机器学习中的特征工程
Posted AI算法攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中的特征工程相关的知识,希望对你有一定的参考价值。
一、前言
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。
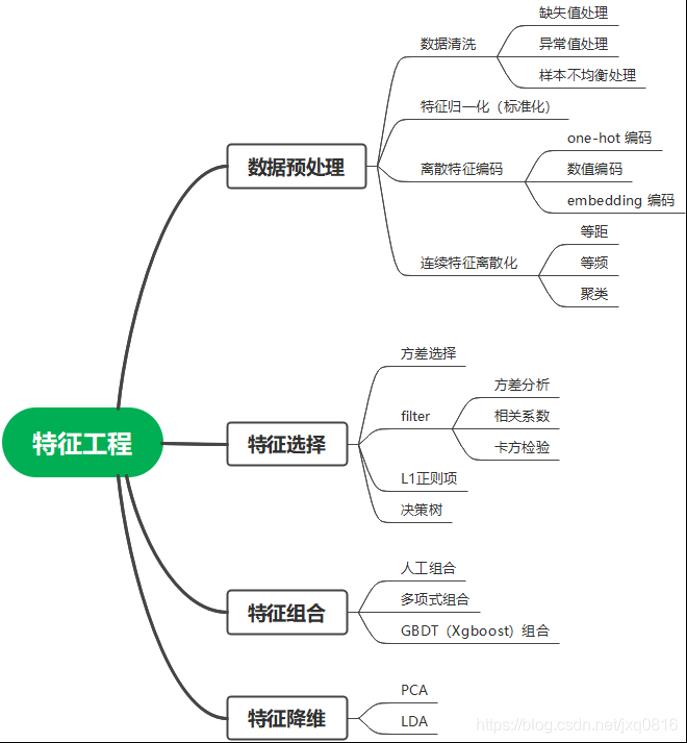
构建一个算法模型需要几个步骤,包括数据准备、特征工程、模型构建、模型调优等,其中特征工程是最重要的步骤,需要 70% 甚至以上的工作量。特征工程主要包括数据预处理、特征选择、特征构造、特征降维等。
通过总结和归纳的特征工程包括以下方面:
二、数据预处理
数据预处理是特征工程的最重要的起始步骤,主要包括数据清洗、特征归一化、特征编码、特征离散化等。
2.1 数据清洗
数据清洗是数据预处理阶段的主要组成部分,主要包括缺失值处理、异常值处理、样本不平衡处理等。
2.1.1 缺失值处理
一般来说,未经处理的原始数据中通常会存在缺失值,因此在建模训练之前需要处理好缺失值。
1)缺失数据占比小于 20%。可以通过直接填充法,连续特征一般取均值填充,离散特征可以取众数填充;可以模型预测法,通过随机森林或者决策树进行预测结果填充;也可以通过插值法填充
以上是关于机器学习中的特征工程的主要内容,如果未能解决你的问题,请参考以下文章