方法的语法格式如下:
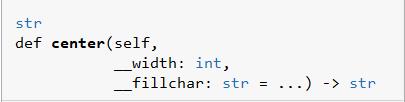
width:参数表示要扩充的长度,即新字符串的总长度。
fillchar:参数表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
【示例1】填充指定的字符串。
print('四川大学'.center(10)) # 长度为10,不指定填充字符,前后各填充3个空格
print('四川大学'.center(6, '-')) # 长度为6,指定填充字符,前后各填充一个'-'字符
print('四川大学'.center(5, '-')) # 长度为5,只在字符串前填充一个'-'字符
print('四川大学'.center(12, '-')) # 长度为12,字符串前后各填充4个'-'字符
print('四川大学'.center(3, '-')) # 长度为3,不足原字符串长度,输出原字符串
运行程序,输出结果为:
四川大学
-四川大学-
-四川大学
----四川大学----
四川大学
【示例2】文本按照顺序显示并且居中对齐。下面输出《中国诗词大会》中的经典诗词《锦瑟》,代码如下。
str1 = ['锦瑟',
'李商隐',
'锦瑟无端五十弦',
'一弦一柱思华年',
'庄生晓梦迷蝴蝶',
'望帝春心托杜鹃',
'沧海月明珠有泪',
'蓝田日暖玉生烟',
'此情可待成追忆',
'只是当时已惘然']
for str1_s in str1:
print('||%s||' % str1_s.center(11, ' '))
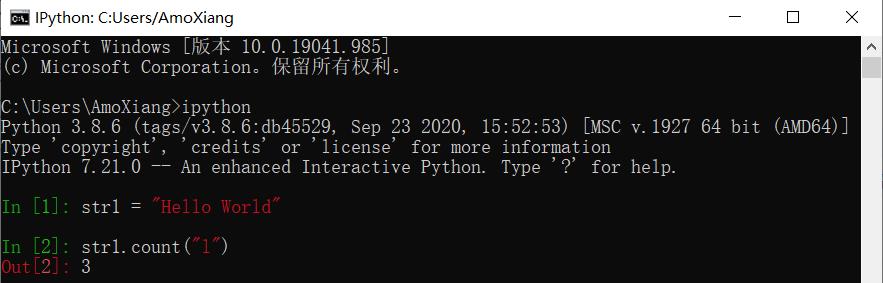
1.4 count() 方法——统计字符串出现次数
count() 方法用于统计字符串中某个字符出现的次数,如起始位置从 11 到结束位置 17 之间字符出现的次数,如下图所示。

count() 方法的语法格式如下:
str.count(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,默认为第一个字符,索引值为 0,可单独指定。
- end:可选参数,表示检索范围的结束位置的索引,默认为字符串的最后一个位置,不可以单独指定。
例如,子字符串 o 在字符串 www.mingrisoft.com 起始位置从 11 到结束位置 17 之间中出现的次数,如下图所示:

注意:这里要注意一点,结束位置为17,但是统计字符个数时不包含17这个位置上的字符。例如结束位置为 16,那么o出现的次数为1。
【示例1】
【示例2】统计关键词在字符串中不同位置处出现的次数。
en = "There's nothing you can do that can't be done."
# 字母"o"在不同位置处出现的次数
print(en.count('o', 0, 17)) # 1
print(en.count('o', 0, 27)) # 3
print(en.count('o', 0, 47)) # 4
【示例3】统计字符串中的标点符号。首先通过 string 模块的 punctuation 常量获取所有标点符号,然后判断字典中每个字符是否为标点符号,如果是标点符号则使用 count() 方法进行统计,最后汇总,代码如下:
import string
count = 0
test_str = "https://blog.csdn.net/xw1680%$&,*,@!"
# 将输入的字符串创建一个新字典
c = {}.fromkeys(test_str, 0)
for keys, values in c.items():
if keys in string.punctuation: # 统计标点符号
count = test_str.count(keys) + count
# 字符串中包含: 14 个标点符号
print('字符串中包含:', count, '个标点符号')
【示例4】统计文本中数字出现的个数。下面统计文本文件中数字出现的个数,如图所示。

示例代码:
import string
f = open('./digits.txt', 'r')
chars = f.read()
count = 0
# 将输入的字符串创建一个新字典
c = {}.fromkeys(chars, 0)
for keys, values in c.items():
if keys in string.digits: # 统计数字
count = chars.count(keys) + count
print('文本中包含:', count, '个数字') # 14
1.5 encode() 方法——编码字符串
编码是将文本(字符串)转换成字节流,Unicode 格式转换成其他编码格式。在 Python 中提供了 encode() 方法,该方法的作用是将 Unicode 编码转换成其他编码的字符串,如下图所示。如 str1.encode(‘gbk’),表示将 Unicode 编码的字符串 str1 转换成 GBK 编码。
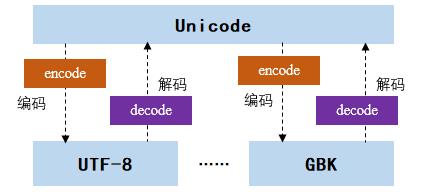
encode() 方法的语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
参数说明:
- str:表示要进行转换的字符串。
- encoding=“utf-8”:可选参数,用于指定进行转码时采用的编码,默认为 utf-8,如果想使用简体中文可以设置为 gbk 或 gb2312(与网站使用的编码方式有关)。当只有一个参数时,可省略前面的
encoding=,直接写编码。 - errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或 xmlcharrefreplace(使用XML的字符引用)等,默认值为 strict。
【示例1】将指定字符串转为不同的编码格式。
test_str = '我爱Amo' # 定义字符串
utf8Str = test_str.encode(encoding='utf-8') # 采用utf-8编码
gbkStr = test_str.encode(encoding='gbk') # 采用GBK编码
print(utf8Str) # 输出utf-8编码内容:b'\\xe6\\x88\\x91\\xe7\\x88\\xb1Amo'
print(gbkStr) # 输出GBK编码内容:b'\\xce\\xd2\\xb0\\xaeAmo'
【示例2】Python中URL链接的编码处理。
最近在豆瓣电影搜索《千与千寻》的时候发现搜素链接是这样的:
https://movie.douban.com/subject_search?search_text=%E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB&cat=1002
很明显 千与千寻 被编码成了 %E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB,那么在 Python 中如何处理这种链接呢?首先来了解下 URL 编码方法:URL 编码方式是把需要编码的字符转化为 %xx 的形式。通常 URL 编码是基于 utf-8,也可能是 gbk 或 gb2312(这与网站使用的编码方式有关)。测试下上述链接中 URL 编码是否为 千与千寻,首先使用 encode() 方法将 千与千寻 的编码格式设置为 utf-8,然后使用 urllib 模块的 quote() 函数将转码后的字符串设置为 URL 编码,代码如下:
from urllib.parse import quote
from urllib.parse import unquote
# 编码测试
my_str1 = '千与千寻'.encode('utf-8')
# 使用urllib模块quote函数进行编码
my_str2 = quote(my_str1)
print(my_str2) # %E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB
# 使用urllib模块unquote函数进行解码
print(unquote(my_str2))
将结果与链接中的字符串对比完全一样,那么这种编码方式可以通过 urllib 模块的 unquote 函数进行解码。
1.6 decode() 方法——解码字符串
解码是将字节流转换成字符串(文本),其他编码格式转成 unicode。在 Python 中提供了 decode() 方法,该方法的作用是将其他编码的字符串转换成 unicode 编码,如 str1.decode(‘gb2312’),表示将 gb2312 编码的字符串 str1 转换成 unicode 编码。decode() 方法的语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
参数说明:
- bytes:表示要进行转换的字节数据,通常是 encode() 方法转换的结果。
- encoding=“utf-8”:可选参数,用于指定进行解码时采用的字符编码,默认为 utf-8,如果想使用简体中文可以设置为 gbk 或 gb2312(与网站使用的编码方式有关)。当只有一个参数时,可省略前面的
encoding=,直接写编码。 - errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或 xmlcharrefreplace(使用XML的字符引用)等,默认值为 strict。
【示例1】对指定的字符串进行解码。
# 定义字节编码
Bytes1 = bytes(b'\\xe6\\x88\\x91\\xe7\\x88\\xb1Amo')
# 定义字节编码
Bytes2 = bytes(b'\\xce\\xd2\\xb0\\xaeAmo')
str1 = Bytes1.decode("utf-8") # 进行utf-8解码
str2 = Bytes2.decode("gbk") # 进行gbk解码
print(str1) # 输出utf-8解码后的内容:我爱Amo
print(str2) # 输出gbk解码后的内容:我爱Amo
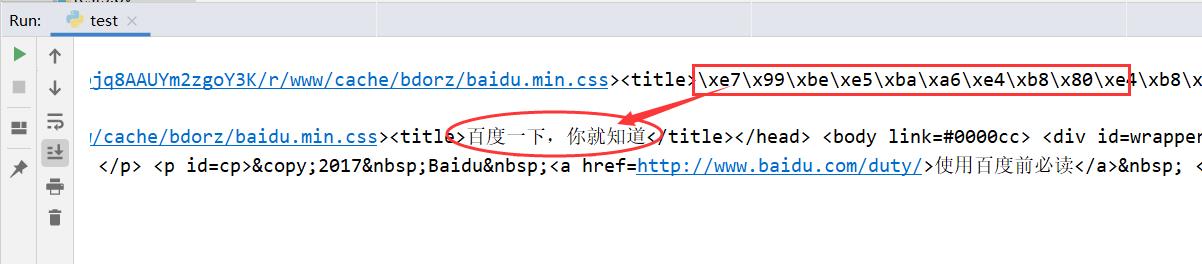
【示例2】解码爬虫获取的字节形式代码。在使用python爬取指定的网页时,获取的内容中,如果汉字都是字节码的情况下,可以通过 decode() 方法实现 html 代码的解码工作。代码如下:
import requests # 网络请求模块
# 对爬取目标发送网络请求
response = requests.get('https://www.baidu.com/')
html_bytes = response.content # 获取爬取的内容,该内容为字节形式
print(html_bytes) # 打印字节形式的html代码
print(html_bytes.decode('utf-8')) # 打印解码后的html代码
运行程序,输出结果为:
【示例3】操作不同编码格式的文件。建立一个文件 test1.txt,文件格式为 ANSI,内容如下:

用 Python 来读取,代码如下:
# 用python来读取
print(open('./test1.txt', encoding="gbk").read())
运行程序,输出结果为:
机器码:NH57Q35XD5MZVI7ZWL7H2UX0I
用户名:MZRCE44HHKBQ
将 test1.txt 另存为 test2.txt,并将编码格式改为 utf-8,再使用 Python 读取test2.txt,代码如下:
# 用python来读取
print(open('./test2.txt', encoding="gbk").read())
此时出现了乱码,这是由于字符经过不同编码解码再编码的过程中使用的编码格式不一致导致的。那么,接下来我们使用 decode() 方法进行解码,代码如下:
# 用python来读取
print(open('./test2.txt', encoding="utf8").read())
1.7 endswith() 方法——是否以指定子字符串结尾、startswith() 方法
endswith() 方法用于检索字符串是否以指定子字符串结尾。如果是则返回 True,否则返回 False。endswith() 方法的语法格式如下:
str.endswith(suffix[, start[, end]])
参数说明:
- str:表示原字符串。
- suffix:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
【示例1】 检索网址是否以“.com”结尾
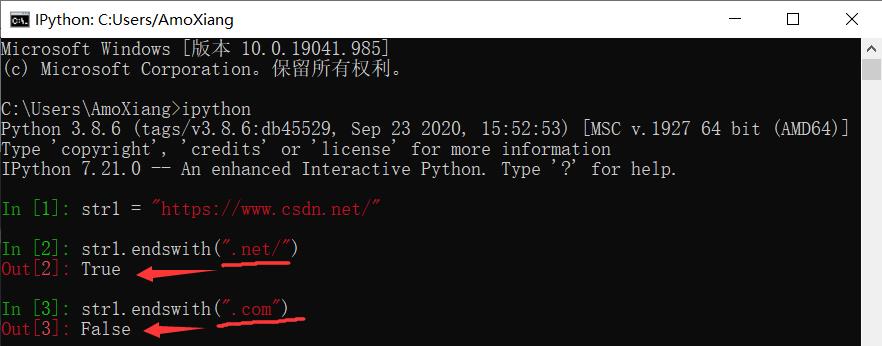
【示例2】 筛选目录下所有以.txt结尾的文件。在开发项目过程中,经常会用到 python 判断一个字符串是否以某个字符串结尾,例如,筛选目录下所有以.txt结尾的文件,代码如下:
import os
file_list = os.listdir('./')
for item in file_list:
if item.endswith('.txt'):
print(item)
运行程序,输出结果为:
startswith() 方法——是否以指定的子字符串开头。
1.8 find() 方法——字符串首次出现的索引位置(rfind()、index()、rindex())
find() 方法实现查询一个字符串在其本身字符串对象中首次出现的索引位置,如起始位置从 11 到结束位置 17 之间子字符串出现的位置,如下图所示。如果没有检索到该字符串,则返回-1。

find() 方法的语法格式如下:
str.find(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
例如,子字符串 o 在字符串 www.mingrisoft.com 起始位置从 11 到结束位置 17 之间首次出现的位置,如下图所示:

说明:Python 的字符串对象还提供了 rfind() 方法,其作用与 find() 方法类似,只是从字符串右边开始查找。Python 的字符串也提供了 index() 方法,它与 find() 方法功能相同,区别在于当 find() 方法没有检索到字符串时会返回 -1,而 index() 方法会抛出 ValueError 异常。
【示例1】 检索邮箱地址中“@”首次出现中的位置

【示例2】提取括号内数据。日常处理数据过程中,有时需要提取括号内的数据,例如下图所示括号内的手机号。
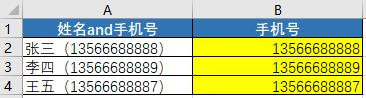
下面使用 find() 方法查找括号所在位置,然后使用切片方法提取括号内的手机号,代码如下:
str1 = '张三(13566688888)'
l1 = str1.find('(')
l2 = str1.find(')')
print(str1[l1 + 1:l2]) # 13566688888
【示例3】从邮箱地址提取ID并将首字母大写。一般情况下,邮箱地址都是由ID和服务器地址组成,那么通过邮箱地址就可以提取到ID或服务器地址。例如,提取ID并将首字母大写,效果如图所示。
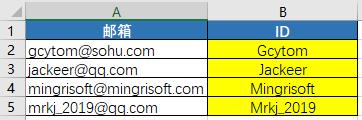
下面使用 find() 方法查找字符串中 @ 的位置,然后使用切片方法提取 ID 并通过 capitalize() 方法设置首字母大写,代码如下:
with open('./email.txt', 'r') as file:
for value1 in file.readlines():
L = value1.find('@')
print(value1[0:L].capitalize())
运行程序,结果为:
Gcytom
Jackeer
Mingrisoft
Mrkj_2019
【示例4】查询字符串中指定字符的全部索引。Python 中字符串只提供了 index() 方法来获取指定字符的索引,但是该方法只能获取字符串中第一次出现的字符索引,所以要想获取字符串中指定字符的全部索引时需要通过自定义函数的方式来实现。代码如下:
str_index_list = [] # 保存指定字符的索引
def get_multiple_indexes(string, str):
str2 = string # 用于获取字符串总长度
while True: # 循环
if str in string: # 判断是否存在需要查找的字符
first_index = string.index(str) # 获取字符串中第一次出现的字符对应的索引
string = string[first_index + 1:] # 将每次找打的字符从字符串中截取掉
result = len(str2) - len(string) # 计算截取部分的长度
str_index_list.append(result - 1) # 长度减1就是字符所在的当前索引,将索引添加列表中
else:
break # 如果字符串中没有需要查找的字符就跳出循环
print(str_index_list) # 打印指定字符出现在字符串中的全部索引
s = "aaabbdddabb" # 测试用的字符串
# [0, 1, 2, 8]
get_multiple_indexes(s, 'a') # 调用自定义方法,获取字符串中指定字符的全部索引
rfind() 方法返回子字符串在字符串中最后一次出现的位置(从右向左查询),如果没有匹配项则返回-1。
rindex() 方法的作用与 index() 方法类似。rindex() 方法用于查询子字符串在字符串中最后出现的位置,如果没有匹配的字符串会报异常。另外,还可以指定开始位置和结束位置来设置查找的区间。
1.9 format() 方法——格式化字符串
1.10 f-string ——格式化字符串
f-string 是格式化字符串的常量,它是 Python3.6 新引入的一种字符串格式化方法,主要目的是使格式化字符串的操作更加简便。f-string 在形式上是以 f 或 F 字母开头的字符串,然后通过一对单引号将要拼接的变量按顺序排列在一起,每个变量名称都需要使用一对花括号括起来,例如输出 IP 地址格式的字符串,如下图所示。
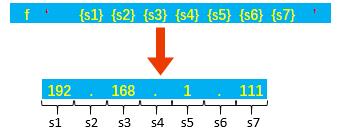
f-string 语法格式如下:
sval = f'{s1}{s2}{s3}……'
f-string 功能非常强大,而且使用起来也简单方便,因此 Python3.6 以上版本推荐使用 f-string 进行字符串格式化。下面详细介绍一下 f-string 在各个方面的应用。
【示例1】连接指定字符串。

【示例2】替换指定内容。f-string用花括号{}表示被替换字段,其中直接填入替换内容即可,代码如下:
name = 'Iphone12'
print(f'您购买的商品是:{name}')
number = 20210517
print(f'您的会员ID是:{number}')
price = 6300
print(f'您消费的金额是:{price}')
<以上是关于超详细的 Python 方法函数总结的主要内容,如果未能解决你的问题,请参考以下文章