图解Flume对接Kafka(附中文注释)
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解Flume对接Kafka(附中文注释)相关的知识,希望对你有一定的参考价值。
文章目录
1、前言
Flume基础:https://yellow520.blog.csdn.net/article/details/112758144
Kafka基础:https://yellow520.blog.csdn.net/article/details/112701565
2、架构图
2.1、前半part:File->Flume->Kafka
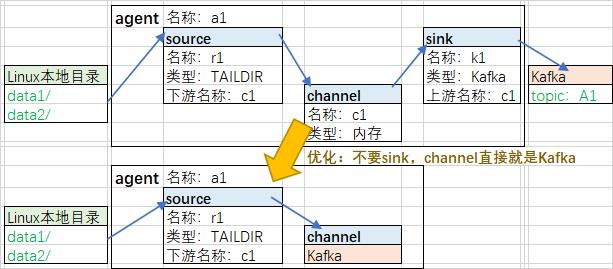
2.2、后半part:Kafka->Flume->HDFS

2.3、总

3、代码
mkdir -p /opt/test/data
3.1、File->Flume->Kafka
vi /opt/test/ffk
# 定义agent、source、channel名称,并绑定关系
a1.sources = r1
a1.channels = c1
a1.sources.r1.channels = c1
# source
a1.sources.r1.type = TAILDIR
# 指定文件组的名称
a1.sources.r1.filegroups = f1
# 指定组监控的目录(支持正则表达式)
a1.sources.r1.filegroups.f1 = /opt/test/data/.+txt
# 指定断点续传文件
a1.sources.r1.positionFile = /opt/test/data/position.json
# 指定一个批次采集多少数据
a1.sources.r1.batchSize = 100
# channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
# kafka服务地址
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092
# 主题
a1.channels.c1.kafka.topic = A1
# 数据写入时,是否以event格式写入,false表示只写body
a1.channels.c1.parseAsFlumeEvent = false
3.2、Kafka->Flume->HDFS
vi /opt/test/kfh
# 定义agent、channel、source、sink名称,并关联
a2.sources = r2
a2.channels = c2
a2.sinks = k2
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
# source
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
# kafka服务地址
a2.sources.r2.kafka.bootstrap.servers = hadoop102:9092
# 主题
a2.sources.r2.kafka.topics = A1
# 消费者组
a2.sources.r2.kafka.consumer.group.id = g1
# 消费者组第一个消费topic的数据的时候从哪里开始消费
a2.sources.r2.kafka.consumer.auto.offset.reset = earliest
# source从Kafka拉消息的批次大小
a2.sources.r2.batchSize = 50
# 拦截器
a2.sources.r2.interceptors = i1
a2.sources.r2.interceptors.i1.type = a.b.c.TimeInterceptor$Builder
# channel
a2.channels = c2
# channel类型:内存(断电可能会丢失数据)
a2.channels.c2.type = memory
# sink
a2.sinks.k2.type = hdfs
# 指定数据存储目录
a2.sinks.k2.hdfs.path = hdfs://hadoop100:8020/kf/%Y-%m-%d
# 指定文件的前缀
a2.sinks.k2.hdfs.filePrefix = log-
# 指定滚动生成文件的时间间隔
a2.sinks.k2.hdfs.rollInterval = 30
# 指定滚动生成文件的大小(133169152=127*1024*1024<128M)
a2.sinks.k2.hdfs.rollSize = 133169152
# 写入多少个event之后滚动生成新文件,通常选0,表示禁用
a2.sinks.k2.hdfs.rollCount = 0
# 文件写入格式:SequenceFile-序列化文件、DataStream-文本文件、CompressedStream-压缩文件
a2.sinks.k2.hdfs.fileType = DataStream
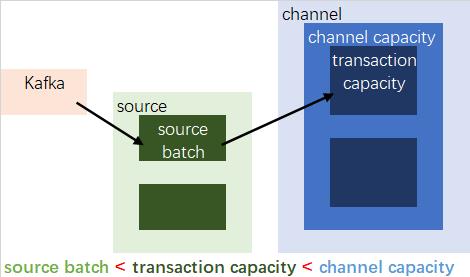
注意:
因为source的batch size默认值1000,channel的transaction capacity默认值100
所以要把source’s batch size调小
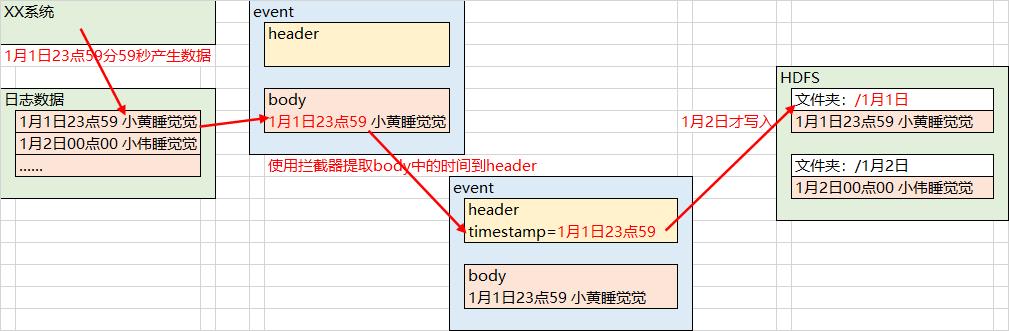
3.2.1、自定义拦截器
-
业务逻辑:
- 由于Flume默认使用Linux系统时间输出到HDFS路径,23:59产生的数据到达HDFS可能到了下一天,所以使用拦截器来获取日志中的实际时间
<!-- 依赖 -->
<dependencies>
<!-- Flume;其中scope设置为provided,打包时不用打包Flume,因为可以用服务器的那个Flume -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<!-- json解析器 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<!-- 打包插件,可以把json相关的依赖打包上 -->
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
package a.b.c;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
import java.util.Map;
public class TimeInterceptor implements Interceptor {
// 初始化
@Override
public void initialize() {}
// 处理单个event
@Override
public Event intercept(Event event) {
// 解析json
String str = new String(event.getBody());
JSONObject js = JSON.parseObject(str);
// 业务逻辑:按key取时间戳
Long ts = js.getLong("ts");
// hdfs.useLocalTimeStamp = false
// hdfs.path = /kf/%Y-%m-%d
// 添加timestamp
// 写到HDFS时,会找event的headers的key=timestamp的value
// 据此value得到%Y-%m-%d
Map<String, String> headers = event.getHeaders();
headers.put("timestamp", ts.toString());
return event;
}
// 处理批次events
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events)
intercept(event);
return events;
}
// 关闭
@Override
public void close() {}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeInterceptor();
}
@Override
public void configure(Context context) {}
}
}
打包后将名称含
with-dependencies的jar包上传到$FLUME_HOME/lib
ll $FLUME_HOME/lib | grep SNAPSHOT
4、测试
zookeeper.py start
kafka.py start
hadoop.py start
- 创建主题
kafka-topics.sh \\
--zookeeper hadoop102:2181/kafka \\
--create \\
--replication-factor 2 \\
--partitions 3 \\
--topic A1
- 写一个Python2脚本,制造含时间的数据
vi /opt/test/a.py
from time import strptime, mktime
t0 = '2020-12-31'
for i in range(1, 200000, 2):
t = int(i + mktime(strptime(t0, '%Y-%m-%d'))) * 1000
js = {'ts': t, 'num': str(i)}
print(js)
python /opt/test/a.py > /opt/test/data/a.txt
- 启动Flume
cd /opt/test/
nohup \\
flume-ng agent -n a1 -c $FLUME_HOME/conf/ -f ffk -Dflume.root.logger=INFO,console \\
>/opt/test/f1.log 2>&1 &
nohup \\
flume-ng agent -n a2 -c $FLUME_HOME/conf/ -f kfh -Dflume.root.logger=INFO,console \\
>/opt/test/f2.log 2>&1 &
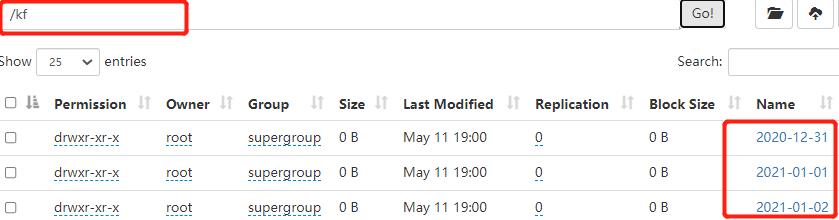
- 查看HDFS
以上是关于图解Flume对接Kafka(附中文注释)的主要内容,如果未能解决你的问题,请参考以下文章