不平衡多分类问题模型评估指标探讨与sklearn.metrics实践
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不平衡多分类问题模型评估指标探讨与sklearn.metrics实践相关的知识,希望对你有一定的参考价值。
我们在用机器学习、深度学习建模、训练模型过程中,需要对我们模型进行评估、评价,并依据评估结果决策下一步工作策略,常用的评估指标有准确率、精准率、召回率、F1分数、ROC、AUC、MAE、MSE等等,本文将结合SKlearn的metrics所封装的函数,重点围绕多分类问题实践评估指标。
1. 模型评估指标
在机器学习、深度学习、数据挖掘领域,工业界往往会根据实际的业务场景拟定相应的业务指标。本文主要是分享分类问题模型的评价指标,对于分类问题,实际应用中往往会遇到多分类情况。
其实,分类问题评估指标是适合多分类情况的,只是举例往往是二分类的,本文虽然介绍指标时是以二分类开始,但是公式可以拓展到多分类。
分类问题评估指标:
- 准确率 – Accuracy
- 精确率(差准率)- Precision
- 召回率(查全率)- Recall
- F1分数
- ROC曲线
- AUC曲线
回归问题评估指标:
- MAE
- MSE
优化目标指标:
- 交叉熵 — cross-entropy
- rmse
1.1. 混淆矩阵
混淆矩阵(confusion matrix)也称误差矩阵,是表示精度评价的一种标准格式,用 n n n行 n n n列的矩阵形式来表示。在人工智能中,特别用于监督学习衡量的是一个分类器分类的准确程度,比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
混淆矩阵适用于多分类器的问题,本文为了让读者理解更加容易,以手写数字“5”分类识别二元分类的混淆矩阵为例说明。
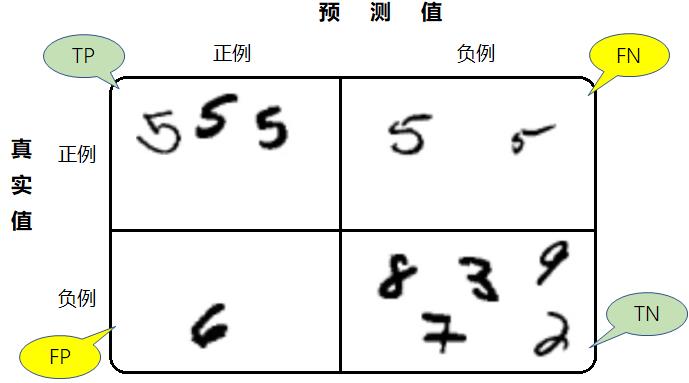
- 真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例
- 真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例
- 假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例
- 假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例
1.2. 准确率P、召回率R、F1 值
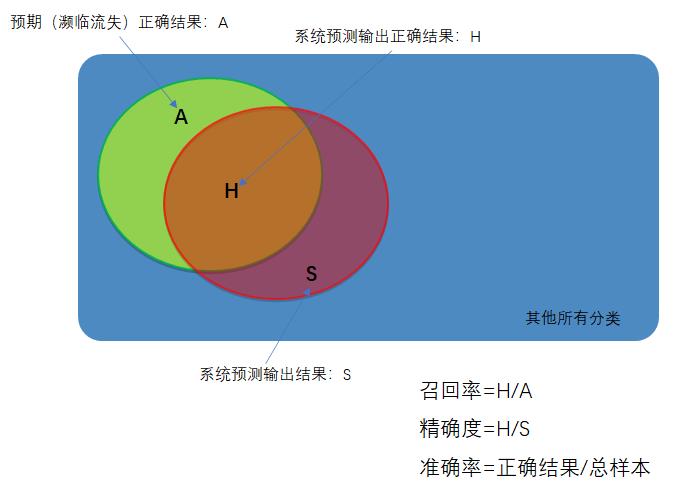
如果我们想知道类别之间相互误分的情况,查看是否有特定的类别相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,可以很清晰的反映各类别之间的错分概率。
- 准确率(Accuracy): A c c = T P + T N T P + T N + F P + F N Acc=\\frac{TP+TN}{TP+TN+FP+FN} Acc=TP+TN+FP+FNTP+TN。通俗地讲,就是预测正确的结果占总样本的百分比。
虽然准确率可以判断总的正确率,但是在样本不平衡 的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占 90%,负样本占 10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到 90% 的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
- 精准率(Precision): P = T P T P + F P P=\\frac{TP}{TP+FP} P=TP+FPTP。通俗地讲,就是预测正确的正例数据占预测为正例数据的比例。
- 召回率(Recall): R = T P T P + F N R=\\frac{TP}{TP+FN} R=TP+FNTP。通俗地讲,就是预测为正例的数据占实际为正例数据的比例
- F1值(F1 score):
F
1
=
2
1
P
+
1
R
F1=\\frac{2}{\\frac{1}{P} + \\frac{1}{R}}
F1=P1+R12。又称平衡F分数(balanced F Score),它被定义为精确率和召回率的调和平均数。
F1的值同时受到P、R的影响,单纯地追求P、R的提升并没有太大作用。在实际业务工程中,结合正负样本比,的确是一件非常有挑战的事。
1.3. ROC与AUC曲线
ROC曲线是Receiver Operating Characteristic Curve的简称,中文名为“受试者工作特征曲线”。
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性率(True Positive Rate,TPR)。FPR和TPR的计算方法分别为:
- 真阳性率:
T
P
R
=
T
P
T
P
+
F
N
TPR= \\frac{TP}{TP+FN}
TPR=TP+FNTP
- 假阳性率: F P R = F P F P + T N FPR=\\frac{FP}{FP+TN} FPR=FP+TNFP
ROC是由点(TPR,FPR)组成的曲线,AUC就是ROC的面积。
一般来说,AUC越大越好;如果TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好;ROC是光滑的,那么基本可以判断没有太大的overfitting。
为什么使用 ROC 曲线
既然已经这么多评价标准,为什么还要使用 ROC 和 AUC 呢?因为 ROC 曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
2. 模型评估工具,sklearn的metrics应用实践
sklearn.metrics中包含了许多模型评估指标,包括:分类、回归、聚类等模型评估工具。官方API为:sklearn.metrics: Metrics。
2.1. 常用分类API列表
- accuracy_score(y_true,y_pre) : 精度
- auc(x, y, reorder=False) : ROC曲线下的面积
- average_precision_score(y_true, y_score, average=‘macro’, sample_weight=None):根据预测得分计算平均精度(AP)
- brier_score_loss(y_true, y_prob, sample_weight=None, pos_label=None):The smaller the Brier score, the better.
- confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):通过计算混淆矩阵来评估分类的准确性 返回混淆矩阵
- f1_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None): F1值
- log_loss(y_true, y_pred, eps=1e-15, normalize=True, sample_weight=None, labels=None):对数损耗,又称逻辑损耗或交叉熵损耗
- precision_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’,) :查准率或者精度;
- recall_score(y_true, y_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None):查全率 ;recall(查全率)=TP/(TP+FN)
- roc_auc_score(y_true, y_score, average=‘macro’, sample_weight=None):计算ROC曲线下的面积就是AUC的值,the larger the better
- roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True);计算ROC曲线的横纵坐标值,TPR,FPR
2.2. 应用实践
准确率:accuracy_score
# 计算准确率
accuracy = accuracy_score(self.y_test, predictions)
精准率:precision_score
precision = precision_score(self.y_test.values, np.array(predictions),average='macro')
print('precision Score: %.2f%%' % (precision*100.0))
召回率:recall_score
recall = recall_score(self.y_test, predictions)
报错:
ValueError: Target is multiclass but average='binary'.
Please choose another average setting, one of [None, 'micro', 'macro', 'weighted'].
- average参数定义了该指标的计算方法,二分类时average参数默认是binary;多分类时,可选参数有micro、macro、weighted和samples。
- None:返回每个班级的分数。否则,这将确定对数据执行的平均类型。
- binary:仅报告由指定的类的结果pos_label。仅当targets(y_{true,pred})是二进制时才适用。
- micro:通过计算总真阳性,假阴性和误报来全球计算指标。也就是把所有的类放在一起算(具体到precision),然后把所有类的TP加和,再除以所有类的TP和FN的加和。因此micro方法下的precision和recall都等于accuracy。
- macro:计算每个标签的指标,找出它们的未加权平均值。这不会考虑标签不平衡。也就是先分别求出每个类的precision再求其算术平均。
- weighted:计算每个标签的指标,并找到它们的平均值,按支持加权(每个标签的真实实例数)。这会改变“宏观”以解决标签不平衡问题; 它可能导致F分数不在精确度和召回之间。
- samples:计算每个实例的指标,并找出它们的平均值(仅对于不同的多标记分类有意义 accuracy_score)。
recall = recall_score(self.y_test.values, np.array(predictions),average='macro')
print('Recall Score: %.2f%%' % (recall*100.0))
AUC:roc_auc_score
- 对于二分类,直接用预测值与标签值计算。
Y_pred = clf.predict(X_test)
# 随机森林的AUC值
forest_auc = roc_auc_score(Y_test, Y_pred)
- 对于多分类
与二分类Y_pred不同的是,概率分数Y_pred_prob,是一个shape为(测试集条数,分类种数)的矩阵。
auc = roc_auc_score(self.y_test, predictions)
报错:
ValueError: multi_class must be in ('ovo', 'ovr')
修改代码:
recall = recall_score(self.y_test, predictions,average='micro')
auc = roc_auc_score(self.y_test, predictions ,multi_class='ovo',average='macro')
ROC与AUC曲线
下面代码参考自sklearn样例代码“Compute macro-average ROC curve and ROC area”:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn.metrics import roc_curve, auc
from scipy import interp
class Multi_class_evaluation(object):
# 输入原始值,预测值,分类数量
def __init__(self, y, y_pred, n_class=2, flag=None):
self.n_class = n_class
self.flag = flag
# 构造数据矩阵n*分类数量
def datas():
cols_name = []
for i in range(self.n_class):
cols_name.append('v'+str(i))
def f(v):
vv = []
for i in range(self.n_class):
if v==i:
vv.append(1)
else:
vv.append(0)
return pd.Series(vv)
self.y = pd.DataFrame()
self.y[cols_name] = y[self.flag].apply(lambda x:f(x))
datas()
self.y = self.y.to_numpy()
self.y_pred = y_pred
# 计算ROC和AUC
def calculation_ROC_AUC(self):
# Compute ROC curve and ROC area for each class
self.fpr = dict()
self.tpr = dict()
self.roc_auc = dict()
for i in range(self.n_class):
self.fpr[i], self.tpr[i], _ = roc_curve(self.y[:, i], self.y_pred[:, i])
self.roc_auc[i] = auc(self.fpr[i], self.tpr[i])
# Compute micro-average ROC curve and ROC area
self.fpr["micro"], self.tpr["micro"], _ = roc_curve(self.y.ravel(), self.y_pred.ravel())
self.roc_auc["micro"] = auc(self.fpr["micro"], self.tpr["micro"])
#默认是多分类
def draw_ROC(self,multi_class=None):
# First aggregate all false positive rates
if multi_class==None:
all_fpr = np.unique(np.concatenate([self.fpr[i] for i in range(self.n_class)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(self.n_class):
mean_tpr += interp(all_fpr, self.fpr[i], self.tpr[i])
# Finally average it and compute AUC
mean_tpr /= self.n_class
self.fpr["macro"] = all_fpr
self.tpr["macro"] = mean_tpr
self.roc_auc["macro"] = auc(self.fpr["macro"], self.tpr["macro"])
# Plot all ROC curves
plt.figure()
lw=2 #折线宽度
plt.plot(self.fpr["micro"], self.tpr["micro"],
label='micro-average ROC curve (area = {0:0.4f})'
''.format(self.roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(self.fpr["macro"], self.tpr["macro"],
label='macro-average ROC curve (area = {0:0.4f})'
''.format(self.roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(self.n_class), colors):
plt.plot(self.fpr[i], self.tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.4f})'
''.format(i, self.roc_auc[i]))
else:
plt.figure()
lw=2 #折线宽度
plt.plot(self.fpr[multi_class], self.tpr[multi_class],
label='ROC curve of class {0} (area = {1:0.4f})'
''.format(multi_class, self.roc_auc[multi_class]),
color='deeppink')
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
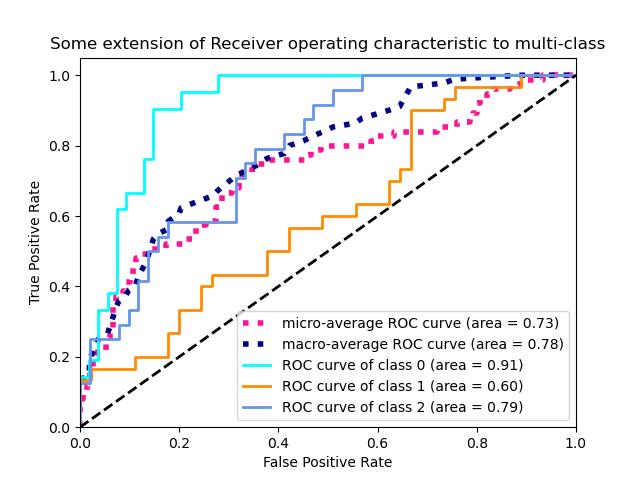
ROC曲线的特征是Y轴上的真阳性率和X轴上的假阳性率。这意味着图的左上角是“理想”点——假阳性率为零,真阳性率为一。这不太现实,但它确实意味着曲线下的较大面积(AUC)通常更好。
ROC曲线的“陡度”也很重要,因为它是理想的最大化真阳性率,同时最小化假阳性率。
ROC曲线通常用于二值分类来研究分类器的输出。为了将ROC曲线和ROC区域扩展到多标签分类,需要对输出进行二值化。每个标签可以绘制一条ROC曲线,但也可以通过将标签指标矩阵的每个元素视为二进制预测(微平均)来绘制ROC曲线。
多标签分类的另一种评估方法是宏平均法,它赋予每个标签的分类同等的权重。
2.3. 多分类案例
客户流失预测分为四个分类:流失、濒临流失、不活跃、活跃,通过XGBoost多分类,代码片段如下:
from PredictionModel import Multi_class_evaluation
......
y_pred=model.predict(xgb.DMatrix(self.x_test))
yprob = np.argmax(y_pred, axis=1) # return the index of the biggest pro
predictions = [round(value) for value in yprob]
# 计算准确率
accuracy = accuracy_score(self.y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
Mce = Multi_class_evaluation.Multi_class_evaluation(self.y_test,y_pred,n_class=4,flag='flag1')
Mce.calculation_ROC_AUC()
Mce.draw_ROC()
# 画客户流失(分类0,1,2,3中的1)
Mce.draw_ROC(multi_class=1)
y, y_ =Mce.y, Mce.y_pred
precision = precision_score(self.y_test.values, np.array(predictions),average='macro')
print('precision Score: %.2f%%' % (precision*100.0))
recall = recall_score(self.y_test.values, np.array(predictions),average='macro')
print('Recall Score: %.2f%%' % (recall*100.0))
auc 以上是关于不平衡多分类问题模型评估指标探讨与sklearn.metrics实践的主要内容,如果未能解决你的问题,请参考以下文章